P 21 insert基本使用 2022/7/14
1.基本使用

代码演示:
sql
# 练习1: insert语句
-- 创建一张商品表goods (id int, goods_name varchar(10),price double );
-- 添加两条记录
CREATE TABLE `goods` (
id INT ,
goods_name VARCHAR(10),
price DOUBLE);
INSERT INTO `goods` (id, goods_name, price) -- 全部添加可不带,单独添加需要列出列名
VALUES(10,'华为手机', 2000);
INSERT INTO `goods` (id ,goods_name, price)
VALUES(20, '苹果手机',3000);
SELECT * FROM goods;
# 练习2:向employee表中添加2个员工信息
SELECT * FROM employee;
INSERT INTO `employee` (id, name_user, birthday,entry_date,job,salary,`resume`)
VALUES(200, '开心超人', '2020-09-15','2022-7-14 16:36:30','打怪兽',5000,'开心每一天'); 相关结果截图:

P 22 insert 注意事项 2022/7/16
1.注意事项

sql
# insert 语句的细节
-- 1.插入的数据应与字段的数据类型相同,例如:把'abc'添加到int类型会错误。
INSERT INTO `goods` (id,goods_name,price)
VALUES('30','锤子手机',2500); # 30加上'',是可以被转成整型的
INSERT INTO `goods` (id,goods_name,price)
VALUES('abc','锤子手机',2500); # 执行会错误,然而abc是不可以被转成整型的
-- 2.数据的长度应在列的规范范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中。
INSERT INTO `goods` (id,goods_name,price)
VALUES(40,'VIVO手机VIVO手机VIVO手机VIVO手机VIVO手机',2500); # varchar(10),太长无法添加
-- 3.在values中列出的数据位置必须与被加入的列的排列位置相对应。
INSERT INTO `goods` (id,goods_name,price)
VALUES('oppo手机',50,2500); # 必须与之相对应,本质还是是否与数据类型相同问题
# id 对应50,goods_name对应 vivo手机,price对应2500
-- 4.字符和日期数据类型应该包含在单引号中。
INSERT INTO `goods` (id,goods_name,price)
VALUES(50,oppo手机,2500); # 未加单引号执行会报错,"未知列"oppo"手机' 在"字段列表"中"
-- 5.列可以插入空值[前提是该字段允许为空],insert into table_name value(null)
INSERT INTO `goods` (id,goods_name,price)
VALUES(50,'oppo手机',NULL); # 把price为空值,取决于创建price列是否允许为空,
CREATE TABLE zjc01 (
price DOUBLE NOT NULL); # 创建时如果设置NOT NULL非空,则不允许
SELECT * FROM zjc01;
INSERT INTO zjc01
VALUES(NULL); # 执行报错:"价格"列不能为空
-- 6.insert into tab_name (列名...) values(),(),() 形式添加多条记录
INSERT INTO `goods` (id,goods_name,price)
VALUES(60,'天迈手机',4000),(70,'红米手机',5000); # 添加了两条记录
-- 7.如果给表中的所有字段添加数据,可以不写前面的字段名称。
INSERT INTO `goods`
VALUES(80,'小辣椒手机',NULL);
-- 8.默认值的使用,当不给某个字段值时,如果有默认值就会添加默认值,否组报错。
INSERT INTO `goods` (id,goods_name) # 只对表中添加了两条数据
# 如果某个字段没有指定NOT NULL,当添加数据时没有给定值,会默认给NULL
VALUES(100,'格力手机');
# 如果我们希望指定某个列的默认值,可以在创建表的时候指定
CREATE TABLE `zjc02` (
price DOUBLE NOT NULL DEFAULT 100);
ALTER TABLE `zjc02`
ADD `name` VARCHAR(10);
INSERT INTO `zjc02` (`name`) # 没有给price列指定任何数值,会自动填充默认的值
VALUES('苹果手机');
SELECT * FROM `zjc02`; P 23 update语句 2022/7/17
1.update 语句用法
- 使用update语句修改表中数据


代码演示:
sql
-- 演示update 语句
-- 要求:在上面创建的employee表中修改表中的记录
SELECT * FROM employee;
-- 1.将所有员工的薪水修改为5000元
UPDATE employee SET salary = 5000 # 没有写where条件统一将所有员工的薪水改为5000(要慎重)
-- 2.将姓名 小妖怪 的员工薪水修改为3000元
UPDATE employee
SET salary = 3000
WHERE name_user = '小妖怪';
-- 3.将 老妖怪 的薪水在原有的基础上增加1000元
INSERT INTO employee (name_user,salary)
VALUES('老妖怪',2000);
UPDATE employee
SET salary = salary + 1000 # 原来的基础增加了1000块
WHERE name_user = '老妖怪';
-- 细节演示:可以修改多个列
UPDATE employee
SET salary = salary + 1000 ,job = '打酱油的' # 同时修改两列
WHERE name_user = '老妖怪';2.update语句使用细节

P 24 delete语句 2022/7/18
1.delete删除记录
代码演示:
sql
-- delete语句的演示
SELECT * FROM employee;
-- 删除表中名称为老妖怪的记录 。
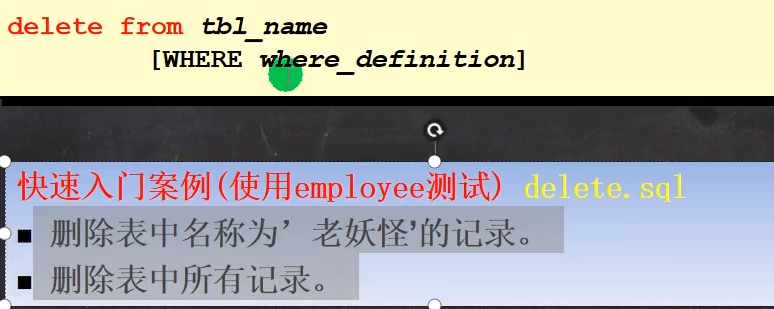
DELETE FROM employee
WHERE name_user = '老妖怪';
-- 删除表中所有记录。
DELETE FROM employee;
-- delete语句不能删除某一列的值(可以使用update设为null 或者'')
UPDATE employee SET `resume` = '' WHERE name_user = '老妖怪' ; -- 将resume列置空2.delete语句使用细节
-
如果不使用where语句将删除表中所有数据
-
delete语句不能删除某一列的值(可以使用update设为null 或者'')
-
使用delete语句仅删除记录,不删除表本身。如要删除表,使用drop table 语句。drop table 表名;
P 25 select 语句(1) 2022/7/19
1.基本使用方法(一)
代码演示:
sql
-- select 语句【重点、难点】
-- ****创建新的表(student)****
CREATE TABLE student(
id INT NOT NULL DEFAULT 1,
NAME VARCHAR(20) NOT NULL DEFAULT '',
chinese FLOAT NOT NULL DEFAULT 0.0,
english FLOAT NOT NULL DEFAULT 0.0,
math FLOAT NOT NULL DEFAULT 0.0
);
INSERT INTO student(id, NAME, chinese,english, math)VALUES(1,'韩顺平',89,78,90);
INSERT INTO student (id, NAME, chinese, english, math)VALUES(2,'张飞',67,98,56);
INSERT INTO student(id, NAME, chinese,english, math)VALUES(3,'宋江',87,78,77);
INSERT INTO student(id, NAME, chinese,english, math)VALUES(4,'关羽',88,98,90);
INSERT INTO student (id, NAME, chinese, english, math)VALUES(5,'赵云',82,84,67);
INSERT INTO student(id,NAME,chinese,english,math)VALUES(6,'欧阳锋',55,85,45);
INSERT INTO student(id,NAME,chinese,english,math)VALUES(7,'黄蓉',75,65,30);
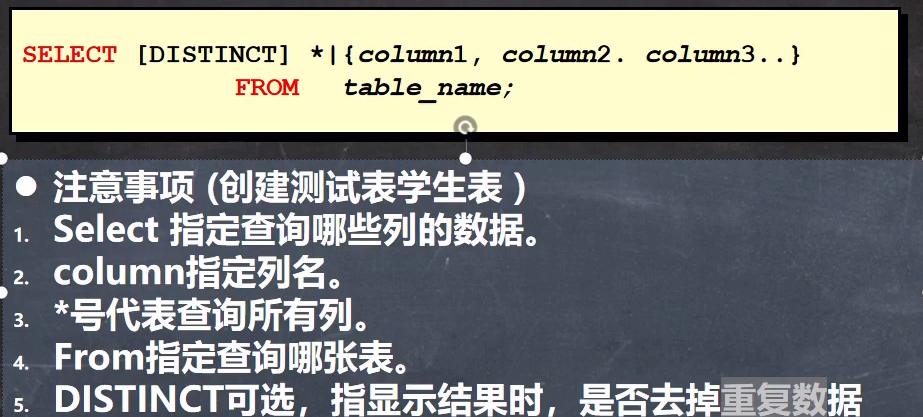
SELECT * FROM student;
-- 练习:
-- 查询表中所有学生信息。
SELECT * FROM student;
-- 查询表中所有学生 姓名 和对应的 英语 成绩。
SELECT `name`,english FROM student;
-- 过滤表中重复数据 distinct 。
SELECT `english` FROM
SELECT DISTINCT `english` FROM student; -- DISTINCT 如果重复的就保留一行【去重】
-- 要查询的记录,每个字段都相同,才会去重。
SELECT DISTINCT `name`,`english` FROM student; -- 需要每一列相同,才会去重,否则不会。P 26 select 语句(2) 2022/7/19
1.基本使用方法(二)

代码演示:
sql
-- select 语句的使用(二)
-- 统计每一个学生的总分
SELECT `name` ,(chinese + english + math + 10)FROM student; -- 三科加一起
-- 使用别名表示学生分数。
SELECT `name` AS '名字' ,
(chinese + english + math + 10)AS toltal_score -- 在原名AS+别名
FROM student;相关结果截图:

P 27 select 语句(3) 2022/7/20
1.基本使用方法(三)
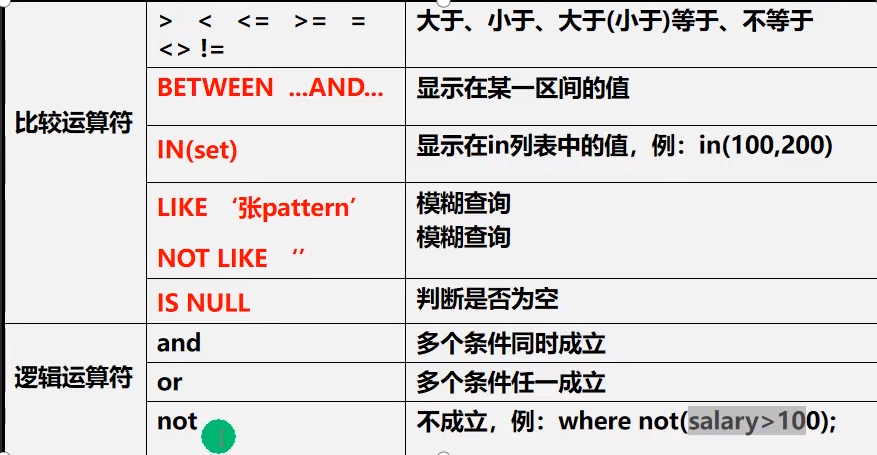
- 在where子句中经常使用的运算符
案例演示:使用where语句进行过滤查询
sql
-- 使用where语句进行过滤查询
SELECT * FROM student;
-- 查询姓名为赵云的学生成绩
SELECT * FROM student
WHERE `name` = '赵云';
-- 查询英语成绩大于90分的同学
SELECT * FROM student
WHERE `english` > 90;
-- 查询总分大于200分的所有同学
SELECT * FROM student
WHERE (chinese + english + math) > 200;
# 多个条件同时成立
-- 查询math大于60并且(and)id大于4的学生成绩
SELECT * FROM student
WHERE math > 60 AND id >4;
-- 查询英语成绩大于语文成绩的同 学
SELECT * FROM student
WHERE math > chinese;
-- 查询总分大于200 并且 数学成绩大于语文成绩的姓韩的同学
SELECT * FROM student
WHERE (math + chinese + english) > 200 AND
math > chinese AND
`name` LIKE '韩%'; # 后面 % 百分号代表后面不管是谁,匹配任意一个字符
# 代表 0-∞,韩一个字也可以匹配
-- 查询英语分数在80-90之间的同学 (在是一个区间)
SELECT * FROM student
WHERE english >= 80 AND english <=90; -- 方法一:多条件
SELECT * FROM student
WHERE english BETWEEN 80 AND 90; -- 方法二:between ... and ... 是一个闭区间[80,90]
-- 查询数学分数为89,90 ,91的同学。
SELECT * FROM student
WHERE math = 89 OR math = 90 OR math = 91;
SELECT * FROM student
WHERE math IN (80,90,91);
-- 查询所有姓张的学生成绩。
SELECT * FROM student
WHERE `name` LIKE '张%';
-- 查询数学分大于80,语文分大于80的同学。
SELECT * FROM student
WHERE math > 80 AND chinese > 80;小练习:

P 28 select 语句(4) 2022/7/21
1.基本使用方法(四)

练习演示:
sql
-- 演示order by的使用
-- 对数学成绩排序后输出【升序】
SELECT * FROM student
ORDER BY math;
-- 对总分按从高到低的顺序输出 【降序】
SELECT * FROM student
ORDER BY (math + chinese + english) DESC;
SELECT `id`,`name`,(chinese + math + english) AS total_score FROM student
ORDER BY total_score DESC;
-- 对姓李的学生成绩排序输出【升序】
SELECT `id`,`name`,(chinese + math + english) AS toltal_name FROM student
WHERE `name` LIKE '张%'
ORDER BY toltal_name; # 按照总分升序排序,将toltal_name换成(chinese + math + english)也可以,但是推荐前者,显示更清晰明了
INSERT INTO student # 重新插入一条记录
VALUES(9,'张良',90,89,78);P 29 统计函数 2022/7/22
1.统计函数count
代码演示:
sql
-- 演示mysql中统计函数的使用
-- conunt 函数的演示
SELECT * FROM student;
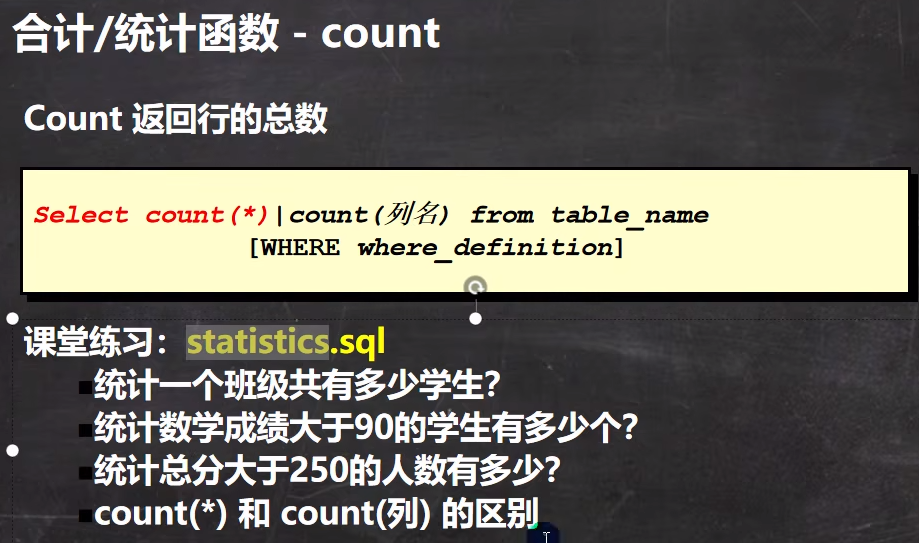
-- 1.统计一个班级共有多少个学生?
SELECT COUNT(*) FROM student; # 统计所有数据
-- 2.统计数学成绩大于90的学生有多少个?
UPDATE student
SET `math` = 99
WHERE `name` = '张良' # 更新一下数据,利于查询
SELECT COUNT(*) FROM student
WHERE `math` > 90
-- 3.统计总分大于250的人数有多少?
SELECT COUNT(*) FROM student
WHERE (chinese + math + english) > 250;
-- count(*) 和 count (列)的区别: 演示如下
-- 解释:
-- count(*) :返回满足条件记录的 行数
-- count(列) :统计满足条件的 某列 有多少个,但是会排除 为null ;
CREATE TABLE t15(
`name` VARCHAR(20));
INSERT INTO t15 VALUES('jake');
INSERT INTO t15 VALUES('tom');
INSERT INTO t15 VALUES('mary');
INSERT INTO t15 VALUES(NULL);
SELECT COUNT(*) FROM t15; -- 4
SELECT COUNT(`name`) FROM t15; -- 3 ,会排除空值,返回的是非空的,所以为32.求和函数sum
简介:sum函数满足where条件的行的和,一般使用在数值列
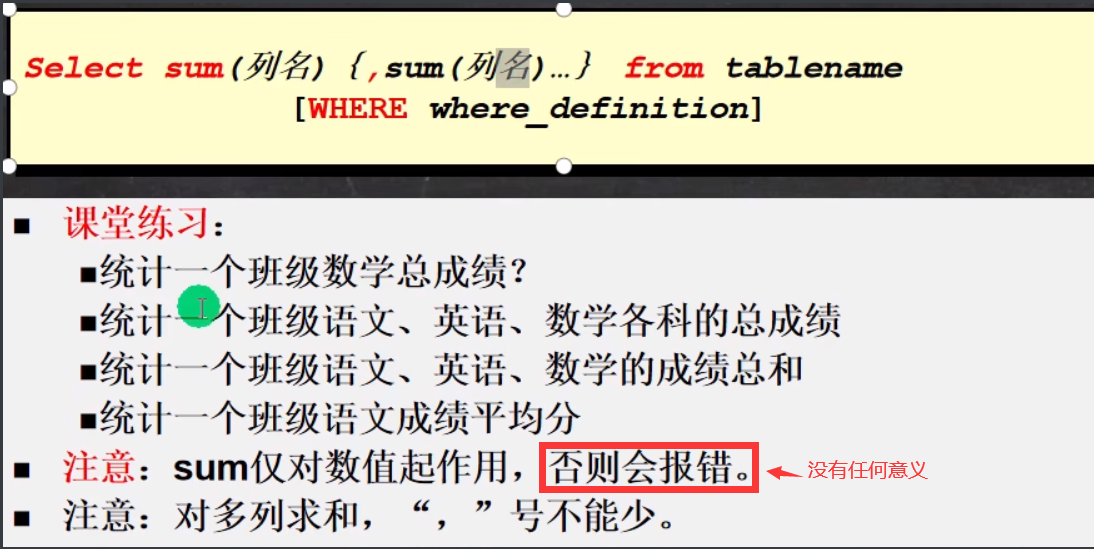
代码演示:
sql
-- 演示sum函数的使用
-- 1.统计一个班数学总成绩
SELECT SUM(math) FROM student;
-- 2.统计一个班语文、英语、数学各科的总成绩
SELECT SUM(math) AS math_totla_score,SUM(english),SUM(chinese) FROM student;
-- 3.统计一个班语文、英语、数学的成绩总和
SELECT SUM(math + chinese + english) AS exam_total FROM student;
-- 4.统计一个班语文成绩平均分
SELECT SUM(chinese)/COUNT(*) FROM student; -- sum计算出总分数除以count(*)计算的总人数得平均成绩3.平均值函数avg

代码演示:
sql
-- 演示avg的使用
-- 练习:
-- 1.求一个班级数学平均分?
SELECT AVG(math) FROM student;
-- 2.求一个班级总分的平均分?
SELECT AVG(math + english + chinese) FROM student;4.最大/小值max/min

代码演示:
sql
-- 演示max和min的使用
-- 1.求班级最高分和最低分
SELECT MAX(math + english + chinese),MIN(math + chinese + english) FROM student;
-- 2.求班级的数学最高分和最低分
SELECT MAX(math) AS math_high_score,MIN(math) AS math_low_score FROM student;P 30 分组统计 2022/7/23
1.group by / having
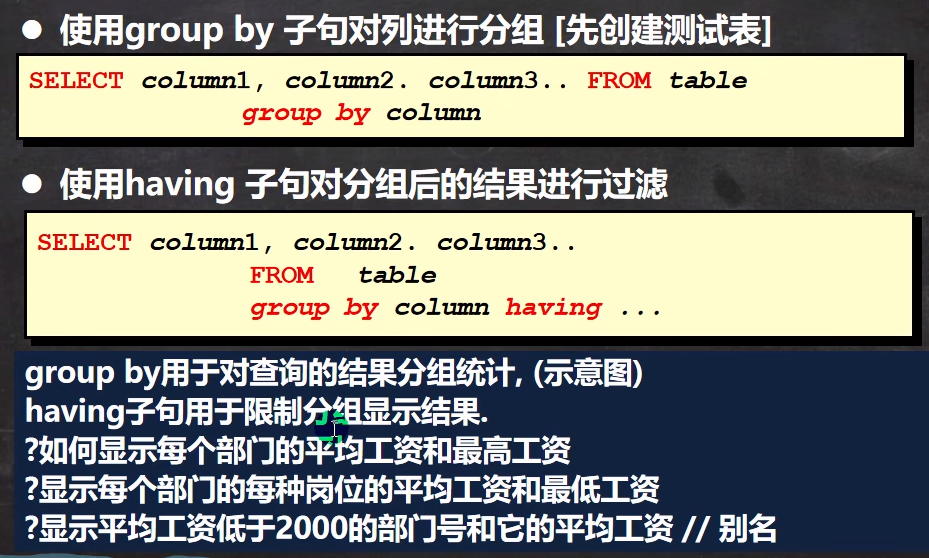
代码演示及其说明:
sql
-- 演示group by + having
-- group by 子句用于对查询的结果分组统计
-- having子句用于限制分组显示结果(一般情况下,where用于过滤数据行,为having用于过滤分组)
CREATE TABLE dept( /*部门表*/
depno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
);
INSERT INTO dept
VALUES(10,'ACCOUNTING','NEW YORK'),(20,'RESEARCH','DALLAS'),
(30,'SALES','CHICAGO'),(40,'OPERATTIONS','BOSTON')
-- 员工表
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*. 工作*/
mgr MEDIUMINT UNSIGNED , /*.上级编号*/
hiredate DATE NOT NULL, /*入职时间*/
sal DECIMAL(7 ,2) NOT NULL, /*薪水*/
comm DECIMAL(7,2) , /*福利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门 门编号*/
);
-- 添加测试数据
INSERT INTO emp VALUES
(7369,'SMITH','CLERK' ,7902,'1990-12-17' ,800.00,NULL,20),
(7499,'ALLEN' ,' SALESMAN',7698, '1991-2-20' ,1600.00, 300.00, 30) ,
(7521,' WARD',' SALESMAN',7698, '1991-2-22' ,1250.00, 500.00, 30) ,
(7566, 'JONES','MANAGER' ,7839, '1991-4-2' ,2975.00 , NULL,20),
(7654, ' MARTIN ' ,' SALESMAN' ,7698, '1991-9-28' ,1250.00 ,1400.00,30),
(7698,'BLAKE' ,'MANAGER',7839, '1991-5-1',2850.00 , NULL,30) ,
(7782, ' CLARK',' MANAGER ',7839, '1991-6-9' , 2450.00 , NULL,10) ,
(7788,' SCOTT' , 'ANALYST' , 7566,'1997-4-19' , 3000.00 , NULL,20),
(7839, 'KING','PRESIDENT' , NULL, '1991-11-17' , 5000.00 , NULL,10),
(7844,' TURNER',' SALESMAN' , 7698,'1991-9-8' ,1500.00,NULL,30) ,
(7900, ' JAMES','CLERK' , 7698, ' 1991-12-31' , 950.00 , NULL, 30) ,
(7902, ' FORD','IANALYST' , 7566, '1991-12-31' ,3000.00, NULL, 20),
(7934, 'MILLER','CLERK' , 7782,' 1992-1-23',1300.00, NULL,10) ;
-- 工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 , /*工资级别*/
losal DECIMAL(17 ,2) NOT NULL, /*该级别的最低工资*/
hisal DECIMAL(17 ,2) NOT NULL /*该级别的最高工资*/
);
INSERT INTO salgrade VALUES (1, 700,1200) ;
INSERT INTO salgrade VALUES (2 ,1201,1400) ;
INSERT INTO salgrade VALUES (3, 1401 ,2000) ;
INSERT INTO salgrade VALUES (4, 2001, 3000) ;
INSERT INTO salgrade VALUES (5,3001,9999) ;
SELECT * FROM salgrade; -- 工资级别表
SELECT * FROM emp; -- 员工表
SELECT * FROM dept; -- 部门表
-- 1.如何显示每个部门的最高工资和平均工资?
-- 分析:avg(sal) max(sal)
SELECT AVG(sal),MAX(sal),deptno
FROM emp GROUP BY deptno; -- group by deptno按照部门分组查询
-- 使用数学方法,保留两位小数
SELECT FORMAT(AVG(sal),2),MAX(sal),deptno
FROM emp GROUP BY deptno;
-- 2.显示每个部门的每种岗位的平均工资和最低工资?
-- 分析:* 显示每个部门的平均工资和最低工资
-- * 显示每个部门的每种岗位的平均工资和最低工资
SELECT MIN(sal) AS min_sal,AVG(sal)AS avg_sal,deptno,job -- 首先对部门进行分组,然后再对岗位
FROM emp GROUP BY deptno,job;
-- 3.显示平均工资低于2000的部门号和它的平均工资 //别名
-- 分析:[写sql语句的思路是化繁为简,各个击破]
-- * 显示各个部门的平均工资和部门号
SELECT AVG(sal),deptno
FROM emp GROUP BY deptno;
-- * 在上面分析的记过进行一个过滤,保留 平均工资小于2000的
-- * 使用别名进行过滤
SELECT AVG(sal),deptno
FROM emp GROUP BY deptno
HAVING AVG(sal) < 2000;
SELECT AVG(sal) AS avg_sal,deptno /*使用别名,只需要计算一次,提升一个效率*/
FROM emp GROUP BY deptno
HAVING avg_sal < 2000;
-- 如何理解分组?
-- 答:如果不使用分组,那么函数返回的数据只有一条,统计表内所有数据;
-- 如果使用分组,返回的数据有组的个数条(组个数条=返回的数据条数),函数分别对各组进行统计。