实时计算Flink版提供了丰富强大的数据实时入仓能力。通过Flink的全增量自动切换、元信息自动发现、表结构变更自动同步和整库同步等功能,简化了数据实时入仓的链路,使得实时数据同步更加高效便捷。本文介绍如何快速构建一个从MySQL到Hologres的数据同步作业。
背景信息
假设MySQL实例中有一个tpc_ds库,里面有24张表结构不相同的业务表。另外还有user_db1~user_db3三个库,由于进行了分库分表的设计,每个库中分别有3张表结构相同的表,共包含名称为user01~user09的9张表。在阿里云DMS控制台观察到MySQL中的库和表情况如下图所示。
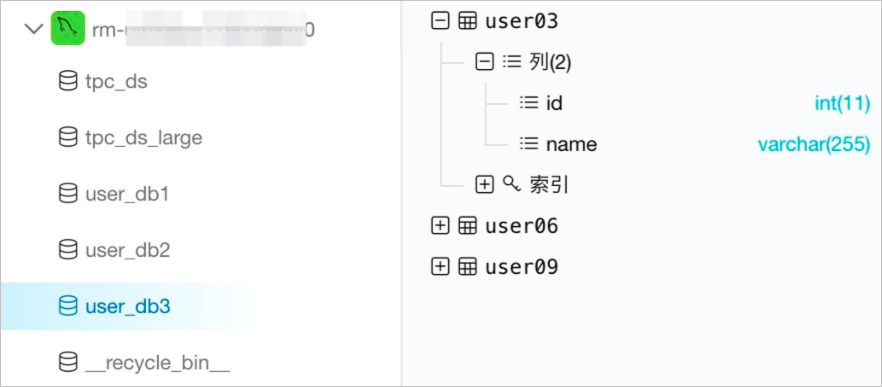
此时,如果您希望开发一个数据同步的作业,将这些表和数据都同步到Hologres中,其中user分库分表能合并到Hologres的一张表中,则可以按照以下步骤进行:
本文使用Flink提供的CREATE TABLE AS(CTAS)语句和CREATE DATABASE AS(CDAS)语句来完成整库同步、分库分表合并同步,一键完成数据的全量和增量同步,以及实时的表结构变更同步。
前提条件
-
如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
-
已创建Flink工作空间,详情请参见开通实时计算Flink版。
-
上下游存储
-
已创建RDS MySQL实例,详情请参见快速创建RDS MySQL实例。
-
已创建Hologres实例,详情请参见购买Hologres。
说明
RDS MySQL和Hologres需要与Flink工作空间在相同地域相同VPC下,否则需要打通网络,详情请参见控制台操作或控制台操作。
-
准备测试数据
-
单击tpc_ds.sql、user_db1.sql、user_db2.sql和user_db3.sql下载测试数据到本地。
-
在DMS数据管理控制台上,准备RDS MySQL的测试数据。
-
通过DMS登录RDS MySQL。
详情请参见通过DMS登录RDS MySQL。
-
在已登录的SQLConsole窗口,输入如下命令后单击执行。
创建tpc_ds、user_db1、user_db2和user_db3四个数据库。
CREATE DATABASE tpc_ds; CREATE DATABASE user_db1; CREATE DATABASE user_db2; CREATE DATABASE user_db3; -
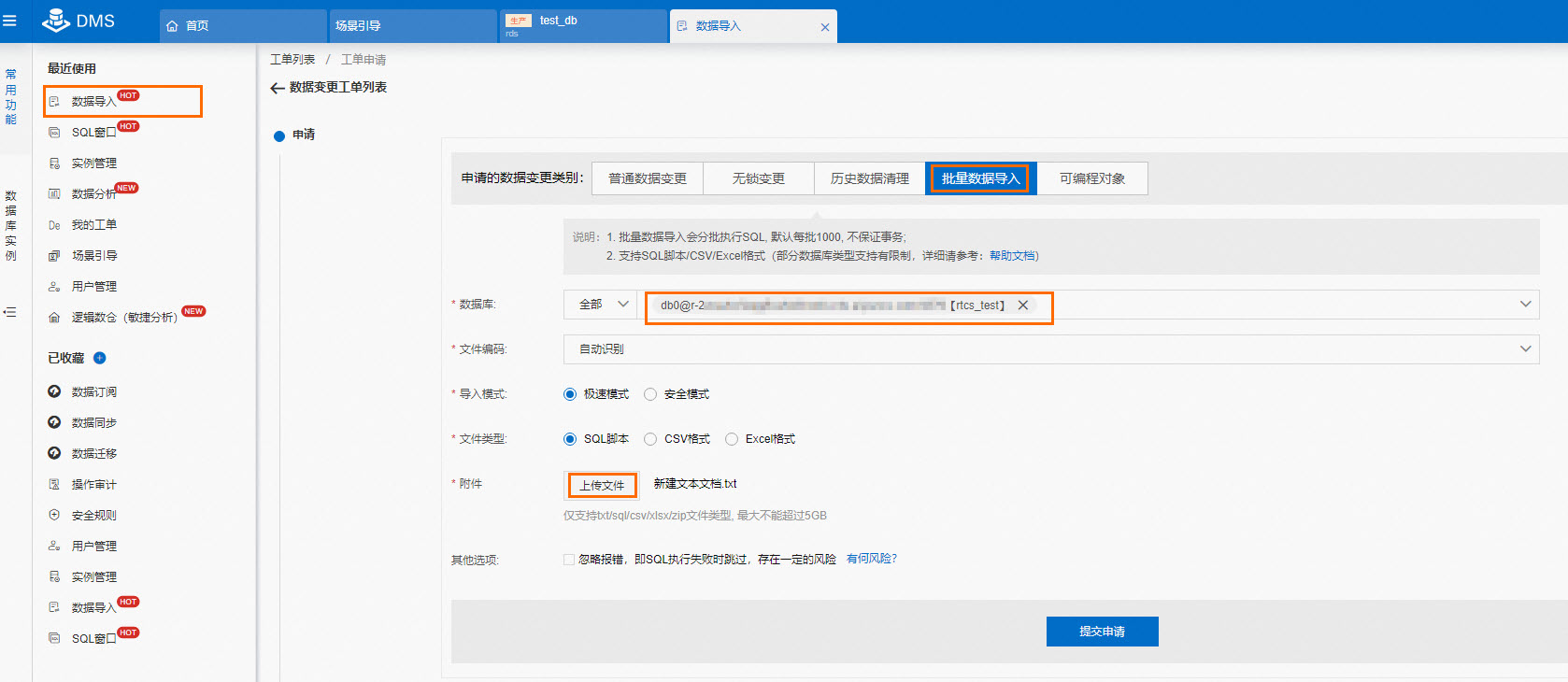
在左侧菜单栏,单击左侧常用功能 页签下的数据导入。
-
在批量数据导入 页签下选择需要导入的数据库,上传对应的SQL文件,单击提交申请 后,单击执行变更 。在弹出的对话框中单击确定执行。
同样的操作依次为tpc_ds、user_db1、user_db2和user_db3数据库导入对应的数据文件。
-
-
在Hologres控制台创建my_user数据库,用于存放合并后的user表数据。
操作步骤详情请参见创建数据库。
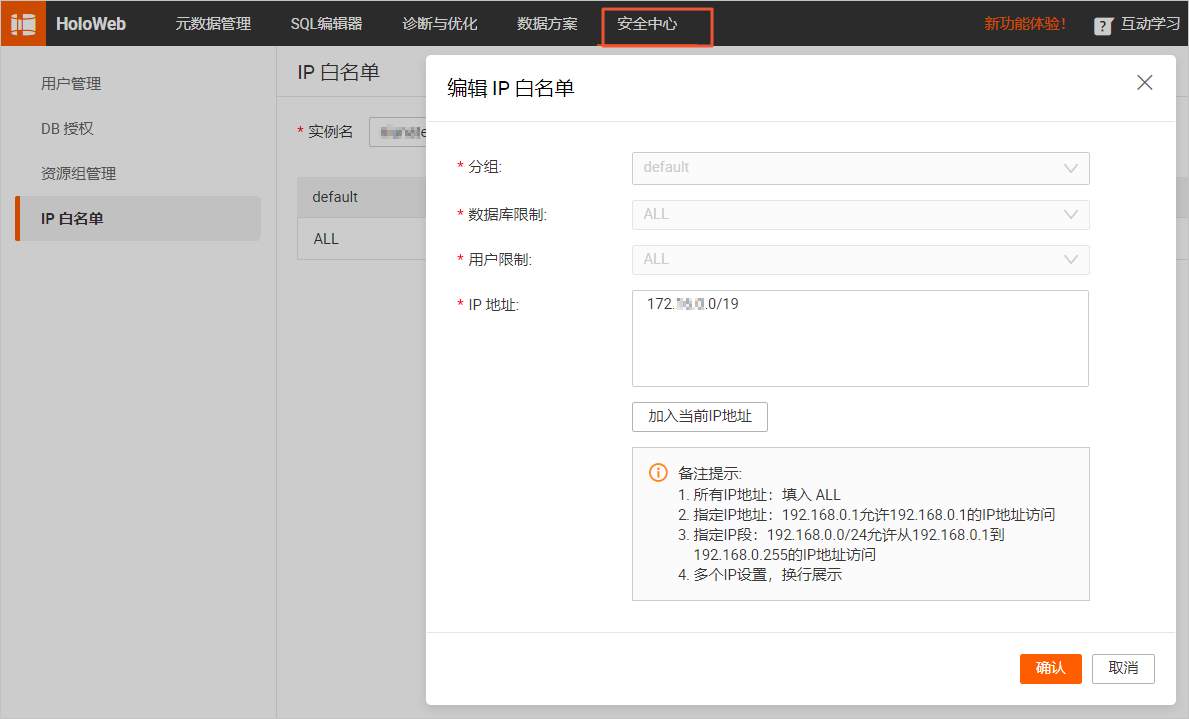
配置IP白名单
为了让Flink能访问MySQL和Hologres实例,您需要将Flink工作空间的网段添加到MySQL和Hologres的白名单中。
-
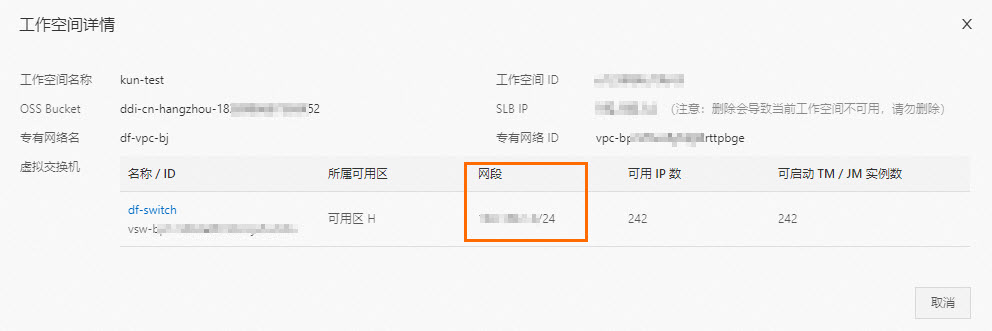
获取Flink工作空间的VPC网段。
-
登录实时计算控制台。
-
在目标工作空间 右侧操作 列,选择更多 > 工作空间详情。
-
在工作空间详情 对话框,查看Flink 虚拟交换机的网段信息。
-
-
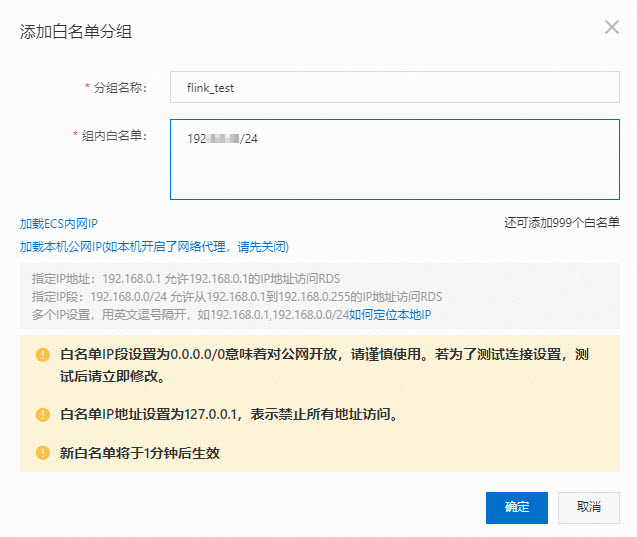
在RDS MySQL的IP白名单中,添加Flink网段信息。
操作步骤详情请参见设置IP白名单。
-
在Hologres的IP白名单中,添加Flink网段信息。
在HoloWeb配置数据连接时,需要将连接的登录方式 设置为当前用户免密登录 ,才可以为当前连接配置IP白名单,操作步骤详情请参见IP白名单。
步骤一:创建Catalog
整库同步、分库分表合并同步、单表同步都需要依赖目标Catalog来创建目标表,也依赖源Catalog来获取源表列表和信息。因此,您需要通过控制台创建源Catalog和目标Catalog。本文将以源Catalog为MySQL Catalog和目标Catalog为Hologres Catalog为例,为您进行介绍。
-
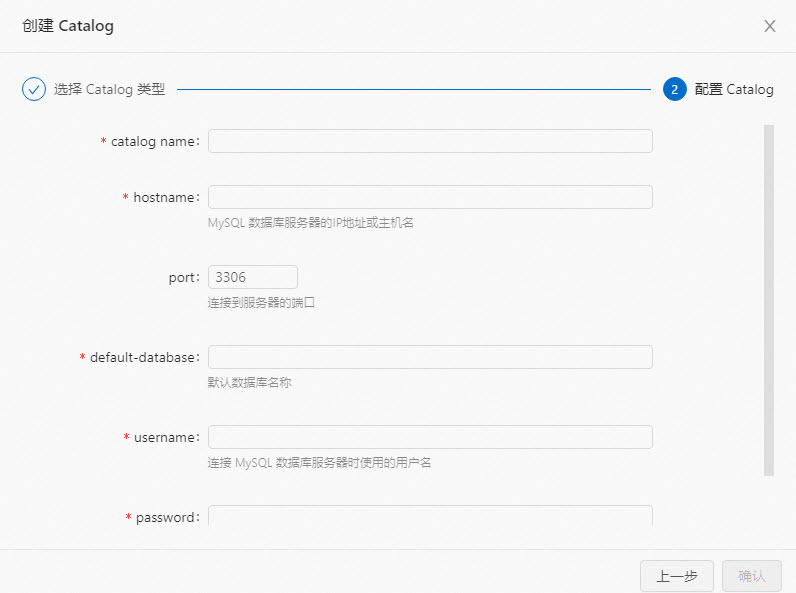
创建名称为mysql的MySQL Catalog。
操作步骤详情请参见配置MySQL Catalog。
-
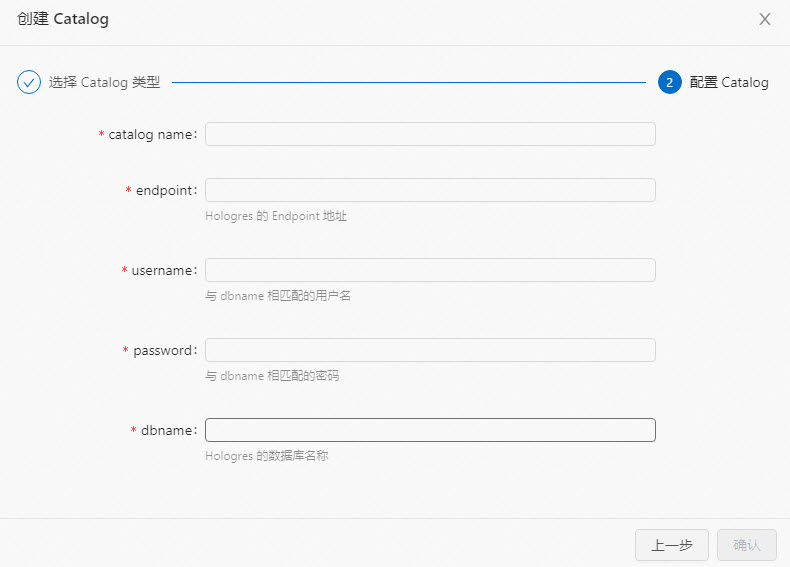
创建名称为holo的Hologres Catalog。
操作步骤详情请参见创建Hologres Catalog。
-
在元数据管理 页面Catalog列表中,确认已创建名为mysql和holo的Catalog。
步骤二:开发数据同步作业
-
登录Flink开发控制台,新建作业。
-
在数据开发 > ETL 页面,单击新建。
-
单击空白的流作业草稿。
Flink为您提供了丰富的代码模板和数据同步,每种代码模板都为您提供了具体的使用场景、代码示例和使用指导。您可以直接单击对应的模板快速地了解Flink产品功能和相关语法,实现您的业务逻辑,详情请参见代码模板和数据同步模板。
-
单击下一步。
-
在新建作业草稿对话框,填写作业配置信息。
|----------|-----------------------------------------------------------------------------------------------------------------------------------------------------|----------------------|
| 作业参数 | 说明 | 示例 |
| 文件名称 | 作业的名称。 说明 作业名称在当前项目中必须保持唯一。 | flink-test |
| 存储位置 | 指定该作业的代码文件所属的文件夹。 您还可以在现有文件夹右侧,单击 图标,新建子文件夹。 | 作业草稿 |
图标,新建子文件夹。 | 作业草稿 |
| 引擎版本 | 当前作业使用的Flink的引擎版本。引擎版本号含义、版本对应关系和生命周期重要时间点详情请参见引擎版本介绍。 | vvr-6.0.4-flink-1.15 | -
单击创建。
-
-
将以下作业代码拷贝到作业文本编辑区。
将tpc_ds库中所有表同步至Hologres,并将user的分库分表合并同步到Hologres的单表中。代码示例如下所示。
USE CATALOG holo; BEGIN STATEMENT SET; -- 同步TPCDS整库到Hologres的tpc_ds库中。 CREATE DATABASE IF NOT EXISTS tpc_ds AS DATABASE mysql.tpc_ds INCLUDING ALL TABLES /*+ OPTIONS('server-id'='8001-8004') */ ; -- 同步user分库分表到Hologres的my_user.users表中。 CREATE TABLE IF NOT EXISTS my_user.users AS TABLE mysql.`user_db[0-9]+`.`user[0-9]+` /*+ OPTIONS('server-id'='8001-8004') */; END;将tpc_ds库中所有表同步至Hologres使用CDAS (CREATE DATABASE AS) 语法来实现,将user的分库分表合并同步到Hologres的单表使用CTAS (CREATE TABLE AS) 语法来实现,最后再使用STATEMENT SET语法将这两条SQL语句合并在一个作业中提交。Flink会自动为Source进行优化,复用一个Source节点读取多张MySQL表的数据,这能显著降低MySQL的连接数和读取压力,提升稳定性。
说明
如果只想同步库中的某些表,您也可以在CDAS语法中使用 INCLUDING TABLE或EXCLUDING TABLE 语法来指定具体需要同步的表。例如INCLUDING TABLE 'web.*'表示只同步中所有web开头的表。
步骤三:启动作业
-
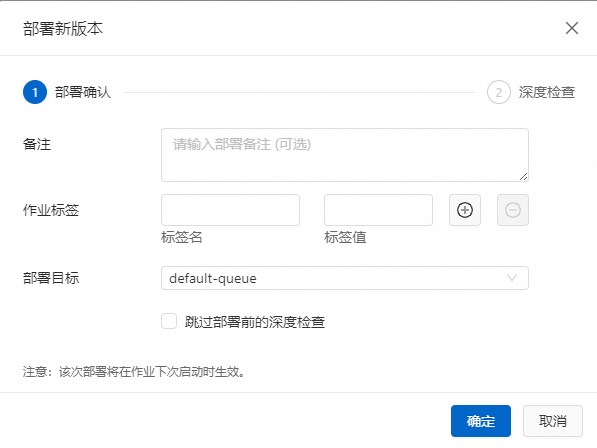
在数据开发 > ETL 页面,单击部署 后,在弹出的对话框中,单击确认。
说明
Session集群适用于非生产环境的开发测试环境,您可以使用Session集群模式部署或调试作业,提高作业JM(Job Manager)资源利用率和提高作业启动速度。但不推荐您将作业提交至Session集群中,因为会存在业务稳定性问题,详情请参见配置开发测试环境(Session集群)。
-
在运维中心 > 作业运维 页面,单击目标作业操作 中的启动 。填写配置信息,详情请参见作业启动。
-
单击启动。
作业启动后,您可以在作业运维页面观察作业的运行信息和状态。

步骤四:观察全量同步结果
-
在元数据管理页签,查看Hologres实例下的tpc_ds数据库中24张表和表数据。
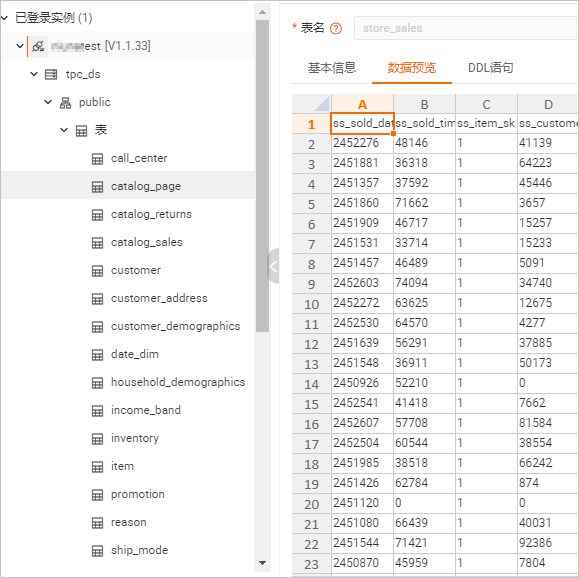
-
在元数据管理页签,查看my_user库下users表结构。
同步后的表结构和数据如下图所示。
-
表结构
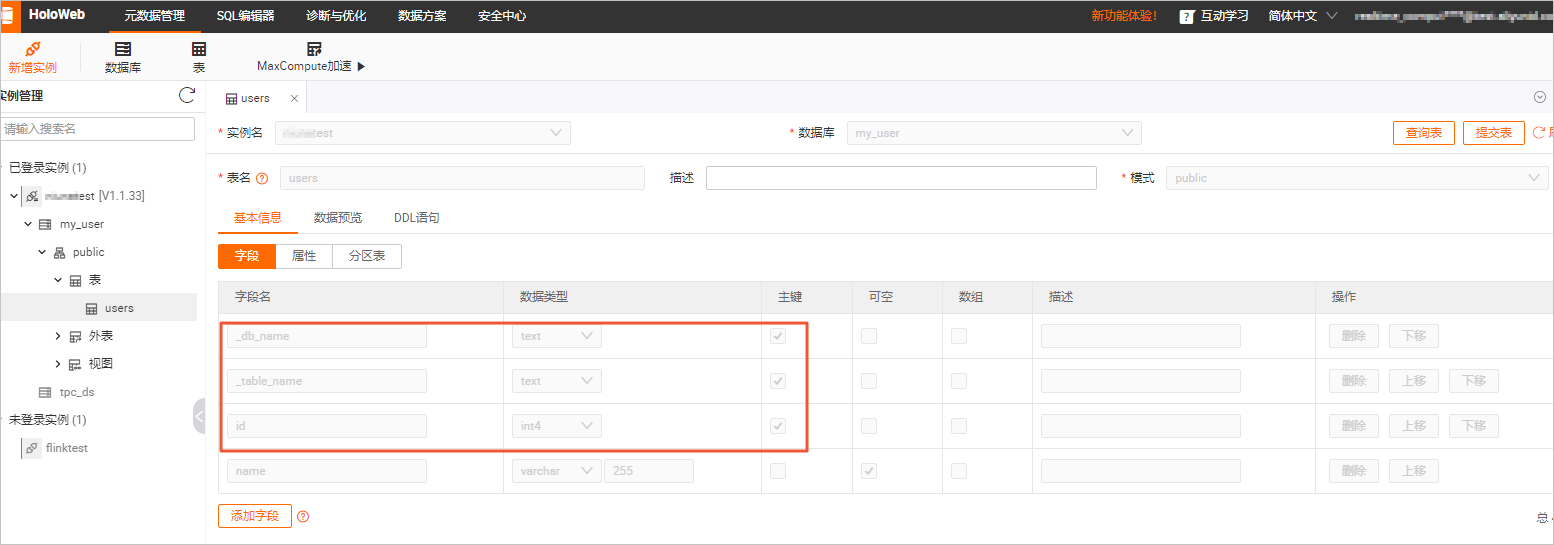
users表的表结构比MySQL源表中多了_db_name和_table_name两列,代表数据来源的库名和表名,且作为联合主键的一部分来保证分库分表合并后的数据唯一性。
-
表数据
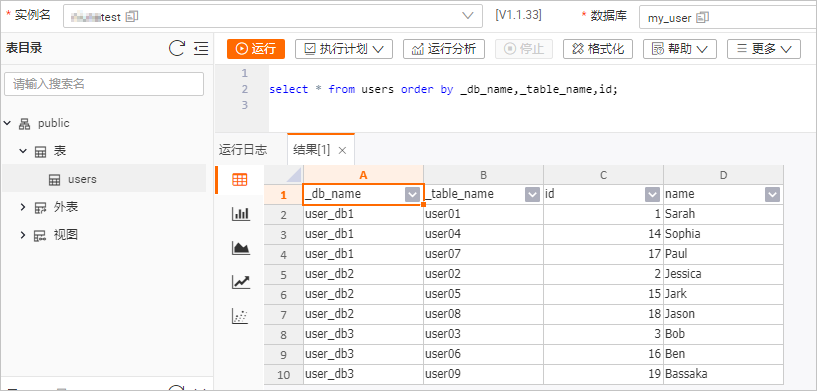
在users表信息页面右上角,单击查询表 后,输入如下命令,单击运行。
select * from users order by _db_name,_table_name,id;表数据结果如下图所示。
-
步骤五:观察增量同步结果
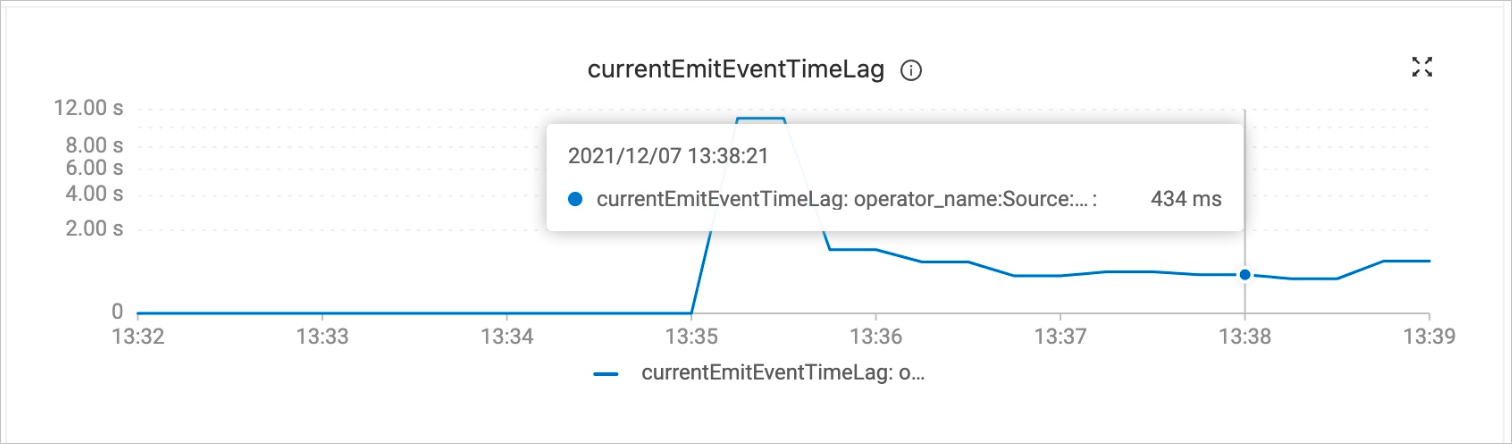
同步作业会在全量数据同步完以后自动切换到增量数据同步阶段,无需干预。您可以通过监控告警页签的currentEmitEventTimeLag值来确定数据同步的阶段。
-
登录实时计算控制台。
-
单击对应工作空间操作 列下的控制台。
-
在运维中心 > 作业运维页面,单击目标作业名称。
-
单击监控告警页签。
-
观察currentEmitEventTimeLag曲线图,确定数据同步阶段。
-
值为0时,代表还在全量同步阶段。
-
值大于0时,代表已经进入增量同步阶段。
-
-
验证实时同步数据变更和结构变更的能力。
MySQL CDC数据源支持在增量同步阶段,实时同步表的数据变更以及表的结构变更。您可以在作业进入到增量同步阶段后,通过修改MySQL的user分表的表结构和数据,来验证实时同步数据变更和结构变更的能力。
-
通过DMS登录RDS MySQL。
详情请参见通过DMS登录RDS MySQL。
-
在user_db2数据库下,执行如下命令修改user02表的表结构,并插入和更新数据。
USE DATABASE `user_db2`; ALTER TABLE `user02` ADD COLUMN `age` INT; -- 添加age列。 INSERT INTO `user02` (id, name, age) VALUES (27, 'Tony', 30); -- 插入带有age的数据。 UPDATE `user05` SET name='JARK' WHERE id=15; -- 更新另一张表,名字改成大写。 -
在Hologres控制台,查看users表结构和数据的变化。
在users表信息页面右上角,单击查询表 后,输入如下命令,单击运行。
select * from users order by _db_name,_table_name,id;表数据结果如下图所示。
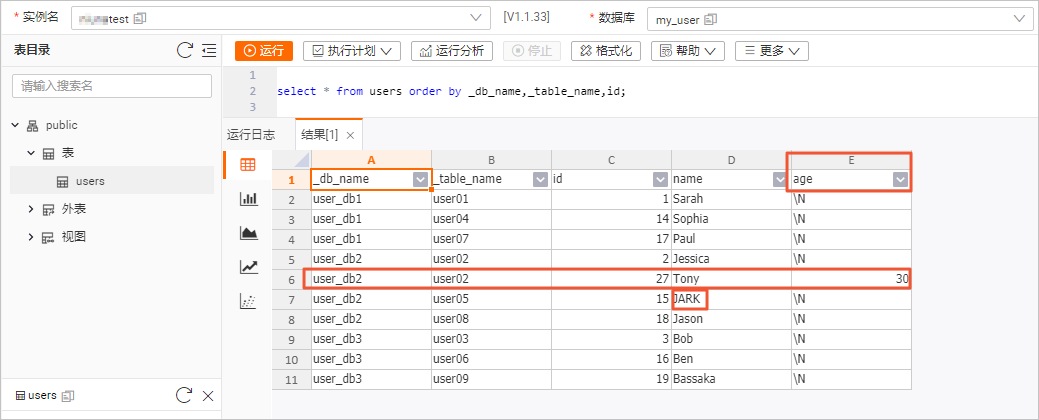
虽然多张分表的Schema并不一致,但是在user02上的表结构变更,以及数据变更都能实时地同步到下游表中。在Hologres的users表中,看到了新增的age字段,插入的Tony数据以及更新成大写的JARK数据。
-
(可选)步骤六:作业资源配置
根据数据量的不同,我们往往需要调节不同节点的并发和资源,以达到更优的作业性能。您可以使用资源配置的基础模式简单配置作业并发度和CU数,也可以使用资源配置的专家模式细粒度地调整节点的并发和资源。
-
在运维中心 > 作业运维页面,单击目标作业名称。
-
在部署详情 页签下,单击资源配置 区域右上角的编辑。
-
在资源模式 配置项中选择专家模式 后,单击立刻获取。
-
将鼠标悬停至更多操作 后,单击展开全部。
通过完整的拓扑图能了解到整个数据的同步计划,即具体同步哪些表。
-
手动设置每个节点的并发。
设置作业为4并发;由于tpc_ds中的store_sales表数据量最大,可以单独设置holo.tpc_ds.store_sales Sink节点并发为8,提升Hologres的写入性能。资源配置步骤详情请参见配置作业部署信息。
-
在资源配置 右侧,单击保存。
-
重启作业。
作业资源配置后,需重启作业才能生效。
-
单击目标作业名称,在作业总览页签下查看调整效果。