我自己的原文哦~ https://blog.51cto.com/whaosoft/11576789
# 大模型对齐阶段的Scaling Laws
Scaling law不仅是一个好用的工具,它本身的存在也给出了能影响模型效果的关键因素,指导着算法的迭代方向,比如在预训练中,核心是数据量、模型尺寸,最近Deepseek的工作中也对batch size、learning rate这两个重要超参数进行了分析。
卷友们好,我是rumor。随着过去一年大模型技术的发展,数据、模型尺寸scale up后的能力已经不容置疑,scaling law也被越来越多研究者重视起来。在预训练资源消耗如此大的情况下,掌握scaling law有众多优点:
- 提前预测最终模型效果,知道每次训练的大概能到什么程度,要是不及预期可以根据预算再进行调整
- 在小尺寸模型上做置信的实验,进行数据、算法策略验证,降低实验的时间、资源成本
- 在真正的大规模预训练中,随时监测模型效果是否符合预期
目前对于scaling law的研究主要是在预训练阶段,而对齐阶段在数据、算法策略上的实验也会有很大成本,今天我们就来看两篇对齐阶段的工作,分别研究了SFT和RLHF阶段影响效果的重要因素,希望能给大家带来一些新的insight。
精调Scaling Law
When Scaling Meets LLM Finetuning - The Effect of Data, Model and Finetuning Method这篇文章来自Google,发表在ICLR2024。作者主要在文本翻译任务上,研究了精调数据数量、模型尺寸、预训练数据数量、PET参数量(prompt tuning、lora)对效果的影响。精调和预训练比较接近,得到的公式也较接近,可以用幂函数来表示:

其中是精调数据尺寸,是其他影响因子,都是需要拟合的参数,可以反应因子的重要程度。在这篇工作中,作者以精调数据量为核心因素,分别建模了精调数据量和其他因素的联合scaling law。
精调数据量+模型尺寸

上图中实线为作者拟合的曲线,圆点是拟合用的实验点,倒三角是held-out点,用来验证外推是否准确。可以看到,随着数据量和模型尺寸的增加,test ppl也展现了一定规律的下降。但实际推到16B尺寸时在PET方式下拟合程度一般,作者分析是16B本身在预训练阶段存在一些问题。
精调数据量+预训练数据量

可以看到,预训练数据量对下游精调确实也有一定影响,外推拟合的也比较好。不过对比模型尺寸可以发现,同样计算预算下,用更大的模型尺寸精调>用更多数据预训练。但作者也指出这可能是因为翻译任务对于多样性的要求不高。
精调数据量+PET参数量
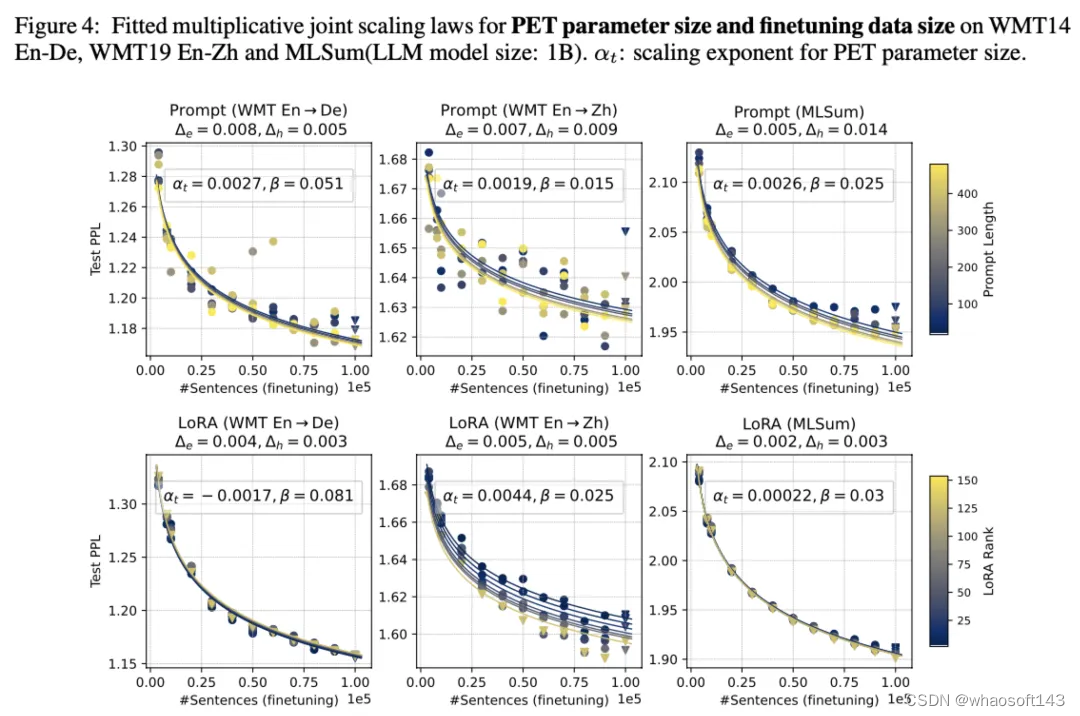
可以看到,增加PET参数量的帮助很小。同时lora比prompt tuning的方式更加稳定,更容易拟合,prompt tuning甚至出现了inverse scaling的现象。
总结
由于这篇工作只在机器翻译任务上做了实验,同时外推到16B的偏差较大,因此参考意义有限。但作者的一些实验也有重要的参考意义:
- 精调数据存在scaling law,虽然现在大家都认同小数量高质数据能取得很好的效果,但当下游任务确定时怼量也是一种选择
- 对比全参数精调FMT和PET精调的结果可以发现,FMT需要更多的数据,也能取得更好的效果。而数据量少时更适合用PET,prompt tuning在数据量少的时候更好,lora在数据量多的时候更好更稳定。另外PET的精调方式很依赖模型尺寸和预训练数据,当基座很强时,PET和FMT的差距会缩小
- 同时作者也分析了一下精调模型在其他任务上的泛化效果,发现精调后模型可以泛化到相似的任务,由于PET对参数的改动较小,因此PET的方式泛化会更好
因此,对于有明确下游任务的场景,用强基座+小数量+PET精调是一个很明智的选择。但对于任务不明确的通用场景,正如作者所言:the optimal finetuning method is highly task- and finetuning data-dependent,要得到明确的规律还有一定难度。
RLHF Scaling Law
RLHF涉及到4个模型,变量非常多,想想都不知道怎么下手。但这并难不倒OpenAI,他们早在22年底就悄咪咪放出了一篇文章,一共只有三个作者,第二作者是PPO之父John Schulman,同时也是OpenAI Alignment的Lead,阵容非常强大。
相比于预训练和精调,Scaling law对于RLHF还有一项重要意义,因为在RLHF过程中,存在着一个很典型的问题:过优化(overoptimization)。当使用奖励模型(Reward Model,简称RM)去代替人类判断时,很难保证它是无偏的,而强化算法又会让模型走捷径,一旦发现哪个地方奖励高,立刻就朝着该方向优化,拿到更高奖励值。这一现象也可以称为Goodhart's law:
When a measure becomes a target, it ceases to be a good measure.
所以真实的场景就很迷了,明明看着奖励曲线上升得很美妙,但评估出来效果不一定更好,所以到底挑哪个checkpoint去评估呢?如果有RLHF的scaling law,我们就可以预测模型真实的最优ckpt,适时停止训练,减少模型训练、评估成本。OpenAI这篇工作得到的结论则是:
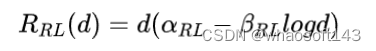
其中,和是通过RM算出来的。
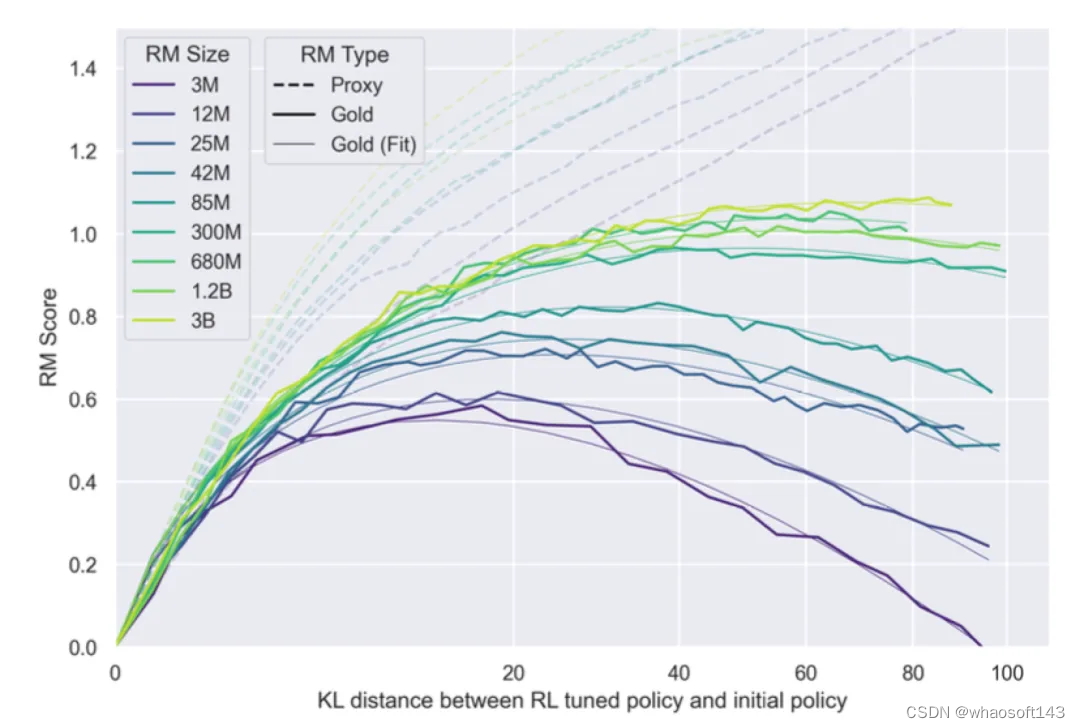
公式中的核心是RM尺寸和KL散度两个因素,有了这个公式之后,我们就可以:
- 根据当前模型偏离的KL散度,来预测模型何时到达最高的真实分数,提升评估效率
- 根据使用的RM,来预测模型能达到什么效果,或者根据效果倒推要用多大的模型
虽然最终的公式看起来非常简单,但作者也进行了很多的实验和分析。首先介绍一下实验设置,为了提升评估效率,作者使用了两个RM,一个时Gold RM,作为labeler的角色,标注一份数据后训练proxy RM,用来做RL实验:

对于RLHF的scaling law,如何挑选X和Y轴?
首先Y轴比较好选,预训练模型一般用loss,比较连续,且可以很好地反映模型效果,RL可以自然地用Reward,也具有同样的功能。但X轴就不一样了,设置成KL散度非常巧妙,因为RL不能像预训练/精调一样用计算量、过的Token数量等,如果RL也用训练时过的Token数量,会有一个问题:预训练和SFT只优化交叉熵损失这一个目标,而RL同时优化总奖励和KL惩罚两个目标,而且这两个目标是互相拉扯的,KL惩罚希望模型尽量不偏离太远,而模型要拿更多的奖励不可避免会有参数更新。于是作者看了一下不同KL惩罚系数下KL散度与步数的关系:
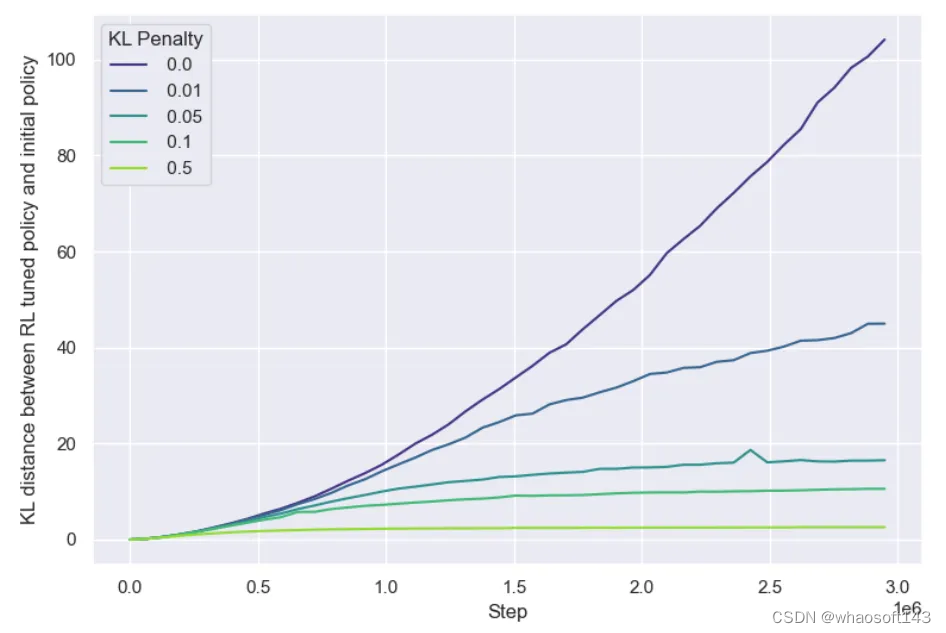
KL散度与步数的关系
如果系数过大,感觉模型就不更新了,那这时候Reward还能提吗?因此KL penalty在RLHF中其实起着early stopping的作用,为了研究训练步数的影响,作者实验时去掉了KL penalty。
除了RM尺寸,还有其他影响因素吗?
作者也对RM的训练数据量进行了实验,结果比较符合直觉,训练数据越多实际的gold score越大,但无法拟合出更清晰的规律。同时作者也尝试了不同的policy模型尺寸,更大的模型在相同RM下效果更好,比较符合直觉。但也有不符合直觉的地方,比如作者觉得更大的模型会更快过优化,实际上是和小模型在相同的KL点开始过优化的。同时不同尺寸下proxy和gold的分数gap也基本接近,没有比小模型更好拟合RM。
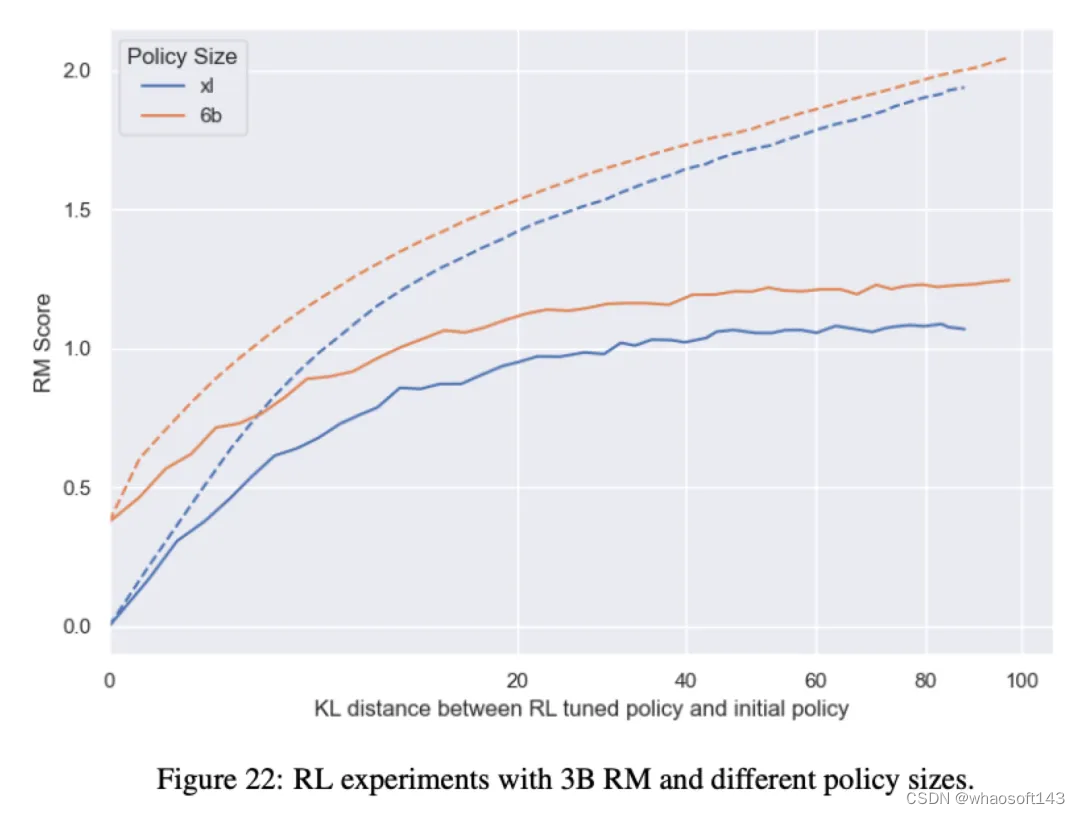
个人认为OpenAI的这篇工作非常值得一看,有很多实验细节,同时得到的结论简洁优雅。
总结
Scaling law不仅是一个好用的工具,它本身的存在也给出了能影响模型效果的关键因素,指导着算法的迭代方向,比如在预训练中,核心是数据量、模型尺寸,最近Deepseek的工作中也对batch size、learning rate这两个重要超参数进行了分析。而在对齐阶段,综合上面两篇工作,数据量、模型尺寸、RM尺寸都对效果有着规律清晰的影响,掌握这些规律十分重要,也希望后面能有更多Scaling law的相关工作。
# 多模态大语言模型综述
去年 6 月底,我们在 arXiv 上发布了业内首篇 多模态大语言模型领域的综述《A Survey on Multimodal Large Language Models》,系统性梳理了多模态大语言模型的进展和发展方向,目前论文引用 120+ ,开源 GitHub 项目获得 8.3K Stars。自论文发布以来,我们收到了很多读者非常宝贵的意见,感谢大家的支持!
- 论文链接:https://arxiv.org/pdf/2306.13549.pdf
- 项目链接(每日更新最新论文):https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
去年以来,我们见证了以 GPT-4V 为代表的多模态大语言模型(Multimodal Large Language Model,MLLM)的飞速发展。为此我们对综述进行了重大升级,帮助大家全面了解该领域的发展现状以及潜在的发展方向。
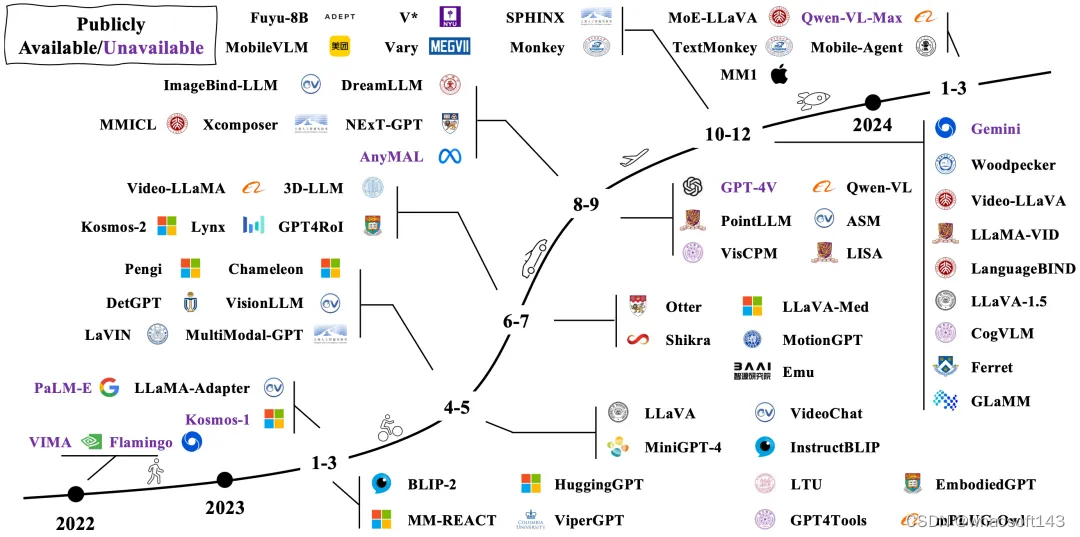
MLLM 发展脉络图
MLLM 脱胎于近年来广受关注的大语言模型(Large Language Model , LLM),在其原有的强大泛化和推理能力基础上,进一步引入了多模态信息处理能力。相比于以往的多模态方法,例如以 CLIP 为代表的判别式,或以 OFA 为代表的生成式,新兴的 MLLM 展现出一些典型的特质:(1)模型大 。MLLM 通常具有数十亿的参数量,更多的参数量带来更多的潜力;(2)新的训练范式。为了激活巨大参数量的潜力,MLLM 采用了多模态预训练、多模态指令微调等新的训练范式,与之匹配的是相应的数据集构造方式和评测方法等。在这两种特质的加持下,MLLM 涌现出一些以往多模态模型所不具备的能力,例如给定图片进行 OCRFree 的数学推理、给定图片进行故事创作和理解表情包的深层含义等。
本综述主要围绕 MLLM 的基础形式、拓展延伸以及相关研究课题进行展开,具体包括:
- MLLM 的基础构成与相关概念,包括架构、训练策略、数据和评测;
- MLLM 的拓展延伸,包括输入输出粒度、模态、语言和场景的支持;
- MLLM 的相关研究课题,包括多模态幻觉、多模态上下文学习(Multimodal In-Context Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)、LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)。
架构
对于多模态输入-文本输出的典型 MLLM,其架构一般包括编码器 、连接器 以及 LLM 。如要支持更多模态的输出(如图片、音频、视频),一般需要额外接入生成器,如下图所示:
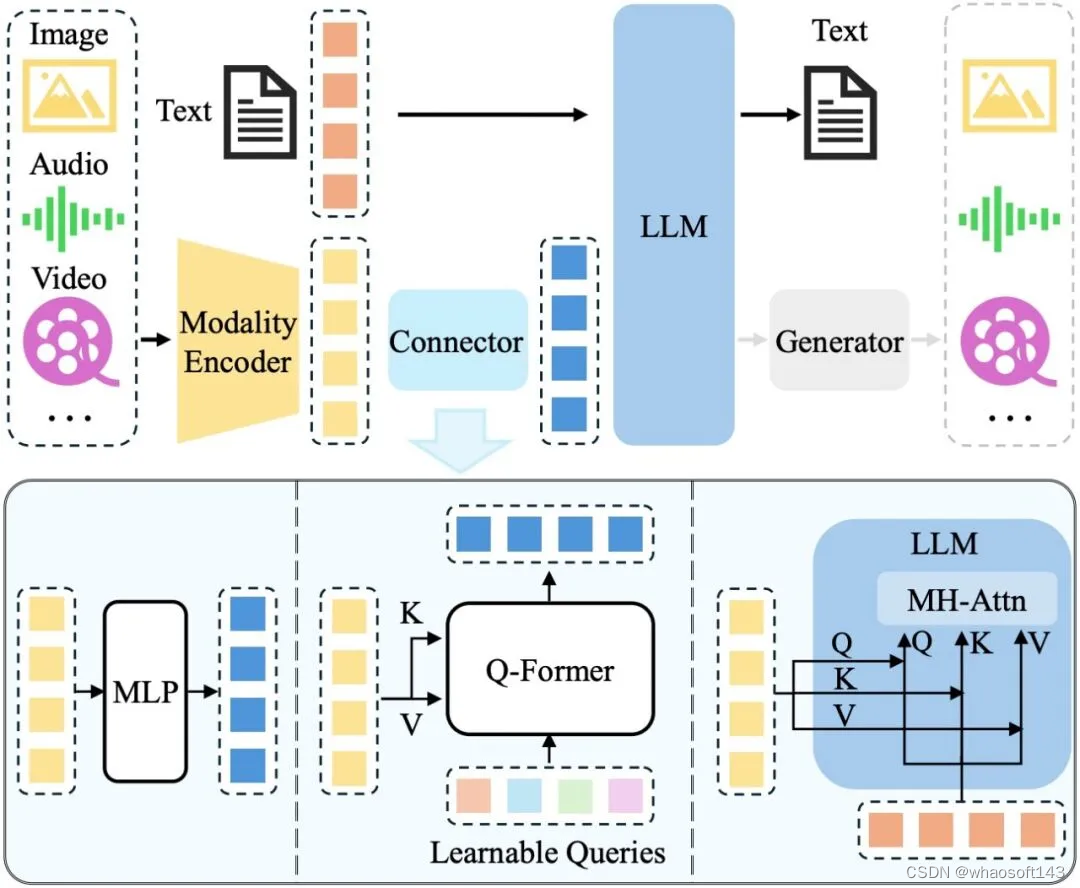
MLLM 架构图
其中,模态编码器负责将原始的信息(如图片)编码成特征,连接器则进一步将特征处理成LLM 易于理解的形式,即视觉 Token。LLM 则作为"大脑"综合这些信息进行理解和推理,生成回答。目前,三者的参数量并不等同,以 Qwen-VL1为例,LLM 作为"大脑"参数量为 7.7B,约占总参数量的 80.2%,视觉编码器次之(1.9B,约占 19.7%),而连接器参数量仅有 0.08B。
对于视觉编码器而言,增大输入图片的分辨率是提升性能的有效方法。一种方式是直接提升分辨率,这种情况下需要放开视觉编码器进行训练以适应更高的分辨率,如 Qwen-VL1等。另一种方式是将大分辨率图片切分成多个子图,每个子图以低分辨率送入视觉编码器中,这样可以间接提升输入的分辨率,如 Monkey2等工作。
对于预训练的 LLM,常用的包括 LLaMA3系列、Qwen4系列和 InternLM5系列等,前者主要支持英文,而后两者中英双语支持得更好。就性能影响而言,加大 LLM 的参数量可以带来显著的性能增益,如 LLaVA-NeXT6等工作在 7B/13B/34B 的 LLM 上进行实验,发现提升LLM 大小可以带来各 benchmark 上的显著提升,在 34B 的模型上更涌现出 zero-shot 的中文能力。除了直接增大 LLM 参数量,近期火热的 MoE 架构则提供了更高效实现的可能性,即通过稀疏计算的方式,在不增大实际计算参数量的前提下提高总的模型参数量。
相对前两者来说,连接器的重要性略低。例如,MM17通过实验发现,连接器的类型不如视觉 token 数量(决定之后 LLM 可用的视觉信息)及图片的分辨率(决定视觉编码器的输入信息量)重要。
数据与训练
MLLM 的训练大致可以划分为预训练阶段 、指令微调阶段 和对齐微调阶段。预训练阶段主要通过大量配对数据将图片信息对齐到 LLM 的表征空间,即让 LLM 读懂视觉 Token。指令微调阶段则通过多样化的各种类型的任务数据提升模型在下游任务上的性能,以及模型理解和服从指令的能力。对齐微调阶段一般使用强化学习技术使模型对齐人类价值观或某些特定需求(如更少幻觉)。
早期工作在第一阶段主要使用粗粒度的图文对数据,如 LAION-5B,这些数据主要来源于互联网上的图片及其附带的文字说明,因此具有规模大(数 10 亿规模)但噪声多、文本短的特点,容易影响对齐的效果。后来的工作则探索使用更干净、文本内容更丰富的数据做对齐。如 ShareGPT4V8使用 GPT-4V 生成的详细描述来做更细粒度的对齐,在一定程度上缓解了对齐不充分的问题,获得了更好的性能。但由于 GPT-4V 是收费的,这种类型的数据规模通常较小(数百万规模)。此外,由于数据规模受限,其包含的世界知识也是有限的,比如是否能够识别出图像中的建筑为广州塔。此类世界知识通常储备于大规模的粗粒度图文对中。
第二阶段的微调数据一方面可以来源于各种任务的数据,如 VQA 数据、OCR 数据等,也可以来源于 GPT-4V 生成的数据,如问答对。虽然后者一般能够生成更复杂、更多样化的指令数据,但这种方式也显著地增加了成本。值得一提的是,第二阶段的训练中一般还会混合部分纯文本的对话数据,这类数据可以视为正则化的手段,保留 LLM 原有的能力与内嵌知识。
第三阶段的数据主要是针对于回答的偏好数据。这类数据通常由人工标注收集,因而成本较高。近期出现一些工作使用自动化的方法对来自不同模型的回复进行偏好排序,如 Silkie9通过调用 GPT-4V 来收集偏好数据。
其他技术方向
除了提升模型的基础能力(如支持的输入/输出形式、性能指标)外,还有一些有意思的问题以及待探索的方向。本综述中主要介绍了多模态幻觉、多模态上下文学习(Multimodal InContext Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)和 LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)等。
多模态幻觉的研究主要关注模型生成的回答与图片内容不符的问题。视觉和文本本质上是异构的信息,完全对齐两者本身就具有相当大的挑战。增大图像分辨率和提升训练数据质量是降低多模态幻觉的两种最直观的方式,此外我们仍然需要在原理上探索多模态幻觉的成因和解法。例如,当前的视觉信息的 Token 化方法、多模态对齐的范式、多模态数据和 LLM 存储知识的冲突等对多模态幻觉的影响仍需深入研究。
多模态上下文学习技术为少样本学习方法,旨在使用少量的问答样例提示模型,提升模型的few-shot 性能。提升性能的关键在于让模型有效地关注上下文,并将内在的问题模式泛化到新的问题上。以 Flamingo10为代表的工作通过在图文交错的数据上训练来提升模型关注上下文的能力。目前对于多模态上下文学习的研究还比较初步,有待进一步探索。
多模态思维链的基本思想是通过将复杂的问题分解为较简单的子问题,然后分别解决并汇总。相较于纯文本的推理,多模态的推理涉及更多的信息来源和更复杂的逻辑关系,因此要复杂得多。当前该方面的工作也比较少。
LLM 辅助的视觉推理方法探索如何利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。相比于通过端到端训练获得单一模型,这类方法一般关注如何通过免训练的方式扩展和加强 LLM 的能力,从而构建一个综合性的系统。
挑战和未来方向
针对 MLLM 的研究现状,我们进行了深入思考,将挑战与可能的未来发展方向总结如下:
- 现有 MLLM 处理多模态长上下文的能力有限,导致模型在长视频理解、图文交错内容理解等任务中面临巨大挑战。以 Gemini 1.5 Pro 为代表的 MLLM 正在掀起长视频理解的浪潮,而多模态图文交错阅读理解(即长文档中既有图像也有文本)则相对空白,很可能会成为接下来的研究热点。
- MLLM 服从复杂指令的能力不足。例如,GPT-4V 可以理解复杂的指令来生成问答对甚至包含推理信息,但其他模型这方面的能力则明显不足,仍有较大的提升空间。
- MLLM 的上下文学习和思维链研究依然处于初步阶段,相关的能力也较弱,亟需相关底层机制以及能力提升的研究探索。
- 开发基于 MLLM 的智能体是一个研究热点。要实现这类应用,需要全面提升模型的感知、推理和规划能力。
- 安全问题。MLLM 容易受设计的恶意攻击影响,生成有偏的或不良的回答。该方面的相关研究也仍然欠缺。
- 目前 MLLM 在训练时通常都会解冻 LLM,虽然在训练过程中也会加入部分单模态的文本训练数据,但大规模的多模态和单模态数据共同训练时究竟对彼此互有增益还是互相损害仍然缺乏系统深入的研究。
更详细内容请阅读
- 论文链接:https://arxiv.org/pdf/2306.13549.pdf
- 项目链接:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
# Mistral开源8X22B大模型
OpenAI更新GPT-4 Turbo视觉,都在欺负谷歌,真有围剿 Google 的态势啊!
在谷歌昨晚 Cloud Next 大会进行一系列重大发布时,你们都来抢热度:前有 OpenAI 更新 GPT-4 Turbo,后有 Mistral 开源 8X22B 的超大模型。
谷歌内心:南村群童欺我老无力。
第二大开源模型:Mixtral 8X22B
今年 1 月,Mistral AI 公布了 Mixtral 8x7B 的技术细节,并推出了 Mixtral 8x7B -- Instruct 聊天模型。该模型的性能在人类评估基准上明显超过了 GPT-3.5 Turbo、Claude-2.1、Gemini Pro 和 Llama 2 70B 聊天模型。
短短 3 个月后,Mistral AI 开源了 Mistral 8X22B 模型,为开源社区带来了又一个性能强劲的大模型。
有人已经查看了 Mistral 8X22B 模型的细节,模型文件大小约为 262 GB。
由此,Mistral 8X22B 仅次于 xAI 此前推出的 Grok-1(参数量为 3140 亿),成为迄今为止第二大开源模型。
还有人惊呼,MoE 圈子又来了个「大家伙」。MoE 即专家混合模型,此前 Grok-1 也为 MoE 模型。
GPT-4 Turbo 视觉功能新升级
另一边,OpenAI 宣布 GPT-4 Turbo with Vision 现在可以通过 API 使用了,并且 Vision 功能也可以使用 JSON 模式和函数调用了。
下面为 OpenAI 官网细节。
虽然如此,各路网友对 OpenAI 的小修小补「并不感冒」。
参考链接:
https://platform.openai.com/docs/models/continuous-model-upgrades
# 谷歌更新了一大波大模型产品
这次,谷歌要凭「量」打败其他竞争对手。
当地时间本周二,谷歌在 Google's Cloud Next 2024 上发布了一系列 AI 相关的模型更新和产品,包括 Gemini 1.5 Pro 首次提供了本地音频(语音)理解功能、代码生成新模型 CodeGemma、首款自研 Arm 处理器 Axion 等等。
Gemini 1.5 Pro
Gemini 1.5 Pro 是 Google 功能最强大的生成式 AI 模型,现已在 Google 以企业为中心的 AI 开发平台 Vertex AI 上提供公共预览版。这是谷歌面向企业的 AI 开发平台。它能处理的上下文从 12.8 万个 token 增加到 100 万个 token。100 万个 token 大约相当于 70 万个单词,或者大约 3 万行代码。这大致是 Anthropic 的旗舰模型 Claude 3 能作为输入处理的数据量的四倍,也大约是 OpenAI 的 GPT-4 Turbo 最大上下文量的八倍。
官方原文链接:https://developers.googleblog.com/2024/04/gemini-15-pro-in-public-preview-with-new-features.html
该版本首次提供了本地音频(语音)理解功能和全新的文件 API,使文件处理变得更加简单。Gemini 1.5 Pro 的输入模态正在拓展,包括在 Gemini API 和 Google AI Studio 中增加对音频(语音)的理解。此外,Gemini 1.5 Pro 现在能够对在 Google AI Studio 中上传的视频的图像(帧)和音频(语音)进行推理。
可以上传一个讲座的录音,比如这个由 Jeff Dean 进行的超过 117000 个 token 的讲座,Gemini 1.5 Pro 可以将其转换成一个带有答案的测验。(演示已加速)
谷歌在 Gemini API 方面也进行了改进,主要有以下三个内容:
- 系统指令:现在可以在 Google AI Studio 和 Gemini API 中使用系统指令来指导模型的响应。定义角色、格式、目标和规则,以针对您的特定用例指导模型的行为。
在 Google AI Studio 中轻松设置系统指令
2.JSON 模式:指示模型仅输出 JSON 对象。这种模式使从文本或图像中提取结构化数据成为可能。现在可以使用 cURL,Python SDK 支持即将推出。
- 对函数调用的改进:现在可以选择模式来限制模型的输出,提高可靠性。选择文本、函数调用或仅函数本身。
此外,谷歌将发布下一代文本嵌入模型,其性能优于同类模型。从今天开始,开发者将能够通过 Gemini API 访问下一代文本嵌入模型。这个新模型,text-embedding-004(在 Vertex AI 中为 text-embedding-preview-0409),在 MTEB 基准测试中实现了更强的检索性能,并且超越了具有可比维度的现有模型。
在 MTEB 基准测试中,使用 256 dims 输出的 Text-embedding-004(又名 Gecko)优于所有较大的 768 dims 输出模型
不过,需要注意的是,Gemini 1.5 Pro 对于没有访问 Vertex AI 和 AI Studio 权限的人来说是不可用的。目前,大多数人通过 Gemini 聊天机器人来接触 Gemini 语言模型。Gemini Ultra 驱动了 Gemini Advanced 聊天机器人,虽然它功能强大,也能理解长命令,但它的速度不如 Gemini 1.5 Pro。
三大开源工具
在 2024 年的 Google Cloud Next 大会上,该公司推出多个开源工具,主要用于支持生成式 AI 项目和基础设施。其一是 Max Diffusion,它是各种扩散模型参考实现的集合,可在 XLA(加速线性代数)设备上运行。
GitHub 地址:https://github.com/google/maxdiffusion
其二是 Jetstream,一个运行生成式 AI 模型的新引擎。目前,JetStream 只支持 TPU,未来可能会兼容 GPU。谷歌声称,JetStream 可为谷歌自己的 Gemma 7B 和 Meta 的 Llama 2 等模型提供高达 3 倍的性价比。
GitHub 地址:https://github.com/google/JetStream
第三个是 MaxTest,这是一个针对云中的 TPUs 和 Nvidia GPUs 的文本生成 AI 模型的集合。MaxText 现在包括 Gemma 7B、OpenAI 的 GPT-3、Llama 2 和来自 AI 初创公司 Mistral 的模型,谷歌表示所有这些模型都可以根据开发人员的需求进行定制和微调。
GitHub 地址:https://github.com/google/maxtext
首款自研 Arm 处理器 Axion
谷歌云宣布推出其首款自主研发的 Arm 处理器,名为 Axion。其基于 Arm 的 Neoverse 2,专为数据中心设计。谷歌表示其 Axion 实例的性能比其他竞争对手如 AWS 和微软的基于 Arm 的实例高出 30%,与相应的基于 X86 的实例相比,性能提高了最多 50%,能效提高了 60%。
谷歌在周二的发布会上强调,由于 Axion 建立在一个开放的基础上,谷歌云的客户将能够将他们现有的 Arm 工作负载带到谷歌云,而无需任何修改。
不过,目前谷歌还没有发布对此进行详细介绍的内容。
代码补全、生成利器 ------CodeGemma
CodeGemma 以 Gemma 模型为基础,为社区带来了强大而轻量级的编码功能。该模型可分为专门处理代码补全和代码生成任务的 7B 预训练变体、用于代码聊天和指令跟随的 7B 指令调优变体、以及在本地计算机上运行快速代码补全的 2B 预训练变体。
CodeGemma 具有以下几大优势:
- 智能代码补全和生成:补全行、函数,甚至生成整个代码块,无论你是在本地还是云上工作;
- 更高准确性:CodeGemma 主要使用来自网络文档、数学和代码的 5000 亿 token 的英语语言数据进行训练,生成的代码不仅语法更正确,语义也更有意义,有助于减少错误和 debug 时间;
- 多语言能力:支持 Python、JavaScript、Java 和其他流行编程语言;
- 简化工作流程:将 CodeGemma 集成到你的开发环境中,以减少编写的样板代码,并更快地编写重要、有趣且差异化的代码。
CodeGemma 与其他主流代码大模型的一些比较结果如下图所示:
CodeGemma 7B 模型与 Gemma 7B 模型在 GSM8K、MATH 等数据集上的比较结果。
论文地址:https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf
开放语言模型 ------RecurrentGemma
Google DeepMind 还发布了一系列开放权重语言模型 ------RecurrentGemma。RecurrentGemma 基于 Griffin 架构,通过将全局注意力替换为局部注意力和线性循环(linear recurrences)的混合,在生成长序列时实现快速推理。
技术报告:https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf
RecurrentGemma-2B 在下游任务上实现了卓越的性能,可与 Gemma-2B(transformer 架构)媲美。
同时,RecurrentGemma-2B 在推理过程中实现了更高的吞吐量,尤其是在长序列上。
视频编辑工具 ------Google Vids
Google Vids 是一款 AI 视频创建工具,是 Google Workspace 中添加的新功能。
谷歌表示,借助 Google Vids,用户可以与文档和表格等其他 Workspace 工具一起制作视频,并且可与同事实时协作。
企业专用代码助手 ------Gemini Code Assist
Gemini Code Assist 是一款面向企业的 AI 代码完成和辅助工具, 对标 GitHub Copilot Enterprise。Code Assist 将通过 VS Code 和 JetBrains 等流行编辑器以插件的形式提供。
Code Assist 由 Gemini 1.5 Pro 提供支持。Gemini 1.5 Pro 拥有百万 token 的上下文窗口,这使得谷歌的工具能够比竞争对手引入更多的上下文。谷歌表示,这意味着 Code Assist 能够提供更准确的代码建议,并具备推理和更改大段代码的能力。
谷歌表示:「Code Assist 使客户能够对整个代码库进行大规模更改,从而实现以前不可能实现的人工智能辅助代码转换。」
智能体构建器 ------Vertex AI
AI 智能体是今年一个热门的行业发展方向。谷歌现在宣布推出一款帮助企业构建 AI 智能体的新工具 ------Vertex AI Agent Builder。
谷歌云首席执行官 Thomas Kurian 表示:「Vertex AI Agent Builder 使人们能够非常轻松、快速地构建和部署可用于生产的、由人工智能驱动的生成式对话智能体,并且能够以指导人类的方式指导智能体,以提高模型生成结果的质量和正确性。」
参考链接:
https://techcrunch.com/2024/04/09/google-open-sources-tools-to-support-ai-model-development/