目录
[清单文件(Manifest File)](#清单文件(Manifest File))
[数据文件(Data File)](#数据文件(Data File))
[增量更新(Incremental Updates)](#增量更新(Incremental Updates))
[变更日志(Change Log)](#变更日志(Change Log))
[统一存储(Unified Storage)](#统一存储(Unified Storage))
[生态系统集成(Ecosystem Integration)](#生态系统集成(Ecosystem Integration))
背景
在大数据处理领域,传统的数据仓库和数据湖解决方案在处理实时数据和大规模数据时面临诸多挑战,如数据一致性、高性能查询、实时更新等。随着实时数据分析需求的不断增加,业界迫切需要一种能够高效处理大规模流式数据的存储系统。
诞生
Paimon 最初名为 Flink Table Store,是在 Apache Flink 社区内部于2022年1月启动的一个项目。目标是希望开发一个高性能的流式数据湖存储系统,支持高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。并且与2024年4月16号毕业成为Apache的顶级项目。
应用场景
Apache Paimon的应用场景主要集中在需要高吞吐、低延迟数据摄入、流式订阅以及实时查询能力的领域。以下是对其应用场景的详细归纳:
实时数据分析与查询
- **金融行业:**可用于实时风险分析、欺诈检测等场景,通过实时处理交易数据,及时发现潜在风险。
- **电子商务:**在电商平台上,Paimon可用于实时推荐系统,通过分析用户行为数据,实时推送个性化商品推荐。
- **物联网:**在物联网场景中,Paimon可以处理来自传感器的大量实时数据,实现设备监控、故障预警等功能。
流批一体处理
- **统一存储:**Paimon支持流处理和批处理的无缝切换,使得同一份存储可以同时服务于流处理和批处理作业,降低了开发和运维的复杂度。
- **复杂计算逻辑:**在处理具有复杂计算逻辑的数据时,如宽表加工、JOIN操作和复杂的ETL等,Paimon能够提供高效的存储和查询性能。
低成本高效存储
- **高存储成本场景:**对于存储成本较高的场景,如大量数据的持久化存储,Paimon通过其高效的存储格式和压缩策略,能够显著降低存储成本。
- **数据湖生态:**作为数据湖的一部分,Paimon可以与其他大数据组件无缝集成,构建完整的数据湖生态,实现数据的集中存储和高效使用。
具体业务场景示例
- **样本生成链路:**在样本生成过程中,Paimon可以作为数据镜像及DimJoin维表,实现样本处理过程中的数据存储需求,降低存储成本并提高处理效率。
- **在线检索引擎:**通过支持Paimon这种湖格式,在线检索引擎可以直接从Paimon中读取数据,减少依赖组件,提升整体链路的可控性和运维效率。
总结
综上所述,Apache Paimon凭借其高吞吐、低延迟、流批一体以及低成本高效存储等特性,在实时数据分析与查询、流批一体处理、低成本高效存储等多个方面都有广泛的应用。
系统架构
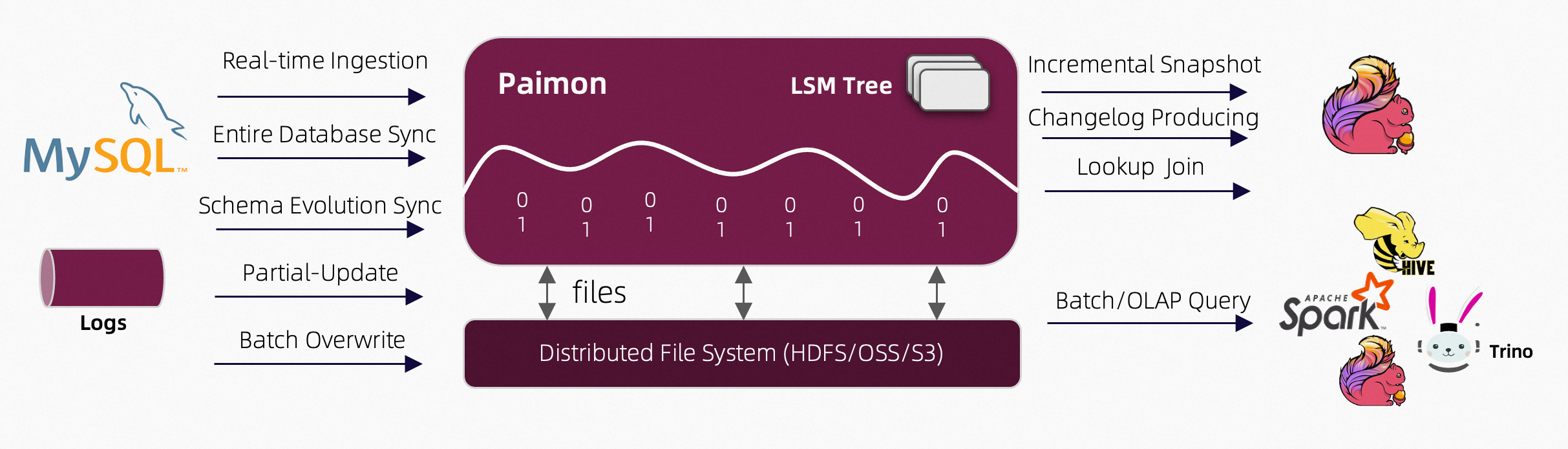
Apache Paimon 是一个高性能的数据存储和查询分析引擎,其设计目标是支持高吞吐、低延迟的数据摄入和实时查询。Paimon 的系统架构主要包括以下几个关键组件和概念:
存储层
- 列式存储:Paimon 使用列式存储格式(如 Parquet、ORC),这种格式非常适合大规模数据的压缩和查询优化。
- LSM 树结构:Paimon 采用了 LSM (Log-Structured Merge) 树结构,这种结构支持高效的写入操作和合并机制,确保数据的高吞吐和低延迟。
- 数据分区:Paimon 支持数据分区,可以根据时间、键值或其他维度对数据进行分区,提高查询性能。
元数据管理
- 元数据存储:Paimon 使用一个独立的元数据存储系统来管理表结构、分区信息、事务日志等元数据。常见的元数据存储系统包括 MySQL、Hive Metastore 等。
- 事务管理:Paimon 提供 ACID 事务支持,确保数据操作的一致性和可靠性。事务管理模块负责记录和管理事务日志,支持多版本并发控制(MVCC)。
计算层
- SQL 引擎:Paimon 提供了一个 SQL 引擎,支持标准的 SQL 查询。用户可以通过 SQL 语句进行数据查询、插入、更新和删除操作。
- 计算引擎集成:Paimon 可以与多种计算引擎(如 Apache Flink、Apache Spark、Trino)集成,提供丰富的数据处理和分析能力。这些计算引擎可以读取和写入 Paimon 存储的数据,实现复杂的数据处理和分析任务。
数据摄入和输出
- 数据摄入:Paimon 支持多种数据摄入方式,包括批量加载、流式摄入和事务性写入。数据摄入模块负责将外部数据源的数据高效地写入 Paimon 存储。
- 数据输出:Paimon 支持将数据导出到其他系统,如数据仓库、数据湖、消息队列等。数据输出模块负责将 Paimon 存储的数据高效地导出到目标系统。
查询优化
- 索引:Paimon 支持多种索引类型,如 B-Tree 索引、Bitmap 索引等,用于加速查询性能。
- 查询优化器:Paimon 内置了一个查询优化器,可以根据查询条件和数据分布自动选择最优的查询计划,提高查询效率。
扩展性和可靠性
- 水平扩展:Paimon 设计为分布式系统,支持水平扩展。可以通过增加更多的节点来提升系统的处理能力和存储容量。
- 容错机制:Paimon 提供了多种容错机制,如数据复制、故障恢复等,确保系统的高可用性和数据的可靠性。
生态系统集成
- 数据连接器:Paimon 提供了多种数据连接器,可以与不同的数据源和目标系统进行集成,如 Kafka、HDFS、S3、数据库等。
- 工具和库:Paimon 还提供了丰富的工具和库,帮助用户进行数据迁移、备份、恢复等操作。
总结
Apache Paimon 的系统架构设计旨在支持高性能的数据存储和实时查询,通过列式存储、LSM 树结构、元数据管理、计算层集成、查询优化等多个组件的协同工作,确保了系统的高吞吐、低延迟和高可用性。
核心概念
Apache Paimon 是一个开源的数据存储和查询分析引擎,旨在支持海量数据的高效存储和实时分析。它具有高度的扩展性和灵活性,能够处理半结构化和非结构化数据,适用于流处理、批处理和OLAP(在线分析处理)等多种应用场景。本文将详细介绍Paimon的核心概念,帮助你更好地理解和使用这一强大的数据处理工具。
表(Table)
在Paimon中,表是最基本的数据组织单元。每个表都有一个定义好的模式(Schema),包括列名、数据类型和主键。表可以是非分区表,也可以是分区表,后者通过将数据按照特定列的值进行划分,以提高查询性能。
示例:
CREATE TABLE my_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id)
) PARTITIONED BY (age);在这个例子中,my_table 是一个分区表,按照 age 列进行分区。
模式(Schema)
模式定义了表的结构,包括列的名称、数据类型和主键。Paimon支持动态改变表的模式,允许在不中断现有数据处理的情况下添加新的字段。
示例:
ALTER TABLE my_table ADD COLUMNS (email STRING);这条命令将向 my_table 表中添加一个新的列 email。
分区(Partition)
分区是将表中的数据物理地划分为多个部分的技术,通常基于某些字段的值。分区可以显著提高查询性能,特别是在处理大规模数据集时。Paimon支持静态和动态分区。
示例:
CREATE TABLE my_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id)
) PARTITIONED BY (age);在这个例子中,my_table 表按照 age 列进行分区。查询时,Paimon只需扫描相关的分区,从而减少I/O操作和提高查询速度。
快照(Snapshot)
快照捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据,也可以通过较早的快照访问表的先前状态。快照机制支持时间旅行查询(Time Travel Query),即能够查询特定时间点的数据状态。
示例:
SELECT * FROM my_table FOR SYSTEM_TIME AS OF '2023-10-01 00:00:00';这条命令将查询 my_table 表在2023年10月1日00:00:00时的状态。
清单文件(Manifest File)
清单文件是包含有关LSM(Log-Structured Merge-Tree)数据文件和更改日志文件的更改的文件。每个快照文件都包含一个或多个清单文件,这些清单文件记录了快照中创建或删除的数据文件。
示例:
{
"files": [
{
"path": "data/00000001-00001-00001-00001.parquet",
"partition_values": {"age": 30},
"file_size": 1024,
"num_records": 100
}
]
}这个清单文件记录了快照中包含的一个数据文件的路径、分区值、文件大小和记录数。
数据文件(Data File)
数据文件按分区分组,存储实际的数据。Paimon支持多种数据文件格式,包括ORC、Parquet和Avro。这些格式都是列式存储格式,适用于高效的数据压缩和查询。
示例:
CREATE TABLE my_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id)
) PARTITIONED BY (age) WITH ('format'='parquet');在这个例子中,my_table 表的数据文件格式设置为Parquet。
事务(Transaction)
Paimon支持ACID事务,确保数据操作的一致性和可靠性。每次写入操作都会在一个事务上下文中执行,如果事务失败,所做的更改将被回滚,保证数据的一致性。
示例:
BEGIN TRANSACTION;
INSERT INTO my_table (id, name, age) VALUES (1, 'Alice', 30);
COMMIT;这段代码演示了一个典型的事务操作,包括开始事务、插入数据和提交事务。
增量更新(Incremental Updates)
Paimon支持增量更新,允许用户只更新表中发生变化的部分,而不是重新处理整个表。这对于持续更新的实时应用非常重要。
示例:
MERGE INTO my_table
USING (
SELECT 1 as id, 'Alice' as name, 31 as age
) updates
ON my_table.id = updates.id
WHEN MATCHED THEN UPDATE SET age = updates.age;这条命令将更新 my_table 表中 id 为1的记录的 age 字段。
变更日志(Change Log)
Paimon支持生成变更日志,记录表中数据的每一次更改。变更日志可以用于构建流式数据处理管道,实现实时数据同步和订阅。
示例:
CREATE TABLE change_log (
id INT,
name STRING,
age INT,
op STRING
) WITH ('connector'='kafka', 'topic'='change-topic');这条命令创建了一个Kafka连接器,用于将 my_table 表的变更日志发送到Kafka主题 change-topic。
统一存储(Unified Storage)
Paimon采用统一存储架构,将列式存储和LSM树结构相结合,支持大规模数据更新和高性能查询。这种架构使得Paimon能够在流处理和批处理之间无缝切换,提供一致的数据视图。
示例:
CREATE TABLE my_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id)
) PARTITIONED BY (age) WITH ('format'='parquet', 'storage'='s3');在这个例子中,my_table 表的数据存储在Amazon S3上,使用Parquet格式。
生态系统集成(Ecosystem Integration)
Paimon与多个大数据生态系统组件紧密集成,包括Apache Flink、Apache Spark、Trino等。这些集成使得Paimon可以与其他计算引擎无缝协作,提供丰富的数据处理和分析能力。
示例:
-- 使用Flink SQL查询Paimon表
SELECT * FROM my_table WHERE age > 30;这条命令使用Flink SQL查询 my_table 表中 age 大于30的记录。
总结
Apache Paimon 是一个强大的数据存储和查询分析引擎,具有高度的扩展性和灵活性。通过理解其核心概念,你可以更好地利用Paimon的功能,构建高效的数据处理和分析应用。无论是流处理、批处理还是OLAP,Paimon都能提供一致且高性能的数据存储和查询能力。