现象
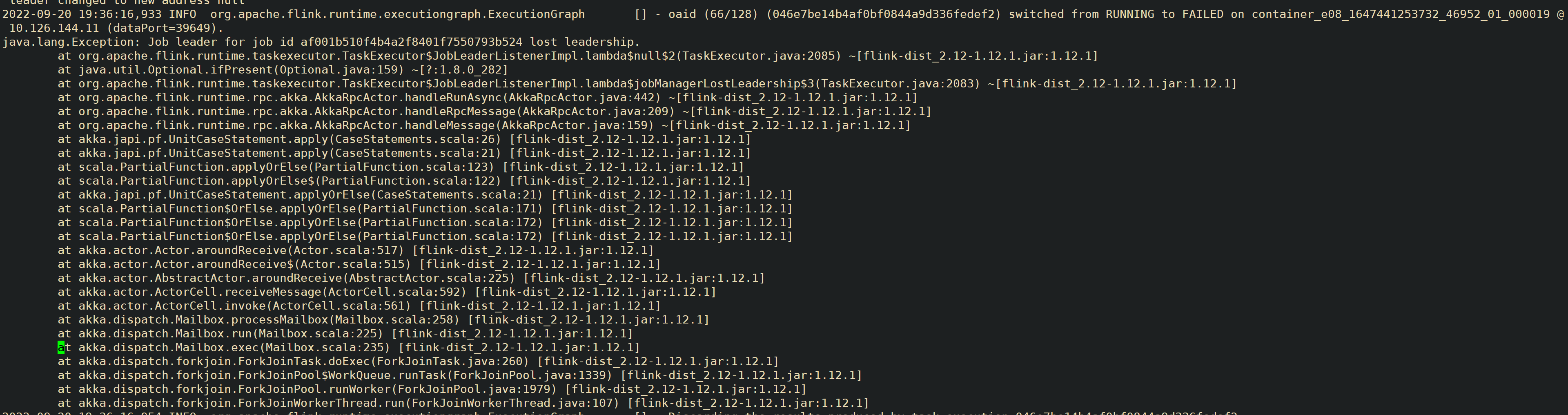
用户 flink 任务提交客户端侧抛出请求错误,经排查发现是客户端主动 cancle 的.接着排查 yarn app 日志,发现本质错误是 jm 退出了,接着看 jm 日志,jm 退出是由于失去了 leadership 导致的
排查过程
了解背景发现,用户有 flink ha任务,也有非 ha 任务, ha 使用的是基于 zookeeper 的实现
ha 任务是由于 jm 与选主的 zk 间的session 超时,导致jm 失去 leader
非 ha 任务是由于 jm 与 tm 间的心跳超时,jm 将 tm 置为 failed 状态,且没有配置 Restart Strategy
超时优化措施:
1.优化超时任务的 gc,通过 jstat 命令可以看到 tm jvm 的 old 分区占比 在 85 以上,
建议增大 flink 的 tm 内存参数 :
-D taskmanager.memory.task.heap.size
-D taskmanager.memory.managed.size
-D taskmanager.memory.task.off-heap.size
在原来值的基础上增大 50%
2.优化超时任务的超时时间
增加 zk server ticktime (已经调整)
增加 jm 和 tm 的心跳超时时间 heartbeat.timeout = 180000
解决办法
-
把 基于 ZooKeeper 的 HA 实现 改成 Flink on YARN 模式下的高可用,这样利用 yarn 自动拉起失败的 jobmanager 来解决实现任务的高可用
-
通过提交平台侧来实现任务的高可用,既让任务快速失败,然后通过平台侧的检测来重新提交来实现,需要配置如下参数,关闭 yarn 的自动拉起机制,从而让任务快速失败,被平台侧检测到,发起重新提交
yarn.application-attempts: 1
yarn.application-attempt-failures-validity-interval: -1
ZooKeeper参数调优 - skyl夜 - 博客园 (cnblogs.com)
Flink JobManager 高可用详解 - 白墨的博客 | Ink's Blog (baixin.ink)