1.Hystrix / Sentinel
●服务雪崩场景
自己即是服务消费者,同时也是服务提供者,同步调用等待结果导致资源耗尽
●解决方案
服务方:扩容、限流,排查代码问题,增加硬件监控
消费方:使用Hystrix资源隔离,熔断降级,快速失败
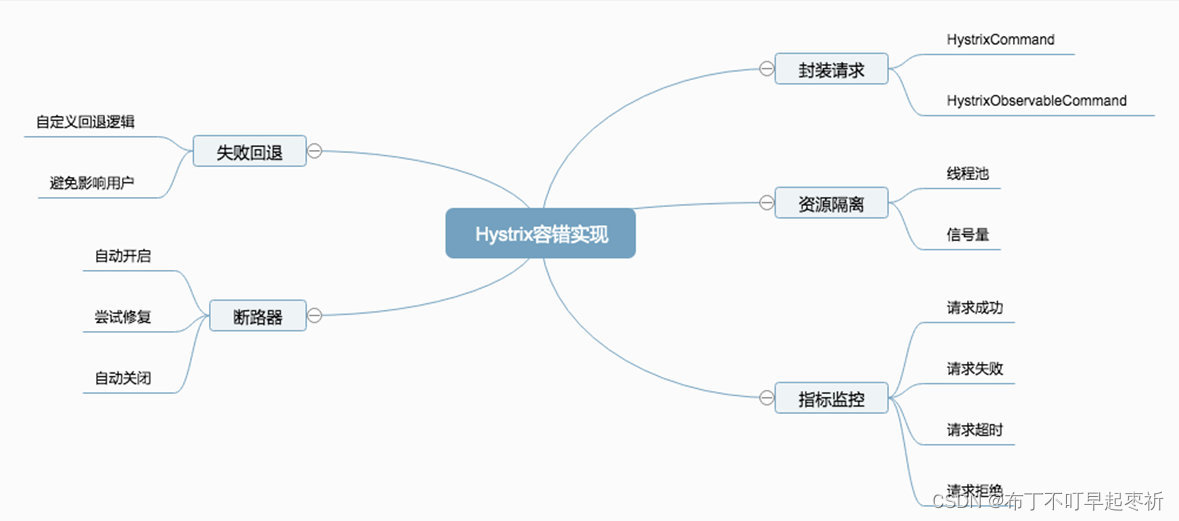
●Hystrix断路保护器的作用
✮封装请求会将用户的操作进行统一封装,统一封装的目的在于进行统一控制。
✮资源隔离限流会将对应的资源按照指定的类型进行隔离,比如线程池和信号量。
⁰计数器限流,例如5秒内技术1000请求,超数后限流,未超数重新计数
⁰滑动窗口限流,解决计数器不够精确的问题,把一个窗口拆分多滚动窗口
⁰令牌桶限流,类似景区售票,售票的速度是固定的,拿到令牌才能去处理请求
⁰漏桶限流,生产者消费者模型,实现了恒定速度处理请求,能够绝对防止突发流量
●失败回退其实是一个备用的方案,就是说当请求失败后,有没有备用方案来满足这个请求的需求。
●断路器这个是最核心的,如果断路器处于打开的状态,那么所有请求都将失败,执行回退逻辑。如果断路器处于关闭状态,那么请求将会被正常执行。有些场景我们需要手动打开断路器强制降级。
●指标监控会对请求的生命周期进行监控,请求成功、失败、超时、拒绝等状态,都会被监控起来。
★Hystrix使用上遇到的坑
●配置可以对接配置中心进行动态调整
Hystrix 的配置项非常多,如果不对接配置中心,所有的配置只能在代码里修改,在集群部署的难以应对紧急情况,我们项目只设置一个 CommandKey,其他的都在配置中心进行指定,紧急情况如需隔离部分请求时,只需在配置中心进行修改以后,强制更新即可。
●回退逻辑中可以手动埋点或者通过输出日志进行告警
当请求失败或者超时,会执行回退逻辑,如果有大量的回退,则证明某些服务出问题了,这个时候我们可以在回退的逻辑中进行埋点操作,上报数据给监控系统,也可以输出回退的日志,统一由日志收集的程序去进行处理,这些方式都可以将问题暴露出去,然后通过实时数据分析进行告警操作
●用 ThreadLocal配合线程池隔离模式需当心
当我们用了线程池隔离模式的时候,被隔离的方法会包装成一个 Command 丢入到独立的线程池中进行执行,这个时候就是从 A 线程切换到了 B 线程,ThreadLocal 的数据就会丢失
●Gateway中多用信号量隔离
网关是所有请求的入口,路由的服务数量会很多,几十个到上百个都有可能,如果用线程池隔离,那么需要创建上百个独立的线程池,开销太大,用信号量隔离开销就小很多,还能起到限流的作用。
★Sentinel
Sentinel是⼀个⾯向云原⽣微服务的流量控制、熔断降级组件。
替代Hystrix,针对问题:服务雪崩、服务降级、服务熔断、服务限流
★Hystrix区别:
●独⽴可部署Dashboard(基于 Spring Boot 开发)控制台组件
●不依赖任何框架/库,减少代码开发,通过UI界⾯配置即可完成细粒度控制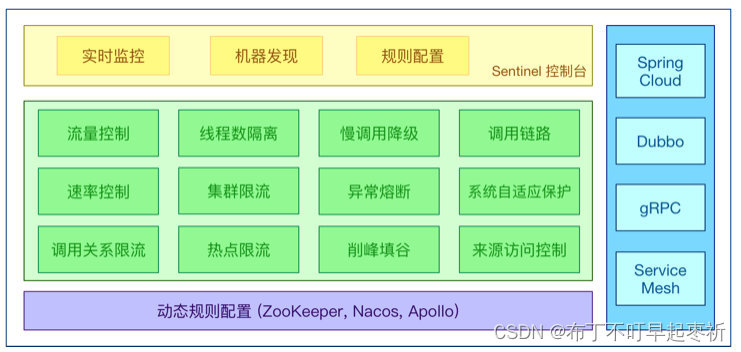
●丰富的应⽤场景:Sentinel 承接了阿⾥巴巴近 10 年的双⼗⼀⼤促流量的核⼼场景,例如秒杀、消息削峰填⾕、集群流量控制、实时熔断下游不可⽤应⽤等。
●完备的实时监控:可以看到500 台以下规模的集群的汇总也可以看到单机的秒级数据。
●⼴泛的开源⽣态:与 SpringCloud、Dubbo的整合。您只需要引⼊相应的依赖并进⾏简单的配置即可快速地接⼊ Sentinel。
★区别:
●Sentinel不会像Hystrix那样放过⼀个请求尝试⾃我修复,就是明明确确按照时间窗⼝来,熔断触发后,时间窗⼝内拒绝请求,时间窗⼝后就恢复。
●Sentinel Dashboard中添加的规则数据存储在内存,微服务停掉规则数据就消失,在⽣产环境下不合适。可以将Sentinel规则数据持久化到Nacos配置中⼼,让微服务从Nacos获取。
2.Config / Nacos
Nacos是阿⾥巴巴开源的⼀个针对微服务架构中服务发现、配置管理和服务管理平台。
Nacos就是注册中⼼+配置中⼼的组合(Nacos=Eureka+Confifig+Bus)
★Nacos功能特性
●服务发现与健康检查
●动态配置管理
●动态DNS服务
●服务和元数据管理
★保护阈值:
当服务A健康实例数/总实例数 < 保护阈值 的时候,说明健康实例真的不多了,这个时候保护阈值会被触发(状态true),nacos将会把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费者可能访问到不健康的实例,请求失败,但这样也⽐造成雪崩要好,牺牲了⼀些请求,保证了整个系统的⼀个可⽤。
★Nacos 数据模型(领域模型)
●Namespace 代表不同的环境,如开发dev、测试test、⽣产环境prod
●Group 代表某项⽬,⽐如爪哇云项⽬
●Service 某个项⽬中具体xxx服务
●DataId 某个项⽬中具体的xxx配置⽂件
可以通过 Spring Cloud 原⽣注解 @RefreshScope 实现配置⾃动更新
3.Bus / Stream
Spring Cloud Stream 消息驱动组件帮助我们更快速,更⽅便的去构建消息驱动微服务的
本质:屏蔽掉了底层不同MQ消息中间件之间的差异,统⼀了MQ的编程模型,降低了学习、开发、维护MQ的成本,⽬前⽀持Rabbit、Kafka两种消息
4.Sleuth / Zipkin
全链路追踪
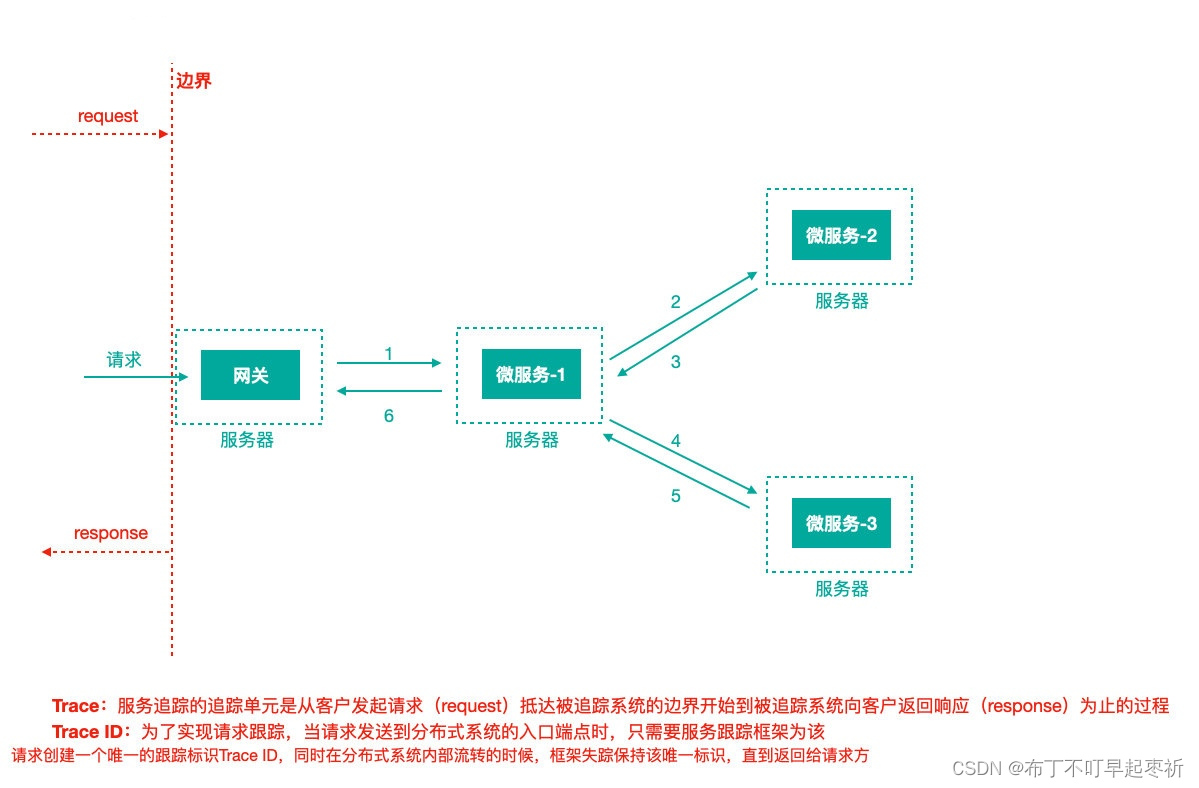
●Trace ID:当请求发送到分布式系统的⼊⼝端点时,Sleuth为该请求创建⼀个唯⼀的跟踪标识Trace ID,在分布式系统内部流转的时候,框架始终保持该唯⼀标识,直到返回给请求⽅
●Span ID:为了统计各处理单元的时间延迟,当请求到达各个服务组件时,也是通过⼀个唯⼀标识SpanID来标记它的开始,具体过程以及结束。
●Spring Cloud Sleuth (追踪服务框架)可以追踪服务之间的调⽤,Sleuth可以记录⼀个服务请求经过哪些服务、服务处理时⻓等,根据这些,我们能够理清各微服务间的调⽤关系及进⾏问题追踪分析。
●耗时分析:通过 Sleuth 了解采样请求的耗时,分析服务性能问题(哪些服务调⽤⽐较耗时)
●链路优化:发现频繁调⽤的服务,针对性优化等
●聚合展示:数据信息发送给 Zipkin 进⾏聚合,利⽤ Zipkin 存储并展示数据。