使用的数据集在这里E-Commercial NER Dataset / 电商NER数据集_数据集-阿里云天池
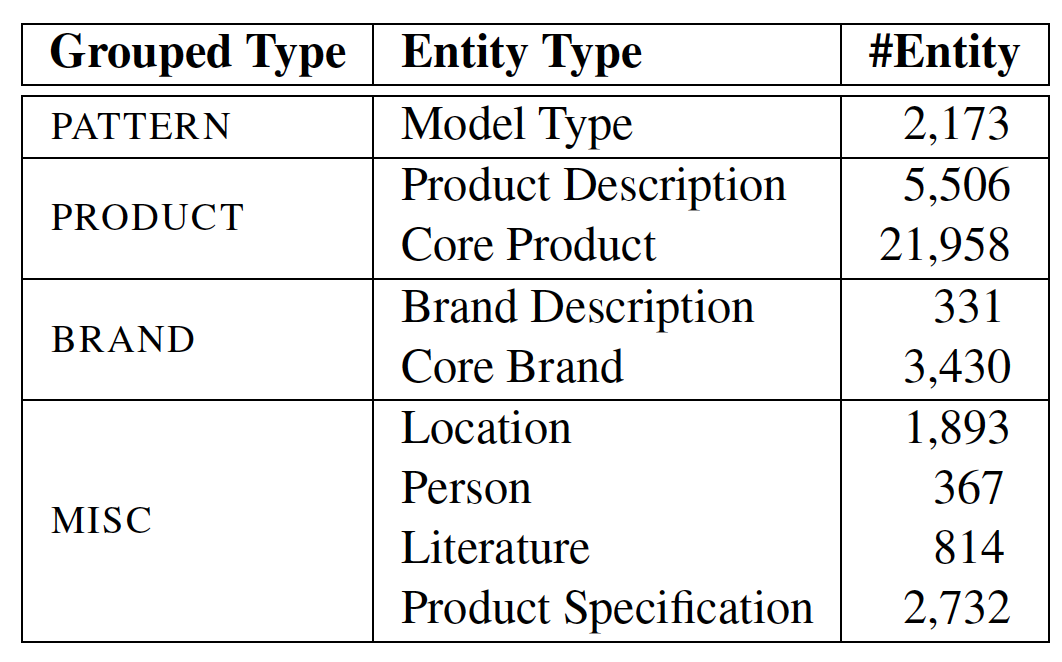
针对面向电商的命名实体识别研究,我们通过爬取搜集了淘宝商品文本的标题,并标注了4大类,9小类的实体类别。具体类型及实体数量如下
针对面向电商的命名实体识别研究,我们通过爬取搜集了淘宝商品文本的标题,并标注了4大类,9小类的实体类别。具体类型及实体数量如下:
每个文件数据格式相同,都为根据BI schema标注的NER数据
模型使用BERT + BiLSTM + CRF 该结构通过结合强大的预训练语言表示、序列建模能力和标签依赖建模,能够有效地提升命名实体识别任务的准确性和鲁棒性。这种组合在实际应用中已经显示出优越的性能,尤其是在复杂的语言理解任务中。
BERT + BiLSTM + CRF 是一种常用于命名实体识别(NER)任务的深度学习模型结构。下面是对这个模型结构的详细解释,以及它在 NER 任务中的好处。
模型结构
BERT(Bidirectional Encoder Representations from Transformers)
- 预训练模型:BERT 是一种基于 Transformer 的预训练语言模型,能够捕捉到上下文信息。它通过双向编码器考虑上下文中的所有单词,从而生成每个单词的上下文嵌入。
- 词向量表示:在 NER 任务中,BERT 可以生成高质量的词嵌入,帮助模型更好地理解文本中的语义。
BiLSTM(Bidirectional Long Short-Term Memory)
- 序列建模:BiLSTM 是一种改进的 LSTM(长短期记忆网络),能够同时考虑序列的前向和后向信息。通过双向处理,BiLSTM 可以更好地捕捉上下文依赖关系。
- 特征提取:在 NER 任务中,BiLSTM 能够从 BERT 输出的嵌入中提取序列特征,并对它们进行时间序列建模。
CRF(Conditional Random Field)
- 序列标注:CRF 是一种用于序列标注的概率模型,可以考虑标签之间的依赖关系。它在输出层对 BiLSTM 的结果进行后处理,以确保输出标签满足特定的序列约束。
- 提高准确性:CRF 能够通过学习标签之间的关系(例如,实体标签之间的相互影响)来增强模型的预测能力。
应用在 NER 任务中的好处
1. 上下文理解
- BERT 的强大能力:BERT 提供丰富的上下文信息,能够更好地理解文本中的语义,从而提高对实体的识别能力。
2. 序列建模
- BiLSTM 的双向特性:通过双向处理,BiLSTM 能够捕捉到前后文的依赖关系,改进对实体边界的识别。
3. 标签依赖建模
- CRF 的序列约束:CRF 考虑了输出标签的依赖关系,能够避免产生不合理的标签序列(例如,"B-PER" 后面直接跟 "B-LOC")。
4. 提高性能
- 综合优势:结合 BERT、BiLSTM 和 CRF 的优点,可以显著提高 NER 任务的性能,尤其是在处理复杂的实体关系和多样的语境时。
模型model.py内容
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from transformers import BertModel
from TorchCRF import CRF
class Bert_BiLSTM_CRF(nn.Module):
def __init__(self, tag_to_ix, embedding_dim=768, hidden_dim=256):
super(Bert_BiLSTM_CRF, self).__init__()
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.hidden_dim = hidden_dim
self.embedding_dim = embedding_dim
self.bert = BertModel.from_pretrained('bert-base-chinese')
self.lstm = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_dim // 2,
num_layers=2,
bidirectional=True,
batch_first=True)
self.dropout = nn.Dropout(p=0.1)
self.linear = nn.Linear(hidden_dim, self.tagset_size)
self.crf = CRF(self.tagset_size)
def _get_features(self, sentence):
with torch.no_grad():
outputs = self.bert(sentence)
embeds = outputs.last_hidden_state
enc, _ = self.lstm(embeds)
enc = self.dropout(enc)
feats = self.linear(enc)
return feats
def forward(self, sentence, tags, mask, is_test=False):
emissions = self._get_features(sentence)
if not is_test: # 训练阶段,返回loss
loss = -self.crf(emissions, tags, mask)
return loss.mean()
else:
return self.crf.viterbi_decode(emissions, mask)统计下数据集中出现的多少种类型的标注
# 统计标签类型的Python脚本
def count_labels(file_path):
labels = set() # 使用集合来存储唯一标签
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
parts = line.strip().split() # 按空格分割每一行
if len(parts) > 1: # 确保这一行有标签
label = parts[-1] # 标签通常在最后一列
labels.add(label) # 将标签添加到集合中
return labels
# 指定文件路径
file_path = 'dataset/train.txt'
unique_labels = count_labels(file_path)
# 输出结果
print(f"总共有 {len(unique_labels)} 种类型的标签:")
for label in unique_labels:
print(label)该数据集里共出现了 9 种类型的标签:
I-HCCX
I-HPPX
B-HCCX
B-XH
I-XH
I-MISC
O
B-HPPX
B-MISC标注遵循了一种常见的命名实体识别标注方案:
- B- 表示实体的开始。
- I- 表示实体的内部部分。
- O 表示非实体部分。
- 实体类别(如 HCCX、HPPX、XH、MISC)根据具体任务和数据集定义。例如HCCX为产品类型,HPPX是品牌名称,XH 是产品型号
下面开始编写训练需要工具
# -*- coding: utf-8 -*-
'''
@Author: Chenrui
@Date: 2021-9-30
@Description: This file is for implementing Dataset.
@All Right Reserve
'''
import torch
from torch.utils.data import Dataset
from transformers import BertTokenizer
bert_model = 'bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_model)
'''
<PAD>: 用于填充序列,确保输入长度一致。
[CLS]: 表示序列的开始,常用于分类任务。
[SEP]: 用于分隔不同的输入序列,帮助模型理解输入的结构。
'''
labels = ['B-HCCX',
'I-HPPX',
'I-HCCX',
'I-MISC',
'B-XH',
'O',
'I-XH',
'B-MISC',
'B-HPPX']
VOCAB = ('<PAD>', '[CLS]', '[SEP]')
# 将 VOCAB 转换为列表以便修改
vocab_list = list(VOCAB)
# 添加 labels 到 vocab_list
vocab_list.extend(labels)
# 将列表转换回元组
VOCAB = tuple(vocab_list)
tag2idx = {tag: idx for idx, tag in enumerate(VOCAB)}
idx2tag = {idx: tag for idx, tag in enumerate(VOCAB)}
MAX_LEN = 256 - 2
class NerDataset(Dataset):
''' Generate our dataset '''
def __init__(self, f_path):
self.sents = []
self.tags_li = []
with open(f_path, 'r', encoding='utf-8') as f:
lines = [line.split('\n')[0] for line in f.readlines() if len(line.strip()) != 0]
tags = [line.split(' ')[1] for line in lines]
words = [line.split(' ')[0] for line in lines]
word, tag = [], []
for char, t in zip(words, tags):
if char != '。':
word.append(char)
tag.append(t)
else:
if len(word) > MAX_LEN:
self.sents.append(['[CLS]'] + word[:MAX_LEN] + ['[SEP]'])
self.tags_li.append(['[CLS]'] + tag[:MAX_LEN] + ['[SEP]'])
else:
self.sents.append(['[CLS]'] + word + ['[SEP]'])
self.tags_li.append(['[CLS]'] + tag + ['[SEP]'])
word, tag = [], []
def __getitem__(self, idx):
words, tags = self.sents[idx], self.tags_li[idx]
token_ids = tokenizer.convert_tokens_to_ids(words)
label_ids = [tag2idx[tag] for tag in tags]
seqlen = len(label_ids)
return token_ids, label_ids, seqlen
def __len__(self):
return len(self.sents)
def PadBatch(batch):
maxlen = 512
token_tensors = torch.LongTensor([i[0] + [0] * (maxlen - len(i[0])) for i in batch])
label_tensors = torch.LongTensor([i[1] + [0] * (maxlen - len(i[1])) for i in batch])
mask = (token_tensors > 0)
return token_tensors, label_tensors, mask训练的主程序
# -*- coding: utf-8 -*-
'''
@Author: Chenrui
@Date: 2023-9-30
@Description: This file is for training, validating and testing.
@All Right Reserve
'''
import argparse
import warnings
import numpy as np
import torch
from sklearn import metrics
from torch.utils import data
from transformers import AdamW, get_linear_schedule_with_warmup
from models import Bert_BiLSTM_CRF
from utils import NerDataset, PadBatch, tag2idx, idx2tag, labels
warnings.filterwarnings("ignore", category=DeprecationWarning)
# os.environ['CUDA_VISIBLE_DEVICES'] = '0'
if __name__ == "__main__":
best_model = None
_best_val_loss = 1e18
_best_val_acc = 1e-18
parser = argparse.ArgumentParser()
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--lr", type=float, default=0.001)
parser.add_argument("--n_epochs", type=int, default=40)
parser.add_argument("--trainset", type=str, default="./dataset/train.txt")
parser.add_argument("--validset", type=str, default="./dataset/dev.txt")
parser.add_argument("--testset", type=str, default="./dataset/test.txt")
ner = parser.parse_args()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = Bert_BiLSTM_CRF(tag2idx).to(device)
print('Initial model Done.')
train_dataset = NerDataset(ner.trainset)
eval_dataset = NerDataset(ner.validset)
test_dataset = NerDataset(ner.testset)
print('Load Data Done.')
'''
torch.utils.data.DataLoader 是 PyTorch 中用于加载数据的一个强大工具。它的主要作用是将数据集分成小批量(batches),
并提供迭代器以便在训练模型时方便地访问数据。以下是 DataLoader 的一些主要功能和使用方法。
'''
train_iter = data.DataLoader(dataset=train_dataset,
batch_size=ner.batch_size,
shuffle=True,
num_workers=4,
collate_fn=PadBatch)
eval_iter = data.DataLoader(dataset=eval_dataset,
batch_size=(ner.batch_size) // 2,
shuffle=False,
num_workers=4,
collate_fn=PadBatch)
test_iter = data.DataLoader(dataset=test_dataset,
batch_size=(ner.batch_size) // 2,
shuffle=False,
num_workers=4,
collate_fn=PadBatch)
# optimizer = optim.Adam(self.model.parameters(), lr=ner.lr, weight_decay=0.01)
optimizer = AdamW(model.parameters(), lr=ner.lr, eps=1e-6)
# Warmup
len_dataset = len(train_dataset)
epoch = ner.n_epochs
batch_size = ner.batch_size
total_steps = (len_dataset // batch_size) * epoch if len_dataset % batch_size == 0 \
else (len_dataset // batch_size + 1) * epoch
warm_up_ratio = 0.1 # Define 10% steps
'''
get_linear_schedule_with_warmup 是 Hugging Face 的 transformers 库中提供的一个函数,用于创建一个学习率调度器。
它的主要作用是在训练过程中动态调整学习率,具体通过以下几个步骤实现:
主要功能
学习率预热(Warmup):
在训练的初始阶段,学习率从 0 逐渐增加到设定的最大学习率。这有助于防止模型在训练初期出现较大的更新,从而导致不稳定。
线性衰减(Linear Decay):
在预热阶段结束后,学习率会线性地递减到 0。这种衰减方式通常能有效地提高模型的收敛性。
'''
scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,
num_warmup_steps=warm_up_ratio * total_steps,
num_training_steps=total_steps)
print('Start Train...,')
for epoch in range(1, ner.n_epochs + 1):
train(epoch, model, train_iter, optimizer, scheduler, device)
candidate_model, loss, acc = validate(epoch, model, eval_iter, device)
if loss < _best_val_loss and acc > _best_val_acc:
best_model = candidate_model
_best_val_loss = loss
_best_val_acc = acc
print("=============================================")
y_test, y_pred = test(best_model, test_iter, device)
print(metrics.classification_report(y_test, y_pred, labels=labels, digits=3))
# 保存模型
torch.save(model.state_dict(), 'ner_task_model.pth')导入部分工具的用途
- argparse:用于解析命令行参数。
- warnings:用于控制警告信息。
- numpy 和 torch:用于数值计算和深度学习。
- sklearn.metrics:用于评估模型性能。
- transformers:提供 AdamW 优化器和学习率调度器
train训练函数,功能训练模型并输出损失。
def train(e, model, iterator, optimizer, scheduler, device):
model.train()
losses = 0.0
step = 0
for i, batch in enumerate(iterator):
step += 1
x, y, z = batch
x = x.to(device)
y = y.to(device)
z = z.to(device)
loss = model(x, y, z)
losses += loss.item()
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
print("Epoch: {}, Loss:{:.4f}".format(e, losses / step))e: 当前的训练轮数。model: NER 模型。iterator: 数据加载器。optimizer: 优化器。scheduler: 学习率调度器。device: 设备(CPU 或 GPU)
**validate函数,**验证集上评估模型性能,计算损失和准确率,并返回模型、损失和准确率。
def validate(e, model, iterator, device):
# 设置模型为评估模式
model.eval()
Y, Y_hat = [], []
losses = 0
step = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
step += 1
x, y, z = batch
x = x.to(device)
y = y.to(device)
z = z.to(device)
y_hat = model(x, y, z, is_test=True)
loss = model(x, y, z)
losses += loss.item()
for j in y_hat:
Y_hat.extend(j)
mask = (z == 1)
y_orig = torch.masked_select(y, mask)
Y.append(y_orig.cpu())
Y = torch.cat(Y, dim=0).numpy()
Y_hat = np.array(Y_hat)
acc = (Y_hat == Y).mean() * 100
print("Epoch: {}, Val Loss:{:.4f}, Val Acc:{:.3f}%".format(e, losses / step, acc))
return model, losses / step, acc**test函数,**在测试集上评估模型性能,返回真实标签和预测标签
def test(model, iterator, device):
model.eval()
Y, Y_hat = [], []
with torch.no_grad():
for i, batch in enumerate(iterator):
x, y, z = batch
x = x.to(device)
z = z.to(device)
y_hat = model(x, y, z, is_test=True)
# Save prediction
for j in y_hat:
Y_hat.extend(j)
# Save labels
mask = (z == 1).cpu()
y_orig = torch.masked_select(y, mask)
Y.append(y_orig)
Y = torch.cat(Y, dim=0).numpy()
y_true = [idx2tag[i] for i in Y]
y_pred = [idx2tag[i] for i in Y_hat]
return y_true, y_pred上面代码实现了一个完整的 NER 训练、验证和测试流程,使用了 BERT、BiLSTM 和 CRF 模型结构。通过 argparse 解析输入参数,使用 PyTorch 处理数据和模型训练,使用 DataLoader 创建迭代器以便于批量处理数据,置 AdamW 优化器和学习率调度器,进行多个训练轮次,每个轮次调用训练和验证函数,最终评估模型性能并保存最佳模型。这是一个典型的深度学习项目框架,适用于序列标注任务。
运行训练
python main.py --n_epochs 1000
查看到准确率稍低, 先不管了把模型文件下载下来本地先试试识别提取能力
下载保存的模型文件

测试该模型代码
import os
import torch
from torch.utils.data import Dataset
from models import Bert_BiLSTM_CRF
from utils import tokenizer, tag2idx, MAX_LEN, idx2tag
device = 'cuda' if torch.cuda.is_available() else 'cpu'
class SequenceLabelingDataset(Dataset):
def __init__(self, lines):
self.lines = lines
self.sents, word = [], []
words = [line[0] for line in lines]
for char in words:
if char != '。':
word.append(char)
else:
if len(word) > MAX_LEN:
self.sents.append(['[CLS]'] + word[:MAX_LEN] + ['[SEP]'])
else:
self.sents.append(['[CLS]'] + word + ['[SEP]'])
word = []
def __len__(self):
return len(self.sents)
def item(self):
words = self.sents[0]
token_ids = tokenizer.convert_tokens_to_ids(words)
seqlen = len(token_ids)
return token_ids, None, seqlen
def get_token_ids(self, batch):
maxlen = 512
token_tensors = torch.LongTensor([i[0] + [0] * (maxlen - len(i[0])) for i in batch])
label_tensors = None
mask = (token_tensors > 0)
return token_tensors, label_tensors, mask
# 示例数据
data_string = '2005复刻正版戏曲光盘1dvd视频碟片河南曲剧优秀剧目集锦。'
print('data_string', data_string)
data = [(char,) for char in data_string]
print('data', data)
# 创建数据集和 DataLoader
dataset = SequenceLabelingDataset(data)
current_directory = os.getcwd()
model_path = os.path.join(current_directory, 'model', 'ner_task_model.pth')
model = Bert_BiLSTM_CRF(tag2idx).to(device)
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
def predict(model, batch, device):
x, y, z = batch[0]
maxlen = 512
token_tensors = torch.LongTensor([i[0] + [0] * (maxlen - len(i[0])) for i in batch])
mask = (token_tensors > 0)
predict = model(token_tensors, None, mask, is_test=True) # 使用生成的 mask
return predict
try:
batch = [dataset.item()]
predict = predict(model, batch, device)
print('predict', predict)
label_ids = [idx2tag[tag] for tag in predict[0]]
print('label_ids', label_ids)
except Exception as e:
print('predict throw exception', e)
# 提取实体
entities = {
'HCCX': [],
'HPPX': [],
'MISC': [],
'XH': [],
'O': []
}
# 当前实体存储
current_entities = {
'HCCX': [],
'HPPX': [],
'MISC': [],
'XH': [],
'O': []
}
# 按照标签提取实体
for i, label in enumerate(label_ids):
word = data_string[i] if i < len(data_string) else ''
if 'B-' in label:
entity_type = label[2:] # 获取实体类型
current_entities[entity_type].append(word)
elif 'I-' in label:
entity_type = label[2:] # 获取实体类型
if current_entities[entity_type]: # 确保当前实体存在
current_entities[entity_type].append(word)
else:
# 处理当前实体
for entity_type in current_entities:
if current_entities[entity_type]:
entities[entity_type].append("".join(current_entities[entity_type]))
current_entities[entity_type] = []
# 处理最后一个实体
for entity_type in current_entities:
if current_entities[entity_type]:
entities[entity_type].append("".join(current_entities[entity_type]))
# 输出结果
for entity_type, entity_list in entities.items():
print(f"提取的{entity_type}实体:", entity_list)返回结果

实体识别出来一些
现在NER任务基本都是大模型去做,相比大语言模型小模型越来越势微越来越不受重视,前公司在知识图谱上搞得globalpointer 任务做NER得产品已经彻底放弃,以至于我们还有些用该产品得客户已经无法得到支持了,但作为NER 入门得例子还是值得拿出来写写