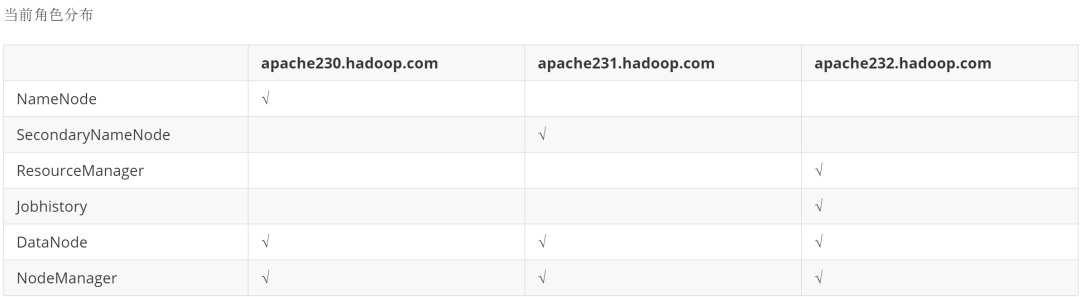
节点信息请参考:
zookeeper: Apache Hadoop生态组件部署分享-zookeeper
1.1 上传安装包并解压
apache
tar -xf hadoop-3.4.1.tar.gz -C /opt/apache/#创建临时目录,下面配置中会用到mkdir /opt/apache/hadoop-3.4.1/tmp#配置jn数据存储路径会用到mkdir /opt/apache/hadoop-3.4.1/data1.2 配置core-site.xml文件
xml
<configuration><!--默认的文件系统--><property> <name>fs.defaultFS</name> <value>hdfs://apache230.hadoop.com:8020</value></property><!--其他临时目录的基础--><property> <name>hadoop.tmp.dir</name> <value>/opt/apache_v00/hadoop-3.3.5/tmp</value></property></configuration>1.3 配置hdfs-site.xml文件
xml
<configuration><!-- secondaryNameNode Web UI端口 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>apache231.hadoop.com:9868</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/apache_v00/hadoop-3.3.5/data/nn</value> </property> <property> <name>dfs.namenode.name.dir.restore</name> <value>true</value> </property></configuration>1.4 配置yarn-site.xml
xml
<configuration><property> <description>resourmanager的主机名称</description> <name>yarn.resourcemanager.hostname</name> <value>apache232.hadoop.com</value></property><property> <description>扩展NodeManager的功能,使其能够为上层计算框架(如 MapReduce, Spark)提供超出基本容器管理之外的数据交换服务</description> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property> <description>对应上面mapreduce_shuffle的实现类</description> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>1.5 配置 mapred-site.xml文件
xml
<configuration><property> <description>用于执行MapReduce作业的运行时框架。可选值为 local、classic(1.x中使用,已过时) 或 yarn</description> <name>mapreduce.framework.name</name> <value>yarn</value></property><property> <description>MapReduce 作业历史服务器的 IPC 主机地址和端口</description> <name>mapreduce.jobhistory.address</name> <value>apache232.hadoop.com:10020</value></property><property> <description>MapReduce 作业历史服务器的 IPC 主机地址和端口</description> <name>mapreduce.jobhistory.webapp.address</name> <value>apache232.hadoop.com:19888</value></property></configuration>1.6 执行NameNode格式化
在 apache230.hadoop.com节点执行命令
nginx
hdfs namenode -format1.7 启动服务
css
#apache230.hadoop.com执行启动命令hdfs --daemon start namenodehdfs --daemon start datanodeyarn --daemon start nodemanager#apache231.hadoop.com执行启动命令hdfs --daemon start secondarynamenodehdfs --daemon start datanodeyarn --daemon start nodemanager#apache232.hadoop.com执行启动命令yarn --daemon start resourcemanagerhdfs --daemon start datanodeyarn --daemon start nodemanagermapred --daemon start historyserver1.8 打开相关webui验证
namenode ui
http://192.168.242.230:9870/dfshealth.html#tab-overview
resourcemanager ui
http://192.168.242.232:8088/cluster
JobHistory WEB UI页面
http://192.168.242.232:19888/jobhistory
1.9 namenode 高可用配置
以下为修改后各个配置内容
A.core-site.xml
xml
<configuration><!--默认的文件系统--><property> <name>fs.defaultFS</name> <value>hdfs://nameservice1</value></property><!--其他临时目录的基础--><property> <name>hadoop.tmp.dir</name> <value>/opt/apache_v00/hadoop-3.3.5/tmp</value></property></configuration>B.hdfs-site.xml
xml
<configuration><!-- 完全分布式集群名称 --><property> <name>dfs.nameservices</name> <value>nameservice1</value></property><!--集群中NameNode节点都有哪些--><property> <name>dfs.ha.namenodes.nameservice1</name> <value>namenode1,namenode2</value></property><!--namenode1 的RPC通信地 --><property> <name>dfs.namenode.rpc-address.nameservice1.namenode1</name> <value>apache230.hadoop.com:8020</value></property><!-- namenode2 的RPC通信地 --><property> <name>dfs.namenode.rpc-address.nameservice1.namenode2</name> <value>apache231.hadoop.com:8020</value></property><!-- namenode1 web ui地址与端口 --><property> <name>dfs.namenode.http-address.nameservice1.namenode1</name> <value>apache230.hadoop.com:9870</value></property><!-- namenode2 web ui地址与端口 --><property> <name>dfs.namenode.http-address.nameservice1.namenode2</name> <value>apache231.hadoop.com:9870</value></property><!-- NameNode1 安全 HTTP 服务器的地址和端口。--><property> <name>dfs.namenode.https-address.nameservice1.namenode1</name> <value>apache230.hadoop.com:9871</value></property><!-- NameNode2 安全 HTTP 服务器的地址和端口 --><property> <name>dfs.namenode.https-address.nameservice1.namenode2</name> <value>apache231.hadoop.com:9871</value></property><!--指定NameNode读写JournalNode组的uri,通过这个uri,NameNodes可以读写edit log内容--><property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://apache230.hadoop.com:8485;apache231.hadoop.com:8485;apache232.hadoop.com:8485/nameservice1</value></property><!--shell(true)就是直接返回隔离成功,即表示没进行任何操作 --><property> <name>dfs.ha.fencing.methods</name> <value>shell(true)</value></property><!-- 声明journalnode服务器存储目录--><property> <name>dfs.journalnode.edits.dir</name> <value>/opt/apache_v00/hadoop-3.3.5/data/jn</value></property><!-- 关闭权限检查,像Linux上权限检查一下--><property> <name>dfs.permissions.enable</name> <value>false</value></property><!--客户端与活动状态的NameNode进行交互的JAVA实现类。由于有两个NameNode,只有活动NameNode可以对外提供读写服务,当客户端访问HDFS时,客户端将通过该类寻找当前的活动NameNode。 目前Hadoop的唯一实现是ConfiguredFailoverProxyProvider类,除非用户自己对其定制,否则应该使用这个类。--><property> <name>dfs.client.failover.proxy.provider.nameservice1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!--设置为 true 时,NameNode 会尝试恢复之前失败过的 dfs.namenode.name.dir。启用后,在检查点(checkpoint)过程中会尝试恢复任何失败的目录。 如果dfs.namenode.name.dir只是配置了单目录则是无法恢复--><property> <name>dfs.namenode.name.dir.restore</name> <value>true</value></property><!--file:///opt/apache_v00/hadoop-3.3.5/data/nn路径为首次格式化的namenode存储路径--><property> <name>dfs.namenode.name.dir.nameservice1.namenode1</name> <value>file:///opt/apache_v00/hadoop-3.3.5/data/nn,file:///opt/apache_v00/hadoop-3.3.5/data/nn2</value></property><property> <name>dfs.namenode.name.dir.nameservice1.namenode2</name> <value>file:///opt/apache_v00/hadoop-3.3.5/data/nn,file:///opt/apache_v00/hadoop-3.3.5/data/nn2</value></property><property> <name>ha.zookeeper.quorum</name> <value>apache230.hadoop.com:2181,apache231.hadoop.com:2181,apache232.hadoop.com:2181</value></property><property> <name>dfs.ha.automatic-failover.enabled.nameservice1</name> <value>true</value></property></configuration>C.分发配置文件
ruby
cd /opt/apache_v00/hadoop-3.3.5/etc/hadoopscp hdfs-site.xml core-site.xml yarn-site.xml mapred-site.xml 192.168.242.231:/opt/apache_v00/hadoop-3.3.5/etc/hadoop/scp hdfs-site.xml core-site.xml yarn-site.xml mapred-site.xml 192.168.242.232:/opt/apache_v00/hadoop-3.3.5/etc/hadoop/D.停止所有服务
css
#apache230.hadoop.com执行命令hdfs --daemon stop namenodehdfs --daemon stop datanode
#apache231.hadoop.com执行命令hdfs --daemon stop secondarynamenodehdfs --daemon stop datanode
#apache232.hadoop.com执行命令hdfs --daemon stop datanode
#apache23[0-2].hadoop.com执行命令(三台都执行)hdfs --daemon start journalnode
#创建路径,要不然下面步骤会报错mkdir /opt/apache_v00/hadoop-3.3.5/data/nn2
#apache230.hadoop.com执行命令hdfs namenode -initializeSharedEditshdfs zkfc -formatZKhdfs --daemon start namenode
#apache231.hadoop.com执行命令hdfs namenode -bootstrapStandby
#apache23[0-1].hadoop.com执行命令hdfs --daemon start zkfc
#apache231.hadoop.com执行命令hdfs --daemon start namenode
#apache23[0-2].hadoop.com执行命令(三台都执行)hdfs --daemon start datanodeE.验证高可用
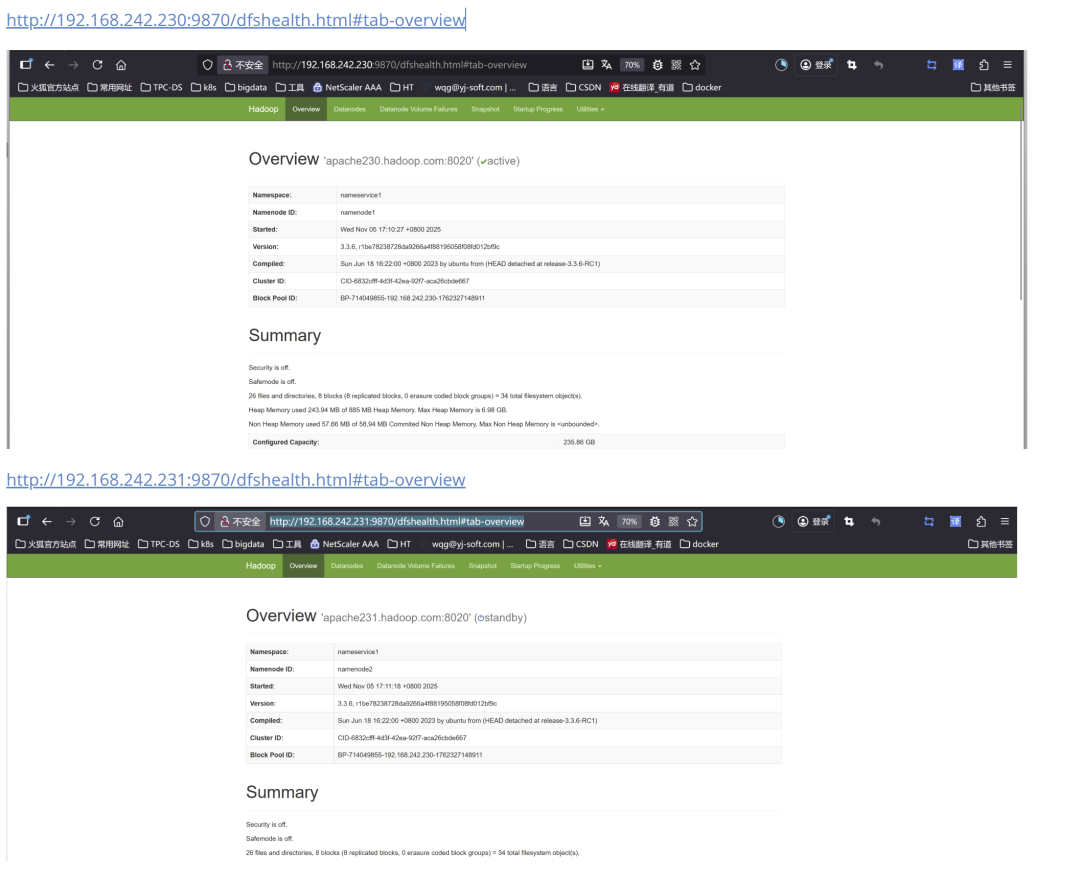
1.10 ResourceManager高可用
A.yarn-site.xml
xml
<configuration>
<!-- Site specific YARN configuration properties --><property> <description>扩展NodeManager的功能,使其能够为上层计算框架(如 MapReduce, Spark)提供超出基本容器管理之外的数据交换服务</description> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property>
<property> <description>对应上面mapreduce_shuffle的实现类</description> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
<!--start 高可用配置--><property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value></property><property> <description>集群名称。在高可用性(HA)环境中,该名称用于确保资源管理器参与此集群的领导者选举,并保证不会影响其他集群。</description> <name>yarn.resourcemanager.cluster-id</name> <value>yarnRM</value></property><property> <description>两个RM的唯一标识</description> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm231,rm232</value></property><property> <description>第一个RM部署在的机器名</description> <name>yarn.resourcemanager.hostname.rm231</name> <value>apache231.hadoop.com</value></property><property> <description>第二个RM部署在的机器名</description> <name>yarn.resourcemanager.hostname.rm232</name> <value>apache232.hadoop.com</value></property><property> <description>第一个RM的web ui的端口</description> <name>yarn.resourcemanager.webapp.address.rm231</name> <value>apache231.hadoop.com:8088</value></property><property> <description>第二个RM的web ui的端口</description> <name>yarn.resourcemanager.webapp.address.rm232</name> <value>apache232.hadoop.com:8088</value></property><property> <description>zk的部署的主机名和端口</description> <name>yarn.resourcemanager.zk-address</name> <value>apache230.hadoop.com:2181,apache231.hadoop.com:2181,apache232.hadoop.com:2181</value></property><!--end 高可用配置-->
<!--start 日志聚合--><property> <description>是否启用日志聚合功能。日志聚合会收集每个容器的日志,并在应用程序完成后将这些日志转移到文件系统(例如HDFS)。 用户可通过配置"yarn.nodemanager.remote-app-log-dir"和"yarn.nodemanager.remote-app-log-dir-suffix"属性来确定日志转移的目标位置。 用户可通过应用程序时间轴服务器访问这些日志。</description> <name>yarn.log-aggregation-enable</name> <value>true</value></property><property> <description>保留聚合日志多久.此值不宜设置太小,否则会滥发请求给到namenode</description> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value></property><property> <description>聚合日志在HDFS上的位置</description> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value></property><property> <description>远程日志目录的创建路径为:{yarn.nodemanager.remote-app-log-dir}/${user}/{此参数}</description> <name>yarn.nodemanager.remote-app-log-dir-suffix</name> <value>logs</value></property><property> <description>定义 NodeManager 唤醒并上传日志文件的频率。默认值为 -1。默认情况下,日志会在应用程序结束时上传。通过设置该参数,可以在应用运行过程中周期性地上传日志。 可接受的最小正值由参数 yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds.min 配置。</description> <name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds</name> <value>-1</value></property><property> <description>定义 yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds 的最小正硬性限制。如果该配置被设置得低于默认值(3600),NodeManager 可能会发出警告</description> <name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds.min</name> <value>3600</value></property><property> <description>日志聚合服务器URL</description> <name>yarn.log.server.url</name> <value>http://apache232.hadoop.com:19888/jobhistory/logs</value></property>
<!--end 日志聚合-->
</configuration>B.分发yarn-site.xml
ruby
cd /opt/apache_v00/hadoop-3.3.5/etc/hadoopscp hdfs-site.xml core-site.xml yarn-site.xml mapred-site.xml 192.168.242.231:/opt/apache_v00/hadoop-3.3.5/etc/hadoop/scp hdfs-site.xml core-site.xml yarn-site.xml mapred-site.xml 192.168.242.232:/opt/apache_v00/hadoop-3.3.5/etc/hadoop/C.重启服务
css
#apache230.hadoop.com执行命令yarn --daemon stop nodemanageryarn --daemon start nodemanager
#apache231.hadoop.com执行命令yarn --daemon stop resourcemanageryarn --daemon start resourcemanageryarn --daemon stop nodemanageryarn --daemon start nodemanager
#apache232.hadoop.com执行命令yarn --daemon stop resourcemanageryarn --daemon start resourcemanageryarn --daemon stop nodemanageryarn --daemon start nodemanagermapred --daemon stop historyservermapred --daemon start historyserver后面你可以执行去验证是否可以正常提交:
apache
hadoop jar /opt/apache_v00/hadoop-3.3.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.5.5.jar pi 2 4后面会分享hive