摘要:本文撰写自阿里云研发工程师李俊睿(昕程),主要介绍 Flink 1.20 版本中引入了批作业在 JM failover 后的进度恢复功能。主要分为以下四个内容:
- 背景
- 解决思路
- 使用效果
- 如何启用
一、背景
在 Flink 1.20 版本之前,如果 Flink 的 JobMaster(JM)发生故障导致被终止,将会发生如下两种情况:
-
如果作业未启用高可用性(HA),作业将失败。
-
如果作业启用了 HA,JM 会被自动重新拉起 (JM failover)。在这种情况下,流作业将从最后一个成功的检查点恢复。然而,批作业由于缺乏检查点机制,将不得不从头开始运行,导 致之前的所有进度丢失。这对于需要长时间运行的批作业来说,意味着巨大的回退。
为了解决这一问题,我们在 Flink 1.20 版本中引入了批作业在 JM failover 后的进度恢复功能。这一功能的目的是使批作业在 JM failover 后能够尽可能地恢复到出错前的进度,避免重新运行已完成
的任务。
二、解决思路
为了实现这一目标,我们需要能够将 JM 的状态持久化到外部存储,从而在 JM 发生 failover 后,Flink 能够利用这些状态信息恢复作业到之前的运行进度。
我们设计了一种基于事件的 JM 状态恢复机制,在作业正常运行时,JM 会将状态变更事件写入外部持久化存储,以确保在 JM failover 后仍能获得作业的执行进度。此外,我们还需要解决 JM failover 后实际作业状态与状态变更事件可能不一致的问题。例如,某些 TaskManager (TM)在运行过程中意外丢失,可能导致中间数据结果无法访问。因此,Flink 必须从 TM 和 Remote Shuffle Service (RSS)获取中间结果数据的信息,来对作业运行进度的恢复结果进行校准。
该功能的整体流程分为如下几个阶段:
-
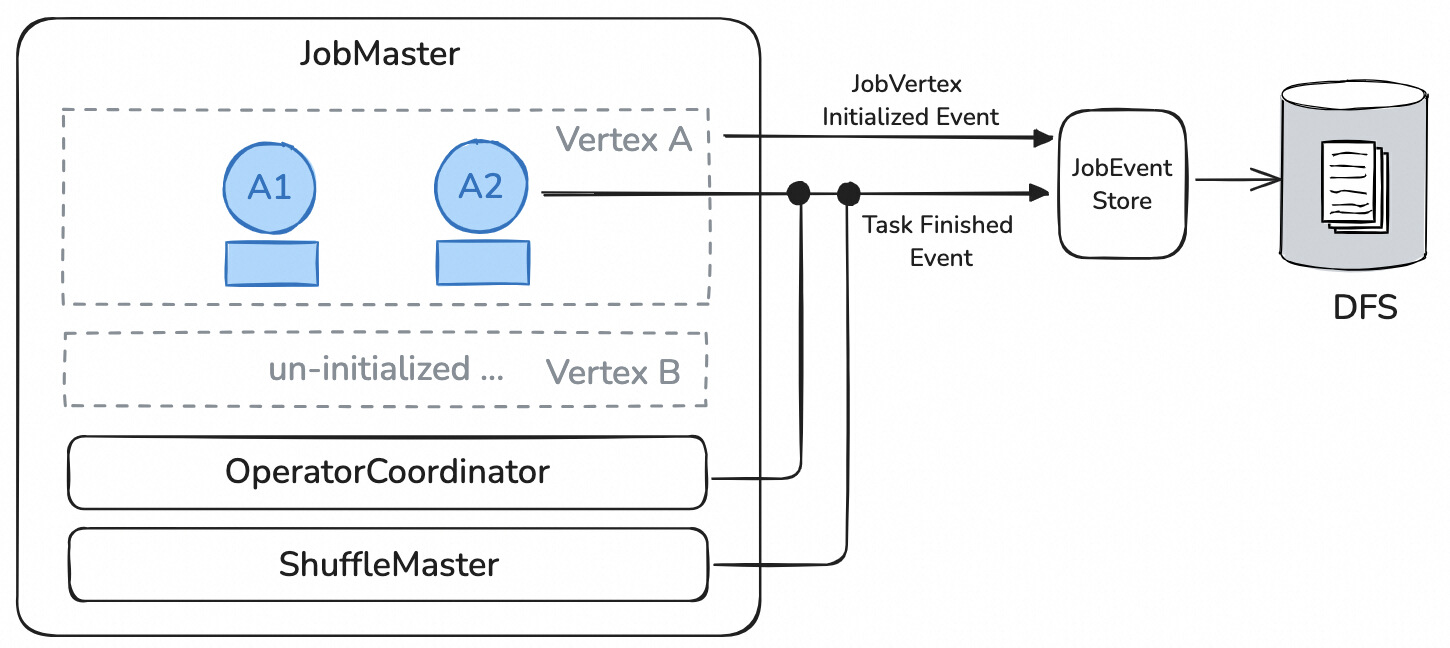
作业执行时 我们引入了 JobEventStore 组件,该组件负责在作业正常运行期间将 JM 的状态变更事件写入到外部文件系统中。其中需要被写入的状态变更事件分为如下以下几类:
(1)自适应执行计划优化:Flink 会自适应地优化批作业的执行计划,这些优化结果是基于上游的执行结果来确定的。如果每次都依赖上游的执行结果进行重建,将会产生较大的开销。因此,记录这些优化结果对于任务调度和容错非常重要。
(2)已经结束的 Task 信息:保存已完成任务的执行进度,以便在恢复作业时能够准确地继续从上次执行的位置开始。
(3)OperatorCoordinator 状态:OperatorCoordinator 负责协调算子,实行算子之间的通信,其状态与数据一致性密切相关。例如,SourceCoordinator 中包含记录哪些数据分片已经分发的状态信息。重建该组件的状态有助于保证数据的一致性。
(4)ShuffleMaster 状态:Flink 目前支持 RSS,而 RSS 的 Shuffle Master 可能会保存一些状态信息,如 Shuffle 数据的元数据。为了使新的 JobManager 能够复用这些中间结果,恢复 Shuffle Master 的状态是必不可少的。
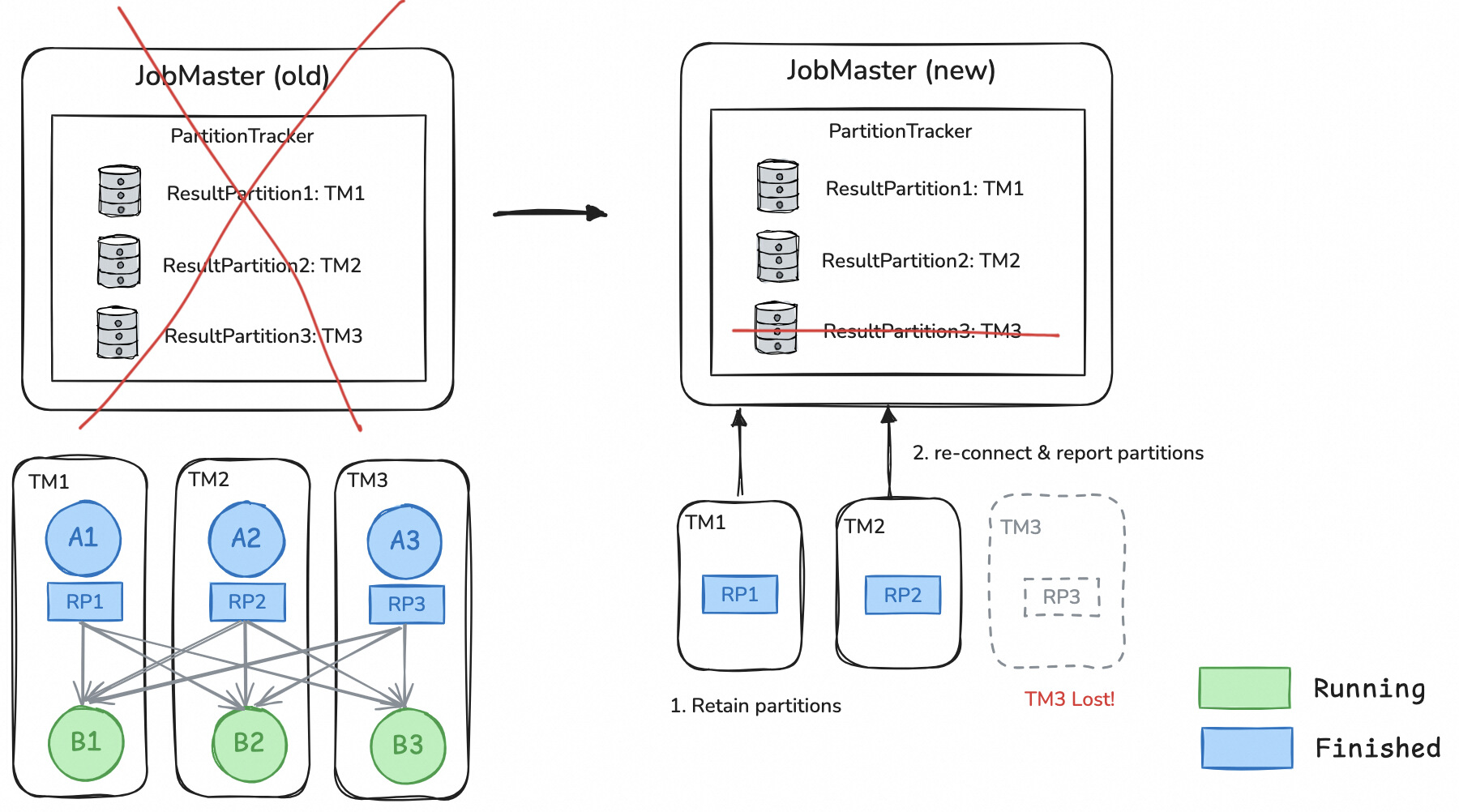
- JM failover 期间 Flink 批作业在运行过程中,其中间结果数据会保存在 TM 上和 RSS 上。当 JM 发生故障时,TM 和 RSS 将保留与作业相关的中间结果数据,并不断地尝试重新连接到 JM。一旦新的 JM 重新被拉起来后,TM 和 RSS 将重新与 JM 建立连接,然后 TM 和 RSS 会主动上报它们持有的中间结果数据。
- JM failover 后的作业进度恢复
一旦 JM 重启,它会与 TM 和 RSS 重新建立连接,利用 JobEventStore 中记录的事件以及 TM 和 RSS 保留的中间结果数据,来重建作业的执行进度。
JM 首先会利用 JobEventStore 中记录的事件,恢复作业各个节点的执行状态。
然后根据 OperatorCoordinator 的状态,JM 会恢复尚未处理的 Source 数据分片,以避免数据丢失或重复。
随后,JM 将根据汇报上来的可用中间数据进一步校正执行进度。如果某个 task 产生的中间数据丢失,但这些数据仍被下游 task 所需要,那么该 task 将被重置并重新执行。
最后作业将从恢复出来的进度继续执行。

三、使用效果
以下是一个 JM 出错重启后进度恢复的效果示例。
该批作业的拓扑结构为 Source -> Map -> Sink ,当作业运行到 Map 节点时,因为外部服务的原因导致 JM 所在机器下线,从而造成了 JM failover。
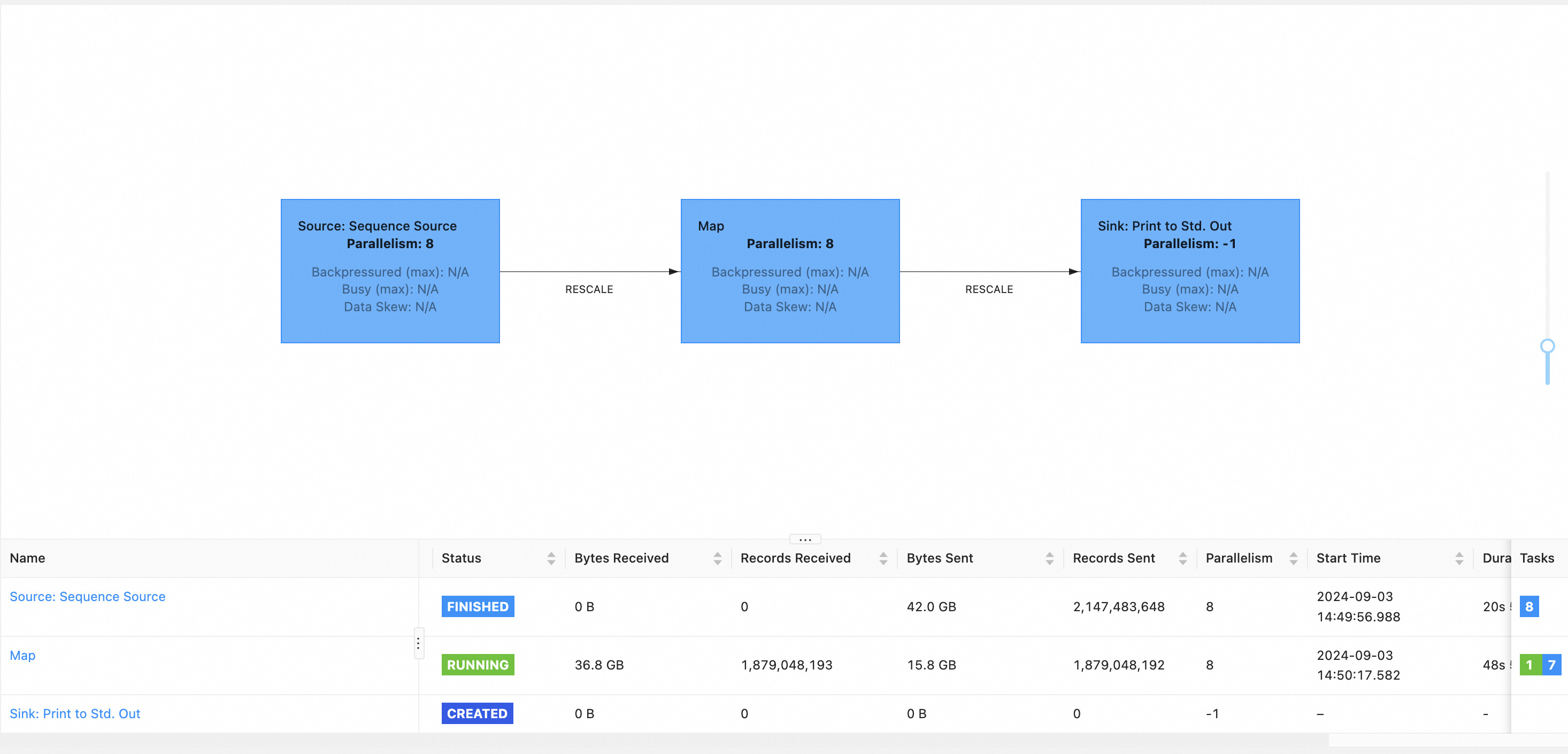
随后,高可用服务将会自动拉起新的 JM 进程,作业将进入 RECONCILING 状态,表示作业进入了恢复运行进展的阶段。

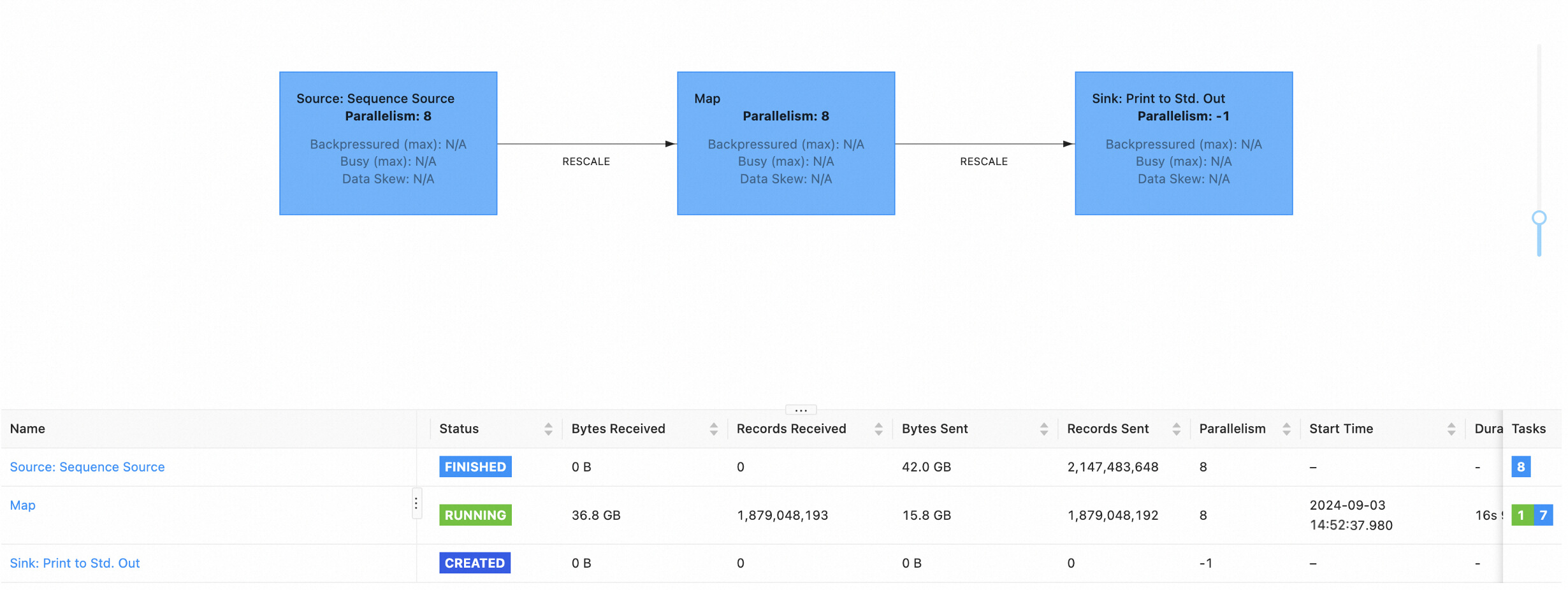
当作业恢复完成后,将进入 RUNNING 状态。

点进作业详情页后,可以观察到作业已经恢复到 JM failover 前到进展了。
四、如何启用
要使用 Flink 批作业的状态恢复功能,用户需要:
- 确保已启用集群高可用:目前 Flink 提供了基于 Zookeeper 和 Kubernetes 的两种高可用服务,更多细节详见官方文档。
- 配置 execution.batch.job-recovery.enabled: true
所有 new source 都支持批处理作业在 JM 出错后进行进度恢复。然而,为了实现细粒度的进度恢复,new source的 SplitEnumerator 需要实现 SupportsBatchSnapshot 接口,否则只有在该 source 的所有并发任务完成后,才能在 JM 出错恢复后避免重新执行这个 source 的 task。当前,FileSource 和 HiveSource 已经实现了该接口。详细信息请参见官方文档。
考虑到不同集群和作业的差异,为了让批作业在 job master failover 后能够尽可能的恢复出错前的进度,避免重新运行已完成的任务,用户可以参考此文档进行配置项调优。