第5章 数据复制
- 目的:
- 地理位置更近,降低延迟
- 故障冗余
- 提高读吞吐量
- 主节点与从节点(主从复制)
- 主从复制:
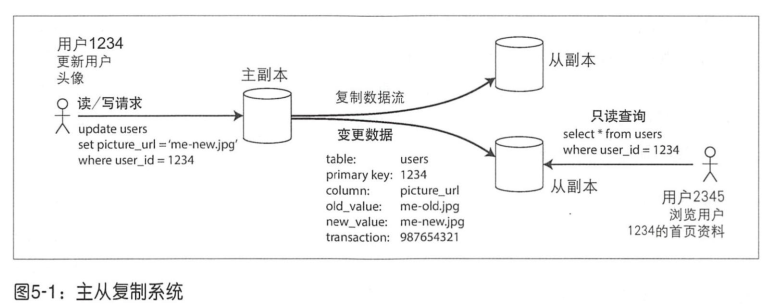
- 写请求发送给主节点,主节点将新数据写入本地存储;
- 主节点将数据更改作为复制的日志发送给从节点,从节点将其应用到本地,严格保持与主节点相同的写入顺序;
- 读请求主从节点均可;
- 同步复制:主节点需等待直到从节点确认完成了写入,然后才会向用户报告完成,并且将最新的写入对其他客户端可见
- 半同步:只有一个从节点是同步的,其他均为异步,若同步从节点不可用,提升其他从节点同步
- 异步复制:主节点发送完消息之后立即返回,不用等待从节点的完成确认
- 配置新的从节点:
- 主节点产生一个一致性快照;
- 将快照拷贝到从节点;
- 从节点连接到主节点并请求快照点之后所发生的数据更改日志;
- 从节点追赶快照点之后的数据变更;
- 节点失效
- 从节点失效:追赶式恢复
- 从节点本地磁盘保存了故障前最后一笔事务,连接到主节点请求该事务后所有数据变更
- 主节点失效:节点切换
- 确认主节点失效:心跳超时
- 选举新的主节点:共识问题
- 重新配置系统使其生效
- 问题:
- 异步复制:原主节点恢复后尝试继续同步,需要丢弃****原主节点上未完成复制的写请求
- 如果有其他系统依赖数据库的内容,那么丢弃方案不可行
- 脑裂:强制关闭其中一个节点
- 超时设置越长,恢复越长;超时设置越短,导致不必要的切换
- 从节点失效:追赶式恢复
- 复制日志的实现
- 基于SQL语句的复制,但是有一些非确定的函数需要转为确定
- 基于预写日志(WAL)传输
- 日志结构存储引擎(SSTables、LSM-trees),日志段在后台压缩并支持垃圾回收
- 覆盖写磁盘的B-tree,每次修改会预先写入日志,用于崩溃恢复
- 基于行的逻辑日志复制,binlog
- 基于触发器的复制,当发生写事务时,将数据更改记录到另一个表中,然后外部处理逻辑访问该表,实施必要的自定义应用层逻辑,例如将数据更改复制到另一个系统
- 主从复制:
- 复制滞后问题
- 最终一致性
- 写后读一致性:
- 用户访问可能被修改的内容(自己的主页),从主节点读
- 跟踪最近更新时间,小于一分钟则从主节点读;监控从节点的滞后程度,避免读滞后时间超过一分钟的从节点
- 客户端请求记录最近更新的时间戳(需要设备一致),与副本数据比较
- 单调读一致性(进行多次读取,不会出现数据回滚的情况):
- 基于用户ID进行哈希,读取固定的副本
- 前缀一致读(分片数据库常见,不存在全局写入顺序):
- 确保任何具有因果顺序关系的写入都交给一个分片
- 多主节点复制
- 场景
- 每个数据中心内,采用一主多从
- 离线客户端,一个设备就是数据中心
- 协作编辑
- 处理写冲突:
- 同步或异步进行冲突检测
- 避免冲突:将用户的请求总是路由到特定的数据中心
- 收敛于一致状态:基于时间戳,最后写入者获胜
- 自定义应用层代码来解决冲突
- 拓扑结构
- MySQL:环形拓扑,在修复故障前会影响其他节点之间的日志转发
- 场景
- 无主节点复制
- 读修复:每个数据都有版本号,读多个副本,更新旧值所在副本
- 反熵:后台线程将缺少的数据从一个副本复制到另一个副本
- 读写quorum:w+r>n,如果有n个副本,写入需要w个节点确认,读取必须至少查询r个节点,从而保证读取到新值
- 监控旧值
- 并发写(如果两个操作并不需要意识到对方):每个主键维护一个版本号,写之前要求读,然后进行写合并;项目在删除时不能简单地从数据库中删除,系统必须保留一个对应的版本号 以恰当的标记该项目需要在合并时被剔除 。这种删除标记被称为墓碑
- 版本向量:比较副本状态
第6章 数据分区
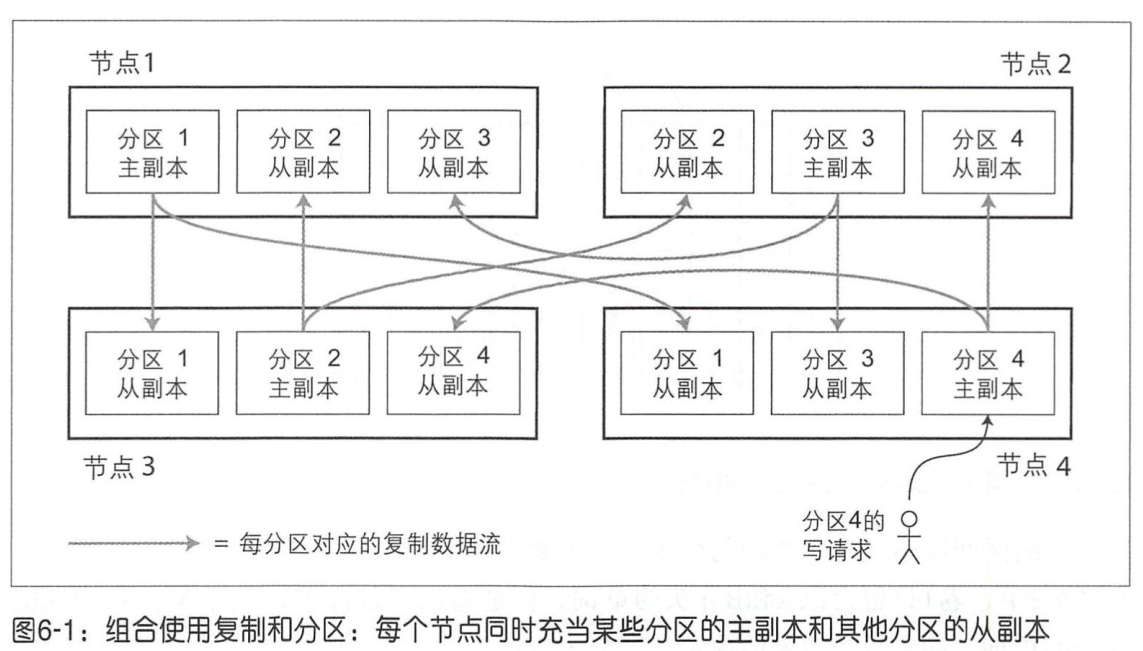
- 数据分区与数据复制
- k-v数据分区
- 基于关键字区间分区:每个分区分配连续的关键字,辅以前缀
- 基于关键字哈希值分区:缺点是区间查询失去了原有的有序相邻的特性
- 负载倾斜与热点:key加随机数,分配到不同分区
- 分区与二级索引
- 基于文档分区的二级索引:每个分区类似有个类似倒排的索引
- 基于词条的二级索引分区:相同属性放在同一分区
- 分区再平衡
- 不取模,而是将哈希值划分为不同的区间范围,因为节点数量变化会导致重新迁移
- 固定数量的分区:新加入节点承担其他节点上的分区
- 动态分区:类似于b-tree的合并分裂操作
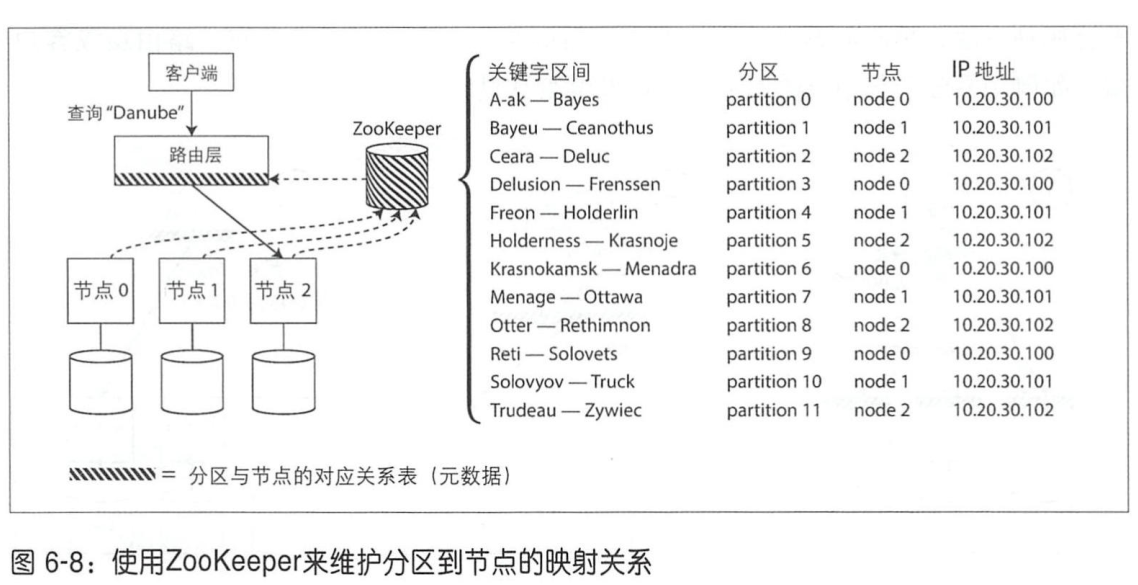
- 请求路由
第7章 事务
todo
第8章 分布式系统的挑战
- 故障与部分失效
- 需要在不可靠的组件之上构建可靠的系统
- 不可靠的网络
- 超时机制,但是数据包到达时间并没有上确界;最佳实践:根据最新的响应分布来自动调整
- 网络是动态分配带宽的,缺点是存在排队,优点是最大限度利用带宽
- 不可靠的时钟
- 墙上时钟:若远远快于NTP(网络时间协议)服务器,强行重置之后会跳回到先前的某个时间点
- 单调时钟:NTP会运行本地时钟加快或减慢,而不会回拨
- 最后写入获胜策略(LWW)需要额外的因果关系跟踪机制(版本向量)来防止因果冲突
- 时钟漂移:取决于机器的温度
- 将时钟读数视为带有置信区间的时间范围,google spanner在提交读写事务之前故意等待置信区间的长度,避免区间重叠
- 进程暂停:GC
- 当使用锁和租约机制来保护资源的并发访问时,客户端除了得到锁还要获取令牌(单调增),资源本身必须主动检查所持令牌信息,如果发现已经处理过更高令牌的请求,要拒绝持有低令牌的所有写请求
- 拜占庭将军问题:在不信任的环境中达成共识
- 校验和
- 检查输入
- 使用多台NTP服务器
第9章 一致性与共识
- 一致性保证
- 最终一致性意味着"收敛",即预期所有的副本最终会收敛到相同的值
- 可线性化(强一致性)
- 一旦新值被写入或读取,所有后续的读都看到的是最新的值,直到被再次覆盖
- 线性化违例之所以被注意到,是因为系统中存在其他的通信渠道
- 实现
- 主从复制(前提是从主节点或者同步更新的从节点读)
- 共识算法
- CAP:网络分区情况下,选择一致还是可用
- 不适用多核-内存一致性模型:性能考虑
- 原子广播(满足可靠发送、严格有序)
- 基于异步模型:保证消息以固定顺序可靠地发送,但不保证消息合适发送成功(消息按照相同的顺序发送到所有节点,有且只有一次)
- 分布式事务与共识
- 原子提交
- 单节点:先写入数据,再提交log
- 多节点:通过补偿性事务将已提交事务抵消
- 两阶段提交(2PC)
- phase1:协调者发送一个准备请求到所有节点
- phase2:如果所有节点都准备好提交,那么协调者发出提交请求(将提交或中止请求落日志,避免协调者崩溃),提交开始实际执行
- XA交易:异构环境下实施两阶段提交的一个工业标准
- 主节点:世代编号(term)
- 如果由于网络故障切断了节点之间的连接,则只有多数节点所在的分区可以继续工作,剩下的少数节点分区则处于事实上的停顿状态
- Raft已被发现存在不合理的边界条件处理: 如果整个网络中存在某一条网络连接持续不可靠,Raft会进入一种奇怪的状态:它不断在两个节点之间反复切换主节点,当前主节点不断被赶下台,这最终导致系统根本无法安心提供服务
- ZAB:
- CAS实现加锁,带有一个到期的租约
- 采用了对所有操作执行全局排序,然后为每个操作都赋予一个单调递增的事务ID(zxid)和版本号(eversion)
- 客户端与zk互发心跳
- 客户端watch
- 原子提交