在 Kubernetes 集群中部署 Apache Spark,需要你具备对 Kubernetes 的工作原理、Spark 的架构以及云原生应用的理解。
前期准备工作
在进行 Spark 的部署之前,需要对你的 Kubernetes 环境做好充分的准备。这包括 Kubernetes 集群的搭建以及基础工具的安装,比如 kubectl 和 Helm 等。这些步骤对于成功部署 Spark 至关重要。
假设你已经有了一个 Kubernetes 集群。如果没有,你可以使用 Minikube 来创建一个本地的集群,或者选择 AWS EKS、Azure AKS、Google GKE 等云服务来提供的 Kubernetes 集群服务。
以下是一些关键的准备步骤:
-
设置 Kubernetes 集群 :
为了在 Kubernetes 集群上部署 Spark,首先你需要一个稳定的 Kubernetes 环境。对于本地测试,你可以选择 Minikube,它非常适合本地开发和测试。对于生产环境,你可以选择使用公共云平台的 Kubernetes 服务,如 Google Kubernetes Engine (GKE) 或 Amazon Elastic Kubernetes Service (EKS)。
例如,使用 Minikube 创建 Kubernetes 集群:
bashminikube start --memory=4096 --cpus=4这个命令会启动一个本地 Kubernetes 集群,并分配 4GB 的内存和 4 个 CPU 以支持 Spark 应用的运行。
-
安装 Kubernetes 工具 :
确保你已经安装了
kubectl(用于与 Kubernetes 集群通信的命令行工具)和 Helm(Kubernetes 的包管理工具)。这些工具会帮助你管理集群和部署应用。例如,可以使用如下命令安装 Helm:
bash
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash通过 Helm,你可以快速安装和配置 Spark 以及其他工具。
-
配置 Docker 镜像 :
Kubernetes 使用容器化应用程序,因此你需要确保 Spark 可以作为 Docker 容器运行。Apache Spark 的官方 Docker 镜像可以直接从 Docker Hub 获取,也可以自定义构建自己的镜像。
例如,从 Docker Hub 拉取 Spark 镜像:
bash
docker pull bitnami/spark:latest
如果你需要修改 Spark 的配置,可以基于这个官方镜像构建你自己的 Docker 镜像。
创建 Spark 配置文件
在 Kubernetes 中部署 Spark 时,通常需要定义多个配置文件来描述资源和服务。这些文件包括 Spark 的 Deployment、Service,以及其他 Kubernetes 资源的 YAML 文件。具体来说,以下几个配置文件非常关键:
- Spark Master 和 Worker 的 Deployment 配置:
Spark 集群由 Master 和 Worker 节点组成。Master 节点负责管理 Worker 节点,分发任务并收集结果。需要在 Kubernetes 中分别创建 Master 和 Worker 的 Deployment 配置。
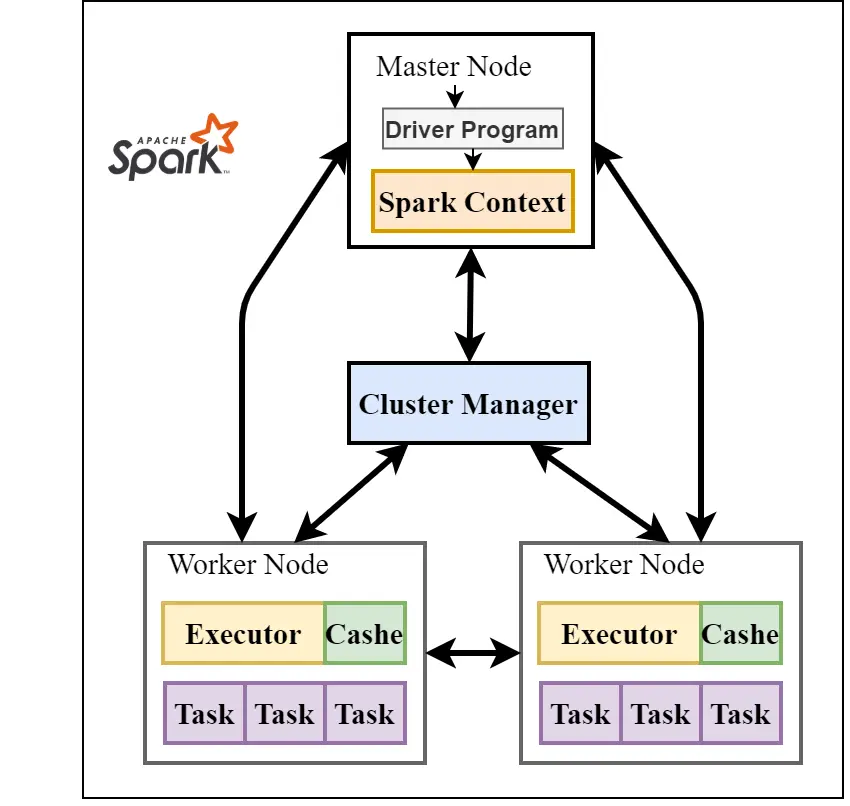
一个简单的 Spark Master Deployment YAML 文件如下:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-master
labels:
app: spark
role: master
spec:
replicas: 1
selector:
matchLabels:
app: spark
role: master
template:
metadata:
labels:
app: spark
role: master
spec:
containers:
- name: spark-master
image: bitnami/spark:latest
ports:
- containerPort: 7077
- containerPort: 8080
env:
- name: SPARK_MODE
value: master
在这个配置中,我们指定了使用 Bitnami 提供的 Spark Docker 镜像,并设置了 Master 的工作模式。
- Spark Worker 的 Deployment 配置 :
与 Master 类似,Worker 节点的 Deployment 配置如下:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-worker
labels:
app: spark
role: worker
spec:
replicas: 2
selector:
matchLabels:
app: spark
role: worker
template:
metadata:
labels:
app: spark
role: worker
spec:
containers:
- name: spark-worker
image: bitnami/spark:latest
ports:
- containerPort: 8081
env:
- name: SPARK_MODE
value: worker
- name: SPARK_MASTER_URL
value: spark://spark-master:7077
在这个配置文件中,SPARK_MASTER_URL 用于指向 Master 的位置。Worker 会与 Master 进行通信,以获取任务并执行。
- Service 配置 :
为了让集群内部和外部的应用程序可以访问 Spark Master 和 Worker,通常需要为它们创建 Service 资源。一个典型的 Spark Master 的 Service 配置如下:
yaml
apiVersion: v1
kind: Service
metadata:
name: spark-master
labels:
app: spark
role: master
spec:
type: LoadBalancer
ports:
- port: 7077
targetPort: 7077
- port: 8080
targetPort: 8080
selector:
app: spark
role: master这个 Service 使用 LoadBalancer 类型来确保外部可以访问 Spark Master 的 UI 界面。
部署 Spark 到 Kubernetes
准备好上述配置文件后,你可以使用 kubectl 命令将这些资源部署到 Kubernetes 集群中。
- 部署 Master 和 Worker :
使用以下命令分别部署 Spark Master 和 Worker:
bash
kubectl apply -f spark-master-deployment.yaml
kubectl apply -f spark-worker-deployment.yaml这些命令会创建 Master 和 Worker 的 Pod,并确保它们能够在 Kubernetes 集群中正常运行。
- 部署 Service :
接下来,创建 Service 以便让 Spark 集群对外部服务开放:
bash
kubectl apply -f spark-master-service.yaml通过这个 Service,你可以访问 Spark Master 的 Web UI,查看集群的运行状态和 Worker 的信息。
提交 Spark 作业到 Kubernetes 集群
Spark 任务的执行可以通过 Spark 提交工具 spark-submit 来完成。在 Kubernetes 环境中,可以直接使用带有 Kubernetes 支持的 Spark 镜像来提交作业。
例如,使用以下命令提交一个简单的 Spark 作业:
bash
spark-submit \
--master k8s://https://<kubernetes-master-url>:<port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=3 \
--conf spark.kubernetes.container.image=bitnami/spark:latest \
local:///opt/spark/examples/jars/spark-examples_2.12-3.0.1.jar在这个例子中,我们使用 spark-submit 命令来提交 Spark 作业,并指定使用 Kubernetes 集群作为 Master。--conf spark.kubernetes.container.image 用于指定作业运行时使用的 Docker 镜像。这个命令会在 Kubernetes 集群中启动一个 Spark Driver Pod,Driver 会进一步启动 Executor Pods 来执行计算任务。
真实案例:数据分析平台的部署
为了帮助理解,可以看一个真实的应用场景:一家大型电商公司需要构建一个实时的数据分析平台来监控用户行为和销售数据。他们选择使用 Spark 来实现数据处理,并使用 Kubernetes 管理他们的 Spark 集群。以下是该公司如何实现这一目标的案例:
- 需求分析:公司需要对网站的实时访问数据进行处理,以便对用户行为进行分析。Spark 被选中用于数据处理,因为它支持大规模数据并行处理,能够很好地处理电商平台的日志数据。
- Kubernetes 的选择:为了实现灵活的资源管理和自动扩展,公司决定将 Spark 部署在 Kubernetes 集群中。Kubernetes 提供了强大的调度和集群管理功能,能够动态地分配资源,并根据负载自动扩展 Worker 节点的数量。
- 部署过程:公司首先准备了 Kubernetes 集群,并使用 Helm Charts 部署了 Spark。通过 Helm,部署过程被大大简化,他们只需调整一些配置参数,比如 Spark 运行的 Executor 数量和资源限制。
- 作业提交与监控 :团队通过 Spark 的 Web UI 监控集群的状态,确保所有 Worker 都处于活跃状态。然后,他们通过
spark-submit提交了一个流式数据处理作业,这个作业从 Kafka 读取实时数据,并进行清洗、聚合,最终将结果存储到 Elasticsearch 中以供分析。 - 扩展性和弹性:在双十一大促期间,用户访问量激增,公司通过 Kubernetes 轻松地增加了 Spark Worker 节点的数量,以确保处理能力能够应对高峰流量。Kubernetes 的弹性伸缩功能在这一场景下发挥了关键作用。
这个案例展示了在 Kubernetes 中部署 Spark 的灵活性和可扩展性。使用 Kubernetes 的好处是,你可以很容易地扩展 Spark 的 Worker 数量来应对峰值流量,而且 Kubernetes 还提供了健壮的容错机制,确保集群的高可用性。
部署中的挑战和解决方法
在 Kubernetes 中部署 Spark,除了基本的配置外,还可能遇到一些挑战。例如,网络通信、资源调度和存储系统的集成等问题。这些挑战可以通过以下方法解决:
-
网络配置 :
Spark 需要 Master 与 Worker 之间的网络通信。为了保证网络的连通性,可以使用 Kubernetes 的
NetworkPolicy来控制 Pod 之间的通信。此外,确保 Kubernetes 集群中的所有节点都可以访问 Spark 的 Master 和 Worker。在某些云环境中,可能需要配置额外的安全组或防火墙规则,以确保集群内外的访问正常。比如,在 AWS 环境中,需要对 Spark Master 的 LoadBalancer 开放 7077 和 8080 端口,以便 Worker 和用户能够访问。
-
资源调度 :
Spark 的 Executor 和 Driver 都需要一定的计算资源。如果 Kubernetes 集群中的资源不够,可能会导致作业失败或性能下降。因此,在提交作业时,可以通过
--conf参数来为 Spark 任务设置适当的 CPU 和内存限制。例如,可以使用如下配置来限制 Executor 使用的资源:
bash
--conf spark.executor.memory=2g \
--conf spark.executor.cores=1通过为每个 Executor 分配合适的内存和 CPU,能够保证资源的高效利用,并避免某个节点因为资源不足而导致的任务失败。
-
数据存储与持久化 :
Spark 通常需要从外部存储系统读取数据,比如 HDFS、S3 或 Google Cloud Storage。在 Kubernetes 中部署 Spark 时,可以通过 Kubernetes 的 PersistentVolume 和 PersistentVolumeClaim 来持久化数据。
例如,如果你的数据存储在 AWS S3 上,可以在 Spark 的配置中加入访问凭证,以便 Spark 可以直接从 S3 读取数据:
bash
--conf spark.hadoop.fs.s3a.access.key=YOUR_ACCESS_KEY \
--conf spark.hadoop.fs.s3a.secret.key=YOUR_SECRET_KEY这种方式让 Kubernetes 中的 Spark 可以无缝地与云存储服务集成,使数据处理变得更加方便和高效。
总结与思考
在 Kubernetes 中部署 Spark,可以充分利用 Kubernetes 的容器编排和自动扩展能力,让 Spark 集群能够根据工作负载动态调整。这个过程虽然涉及多个复杂的步骤,但 Kubernetes 的工具链(如 Helm、kubectl 等)以及 Spark 提供的 Kubernetes 集成特性,使得整体部署流程相对顺畅。
通过真实案例的讲解,我们看到 Kubernetes 和 Spark 的结合为大型电商公司提供了强大的数据处理能力。在实际生产中,这种架构不仅可以应对实时数据处理需求,还可以为未来的业务增长提供充足的扩展空间。
如果你正在考虑将 Spark 部署到 Kubernetes 集群中,可以从本地集群(例如 Minikube)开始,熟悉基本的部署和管理流程。一旦你掌握了这些技能,就可以将它们应用到更复杂的生产环境中,例如在公共云上运行的 Kubernetes 集群,通过自动化工具和脚本,进一步优化 Spark 的部署和管理。