由上海人工智能实验室(上海AI实验室)、中国科学院深圳先进技术研究院、中国科学院大学、香港大学、复旦大学、南京大学计算机软件新技术国家重点实验室联合提出的多模态大模型视频理解能力基准MVBench ,入选本届CVPR Highlight论文名单。
联合团队在题为《MVBench: A Comprehensive Multi-modal Video Understanding Benchmark》的论文中提出的MVBench,由20项复杂视频任务组成,用于全面评测现有多模态模型的视频理解能力。同时,基于对已有多模态模型的缺陷分析,提出了更强大的基线模型VideoChat2。所有代码、模型权重、训练数据、评测数据均已开源。

论文链接:
https://arxiv.org/pdf/2311.17005
开源链接:
https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat2
在线demo体验:
评测数据集:
https://huggingface.co/datasets/OpenGVLab/MVBench
指令微调数据:
https://huggingface.co/datasets/OpenGVLab/VideoChat2-IT
模型实时排行榜:
https://huggingface.co/spaces/OpenGVLab/MVBench_Leaderboard
当前,多模态大模型能力评测存在多种方式:
-
人类直接评测。被视作最直接有效的方法,被多模态竞技场(Multi-Modality Arena)所使用,但评测效率较低,且难以避免认知偏差,评判过程难以实现完全公平。
-
借助大语言模型评测。此类方式更加公正,但需要大语言模型拥有贴近人类的强大性能,且需要精心设计评价Prompt。
-
传统问答评价方式。如Multiple-Choice QA,但传统数据集往往侧重角度单一,无法较为全面地评价、诊断对话模型的能力。
近期的图像对话模型评测研究,倾向于从不同的感知和认知角度,考察模型多种能力,并基于不同的能力设计评测任务,再通过人工采集、标定数据。最后使用Multiple-Choice QA的方式,计算不同任务的准确率。
基于以上现状,联合团队认为使用传统问答评价方式,能够更加全面、科学地实现评测。如何确定合适的评测任务成为本次研究重点。
MVBench
时间理解任务(Temporal Task Definition)
通过比较图像和视频任务的本质区别,联合团队确定了一种简单可扩展的方案,即首先总结基本的图像评测任务,再由这些任务出发,构建无法通过单帧有效解决的视频任务。
研究人员从MME、MMBench等图像基准中里总结上述9项空间理解任务,并延伸出20项时间理解任务。如下图所示:
 MVBench包含的所有时间理解任务
MVBench包含的所有时间理解任务
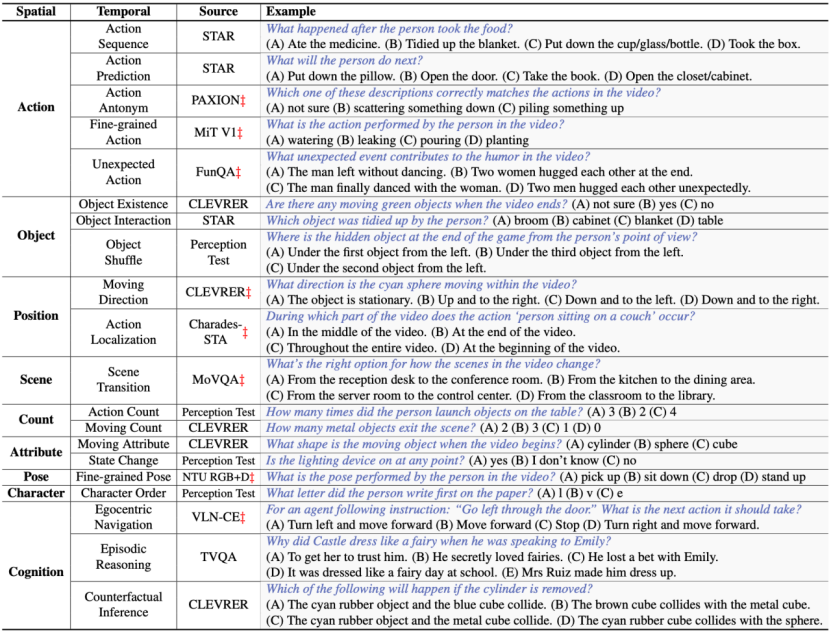 20项时间理解任务举例
20项时间理解任务举例
自动问答生成(Automatic QA Generation)
制定评测数据成为定义评测任务后的另一项关键点。联合团队收集了多个开源的视频数据集,利用开源的高质量数据标注,设计了一套评测数据自动生成流水线(Pipeline)。
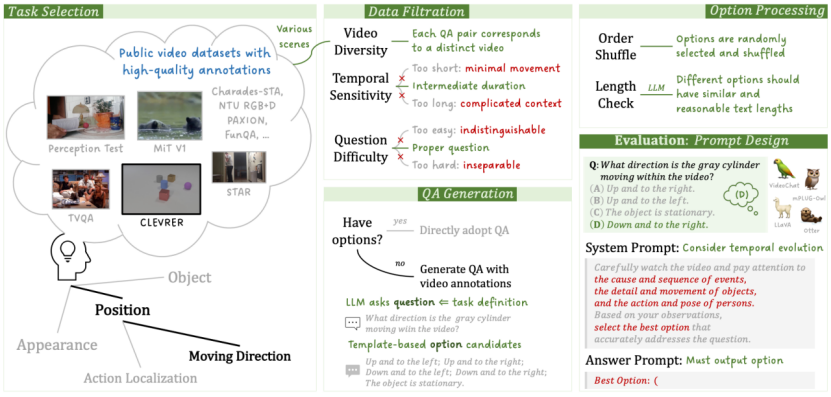 评测数据自动生成流水线
评测数据自动生成流水线
基于模型面临的实际任务,联合团队遵循以下原则进行了数据过滤,构成了当前MVBench中的评测数据:
l 视频多样性。对不同的视频设计独立的问题;
l 时序敏感性。提取取每个数据集中合适的视频长度,过短的视频往往动作幅度较小,而过长的视频包含过于复杂的上下文,问题过难会导致无法区分不同模型的能力;
l 问题复杂度。采用难度适中的问题,包括添加条件限制、粗略时间段定位等问题修饰。
针对多选题的问题及选项生成,在已有数据集中多选问答的基础上,由ChatGPT等大模型生成,生成方式基于以下原则:
l 问题方面,基于ChatGPT任务的定义,生成3-5个对应的问题随机选其一;
l 选项方面,设计出两种策略:
(a)基于模版的构造,设计固定的选项模版,结合GT匹配生成;
(b)基于,将原有数据集中的问答输入ChatGPT,使ChatGPT生成新的问题以及选项。
针对具体任务,联合团队采用了如下图所示的不同处理方式:
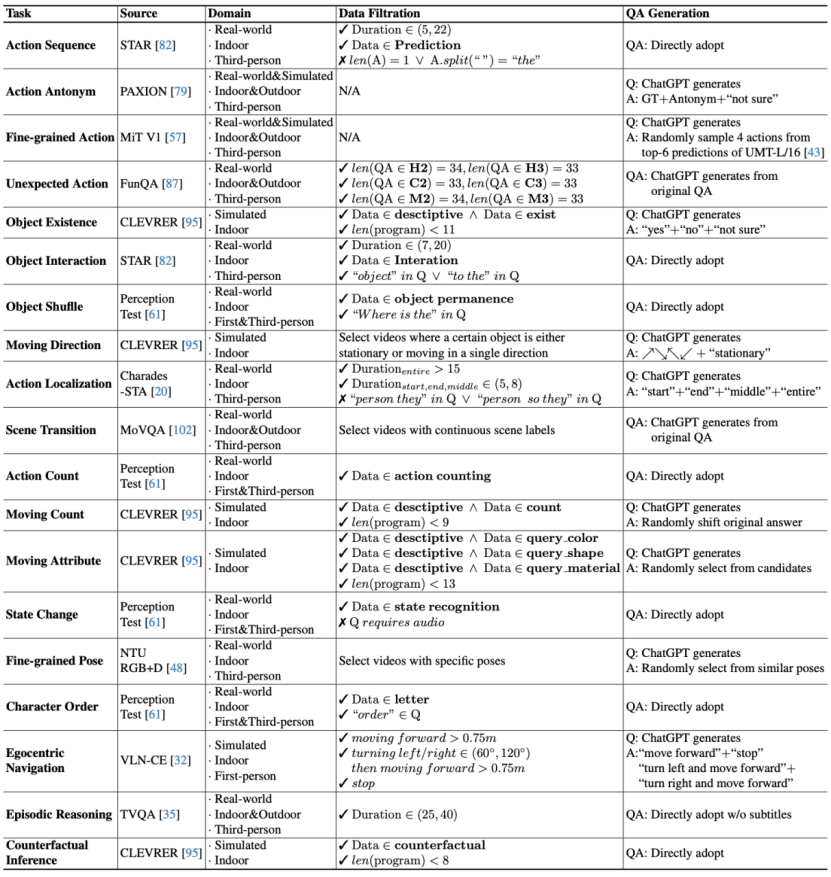 具体任务的不同处理方式
具体任务的不同处理方式
多选题的问题和选项生成后,联合团队对选项进行了随机打乱,并检查不同选项的长度,避免答案过长导致"答案泄露"。对过长的选项再由大模型重新改写。
通过以上方式,每个任务自动获得了200条问答,并得到4000条数据用于高效评测。
评测提示词设计(Prompt Design for Evaluation)
联合团队设计了合理的系统提示词(System Prompt)和高效的答案提示词(Answer Prompt),其中系统提示词用于激发模型的时间理解能力。
针对对话模型难以直接输出选项的现状,联合团队通过构造带括号"()"的选项,控制对话模型输出的起始字符"Best Option: (",即答案提示词。实验结果显示,此方法可以保证模型直接输出选项,同时能够提高答案的准确率。
VideoChat2
联合团队在MVBench上评测了部分当前主流的图像和视频对话模型,结果显示,模型性能普遍差强人意。具体存在两大缺陷:
l 缺乏多样的指令微调数据:由于视频数据难以标注,开源的指令微调数据规模较小;
l 缺乏强视频编码器:普遍基于多模态图像编码器CLIP-ViT进行时序改良,难以本质地处理时序理解。
针对上述缺陷,联合团队设计了新的指令微调数据和模型架构。
借鉴了InstructBLIP、M3IT思路,研究人员从现有的图像和视频数据集中转化出了1.9M统一形式的指令微调数据。
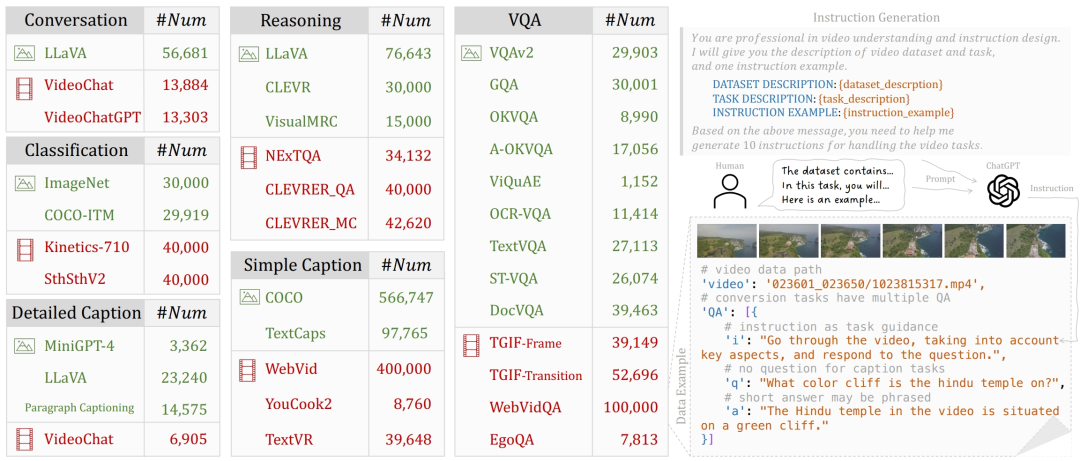 1.9M指令微调数据
1.9M指令微调数据
对于模型架构,研究人员采用了BLIP2结构,并基于强多模态视频编码器UMT,设计了渐进式跨模态训练流程。在第一阶段将冻结的视觉编码器和QFormer对齐,用于将冗余的视频信息压缩;第二阶段打开视觉编码器,并引入冻结的LLM,使用VTG损失进行视觉文本链接;最后阶段,使用1.9M指令微调数据,并在模型中插入LoRA模块进行高效微调。
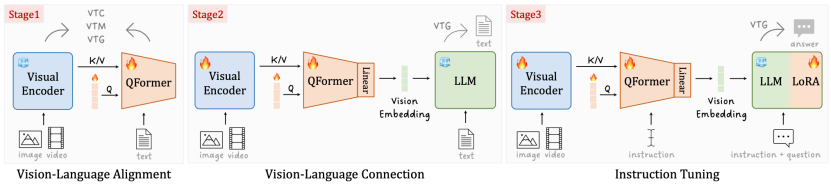 渐进式跨模态训练流程
渐进式跨模态训练流程
基于MVBench的评测结果(Experiments)
部分开源对话模型评测

结果显示,部分开源对话模型在MVBench的时序理解任务表现不佳,图像对话模型LLaVA和视频对话模型VideoChat,相比随机的27.7%准确率提高不足9%。而基线模型VideoChat2相比此前较强模型,评分提升近15%。
GPT-4V评测

完整榜单
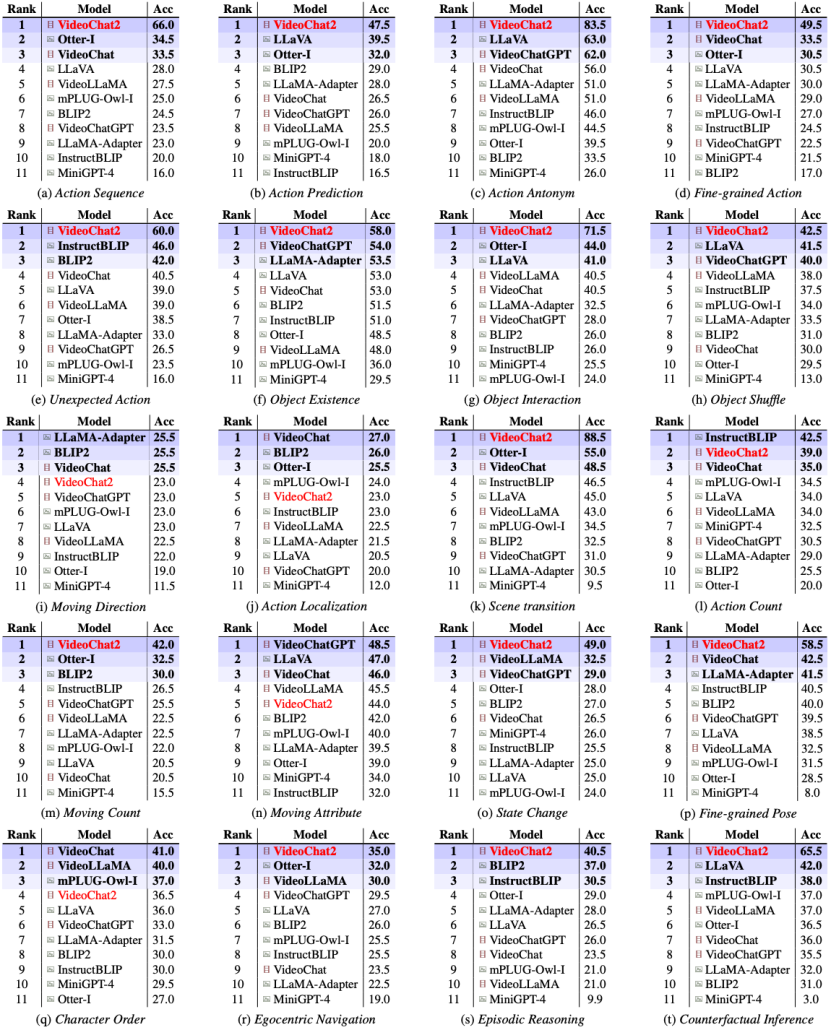
VideoChat2在15个任务上取得了最佳性能表现,但在处理移动方向、动作定位、计数等任务上仍有不足。
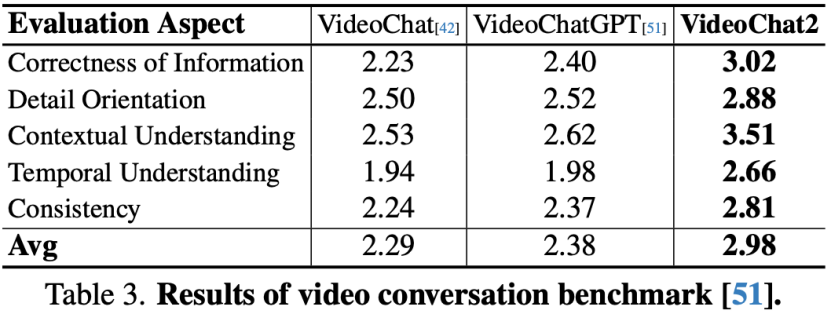
VideoChatGPT对话基准评测
零样本传统QA
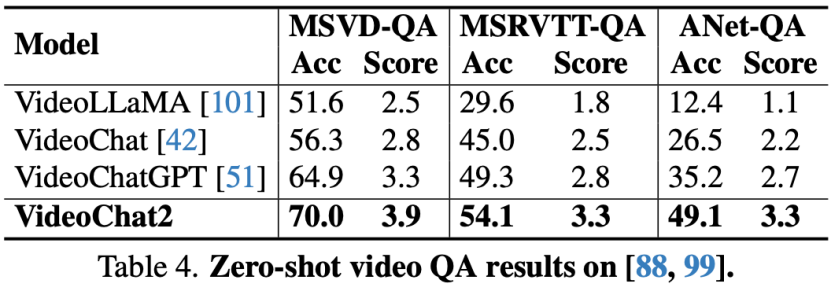
视频问答推理
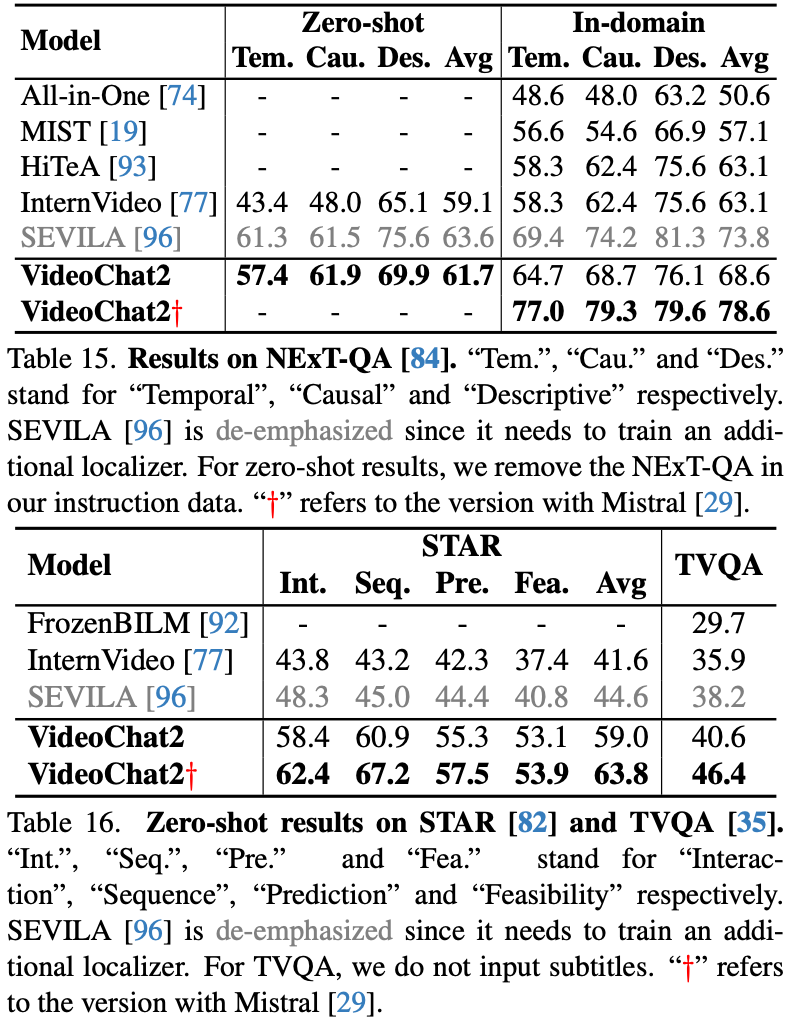
消融实验
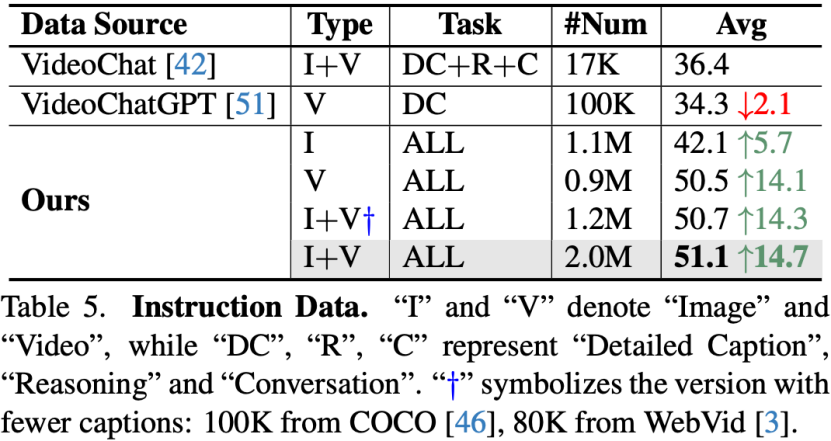
指令微调数据
在指令微调数据上的实验表明,更多样的指令数据、图像视频联合训练,可提升模型性能。
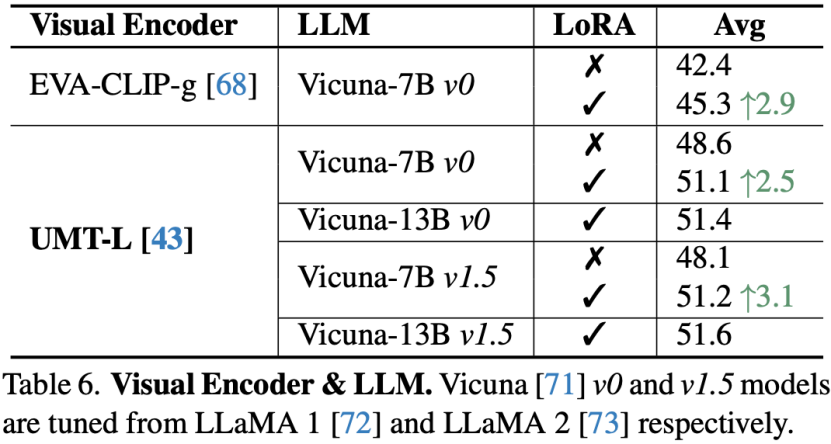
模型结构
在模型结构上的实验表明,使用强视频编码器相比图像编码器,性能提升显著。LoRA微调对于对话模型能力的提升十分关键。
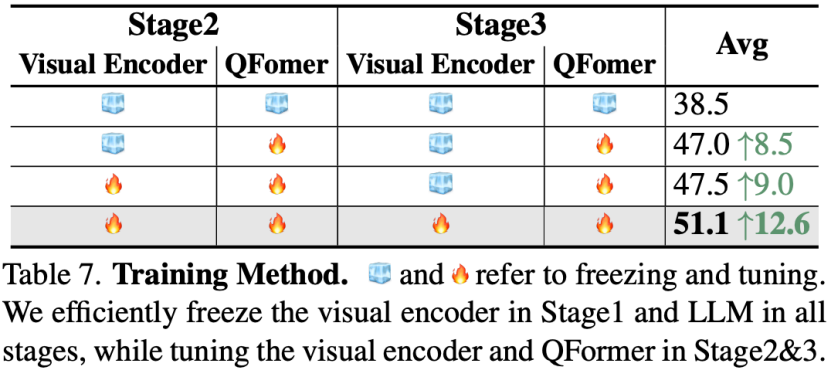
训练方式
联合团队探索了不同的冻结训练方式,结果表明,在第二第三阶段,均打开视觉编码器和QFormer效果最好。

使用精心设计的系统提示词,能较好地激发模型的时序理解能力。

使用简单的答案提示词,可保证输出选项,同时显著提升答案准确率。
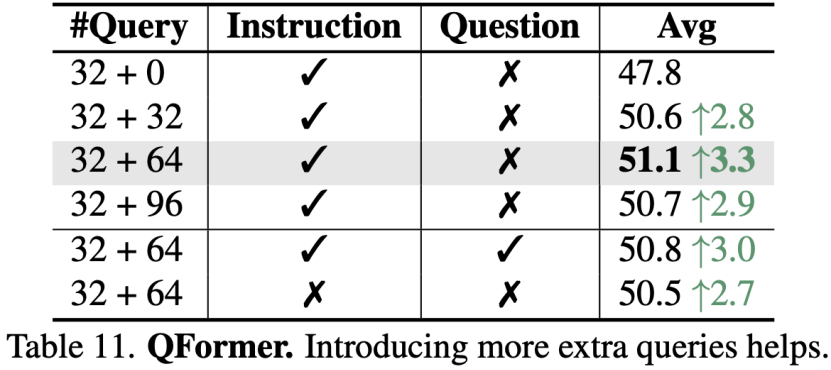
对于QFormer,在第二第三阶段引入了额外可学习的Token,用于和大模型对齐,结果显示,额外引入64个Token效果最佳。
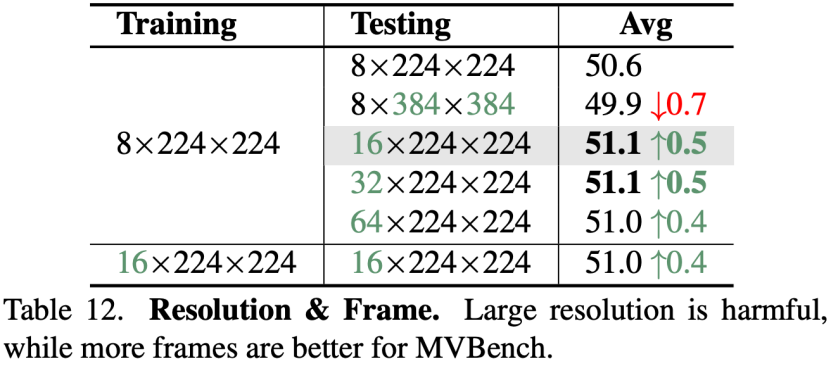
对于训练和测试输入,实验表明,训练阶段使用8帧,测试阶段使用16帧效果较好,训练开销也较小。但使用大分辨率在MVBench上并没有提升,侧面验证了MVBench更依赖于模型的时序理解能力。
定性结果
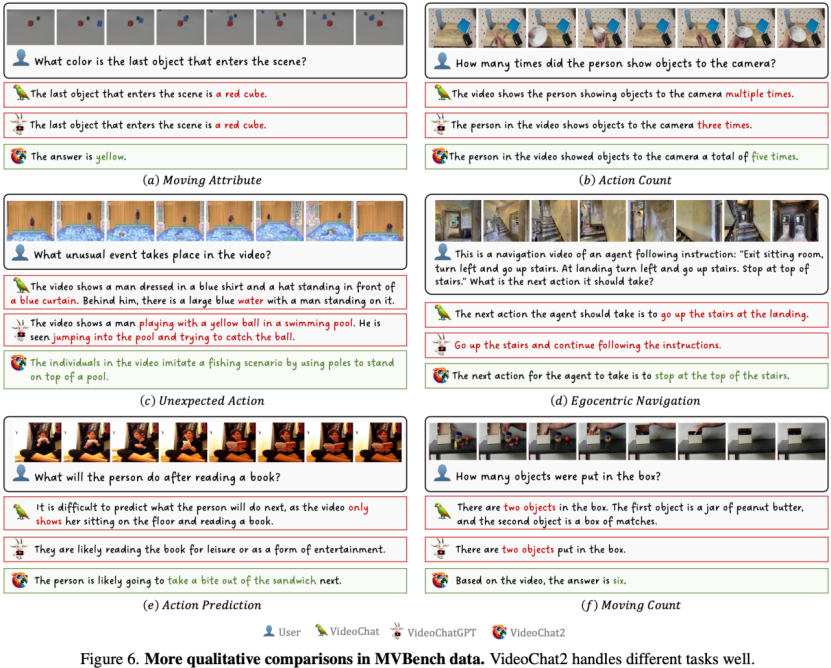
MVBench结果可视化
