1、上传相关jar包到streampark所在服务的 /opt/flink-1.20.0/lib

rm -rf flink-sql-connector-mysql-cdc-3.0.1.jar (要用3.1)
2、在streampark上配置任务
查看相关的类:
jar -tf paimon-flink-action-1.2.0.jar | grep FlinkActions
org/apache/paimon/flink/action/FlinkActions.class
上传
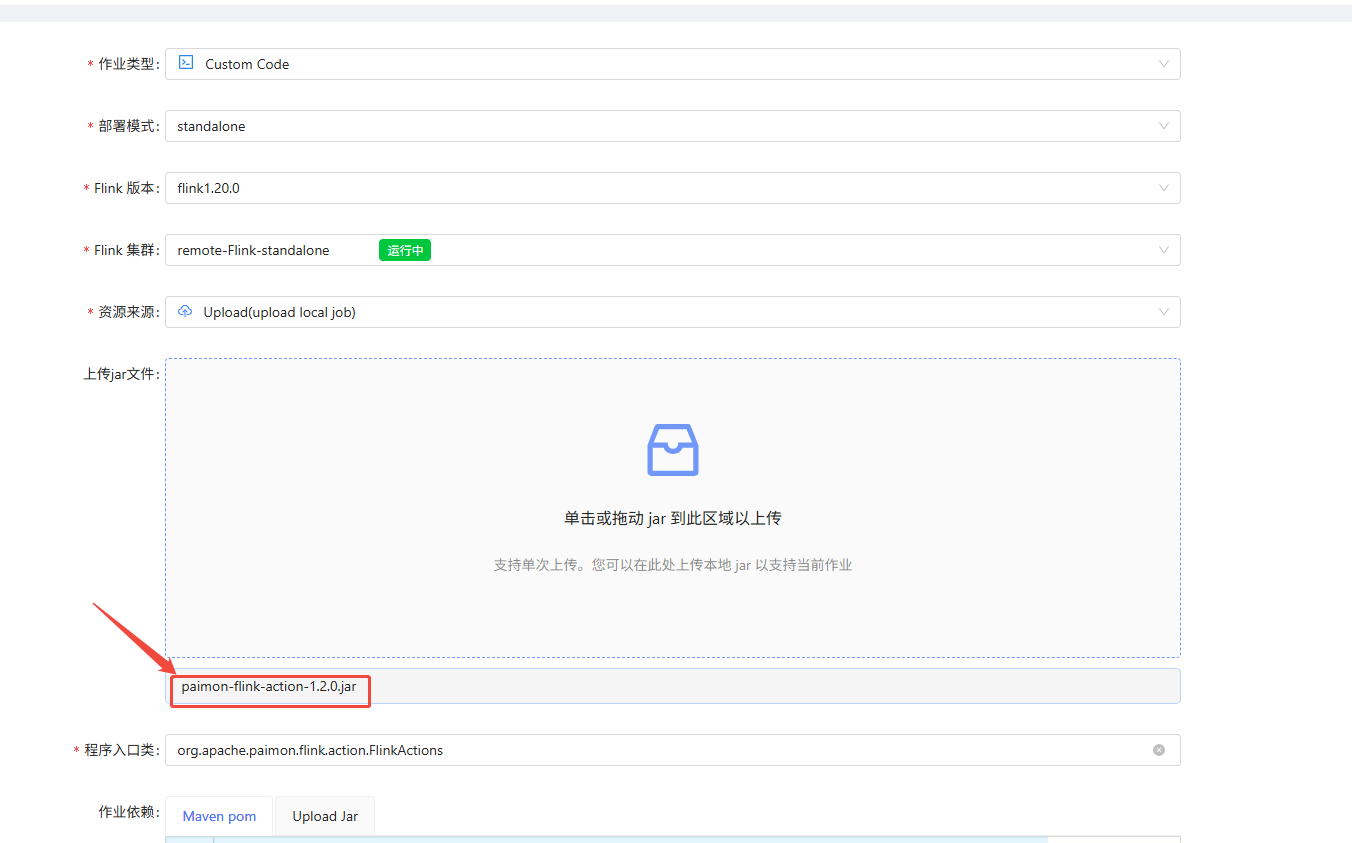

添加程序参数
mysql_sync_database
--warehouse s3://warehouse/wh
--database order_dw
--mysql_conf hostname=192.168.1.247
--mysql_conf port=3306
--mysql_conf username=root
--mysql_conf password=123456
--mysql_conf database-name=order_dw
--catalog_conf s3.endpoint=http://192.168.1.243:9000
--catalog_conf s3.access-key=minio
--catalog_conf s3.secret-key=minio@123
--catalog_conf s3.region=us-east-1
--catalog_conf s3.path.style.access=true
--table_conf bucket=1
--table_conf changelog-producer=input
--table_conf sink.parallelism=1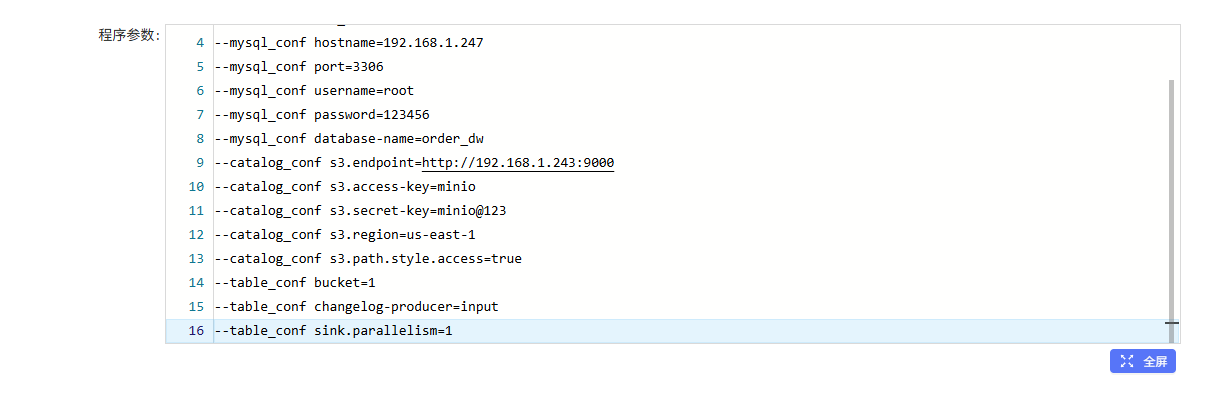
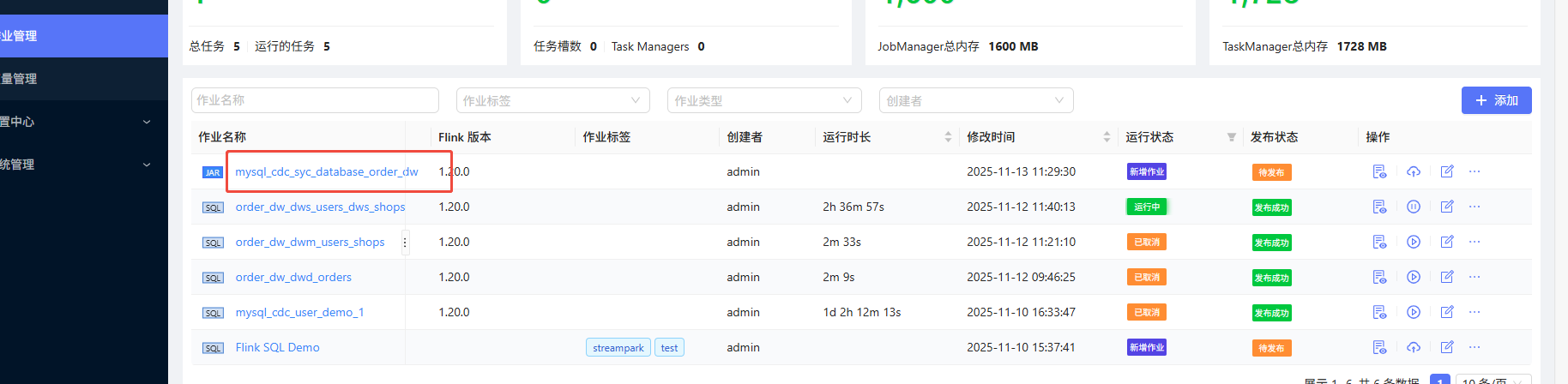
运行成功:

验证:
starrocks 的PAIMON原数据:
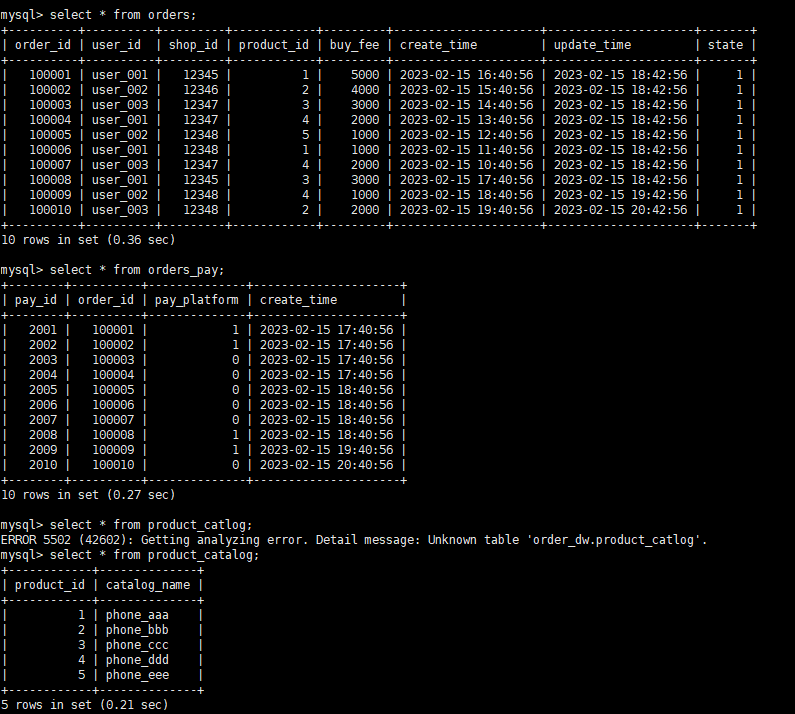
在mysql 新增数据新增数据:
INSERT INTO orders VALUES
(100011, 'user_001', 12345, 3, 3000, '2025-02-15 17:40:56', '2025-02-15 18:42:56', 1),
(100012, 'user_002', 12348, 4, 1000, '2025-02-15 18:40:56', '2025-02-15 19:42:56', 1),
(100013, 'user_003', 12348, 2, 2000, '2025-02-15 19:40:56', '2025-02-15 20:42:56', 1);
INSERT INTO orders_pay VALUES
(2011, 100011, 1, '2025-02-15 18:40:56'),
(2012, 100012, 1, '2025-02-15 19:40:56'),
(2013, 100013, 0, '2025-02-15 20:40:56');在starrocks查询PAIMON的数据:
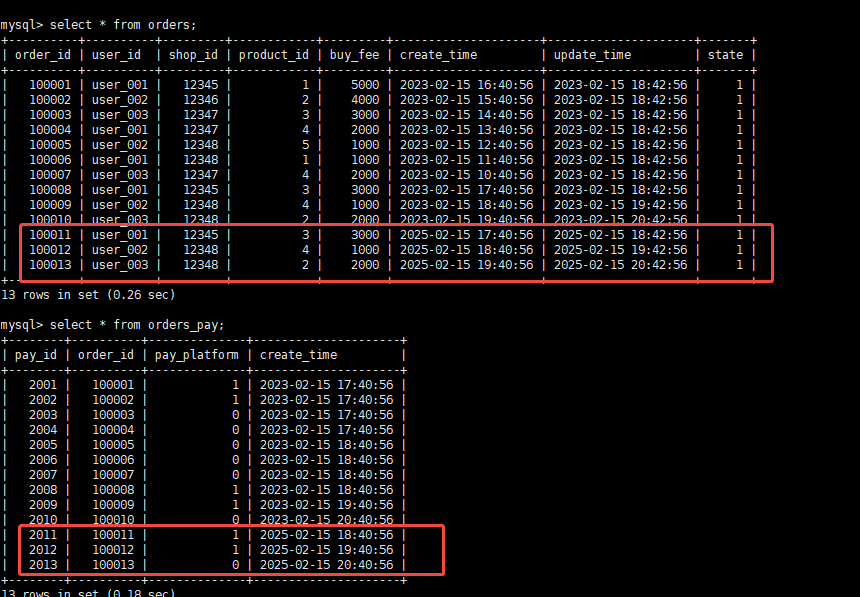
数据已同步