嗨,你好,我是猿java
在很长一段时间里,ZooKeeper都是 Kafka的标配,现如今,Kafka官方已经在慢慢去除ZooKeeper,Kafka 为什么要抛弃 Zookeeper?这篇文章我们来聊聊其中的缘由。
Kafka 和 ZooKeeper 的关系
ZooKeeper 是一个分布式协调服务,常用于管理配置、命名和同步服务。长期以来,Kafka 使用 ZooKeeper 负责管理集群元数据、控制器选举和消费者组协调等任务理,包括主题、分区信息、ACL(访问控制列表)等。
ZooKeeper 为 Kafka 提供了选主(leader election)、集群成员管理等核心功能,为 Kafka提供了一个可靠的分布式协调服务,使得 Kafka能够在多个节点之间进行有效的通信和管理。然而,随着 Kafka的发展,其对 ZooKeeper的依赖逐渐显露出一些问题,这些问题也是下面 Kafka去除 Zookeeper的原因。
抛弃ZooKeeper的原因
1. 复杂性增加
ZooKeeper 是独立于 Kafka 的外部组件,需要单独部署和维护,因此,使用 ZooKeeper 使得 Kafka的运维复杂度大幅提升。运维团队必须同时管理两个分布式系统(Kafka和 ZooKeeper),这不仅增加了管理成本,也要求运维人员具备更高的技术能力。
2. 性能瓶颈
作为一个协调服务,ZooKeeper 并非专门为高负载场景设计, 因此,随着集群规模扩大,ZooKeeper在处理元数据时的性能问题日益突出。例如,当分区数量增加时,ZooKeeper需要存储更多的信息,这导致了监听延迟增加,从而影响Kafka的整体性能34。在高负载情况下,ZooKeeper可能成为系统的瓶颈,限制了Kafka的扩展能力。
3. 一致性问题
Kafka 内部的分布式一致性模型与 ZooKeeper 的一致性模型有所不同。由于 ZooKeeper和 Kafka控制器之间的数据同步机制不够高效,可能导致状态不一致,特别是在处理集群扩展或不可用情景时,这种不一致性会影响消息传递的可靠性和系统稳定性。
4. 发展自己的生态
Kafka 抛弃 ZooKeeper,我个人觉得最核心的原因是:Kafka生态强大了,需要自立门户,这样就不会被别人卡脖子。纵观国内外,有很多这样鲜活的例子,当自己弱小时,会先选择使用别家的产品,当自己羽翼丰满时,再选择自建完善自己的生态圈。
引入KRaft
为了剥离和去除 ZooKeeper,Kafka 引入了自己的亲儿子 KRaft(Kafka Raft Metadata Mode)。KRaft 是一个新的元数据管理架构,基于 Raft 一致性算法实现的一种内置元数据管理方式,旨在替代 ZooKeeper 的元数据管理功能。其优势在于:
-
完全内置,自包含:KRaft 将所有协调服务嵌入 Kafka 自身,不再依赖外部系统,这样大大简化了部署和管理,因为管理员只需关注 Kafka 集群。
-
高效的一致性协议:Raft 是一种简洁且易于理解的一致性算法,易于调试和实现。KRaft 利用 Raft 协议实现了强一致性的元数据管理,优化了复制机制。
-
提高元数据操作的扩展性:新的架构允许更多的并发操作,并减少了因为扩展性问题导致的瓶颈,特别是在高负载场景中。
-
降低延迟:在消除 ZooKeeper 作为中间层之后,Kafka 的延迟性能有望得到改善,特别是在涉及选主和元数据更新的场景中。
-
完全自主:因为是自家产品,所以产品的架构设计,代码开发都可以自己说了算,未来架构走向完全控制在自己手上。
KRaft的设计细节
-
控制器(Controller)节点的去中心化:KRaft 模式中,控制器节点由一组 Kafka 服务进程代替,而不是一个独立的 ZooKeeper 集群。这些节点共同负责管理集群的元数据,通过 Raft 实现数据的一致性。
-
日志复制和恢复机制:利用 Raft 的日志复制和状态机应用机制,KRaft 实现了对元数据变更的强一致性支持,这意味着所有控制器节点都能够就集群状态达成共识。
-
动态集群管理:KRaft 允许动态地向集群中添加或移除节点,而无需手动去 ZooKeeper 中更新配置,这使得集群管理更为便捷。
下面给出一张 Zookeeper 和 KRaft的对比图:
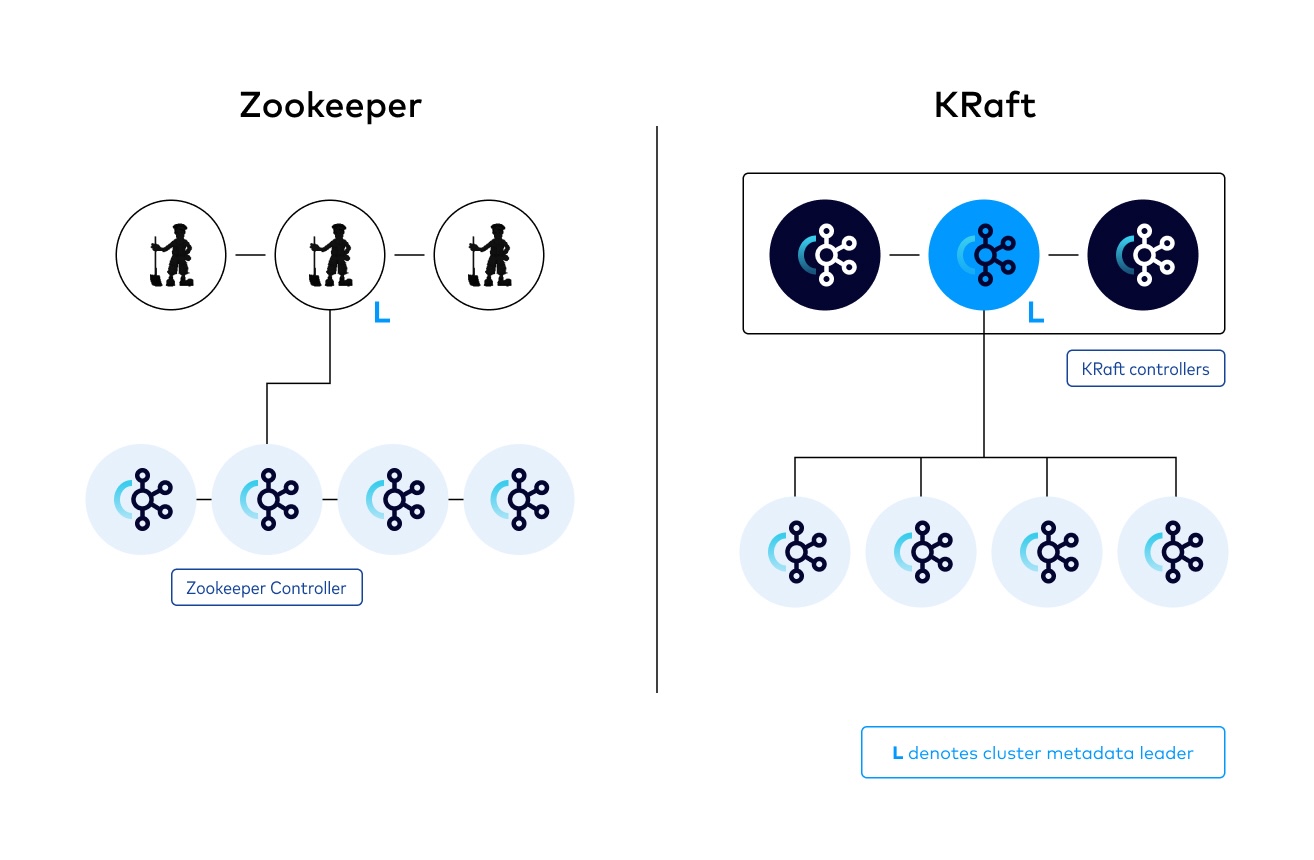
总结
本文,我们分析了为什么 Kafka 要移除 ZooKeeper,主要原因有两个:ZooKeeper不能满足 Kafka的发展以及 Kafka想创建自己的生态。在面临越来越复杂的数据流处理需求时,KRaft 模式为 Kafka 提供了一种更高效、简洁的架构方案。不论结局如何,Kafka 和 ZooKeeper曾经也度过了一段美好的蜜月期,祝福 Kafka 在 KRaft模式越来越强大,为使用者带来更好的体验。
学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注:猿java,持续输出硬核文章。