今天学习UA,user-agent
User-Agent 即用户代理,简称"UA",它是一个特殊字符串头。网站服务器通过识别 "UA"来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
绝大多数网站都具备一定的反爬能力。今天要讲解的 User-Agent 就是反爬策略的第一步。
网站通过识别请求头中 User-Agent 信息来判断是否是爬虫访问网站。如果是,网站首先对该 IP 进行预警,对其进行重点监控,当发现该 IP 超过规定时间内的访问次数, 将在一段时间内禁止其再次访问网站。
常见的 User-Agent 请求头,如下所示:
| 系统 | 浏览器 | User-Agent字符串 |
|---|---|---|
| Mac | Chrome | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36 |
| Mac | Firefox | Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0 |
| Mac | Safari | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15 |
| Windows | Edge | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763 |
| Windows | IE | Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko |
| Windows | Chrome | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36 |
| iOS | Chrome | Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/31.0.1650.18 Mobile/11B554a Safari/8536.25 |
| iOS | Safari | Mozilla/5.0 (iPhone; CPU iPhone OS 8_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12F70 Safari/600.1.4 |
| Android | Chrome | Mozilla/5.0 (Linux; Android 4.2.1; M040 Build/JOP40D) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.59 Mobile Safari/537.36 |
| Android | Webkit | Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; M351 Build/KTU84P) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30 |
| [常见的 User-Agent 汇总表] |
下面,通过向 HTTP 测试网站(httpbin.org)发送 GET 请求来查看请求头信息,从而获取爬虫程序的 UA。代码如下所示:
#导入模块
import urllib.request
#向网站发送get请求
response=urllib.request.urlopen('http://httpbin.org/get')
html = response.read().decode()
print(html)结果如下所示:
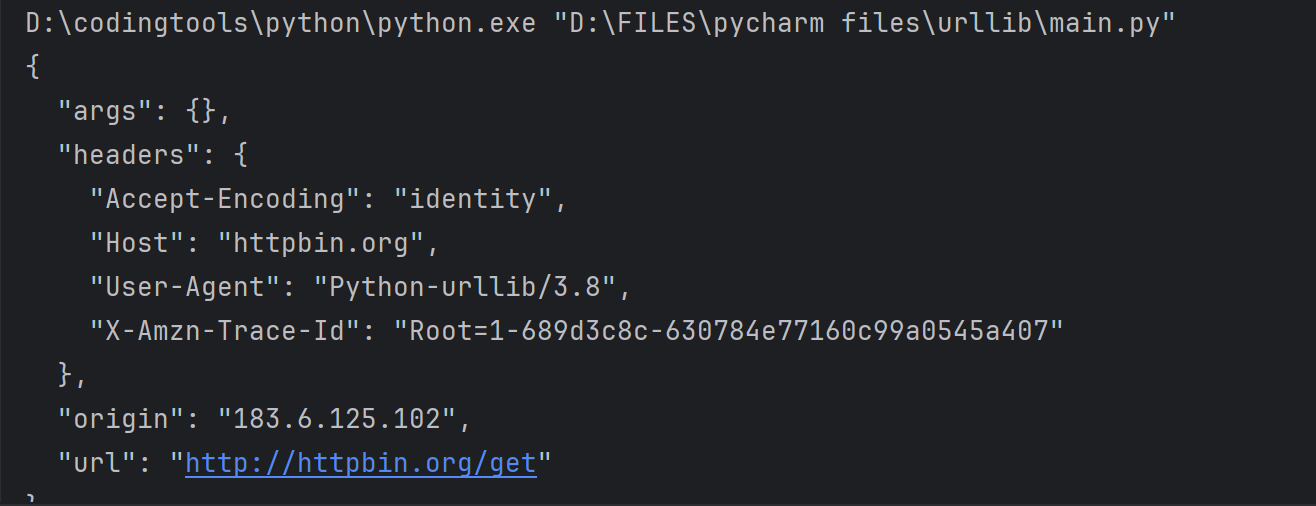
注意:httpbin.org这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、IP、headers 和登录验证等,且支持 GET、POST 等多种方法,对 Web 开发和测试很有帮助。
重构爬虫UA信息
下面使用urllib.request.Request()方法重构 User-Agent 信息
from urllib import request
# 定义变量:URL 与 headers
url = 'http://httpbin.org/get' #向测试网站发送请求
#重构请求头,伪装成 Mac火狐浏览器访问,可以使用上表中任意浏览器的UA信息
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0'}
# 1、创建请求对象,包装ua信息
req = request.Request(url=url,headers=headers)
# 2、发送请求,获取响应对象
res = request.urlopen(req)
# 3、提取响应内容
html = res.read().decode('utf-8')
print(html)结果如下所示:
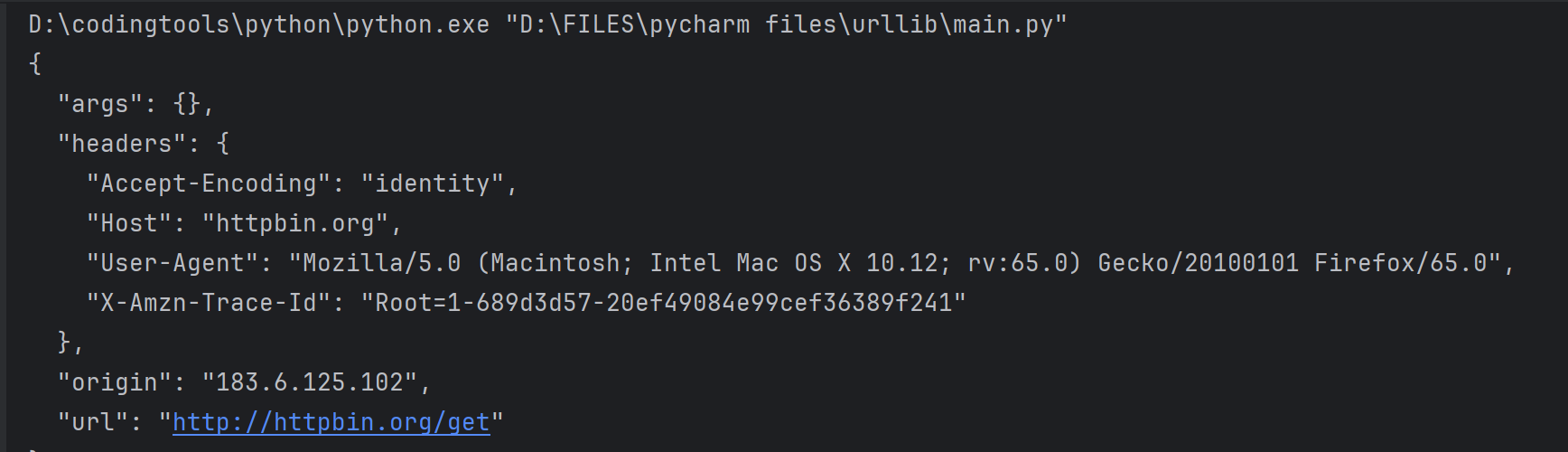
自定义UA代理池
当然也可以构建一个ua信息池
在编写爬虫程序时,一般都会构建一个 User-Agent (用户代理)池,就是把多个浏览器的 UA 信息放进列表中,然后再从中随机选择。构建用户代理池,能够避免总是使用一个 UA 来访问网站,因为短时间内总使用一个 UA 高频率访问的网站,可能会引起网站的警觉,从而封杀掉 IP。
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
' Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
' Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]也可以使用专门第三方的模块来随机获取浏览器 UA 信息,不过该模块需要单独安装。
URL编码/解码详解
当 URL 路径或者查询参数中,带有中文或者特殊字符的时候,就需要对 URL 进行编码(采用十六进制编码格式)。URL 编码的原则是使用安全字符去表示那些不安全的字符。
URL基本组成
URL 是由一些简单的组件构成,比如协议、域名、端口号、路径和查询字符串等,示例如下:
http://www.biancheng.net/index?param=1路径和查询字符串之间使用问号?隔开。上述示例的域名为 www.biancheng.net,路径为 index,查询字符串为 param=1。
URL 中规定了一些具有特殊意义的字符,常被用来分隔两个不同的 URL 组件,这些字符被称为保留字符。例如:
- 冒号:用于分隔协议和主机组件,斜杠用于分隔主机和路径
?:用于分隔路径和查询参数等。=用于表示查询参数中的键值对。&符号用于分隔查询多个键值对。
哪些字符需要编码
URL 之所以需要编码,是因为 URL 中的某些字符会引起歧义,比如 URL 查询参数中包含了"&"或者"%"就会造成服务器解析错误;再比如,URL 的编码格式采用的是 ASCII 码而非 Unicode 格式,这表明 URL 中不允许包含任何非 ASCII 字符(比如中文),否则就会造成 URL 解析错误。
| 字符 | 含义 | 十六进制值编码 |
|---|---|---|
| + | URL 中 + 号表示空格 | %2B |
| 空格 | URL中的空格可以编码为 + 号或者 %20 | %20 |
| / | 分隔目录和子目录 | %2F |
| ? | 分隔实际的 URL 和参数 | %3F |
| % | 指定特殊字符 | %25 |
| # | 表示书签 | %23 |
| & | URL 中指定的参数间的分隔符 | %26 |
| = | URL 中指定参数的值 | %3D |
| [URL特殊字符编码] |
Python实现编码与解码
Python 的标准库urllib.parse模块中提供了用来编码和解码的方法,分别是 urlencode() 与 unquote() 方法。
| 方法 | 说明 |
|---|---|
| urlencode() | 该方法实现了对 url 地址的编码操作 |
| unquote() | 该方法将编码后的 url 地址进行还原,被称为解码 |
1) 编码urlencode()
下面以百度搜索为例进行讲解。首先打开百度首页,在搜索框中输入"爬虫",然后点击"百度一下"。当搜索结果显示后,此时地址栏的 URL 信息,如下所示:
可以看出 URL 中有很多的查询字符串,而第一个查询字符串就是"wd=爬虫",其中 wd 表示查询字符串的键,而"爬虫"则代表您输入的值。
下面编写爬虫程序对 "wd=爬虫"进行编码,如下所示:
#导入parse模块
from urllib import parse
#构建查询字符串字典
query_string = {
'wd' : '爬虫'
}
#调用parse模块的urlencode()进行编码
result = parse.urlencode(query_string)
#使用format函数格式化字符串,拼接url地址
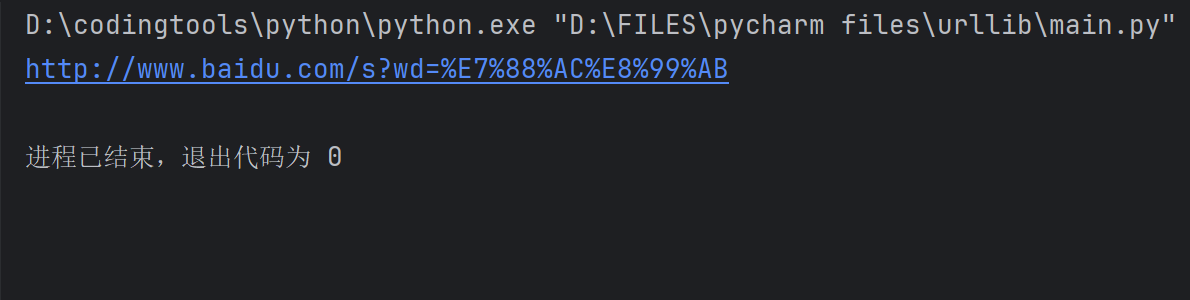
url = 'http://www.baidu.com/s?{}'.format(result)
print(url)结果如下所示:
除了使用 urlencode() 方法之外,也可以使用 quote(string) 方法实现编码,代码如下:
from urllib import parse
#注意url的书写格式,和 urlencode存在不同
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入要搜索的内容:')
#quote()只能对字符串进行编码
query_string = parse.quote(word)
print(url.format(query_string))输出结果如下:
输入:请输入要搜索的内容:编程帮www.biancheng.net
输出:http://www.baidu.com/s?wd=%E7%BC%96%E7%A8%8B%E5%B8%AEwww.biancheng.net注意:quote() 只能对字符串编码,而 urlencode() 可以直接对查询字符串字典进行编码。因此在定义 URL 时,需要注意两者之间的差异。方法如下:
# urllib.parse
urllib.parse.urlencode({'key':'value'}) #字典
urllib.parse.quote(string) #字符串解码unquote(string)
解码是对编码后的 URL 进行还原的一种操作,示例代码如下:
from urllib import parse
string = '%E7%88%AC%E8%99%AB'
result = parse.unquote(string)
print(result)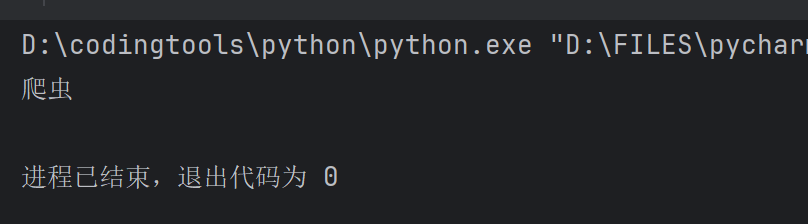
URL地址拼接方式
最后,给大家介绍三种拼接 URL 地址的方法。除了使用 format() 函数外,还可以使用字符串相加,以及字符串占位符,总结如下:
# 1、字符串相加
baseurl = 'http://www.baidu.com/s?'
params='wd=%E7%88%AC%E8%99%AB'
url = baseurl + params
# 2、字符串格式化(占位符)
params='wd=%E7%88%AC%E8%99%AB'
url = 'http://www.baidu.com/s?%s'% params
# 3、format()方法
url = 'http://www.baidu.com/s?{}'
params='wd=%E7%88%AC%E8%99%AB'
url = url.format(params)