目录
[3.de-nosing auto-encoder](#3.de-nosing auto-encoder)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是auto-encoder相关概念及运作流程和auto-encoder的优势,简单了解了de-nosing auto-encoder并与BERT进行对比。
1.auto-encoder概念
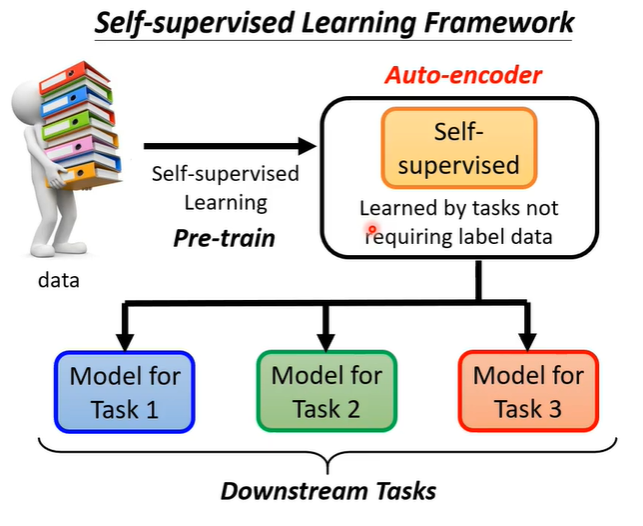
auto-encoder也算是self-supervised learning的一环,简单复习一下self-supervised learning。我们有大量没标注的资料,用这些资料可以训练一个模型(BRET可以做填空题,GPT系列可以预测下一个token),之后可以把这个模型用在下游任务中。在BERT和GPT之前,有一个同样不需要标注资料的任务,就是auto-encoder。
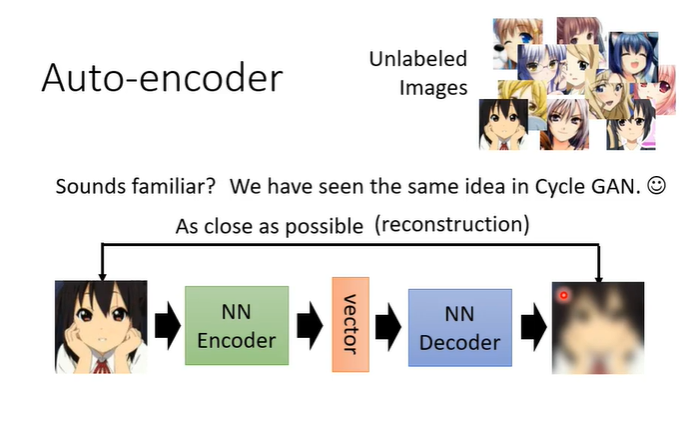
用影像举例,假设有大量的图片在auto-encoder中,在auto-encoder有两个network,一个encoder,一个decoder。encoder将一张图片读进来输出一个向量,即encoder将图片变成一个向量,这个向量再作为decoder的输入,decoder会产生一张图片,训练的目标是encoder的输入与decoder的输出越接近越好。这个概念与cycle GAN有些类似。
2.auto-encoder优势
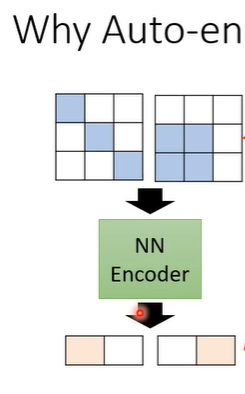
假设一个3x3的图片变为2维的向量,再还原。那么怎么样从9个数值变为2个数值,再还原为9个数值呢?因为对于影像来说不是所有3x3的矩阵都是图片,图片的变化是有限的,虽然图片是3x3但是实际上他的变化可能只有2种类型。
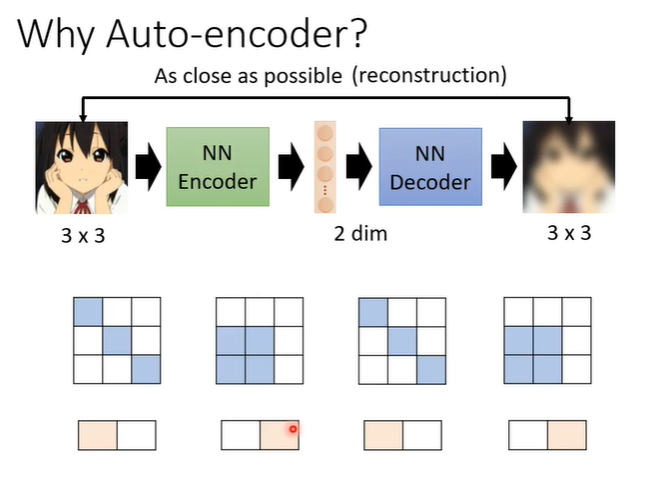
当我们把一个高维度的图片变成低维度的向量时,只要找出它有限的变化,就可以把本来复杂的东西用比较简单的方法来表示。如果可以把复杂的图片用简单的方法表示,那在下游任务中就只需要较少的训练资料,就可以让机器学到本来要它学的事情。
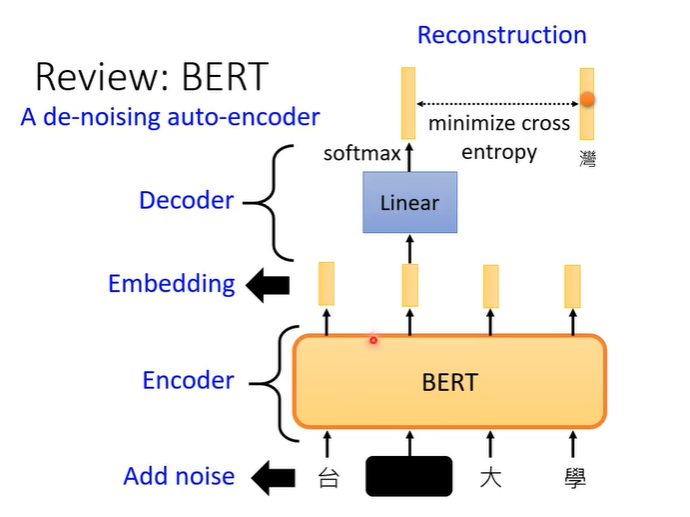
3.de-nosing auto-encoder
de-nosing auto-encoder是auto-encoder的一个变形,它把原来输入的图片加上一些杂讯,之后一样通过encoder变为向量,再通过decoder把他还原回来,但是要还原的不是encoder的输入而是加入杂讯前的图片。这样就多了一个任务,除了还原图片之外,还需要自己学会如何去除杂讯。
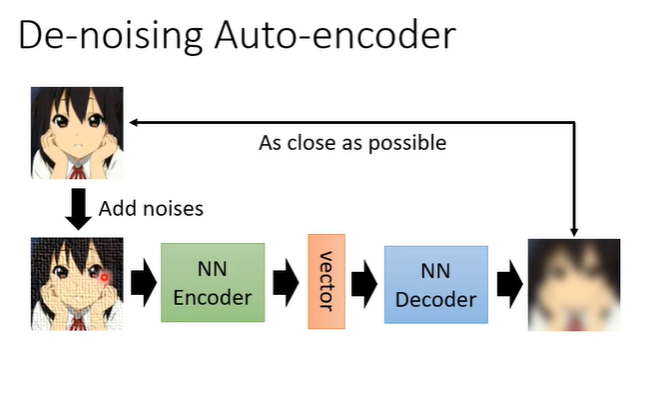
其实今天的BERT也可以看作是de-nosing auto-encoder。输入我们会加mask,那些mask就是noise,BERT的模型就是encoder,输出就是embedding,接下来linear 的模型就是decoder,它要做的就是还原原来的句子,也就是把原来被盖住的部分还原。