硬件平台
机器硬件:OriginBot(导航版/视觉版)PC主机:Windows(>=10)/Ubuntu(>=20.04)扩展硬件:X3语音版
运行案例
首先进入OriginBot主控系统,运行一下指令。请注意,部分操作OriginBot内暂未放入,请根据内容进行适当处理。
cd /userdata/dev_ws/
# 配置TogetheROS环境
source /opt/tros/setup.bash
# 从tros.b的安装路径中拷贝出运行示例需要的配置文件。
cp -r /opt/tros/lib/hobot_audio/config/ .
# 加载音频驱动,设备启动之后只需要加载一次
bash config/audio.sh
#启动launch文件
ros2 launch speech speech_recongnition_launch.py 其中speech_recongnition_launch.py 文件内容如下:
from launch import LaunchDescription
from launch.actions import DeclareLaunchArgument
from launch.substitutions import LaunchConfiguration
from launch_ros.actions import Node
def generate_launch_description():
# 启动音频采集pkg
audio_get = Node(
package='hobot_audio',
executable='hobot_audio',
output='screen',
parameters=[
{"config_path":"./config"},
{"audio_pub_topic_name": "audio_smart"}
],
arguments=['--ros-args', '--log-level', 'error']
)
return LaunchDescription([
audio_get
]) 此时出现如下报错是因为没有语音唤醒,说出"地平线你好"后,即可唤醒

当人依次在麦克风旁边说出"地平线你好"、"向左转"、"向右转"、"向前走"、"向后退"命令词,语音算法sdk经过智能处理后输出识别结果,log显示如下
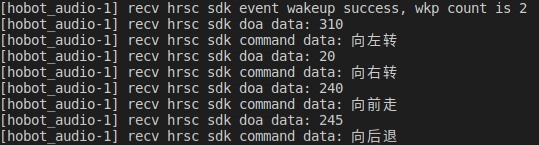
识别到语音命令词"向前走"、"向左转"、"向右转"、"向后退",并且输出DOA的角度信息,如recv hrsc sdk doa data: 110字段表示DOA角度为110度。
语音控制
SSH连接OriginBot成功后,配置智能语音模块:
#从TogetheROS的安装路径中拷贝出运行示例需要的配置文件。
cp -r /opt/tros/lib/hobot_audio/config/ .
#加载音频驱动,设备启动之后只需要加载一次
bash config/audio.sh启动机器人底盘在终端中输入如下指令,启动机器人底盘:
ros2 launch originbot_bringup originbot.launch.py启动语音控制以下是口令控制功能的指令:
ros2 launch audio_control audio_control.launch.py此时即可看到小车运动的效果了