Redis不管是使用还是学习,都已经很多很多遍了,但是对一些术语记得不牢,决定再学习一遍。
一、缓存穿透、缓存击穿、缓存雪崩
| 特性 | 缓存穿透 | 缓存击穿 | 缓存雪崩 |
|---|---|---|---|
| 核心问题 | 查询不存在的数据 | 热点key 在失效瞬间被高并发访问 | 大量key同时失效 或缓存服务宕机 |
| 缓存状态 | 缓存和数据库都没有数据 | 缓存刚好过期 | 缓存大面积失效 或不可用 |
| 影响范围 | 单个不存在的key | 单个热点key | 大量key或整个缓存服务 |
| 恶意攻击 | 通常由恶意攻击引起 | 通常由正常的业务高峰引起 | 通常由设计不当或故障引起 |
| 解决方案 | 1. 缓存空对象 2. 布隆过滤器 | 1. 热点数据永不过期 2. 互斥锁 | 1. 差异化过期时间 2. 高可用集群哨兵模式、集群模式 3. 降级熔断nginx或spring cloud gateway |
| 后果 | 大量无效查询直接落到数据库,给数据库造成巨大压力,甚至可能拖垮数据库。 缓存失去了保护数据库的作用。 | 数据库在短时间内承受巨大的并发请求,可能引起性能骤降甚至服务不可用。 | 导致所有请求都直接落到数据库,数据库因承受不了巨大压力而崩溃,进而导致整个系统瘫痪 |
简单来说:
-
防穿透,重在拦截非法请求(布隆过滤器)。
-
防击穿,重在避免热点数据被集体访问(加锁或永不过期)。
-
防雪崩,重在避免缓存集体失效(随机过期时间 + 高可用)。
缓存穿透-布隆过滤器
在Spring Boot中实现布隆过滤器,通常有几种方式:
1.使用Guava库提供的布隆过滤器(单机版)
java
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.List;
@Component
public class BloomFilterService {
// 预期插入的数据量
private static final int EXPECTED_INSERTIONS = 1000000;
// 误判率
private static final double FPP = 0.01;
// 布隆过滤器
private BloomFilter<String> bloomFilter;
/**
* 初始化布隆过滤器
* 在应用启动时,将已有的数据(例如从数据库加载的所有有效键)放入布隆过滤器
*/
@PostConstruct
public void init() {
// 初始化布隆过滤器
bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), EXPECTED_INSERTIONS, FPP);
// 假设这里从数据库加载所有有效的键,这里用空列表代替,实际应用需要从数据库查询
List<String> allValidKeys = loadAllValidKeysFromDatabase();
for (String key : allValidKeys) {
bloomFilter.put(key);
}
}
/**
* 模拟从数据库加载所有有效键
* @return 有效键列表
*/
private List<String> loadAllValidKeysFromDatabase() {
// 这里应该从数据库查询,例如:select key from table where valid = true
// 返回所有需要加入布隆过滤器的键
// 示例返回空列表,实际应用需要替换
return List.of();
}
/**
* 判断键是否可能存在
* @param key 待检查的键
* @return 如果布隆过滤器认为键存在,则返回true(可能误判);如果返回false,则键一定不存在
*/
public boolean mightContain(String key) {
return bloomFilter.mightContain(key);
}
/**
* 手动添加键到布隆过滤器(例如,当新增数据时,除了写入数据库,也加入布隆过滤器)
* @param key 新增的键
*/
public void put(String key) {
bloomFilter.put(key);
}
}2.使用Redis提供的布隆过滤器模块Redisson(分布式)
java
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.4</version> <!-- 请使用最新版本 -->
</dependency>
java
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.List;
@Component
public class RedisBloomFilterService {
@Autowired
private RedissonClient redissonClient;
private RBloomFilter<String> bloomFilter;
// 布隆过滤器的key
private static final String BLOOM_FILTER_KEY = "myBloomFilter";
/**
* 初始化布隆过滤器
*/
@PostConstruct
public void init() {
// 获取或创建布隆过滤器
bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_KEY);
// 初始化布隆过滤器,预计元素数量为1000000,误判率为0.01
bloomFilter.tryInit(1000000L, 0.01);
// 加载已有的数据
List<String> allValidKeys = loadAllValidKeysFromDatabase();
for (String key : allValidKeys) {
bloomFilter.add(key);
}
}
private List<String> loadAllValidKeysFromDatabase() {
// 从数据库加载所有有效键,同上例,省略
return List.of();
}
/**
* 判断键是否可能存在
*/
public boolean mightContain(String key) {
return bloomFilter.contains(key);
}
/**
* 添加键到布隆过滤器
*/
public void add(String key) {
bloomFilter.add(key);
}
}缓存击穿-互斥锁
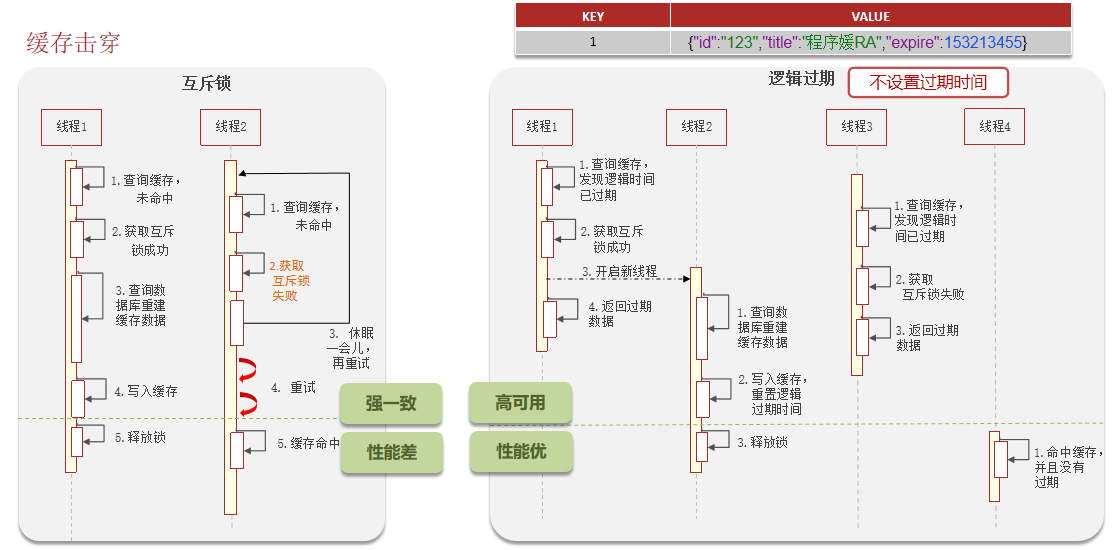
互斥锁 :这是最常见的解决方案。
-
流程 :当发现缓存失效时,不是所有线程都去查询数据库,而是让一个线程(如使用Redis的
SETNX命令获取分布式锁) 去查询数据库并重建缓存。其他线程等待锁释放后,重新从缓存中读取数据。 -
优点:能有效防止数据库被瞬间击垮。
-
缺点:性能有一定损耗,可能出现线程等待。实现相对复杂。
java
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
@Service
@Slf4j
@RequiredArgsConstructor
public class ProductServiceWithDoubleCheck {
private final RedisTemplate<String, Object> redisTemplate;
private final ProductRepository productRepository;
// 本地锁,用于减少Redis访问(适合单机多线程场景)
private static final ConcurrentHashMap<String, ReentrantLock> localLocks =
new ConcurrentHashMap<>();
private static final String CACHE_PREFIX = "product:";
private static final String LOCK_PREFIX = "product_lock:";
private static final String NULL_CACHE_PREFIX = "null_product:";
/**
* 双重检查锁 + 空值缓存
*/
public Product getProductWithDoubleCheck(String productId) {
String cacheKey = CACHE_PREFIX + productId;
String nullCacheKey = NULL_CACHE_PREFIX + productId;
// 1. 先检查空值缓存
if (Boolean.TRUE.equals(redisTemplate.hasKey(nullCacheKey))) {
log.debug("命中空值缓存,productId: {}", productId);
return null;
}
// 2. 检查正常缓存
Product product = getFromCache(cacheKey);
if (product != null) {
return product;
}
// 3. 获取本地锁(减少Redis压力)
ReentrantLock localLock = localLocks.computeIfAbsent(
productId, k -> new ReentrantLock());
localLock.lock();
try {
// 4. 再次检查缓存(第一重检查)
product = getFromCache(cacheKey);
if (product != null) {
return product;
}
// 5. 获取分布式锁
String lockKey = LOCK_PREFIX + productId;
String requestId = UUID.randomUUID().toString();
boolean distributedLocked = false;
try {
// 尝试获取分布式锁
distributedLocked = tryRedisLock(lockKey, requestId, 30, 1000);
if (distributedLocked) {
// 6. 第三重检查
product = getFromCache(cacheKey);
if (product != null) {
return product;
}
// 7. 查询数据库
product = productRepository.findById(productId).orElse(null);
if (product == null) {
// 缓存空值,防止缓存穿透
redisTemplate.opsForValue().set(
nullCacheKey,
"null",
60, // 空值缓存时间短一些
TimeUnit.SECONDS
);
log.debug("缓存空值,productId: {}", productId);
return null;
}
// 8. 写入缓存
setToCache(cacheKey, product);
return product;
} else {
// 9. 获取分布式锁失败,等待并重试
return waitForCache(cacheKey, productId);
}
} finally {
// 释放分布式锁
if (distributedLocked) {
releaseRedisLock(lockKey, requestId);
}
}
} finally {
localLock.unlock();
// 清理本地锁(可选)
localLocks.remove(productId);
}
}
/**
* 等待缓存
*/
private Product waitForCache(String cacheKey, String productId) {
int maxWaitTime = 2000; // 最大等待2秒
long startTime = System.currentTimeMillis();
while (System.currentTimeMillis() - startTime < maxWaitTime) {
try {
Product product = getFromCache(cacheKey);
if (product != null) {
log.debug("等待后获取到缓存,productId: {}", productId);
return product;
}
Thread.sleep(50); // 短暂等待
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
log.warn("等待缓存超时,直接查询数据库(可能有压力),productId: {}", productId);
// 兜底:直接查询数据库
return productRepository.findById(productId).orElse(null);
}
/**
* 尝试获取Redis锁
*/
private boolean tryRedisLock(String lockKey, String requestId,
long expireSeconds, long waitMillis) {
long endTime = System.currentTimeMillis() + waitMillis;
while (System.currentTimeMillis() < endTime) {
Boolean success = redisTemplate.opsForValue()
.setIfAbsent(lockKey, requestId, expireSeconds, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(success)) {
return true;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
return false;
}
/**
* 释放Redis锁
*/
private void releaseRedisLock(String lockKey, String requestId) {
String value = (String) redisTemplate.opsForValue().get(lockKey);
if (requestId.equals(value)) {
redisTemplate.delete(lockKey);
}
}
// ... getFromCache, setToCache 方法同上 ...
}二、先删除缓存,还是先修改数据库
双写一致性指的是同时更新缓存和数据库时,如何保证两者的数据一致。
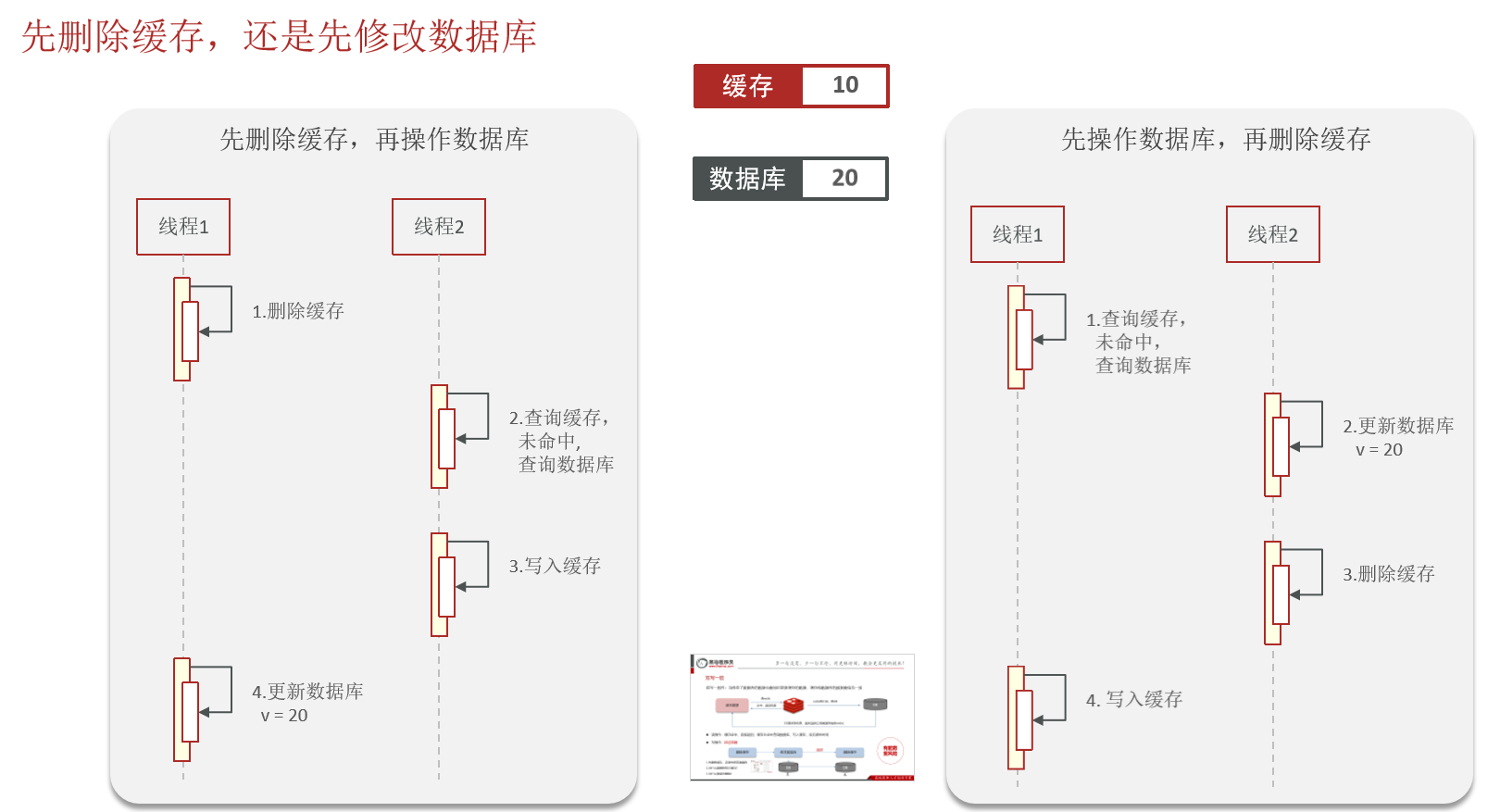
1.双写一致性的核心挑战
挑战1:原子性无法保证
java
// 这不是原子操作!
redis.set(key, value); // 步骤1
db.update(data); // 步骤2 - 可能失败挑战2:并发时序问题
java
线程A:set cache=20 → update db=20
线程B:set cache=30 → update db=30
结果取决于执行顺序挑战3:失败处理
-
缓存成功,数据库失败:如何回滚?
-
数据库成功,缓存失败:如何补偿?
2. 先删除缓存,再更新数据库
可以立即清除旧数据,迫使后续读请求直接访问数据库,获取最新数据
1.问题:并发下的数据不一致
java
时间线:
1. 线程A删除缓存
2. 线程B读取缓存(未命中)→ 读取数据库旧值 → 写入缓存(旧值)
3. 线程A更新数据库(新值)
结果:缓存中是旧数据,数据库是新数据,不一致2.解决方案:延迟双删
java
线程A(写操作) 线程B(读操作) 线程C(读操作)
--------- --------- ---------
1. 删除缓存
2. 缓存未命中
3. 查询从库(旧数据)
4. 写入缓存(旧数据)
5. 更新主库
6. 主从同步开始...
7. 等待延迟(主从同步完成)
8. 第二次删除缓存
9. 缓存未命中
10. 查询从库(新数据)
11. 写入缓存(新数据)3.适用场景:
-
缓存极其重要,读性能要求极高
-
数据库更新可重试,且有补偿机制
-
数据允许短暂不一致
3. 先更新数据库,再删除缓存(推荐)
在修改数据库后、删除缓存前,其他线程可能读到旧的缓存数据
问题:
-
缓存穿透风险:删除后,大量请求直接打到数据库
-
短暂不一致:删除后、更新前,有请求会读到旧数据
优点:
-
数据一致性更好:即使第二步(删除缓存)失败,最多是缓存脏数据,数据库始终是正确的
-
并发问题概率低:缓存未命中时,会从数据库读取最新数据
大多数情况下,选择"先更新数据库,再删除缓存",因为:
-
数据库是唯一可信源,保证数据库正确最重要
-
缓存可以重建,缓存不一致的影响相对较小
-
配合异步删除+重试机制,可以保证最终一致性
-
通过设置合理的缓存过期时间,可以兜底解决脏数据
-
不同业务场景的选择
|--------------------|-------------------|------------------|----------------------|------------------|
| 场景 | 策略 | 补充 | 原因 | 场景示例 |
| 读多写少 | 先更新DB,再删除缓存 | 设置缓存过期时间 | 写操作少,删除缓存影响小 | 商品详情 |
| 写多读少 | 直接更新DB,缓存等待过期 | 使用本地缓存 + 批量写入 | 频繁更新缓存代价高 | 点击计数 |
| 强一致性要求 | 分布式锁+ 先DB后缓存 | 使用数据库行锁或乐观锁 | 不允许超卖 | 库存扣减 |
| 数据量小但访问频繁 | 先更新DB,再更新缓存(带版本号) | 使用广播通知所有节点更新本地缓存 | 配置需要立即生效 | 配置信息 |
| 写操作频繁,缓存删除需要解耦 | 消息MQ,保证最终一致性 | 重试机制 | 保证最终一致性,但可接受短暂延迟 | 跨服务/跨系统的缓存更新 |
如果系统对一致性要求极高,可以考虑:
-
使用分布式锁(性能有影响)
-
使用数据库事务+缓存更新(复杂性高)
-
使用CDC工具监听数据库变更
在分布式系统中,追求最终一致性往往比强一致性更实际。
三、Redis持久化
在Redis中提供了两种数据持久化的方式:1.RDB 2.AOF
1.RDB
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
-
定期生成内存数据的快照
-
生成
.rdb文件(二进制格式)
优点
-
性能好,fork子进程处理,不影响主进程
-
文件紧凑,适合备份和灾难恢复
-
恢复大数据集比AOF快
缺点
-
可能丢失最后一次快照后的数据
-
fork过程可能阻塞(内存大时)
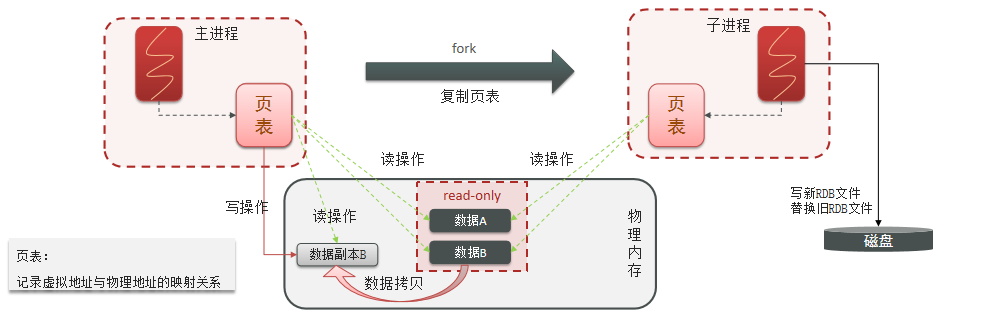
工作原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
数据究竟丢失多少?
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:

比如配置save 900 1(900秒内,如果至少有一个key被修改,则执行bgsave)
-
如果在 900秒(15分钟) 内,至少有一个键被修改
-
那么 在第900秒时 触发一次RDB快照保存
-
从上次快照到本次快照之间的数据修改可能丢失
最坏的情况:
bash
时间线:
0秒: 上一次RDB快照完成(包含此刻的所有数据)
1秒: 修改了一个键(key1) ← 开始计时
... (继续正常使用)
900秒: 触发BGSAVE,开始创建新快照
901秒: BGSAVE完成,新快照保存了key1的修改如果在 899秒 时Redis崩溃
那么从 第1秒到第899秒 的所有修改都会丢失
最多可能丢失899秒(约15分钟)的数据
但是!!!单靠 save 900 1 风险很高,还会配置几个save的,
多个save条件的关系:
|----------------------------------------------------------------------------------|
| * Redis会同时检查所有save条件 * 满足任意一个条件就会触发保存 * save 60 10000 可能在1分钟就触发,覆盖save 900 1 |
如果遇到内存不够等问题
-
BGSAVE可能因为内存问题失败
-
如果BGSAVE失败,直到下次成功保存前,数据都面临丢失风险
2.AOF
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:

AOF文件一般存储在redis服务器的工作目录下,文件名为 appendonly.aof。
-
记录每个写操作到日志文件
-
重启时重新执行所有命令恢复数据
优点
-
数据安全性高(可配置)
-
可读的日志文件,便于分析
-
最多丢失1秒数据(everysec配置)
缺点
-
文件通常比RDB大
-
恢复速度较慢
-
写入性能略低于RDB
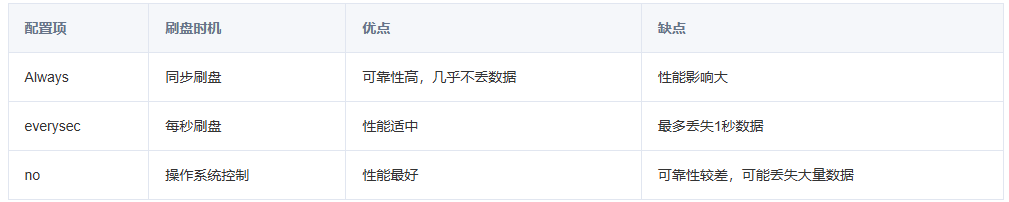
同步策略
AOF的命令记录的频率也可以通过redis.conf文件来配:

解决AOF文件大的问题
**AOF重写,**创建当前数据的最小命令集。
bash
# 手动触发
redis-cli BGREWRITEAOF
# 自动触发配置
auto-aof-rewrite-percentage 100 # 比上次重写后体积增加100%
auto-aof-rewrite-min-size 64mb # AOF文件至少64MB3.混合持久化(Redis 4.0+)
结合两者优势:
bash
aof-use-rdb-preamble yes-
重写时:将当前数据以RDB格式写入AOF开头
-
追加写:后续命令继续以AOF格式追加
-
恢复时:先加载RDB部分,再执行AOF命令
4.选择建议
| 场景 | 推荐方案 |
|---|---|
| 可容忍分钟级数据丢失 | RDB |
| 需要更高数据安全性 | AOF |
| 兼顾性能与安全 | RDB + AOF |
| Redis 4.0+ | 混合持久化 |
5.持久化注意事项
(1)监控持久化状态:
bash
redis-cli info persistence(2)备份策略:
- 定期备份RDB/AOF文件到其他服务器
- 测试恢复流程
(3)性能调优:
- 避免在持久化时执行大量写操作( 最好用户使用少的时候,进行持久化**)**
- 监控fork耗时:
latest_fork_usec指标
(4)内存规划:
- 持久化时需要额外内存(尤其是fork时,RDF持久)
- 建议预留50%内存
6.恢复优先级
RDB因为是二进制文件 ,在保存的时候体积也是比较小的,它恢复的比较快 ,但是它有可能会丢数据;我们在项目中通常也会使用AOF来恢复数据,虽然AOF恢复的速度慢一些,但是它丢数据的风险要小很多,在AOF文件中可以设置刷盘策略,我们当时设置的就是每秒批量写入一次命令
-
如果开启AOF,优先使用AOF恢复
-
否则使用RDB恢复
-
两者都关闭则数据完全在内存
7.推荐生产环境配置:
bash
# 生产环境推荐配置(平衡安全与性能)
save 900 1 # 15分钟至少1个修改
save 300 10 # 5分钟至少10个修改 ← 减少数据丢失窗口
save 60 10000 # 1分钟至少10000个修改 ← 应对突发高写入
# 如果数据非常重要,必须加AOF
appendonly yes
appendfsync everysec # 最多丢失1秒数据
# 监控和报警
监控:rdb_last_save_time, aof_last_bgrewrite_status四、Redis数据过期策略
假如redis的key过期之后,会立即删除吗?
Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。 惰性删除、定期删除
1.惰性删除
惰性删除:
-
原理:只在访问键时检查是否过期,过期则删除
-
触发时机:任何读取/写入键的命令执行前
-
优点:对 CPU 友好,只在实际需要时才会进行过期检查,过期则删除。对于很多用不到的key不用浪费时间进行过期检查
-
缺点:内存不友好,可能积累大量过期键未删除。也就是,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放
bash
客户端执行 GET key
↓
Redis检查 key 是否过期
↓
如果过期 → 删除key → 返回nil
如果未过期 → 返回值2 定期删除
定期删除:每隔一段时间,我们就对一些key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)。
-
原理:Redis 定期(默认每100ms)随机抽取部分键检查删除
-
触发时机:由 Redis 主线程周期性执行
-
配置:不可配置,但行为可调优
-
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
-
缺点:难以确定删除操作执行的时长和频率。
定期清理有两种模式:
- SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的hz 选项来调整这个次数
- FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
3.会带来的问题:
陷阱1 :设置了过期时间但从不访问
后果:依赖定期删除,可能堆积
解决:定期扫描并访问,或使用volatile-ttl策略
陷阱2 :大量键同时过期
后果:内存瞬间释放,可能引发阻塞
解决:给过期时间加随机抖动
SET key value EX $((60 + RANDOM % 60)) # 60-120秒随机
陷阱3 :内存淘汰频繁触发
后果:性能下降
解决:增加内存或调整淘汰策略
Redis的过期删除策略:惰性删除 + 定期删除 两种策略进行配合使用
五、Redis数据淘汰策略
假如缓存过多,内存是有限的,内存被占满了怎么办? ------ 其实就是想问redis的数据淘汰策略是什么?
数据的淘汰策略:当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
1.八种数据淘汰策略
Redis支持8种不同策略来选择要删除的key:
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰
- volatile-random:对设置了TTL的key ,随机进行淘汰
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
| 策略 | 说明 | 适用场景 |
|---|---|---|
| noeviction (默认) | 不淘汰,新写入报错 | 数据绝不能丢失 |
| allkeys-lru | 从所有键中淘汰最少使用的 | 无明确访问模式 |
| volatile-lru | 从设了过期时间的键中淘汰最少使用的 | 部分数据可丢失 |
| allkeys-random | 从所有键中随机淘汰 | 所有键被访问概率相同 |
| volatile-random | 从设了过期时间的键中随机淘汰 | 部分数据随机淘汰 |
| volatile-ttl | 淘汰剩余生存时间最短的 | 清理即将过期的数据 |
Redis 4.0+ 新增LFU策略:
| 策略 | 说明 | 特点 |
|---|---|---|
| allkeys-lfu | 淘汰最不经常使用的键 | 基于访问频率 |
| volatile-lfu | 从过期键中淘汰最不经常使用的 | 结合频率和时间 |
LRU的意思就是最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU的意思是最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
2.数据淘汰策略------使用建议
- 优先使用allkeys-lru策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
六、Redis 数据结构及应用场景对比表
| 数据结构 | 内部实现 | 最大存储 | 特点 | 适合存储的数据类型 | 典型应用场景 | 注意事项 |
|---|---|---|---|---|---|---|
| String | SDS (简单动态字符串) | 512MB | 二进制安全,可存储文本/数字/序列化对象 | 1. 字符串/文本 2. 整数/浮点数 3. 序列化对象(JSON/protobuf) 4. 二进制数据 | 1. 缓存 2. 计数器 3. 分布式锁 4. 会话存储 | 大字符串影响性能,建议分片存储 |
| List | 双向链表/压缩列表(ziplist) | 约40亿元素 | 有序,可重复,支持双向操作 | 1. 消息队列 2. 最新列表 3. 任务队列 4. 历史记录 | 1. 消息队列 2. 时间线 3. 最新N条记录 4. 分页查询 | 长列表影响性能,考虑分拆 |
| Hash | 字典(dict)/压缩列表(ziplist) | 约40亿键值对 | 适合存储对象,可部分更新 | 1. 用户对象 2. 商品属性 3. 配置信息 4. 对象字段聚合 | 1. 用户信息存储 2. 购物车 3. 对象缓存 4. 聚合统计 | 单个Hash不宜过大,建议不超过1000字段 |
| Set | 字典(dict)/整数集合(intset) | 约40亿元素 | 无序,不重复,支持集合运算 | 1. 标签系统 2. 好友关系 3. 抽奖用户池 4. 黑白名单 | 1. 共同好友/兴趣 2. 去重 3. 随机推荐 4. 数据排重 | SMEMBERS返回全部元素,大集合谨慎使用 |
| Sorted Set | 跳表(skiplist)+字典 | 约40亿元素 | 有序,不重复,按分数排序 | 1. 排行榜 2. 带权重的队列 3. 时间轴 4. 范围查询数据 | 1. 实时排行榜 2. 延时队列 3. 范围查询 4. 优先级队列 | 分数可重复,成员唯一;分数支持浮点数 |
| Bitmap | String的位操作 | 512MB(2^32位) | 位操作,极度节省空间 | 1. 用户在线状态 2. 签到记录 3. 布隆过滤器 4. 特征标记 | 1. 日活跃用户统计 2. 用户标签系统 3. 签到打卡 4. 布隆过滤器 | 适合大规模布尔值存储,节省内存 |
| HyperLogLog | 特殊字符串结构 | 约12KB | 基数估算,误差率0.81% | 1. 独立访客统计(UV) 2. 搜索词去重 3. 大规模集合基数估算 | 1. 网站UV统计 2. 大规模数据去重统计 3. 不需要精确结果的计数 | 只能估算基数,不能获取具体元素 |
| Geospatial | Sorted Set扩展 | 基于Sorted Set限制 | 地理位置存储与计算 | 1. 地理位置坐标 2. 附近的人/地点 3. 距离计算 4. 地理围栏 | 1. 附近商家推荐 2. 共享单车位置 3. 出行距离计算 4. 地理围栏监控 | 底层是Sorted Set,使用经纬度转分数 |
七、面试问题:
- Redis常见数据结构有哪些?Hash适合存什么样的数据?
- 什么是缓存穿透,缓存击穿,缓存雪崩?以及解决方案
- 先删除缓存,还是先修改数据库?
- Redis的RDB和AOF持久化方式,优缺点及适用场景是什么?持久化怎么恢复的?
- Redis RDF如果出现丢失数据,会丢失多少,比如save 60 10000
- Redis的数据过期策略有哪些?
- Redis淘汰策略
- 数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据 ?
- Redis的内存用完了会发生什么?
- 主从复制主要解决什么问题?哨兵模式比主从复制增加了哪些能力?
部分答案:
8.数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据 ?
使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据
9.Redis的内存用完了会发生什么?
主要看数据淘汰策略是什么?如果是默认的配置( noeviction ),会直接报错。
10.主从复制主要解决什么问题?哨兵模式比主从复制增加了哪些能力?
主从复制主要解决了数据备份、读写分离和负载均衡 的问题,它通过从节点同步主节点数据来提供冗余副本,并将读请求分流到从节点以提升读性能。而哨兵模式在主从复制的基础上,显著增强了高可用性 ,它通过独立的哨兵集群持续监控所有节点,能在主节点故障时自动完成故障检测、选举新主节点并更新所有客户端配置,从而实现了无需人工干预的自动故障转移,为Redis服务提供了真正的生产级高可用保障。