在刚刚结束的Meta开发者大会上,Llama 3.2惊艳亮相。此次,它不仅拥有多模态能力,还与Arm等公司合作,推出了专门针对高通、联发科硬件优化的"移动"版本。

NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
具体来说,Meta发布了Llama 3.2的四个模型:
- 110亿和900亿参数的多模态版本
- 10亿和30亿参数的轻量级纯文本模型
根据官方数据,Llama 3.2 11B和90B已经展现出超越同等规模闭源模型的性能。
尤其是在图像理解任务上,Llama 3.2 11B的表现优于Claude 3 Haiku,90B版本甚至可以与GPT-4o-mini相媲美。


目前,Llama 3.2 的两个最大模型 11B 和 90B 支持图像推理,包括文档级图表理解、图像描述和视觉定位任务,例如基于自然语言描述精确定位图像中的对象。
例如,用户可以问"去年哪个月的销售额最高?",Llama 3.2 可以通过对现有图表进行推理来快速给出答案。
轻量级 1B 和 3B 版本是纯文本模型,但也拥有多语言文本生成和工具调用功能。Meta 表示,这些模型使开发人员能够构建个性化的设备上通用应用程序------这些应用程序提供了强大的隐私保护,因为数据不需要离开设备。
在本地运行这些模型有两个主要优点:
- 提示和响应可以即时完成,因为处理是在本地完成的。
- 在本地运行模型时,无需将消息和日历等私人信息上传到云端,从而确保数据隐私。由于处理是本地的,因此应用程序可以确定哪些任务可以在设备上处理,哪些任务需要更强大的基于云的模型。
虽然目前没有产品允许移动设备有效地运行这些强大的轻量级模型,但我们仍然可以使用 Linux 环境来预览 Ollama。
本文将指导你在 Android 手机上安装 Termux,并在其 Linux 环境中编译和安装 Ollama,以在本地运行 Llama 3.2。可以使用相同的方法运行任何其他受支持的模型。
1、轻量级模型的技术背景
正如Meta在Llama 3.1发布时所提到的,可以利用强大的教师模型来创建更小但性能更好的模型。Meta对1B和3B模型进行了修剪和蒸馏,使其成为第一款能够在设备上高效运行的轻量级Llama模型。
通过修剪技术,Llama系列模型的尺寸可以显著减小,同时尽可能多地保留原有的知识和性能。在1B和3B模型的开发过程中,Meta采用了从Llama 3.1的8B模型中衍生出来的一次性结构化修剪策略。具体来说,Meta系统地删除了网络的某些部分并相应地调整了权重和梯度,从而得到了一个更小、更高效的模型,同时确保它保持与原始网络相同的性能水平。
完成修剪步骤后,Meta应用知识蒸馏来进一步提升模型的性能。
知识蒸馏是一种将较大的网络将知识转移到较小的网络的技术。核心思想是,在教师模型的指导下,较小的模型可以取得比独立训练更好的性能。在 Llama 3.2 的 1B 和 3B 模型中,Meta 在预训练阶段引入了 Llama 3.1 的 8B 和 70B 模型的输出作为训练过程的 token 级目标。

在训练后阶段,Meta 采用了与 Llama 3.1 类似的方法------对预训练模型进行多轮对齐。每轮包括监督微调 (SFT)、拒绝抽样 (RS) 和直接偏好优化 (DPO)。
具体来说,Meta 将上下文窗口长度扩展到 128K 个 token,同时保持与预训练模型相同的质量。
为了增强模型的性能,Meta 还利用了合成数据生成。他们整理了高质量的混合数据,以优化模型在总结、重写、遵循指令、语义推理和工具使用方面的能力。


上述演示基于未发布的量化模型。
2、测试设备
我使用的手机是四年前发布的三星S21 Ultra,规格如下:
处理器:
- 型号:高通骁龙888
- 制程:5nm
- CPU架构:1+3+4八核设计。1个Cortex-X1主核,主频2.84GHz;3个Cortex-A78性能核,主频2.4GHz; 4个Cortex-A55效率核,主频1.8GHz
- GPU:Adreno 660
- RAM:16GB LPDDR5
- 存储:512GB UFS 3.1闪存
通过测试,这款设备运行Llama 3.2 3B型号略有延迟,但总体流畅。运行Llama 3.2 1B型号流畅无问题。

使用该模型生成答案时,我的手机 16GB 内存只有 2.8GB 可用,温度明显升高。请注意,本文介绍的方法不能确保使用 GPU 进行推理,因为此类移动设备上的 GPU 无法识别。
因此,要在 Android 设备上运行 Llama 3.2,你只需要一部 Android 手机、网络连接和一些耐心。
让我们开始吧。
3、下载并安装 Termux
Termux 是一款功能强大的 Android 终端仿真器和 Linux 环境应用程序,它提供了通常在成熟的 Linux 系统上可用的各种工具。Termux 与其他终端仿真器的不同之处在于它无需 root 访问权限即可运行,从而使更广泛的 Android 用户可以使用它。使用 Termux,你可以直接在 Android 设备上安装和运行各种编程语言、工具和软件包,将其转变为便携式开发环境。
你可以直接从 Termux 的GitHub 页面下载最新版本。在这里,我们选择下载 termux-app_v0.119.0-beta.1+apt-android-7-github-debug_arm64-v8a.apk。
下载完成后,在你的 Android 设备上安装 APK 文件。

4、环境设置
启动 Termux 后,你将看到一个类似于常规 Linux 终端的界面。你可以在手机上打开这篇文章,轻松复制后面的很多命令。

接下来,我们需要运行以下命令:
termux-setup-storageTermux 中的 termux-setup-storage 命令用于授予 Termux 应用访问 Android 设备上共享存储的权限。此命令在 Termux 主目录中创建一个名为 storage 的目录,其中包含指向各种标准 Android 存储目录的符号链接,例如下载、图片、音乐等。通过运行此命令,你可以允许 Termux 读取和写入设备的外部存储,从而更轻松地管理文件、访问媒体以及在 Termux 和其他应用之间保存或检索数据。
运行命令后,将出现系统权限提示。单击允许权限,然后按返回按钮继续。

接下来运行以下命令:
pkg upgradeTermux 中的 pkg upgrade 命令用于将所有已安装的软件包更新为最新可用版本。它可确保您的系统和应用程序保持最新,从而提高性能、安全性和与其他软件的兼容性。
执行过程中,你需要输入 Y 才能继续更新程序。

这里,只需按 Enter 即可继续。

更新完成后,我们将开始安装环境必要的软件包:
pkg install git cmake golang该命令会安装三个软件包:Git(版本控制系统)、CMake(构建系统)和 Go(Go 编程语言),让你能够管理源代码、构建软件以及使用 Go 进行开发。
完成后,将显示如下图所示:

5、编译和安装 Ollama
Ollama 是一个平台,旨在让开发人员更轻松地在自己的机器上本地运行 LLaMA 等大型语言模型 (LLM)。它提供了一个简化和优化的环境来管理、运行和与这些模型交互,专注于性能和可访问性。Ollama 简化了设置依赖项、优化硬件使用(例如 GPU 加速)和提供可供本地执行的预训练模型等任务。
我们将代码从 Ollama 的 GitHub 存储库拉到我们的本地机器:
git clone --depth 1 https://github.com/ollama/ollama.git执行后的结果。

接下来,导航到 ollama 文件夹并执行 Go 代码生成命令:
cd ollama
go generate ./...稍等片刻后,你就会看到:

接下来,将当前目录中的 Go 代码编译为可执行二进制文件。此命令获取目录中的所有 Go 源文件并创建可运行的编译二进制文件。
go build .然后我们在后台启动一个 Ollama 服务器:
./ollama serve &此命令在后台启动 Ollama 服务器(由于 &),使其能够处理请求而不会阻塞终端。服务器将继续运行,并且可以访问该服务器以与模型进行交互,同时终端可以自由执行其他命令。

此时,通过运行ls,我们可以看到ollama已经被创建为可执行文件。

6、运行 Llama 3.2
Ollama 为 Llama 3.2 提供多种原始和量化模型,包括 1b 和 3b 版本。默认为 4 位量化。你可以从这个链接中选择一个模型。
运行以下命令下载 Llama 3.2 3b 量化模型:
./ollama run llama3.2:3b --verbose--verbose 标志用于在模型执行期间启用详细日志记录。它是可选的,如果您不需要详细日志,可以省略。
下载过程中请耐心等待。

当你看到"发送消息"提示出现时,它就可以使用了。值得注意的是,Llama 3.2 3B 仍然可能对"9.11 和 9.9 哪个更大?"等逻辑问题提供错误答案。

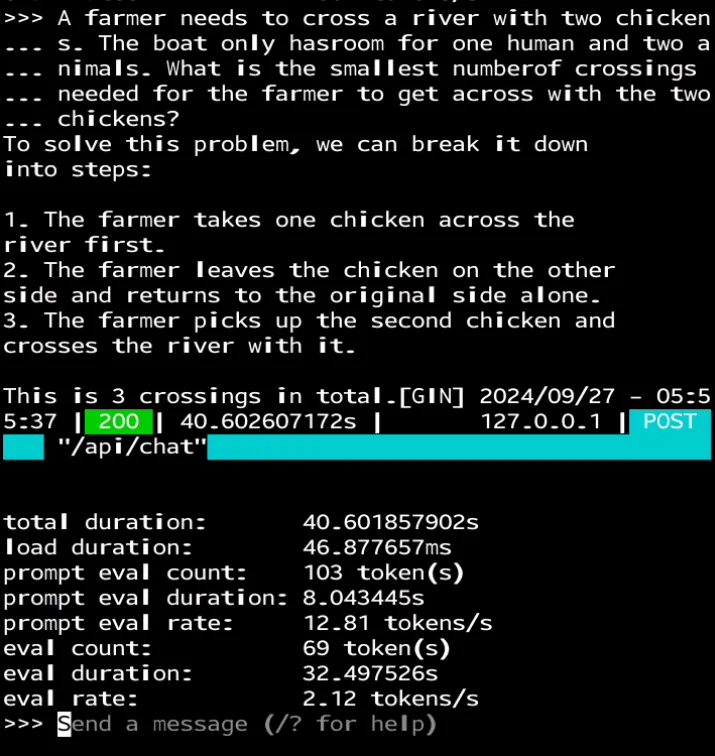
你可以使用 Ctrl+D 退出聊天终端。
如果你想终止响应过程,请按 Ctrl+C 停止生成响应。
如果发现响应速度太慢,你可以尝试使用 Llama 3.2 1B 型号,这将提高响应速度。
7、清理提示
你可能想要删除刚刚在主目录中创建的"go"文件夹。如果是这样,请按照以下方法操作:
chmod -R 700 ~/go
rm -r ~/go目前,termux 的 PATH 中没有 .local/bin(但你可以根据需要添加它)。如果您想将 ollama 二进制文件移动到 bin 文件夹,可以执行以下操作:
cp ollama/ollama /data/data/com.termux/files/usr/bin/现在,你可以直接在终端中运行 ollama!
8、结束语
总之,Llama 3.2 的发布标志着 AI 技术的一个重要里程碑,尤其是在其在移动设备上提供高性能的能力方面。凭借其多模式功能和轻量级模型,Llama 3.2 使开发人员能够创建优先考虑隐私和响应能力的设备应用程序。
本文演示了如何在 Android 设备上运行 Llama 3.2 的 1B 和 3B 版本,从安装 Termux 开始,然后设置必要的环境,编译 Ollama,最后在本地运行模型。能够直接在移动硬件上处理 AI 任务,即使是像三星 S21 Ultra 这样的老款机型,也凸显了现实世界应用程序的潜力,提供了一种安全高效的方式来利用 AI 的力量,而无需依赖云基础设施。
随着我们不断前进,在移动设备上本地运行这些复杂模型的能力可能会通过使高级 AI 更易于访问、更安全、更用户友好来彻底改变行业。