在Java中,final 关键字可以用于修饰类、方法和变量:
- 修饰类:
-
- 被
final修饰的类不能被继承,即不能有子类。 - 这通常用于工具类或者不希望被扩展的类。
- 被
- 修饰方法:
-
- 被
final修饰的方法不能被子类覆盖。 - 这通常用于确保类的行为不会被改变,或者在性能优化时,因为方法覆盖检查会带来一定的开销。
- 被
但是:
- 不能被重写(Override) :
final方法不能在子类中被重写。这是因为final方法的设计意图是让这个方法在继承链中不再改变,确保所有继承这个类的子类都使用同一个方法实现。 - 可以被重载(Overload) :尽管
final方法不能被重写,但它们仍然可以被重载。重载是指在同一个类中定义多个同名方法,但这些方法的参数列表必须有所不同(参数的数量、类型或顺序不同)。
- 修饰变量:
-
- 被
final修饰的变量是常量,一旦赋值后就不能被修改。 - 常量名通常以大写字母开始,并使用下划线分隔单词,以提高可读性。
- 修饰成员变量:类中被声明为
final的成员变量必须在声明时初始化或者在构造器中初始化,之后不能被修改。 - 修饰局部变量:方法中被声明为
final的局部变量必须在声明时初始化或者在声明后的立即一次赋值,之后不能被修改。
- 被
private 和 protected 访问修饰符,控制成员变量和方法的可见性:
- private:
-
private成员变量或方法只能在声明它的类内部访问。private方法不能被子类继承,子类无法访问父类的private方法。private变量同样不能被子类继承或访问。private修饰的成员是最不可见的。
- protected:
-
protected成员变量或方法可以在同一个包内的其他类以及不同包中的子类中访问。protected方法可以被子类继承,子类可以访问父类的protected方法。protected变量也可以被子类继承和访问。protected修饰的成员比private可见性高,但比public可见性低。
区别:
- 可见性 :
private只能被同一个类访问,而protected可以被同一个包内的类以及所有子类访问。 - 继承 :
private成员和方法不参与继承,而protected成员和方法会被子类继承。 - 封装 :
private提供了最强的封装,因为它完全限制了外部访问。protected则在封装和灵活性之间提供了一个折中。
在Java中,限定符通常指的是访问修饰符,它们控制成员的可见性。访问修饰符包括 public、private、protected 以及包级私有(没有修饰符)。
abstract:是一个非访问修饰符,它用于声明抽象类和抽象方法。抽象类不能被实例化,抽象方法没有具体的实现,必须由子类提供实现。
在Java中,"短路"(short-circuit)求值是指在布尔表达式中,如果表达式的结果已经可以确定,那么就不会对表达式的其他部分进行求值。这通常发生在逻辑运算中,特别是使用逻辑AND(&&)和逻辑OR(||)操作符时。
Java的基本数据类型及其占用的内存空间如下:
byte:8位,占用1个字节。short:16位,占用2个字节。int:32位,占用4个字节。long:64位,占用8个字节。float:32位,占用4个字节。double:64位,占用8个字节。char:16位,占用2个字节。boolean:在Java虚拟机中没有定义其大小,但通常在数组中占用1个字节,在其他情况下占用4个字节。
Java中的多态性是面向对象编程(OOP)的一个核心概念。多态性使得同一个方法调用可以对不同的对象有不同的行为。
- 方法重载(Overloading):
-
- 同一个类中可以有多个同名方法,但参数列表必须不同(参数的类型、数量或顺序不同)。
- 编译器根据方法调用时提供的参数列表来决定具体调用哪个方法。
- 方法覆盖(Overriding):
-
- 子类可以覆盖(Override)父类中的方法,即子类提供了一个与父类方法同名、同参数列表的方法。
- 运行时多态性:在运行时,根据对象的实际类型来调用相应的方法。即使通过父类的引用调用该方法,如果对象是子类的实例,也会调用子类中覆盖的方法。
- 接口实现(Interface Implementation):
-
- 一个类可以实现一个或多个接口,接口中的方法在实现类中必须被具体实现。
- 可以通过接口类型的引用调用实现类中的方法,实现多态性。
- 抽象类和抽象方法:
-
- 抽象类是不能实例化的类,它包含一个或多个抽象方法,这些方法没有具体的实现。
- 子类继承抽象类时,必须提供抽象方法的具体实现,除非子类也是抽象的。
- 泛型(Generics):
-
- 从Java 5开始引入,允许在类、接口和方法中使用类型参数,以支持泛型编程。
- 泛型提供了一种方式来编写与类型无关的代码,可以提高代码的复用性和类型安全性。
抽象类:
抽象类可以包含没有具体实现的方法(抽象方法),也可以包含有具体实现的方法(非抽象方法)。
抽象类不能直接实例化,因为可能包含没有实现的方法。
如果子类不是抽象类,那么它必须实现父类中的所有抽象方法。如果一个抽象类的子类本身也是抽象类,那么它不需要实现父抽象类中的所有抽象方法。抽象类可以包含抽象方法,这些方法可以由更具体的子类来实现。如果子类也是抽象的,它可以推迟实现这些方法,直到有一个非抽象的子类出现。
抽象类可以实现一个或多个接口,并且必须提供接口中所有方法的实现,除非抽象类本身也是抽象的。
String 对象一旦创建,其内容就不能被改变。每次对 String 对象进行修改操作时,实际上都会生成一个新的 String 对象。而 StringBuilder 对象的内容可以被修改,这使得它在频繁修改字符串内容的场景下更加高效。
String 类和 StringBuilder 类都可以使用 + 运算符和 append() 方法进行字符串连接。不过,String 使用 + 运算符连接字符串时,每次连接都会生成新的 String 对象,而 StringBuilder 使用 append() 方法连接字符串时,是在原有对象上进行修改。
在Java中,即使使用 StringBuilder 或 StringBuffer 类型的对象,使用 + 号连接字符串时,Java编译器会将这个操作转换为使用 StringBuilder 的 append() 方法的调用来执行连接。这个过程实际上是创建了一个新的 StringBuilder 对象,然后在其上调用 append() 方法,最后通过 toString() 方法将结果转换为一个新的 String 对象。这意味着每次使用 + 连接操作时,都会生成一系列临时的 StringBuilder 对象和新的 String 对象。
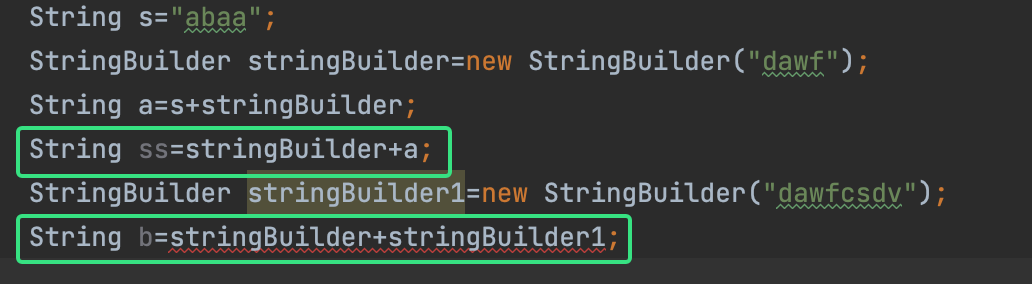
(是+String,不是两个StringBuilder + )
StringBuilder 和 StringBuffer的区别
- 线程安全性:
-
StringBuffer是线程安全的。这意味着它的所有操作都是同步的,可以在多线程环境中使用而不会出现问题。StringBuilder是非线程安全的。它的操作不是同步的,因此在单线程环境中性能更好,但在多线程环境中可能会遇到线程安全问题。
- 性能:
-
- 由于
StringBuilder不需要进行线程同步,所以在单线程环境中,它通常比StringBuffer有更好的性能。 StringBuffer由于需要进行线程同步,所以在性能上可能会稍逊于StringBuilder。
- 由于
- 使用场景:
-
- 如果你的代码在单线程环境中运行,并且需要频繁地修改字符串,那么
StringBuilder是更好的选择,因为它提供了更好的性能。 - 如果你的代码在多线程环境中运行,并且需要频繁地修改字符串,那么
StringBuffer是更好的选择,因为它是线程安全的。
- 如果你的代码在单线程环境中运行,并且需要频繁地修改字符串,那么
- API:
-
StringBuilder和StringBuffer都提供了类似的API,包括append()、insert()、delete()、replace()等方法,用于操作字符串。
- 默认构造方法:
-
StringBuilder的默认构造方法创建的是一个空的字符串缓冲区。StringBuffer的默认构造方法同样创建的是一个空的字符串缓冲区。
- 继承关系:
-
StringBuilder继承自AbstractStringBuilder类。StringBuffer也继承自AbstractStringBuilder类。
创建新线程:
继承Thread类并重写run()方法。
通过创建一个继承自 Thread 类的子类,并重写 run() 方法,然后创建该子类的实例并调用其 start() 方法,可以创建并启动一个新线程。
实现Runnable接口并实现run()方法。
通过创建一个实现了 Runnable 接口的类,并实现 run() 方法,然后将该类的实例传递给 Thread 类的构造函数,再调用新 Thread 实例的 start() 方法,可以创建并启动一个新线程。
使用Executor框架。
Executor 框架是Java并发API的一部分,它提供了一种管理线程池和执行异步任务的方法。通过使用 Executors 类的工厂方法创建一个线程池,然后使用 execute 方法提交一个实现了 Runnable 接口的对象,可以创建并启动新线程。
使用Callable和Future接口。
Callable 和 Future 接口与 Executor 框架一起使用,可以创建新线程。Callable 与 Runnable 类似,但它可以返回一个结果和抛出异常。通过使用 Executors 类创建一个线程池,然后使用 submit 方法提交一个实现了 Callable 接口的对象,可以创建并启动新线程。Future 接口用于获取异步执行的结果。
Stack 是一种后进先出(LIFO)的数据结构。
LinkedList 实现了 List 接口,但它也提供了 add、offer 等方法来实现队列的行为。
PriorityQueue 是一种优先队列,元素的出队顺序是根据元素的优先级来决定的,而不是按照先进先出的顺序。
ArrayDeque 是双端队列,但它也提供了标准的队列操作,如 addFirst、addLast、pollFirst、pollLast 等,可以用来实现标准的先进先出队列。
Java中的构造器:
- 初始化对象:构造器的主要目的是在创建新对象时初始化对象的状态。它允许程序员为对象的属性设置初始值。
- 分配资源:构造器可以在对象创建时分配必要的资源,比如打开文件、网络连接或数据库连接。
- 执行验证:构造器可以包含逻辑来验证对象的状态是否有效。如果传入的参数不满足某些条件,构造器可以抛出异常。
- 控制对象的创建:通过构造器,可以控制对象的创建过程。例如,可以通过构造器中的逻辑来决定是否应该创建一个新的对象实例。
- 提供不同的构造方式:一个类可以有多个构造器,每个构造器可以有不同的参数列表,这样可以提供多种方式来创建和初始化对象。
- 继承和多态:在继承中,子类的构造器会调用父类的构造器来确保父类属性的正确初始化。同时,构造器也可以体现出多态性,即通过父类引用可以创建不同类型的子类对象。
- 封装:构造器有助于封装对象的创建细节,用户不需要知道对象是如何被创建和初始化的,只需要知道如何使用对象。
- 避免对象状态不一致:通过在构造器中设置对象的初始状态,可以避免对象在创建后立即处于不一致状态。
- 实现设计模式:某些设计模式,如单例模式(Singleton),可能会利用构造器的特性来控制对象的创建。
java
public class Person {
// 类的属性
private String name;
private int age;
// 构造器
public Person(String name, int age) {
this.name = name; // 使用this关键字来区分成员变量和参数
this.age = age;
}
// Getter和Setter方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}transient修饰符用于声明一个变量不需要被序列化。
final和transient修饰符不能同时用于同一个变量。因为final变量的值是固定的,所以它不需要序列化,因为序列化是为了在反序列化时恢复对象的状态,而final变量的状态是不可变的。因此,同时使用final和transient修饰符是不合理的。
序列化(Serialization)和反序列化(Deserialization)是编程中的两个重要概念,尤其在对象持久化和网络传输中非常常见。这两个过程涉及到将对象的状态转换为可以存储或传输的格式,以及将这种格式转换回对象状态的过程。
序列化(Serialization)
序列化是指将对象的状态信息转换为可以存储在文件中或通过网络传输的格式(如JSON、XML或二进制格式)的过程。序列化通常用于以下场景:
- 持久化:将对象的状态保存到文件或数据库中,以便在程序下次运行时可以恢复对象的状态。
- 网络传输:在网络上发送对象时,需要将对象转换为可以在网络上传输的格式。由于网络传输只能处理字节流,因此需要将对象序列化为字节流。
反序列化(Deserialization)
反序列化是序列化的逆过程,它是指将序列化后的格式(如文件中的JSON、XML或二进制数据)转换回对象状态的过程。反序列化用于以下场景:
- 从持久化状态恢复对象:当从文件或数据库中读取序列化的对象数据时,需要将这些数据反序列化为对象,以便可以在程序中使用。
- 接收网络传输的对象:当从网络接收到序列化的对象数据时,需要将这些数据反序列化为对象,以便可以在本地环境中使用。
序列化和反序列化的目的
序列化和反序列化的目的是为了在不同的环境和时间点之间保持对象的状态。例如,如果你有一个复杂的对象,并且希望在用户会话之间保持该对象的状态,你可以将对象序列化并存储在数据库中。当用户再次访问系统时,你可以从数据库中读取序列化的数据并反序列化回对象,从而恢复对象的状态。
这个过程可以总结为:
- 序列化:对象 → 可存储/传输的格式
- 反序列化:可存储/传输的格式 → 对象
队列(Queue)是一种先进先出(FIFO, First-In-First-Out)的数据结构,而栈(Stack)是一种先进后出(LIFO, Last-In-First-Out)的数据结构。
先进先出(FIFO)的队列:
- 数组队列:使用数组实现的队列,元素从队列的一端添加,从另一端移除。
- 链表队列:使用链表实现的队列,元素同样从一端添加,从另一端移除。
- 循环队列:一种优化的数组队列,使用模运算来处理数组的循环使用。
- 优先队列(或堆):虽然通常不是严格意义上的FIFO,但可以按照元素的优先级进行出队操作。
- 双端队列(Deque):虽然双端队列允许从两端进行插入和删除操作,但它仍然可以以FIFO的方式工作。
先进后出(LIFO)的栈:
- 数组栈:使用数组实现的栈,元素从栈顶添加和移除。
- 链表栈:使用链表实现的栈,元素同样从栈顶添加和移除。
- 表达式栈:用于解析和计算表达式的栈,通常以LIFO的方式工作。
- 调用栈:在程序执行过程中,用于存储函数调用的栈,当函数返回时,最后一个调用的函数首先被移除。
其他类型的队列:
- 后进先出(LIFO)队列:虽然不是标准的队列,但可以通过栈实现这种类型的队列。
- 广度优先搜索队列:在图算法中使用,通常以FIFO的方式工作,但也可以用于实现其他类型的队列。
- 消息队列:在分布式系统中使用,可以有多种行为,包括FIFO和非FIFO。
文件系统是计算机操作系统中用于管理文件存储和访问的系统。它定义了数据在存储介质(如硬盘、固态硬盘、USB驱动器等)上的组织方式。
- 扇区(Sector):
-
- 扇区是磁盘存储的最小物理单位。
- 磁盘被划分为许多同心圆,每个同心圆被进一步划分为扇区。
- 每个扇区通常包含512字节或4096字节(随着技术的发展,扇区大小也在增加)。
- 扇区是读写磁盘数据的最小单位。
- 页面(Page):
-
- 页面通常是指内存管理中的单位。
- 在虚拟内存系统中,页面是内存被划分的固定大小的块。
- 操作系统使用页面来管理内存,将数据从磁盘交换到RAM,或从RAM交换到磁盘。
- 页面的大小通常为4KB。
- 簇(Cluster/Allocation Unit/Disk Block):
-
- 簇是文件系统在磁盘上分配空间的最小单位。
- 文件系统将磁盘分成许多簇,每个簇可以包含一个或多个扇区。
- 簇的大小可以是512字节、4KB、8KB等,取决于文件系统和磁盘的配置。
- 文件和目录存储在这些簇中,但它们的大小必须适应簇的大小,因此可能会有空间浪费。
- 文件(File):
-
- 文件是文件系统中存储数据的对象。
- 文件由元数据(如文件名、大小、创建时间等)和数据组成。
- 文件可以跨多个簇存储,文件系统会跟踪文件占用的所有簇。
这些组件之间的关系和结构如下:
- 磁盘:磁盘被划分为许多扇区。
- 簇:文件系统将扇区组合成簇,簇是文件存储分配的最小单位。
- 文件:文件存储在簇中,一个文件可能占用一个或多个簇。
- 页面:虽然页面主要与内存管理相关,但操作系统可以使用页面大小来优化文件的读写操作,例如,将文件数据读入内存时,可能会以页面大小为单位进行。
磁盘(特别是传统机械硬盘,HDD)通常是圆的。硬盘内部有一个或多个旋转的磁盘(盘片),这些磁盘是圆形的。每个磁盘的表面被划分为许多同心圆,这些同心圆被称为磁道。磁道被进一步划分为扇区,扇区是磁盘上用于存储数据的最小物理单位。
磁盘的结构:
- 盘片:硬盘内部的圆形磁盘,通常由金属(如铝)或玻璃制成,并涂有磁性材料。
- 磁头:硬盘上用于读取和写入数据的部件,磁头悬浮在磁盘表面之上,非常接近但不接触磁盘。
- 读写臂:控制磁头移动的机械臂,可以将磁头移动到磁盘上的不同磁道上。
- 电机:驱动磁盘旋转的电机。
- 缓存:硬盘内部的小型快速存储器,用于临时存储数据。
- 控制电路:管理硬盘操作的电子电路。
磁盘的工作原理:
当硬盘接收到读写请求时,读写臂会移动磁头到指定的磁道上,然后磁盘旋转,将所需的扇区带到磁头下方进行读取或写入操作。
固态硬盘(SSD):
与机械硬盘不同,固态硬盘没有旋转的磁盘和移动的磁头。SSD使用闪存芯片来存储数据,这些芯片可以是NAND类型。SSD的存储介质是固态的,因此它们没有物理移动部件,这使得SSD在读写速度、耐用性和功耗方面通常优于传统机械硬盘。
