阿里云 EMR Serverless Spark 版已于2024年9月14日正式商业化售卖,本文将简要介绍 EMR Serverless Spark 的产品优势、应用场景、支持地域,及计费模式等。
EMR Serverless Spark 是一款云原生,专为大规模数据处理和分析而设计的全托管 Serverless 产品。该产品内置 Fusion Engine,100%兼容开源 Spark 编程接口,相比于开源 Spark 性能提升300%;提供 Notebook 及 SQL 开发、调试、发布、调度、监控诊断等一站式数据开发体验;支持弹性伸缩、按量付费,进一步降低计算成本!
产品优势
易用
-
提供作业开发、调试、发布、调度等一站式数据开发体验
-
内置版本管理、开发与生产隔离,满足企业级开发与发布标准
-
提供内置 SQL Editor 和 Notebook,提供数据开发和数据科学一体化开发体验
极速
- 自研 Fusion 引擎,内置高性能向量化计算和 RSS 能力,相对开源版本性能提升 3 倍以上
开放
-
支持开放、灵活、弹性的数据湖仓分析
-
支持使用 DataFrame、SQL、PySpark 等多种编程方式开发批、流、交互式分析、机器学习等不同类型的任务,并进行调度执行
-
支持通过 Spark Submit、Livy、Spark Thrift Server 等开源兼容的方式进行任务提交
-
支持 DLF 以及外部 Hive Metastore 作为元数据服务
-
官方提供开源 Operators 对接 Airflow、DolphinScheduler 调度器
云原生
-
开箱即用,无需手动管理和运维云基础设施。
-
弹性伸缩,秒级资源弹性与供给。
-
按量付费,仅按任务实际使用的计算资源量付费,进一步降低计算总成本。

应用场景
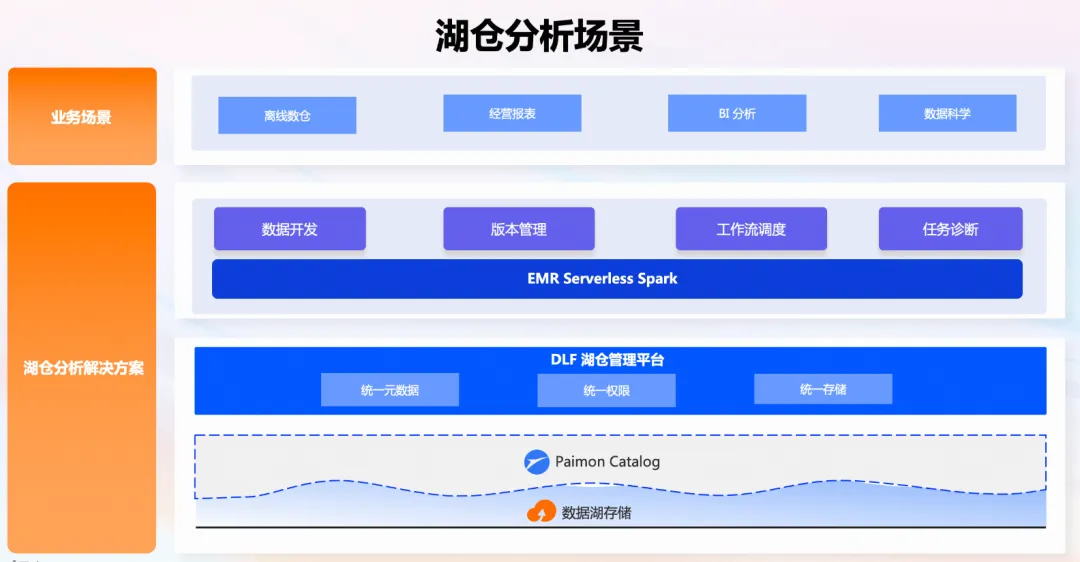
湖仓分析场景
EMR Serverless Spark 与 DLF 深度集成,结合了数据湖仓元数据管理、数据存储等托管能力,提供了一站式湖仓分析解决方案。这一解决方案涵盖了从数据清洗、转换到分析的完整数据处理链路和流程,确保数据处理的高效性。同时,Serverless Spark 还提供企业级的安全能力,包括完整的数据目录、库表等安全要素,以保障数据的安全性。此外,该湖仓分析解决方案支持弹性伸缩功能,实现资源的优化配置,确保能够高效处理大规模数据。通过简化数据治理流程和降低运维成本,EMR Serverless Spark 帮助企业加速业务决策和创新,提升整体数据管理和分析的效率。
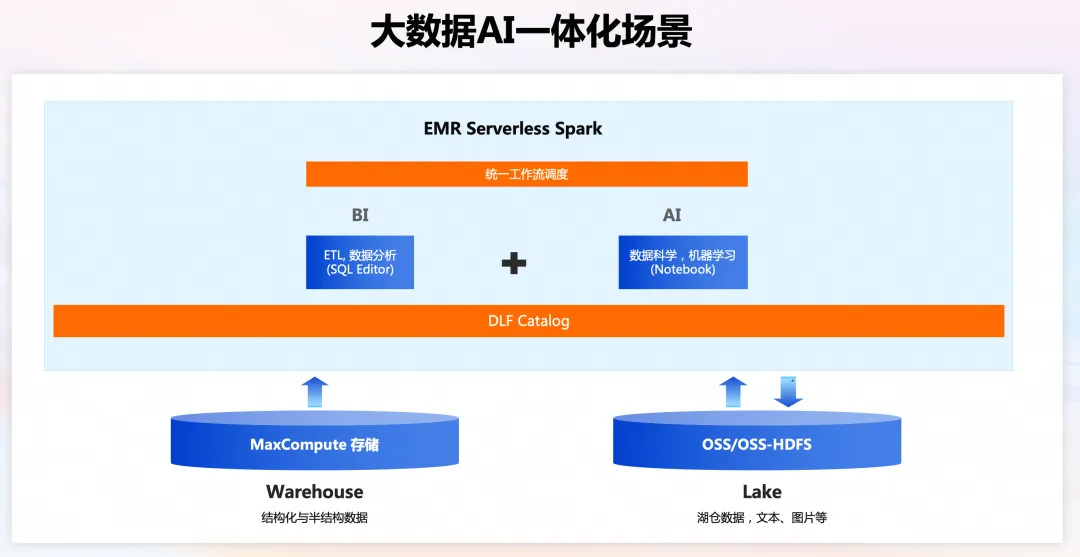
大数据AI一体化场景
EMR Serverless Spark 提供内置 Notebook,支持交叉使用 SQL 和 PySpark 进行大数据处理和数据科学分析一体化开发,同时支持对接 DLF 大数据 + AI 统一元数据视图,融合数据和 AI 应用,支持企业实现数据驱动的智能化决策。
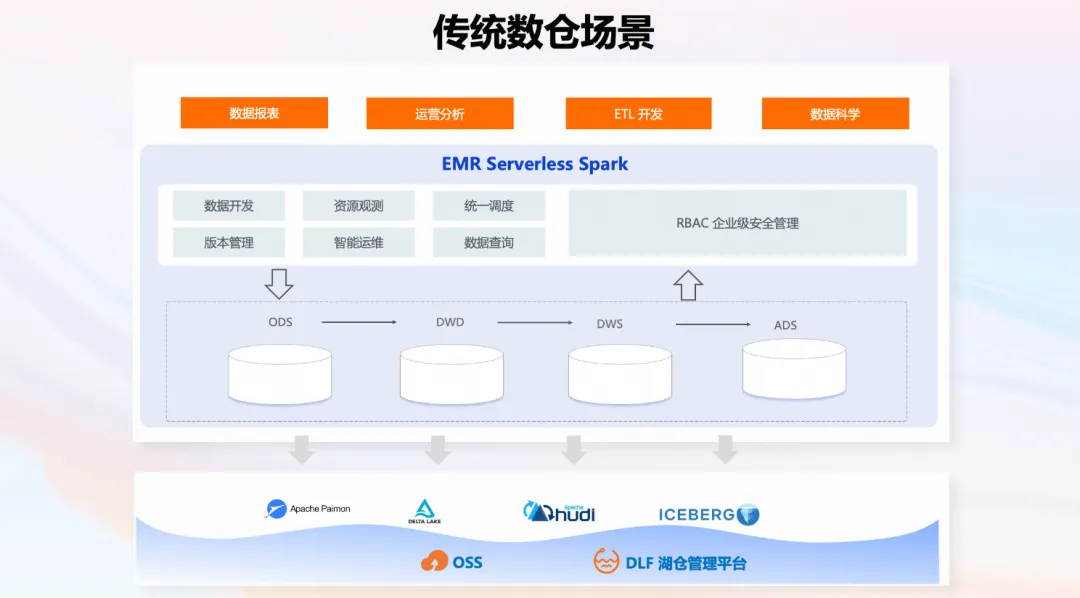
传统数仓场景
面向经典的数据仓库大数据离线处理场景,EMR Serverless Spark 为您提供一站式解决方案,帮助您完成数据仓库的高效建设,包括数据开发、版本管理、任务调度、监控诊断、资源观测等。另外,在 Fusion 引擎的加持下,EMR Serverless Spark 提供在线数据查询与分析服务,方便您即时了解业务变化。借助 Spark Thrift Server 提供的 JDBC 接口,您可以轻松将 EMR Serverless Spark 与您的 BI 系统对接,实现指标数据的高效查询和分析,进一步提升数据仓库的应用价值。
更多信息,请参见什么是EMR Serverless Spark。【https://x.sm.cn/7hmaFqW】
控制台入口:https://x.sm.cn/61a0FwU。
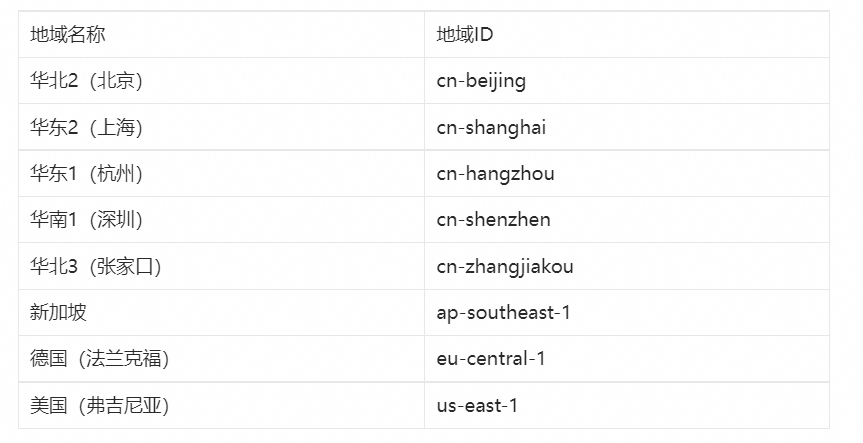
支持地域
EMR Serverless Spark支持以下地域
中国站账号
国际站账号

产品计费
商业化开启后将涉及相关功能的收费,具体收费标准见产品计费。【https://x.sm.cn/3svrzfH】
说明
商业化开启后,继续使用 EMR Serverless Spark 将按照计费标准收取费用,如果不再使用请及时删除相关资源。
服务等级协议
商业化开启后,产品保障服务等级协议,详情请参见 E-MapReduce Serverless Spark 服务等级协议。
中国站:E-MapReduce Serverless Spark服务等级协议
联系我们
如果在使用 EMR Serverless Spark 的过程中遇到任何疑问,可加入钉钉群58570004119咨询。