训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在前几期的实战中,我们深入到底层,完成了 Kernel 代码的编写、Tiling 策略的设计以及 ACL C++ 应用的开发。对于追求极致性能的推理部署(Inference)场景,ACL 是不二之选。
然而,在模型训练(Training)阶段,算法工程师主要工作在 PyTorch 或 TensorFlow 等高层框架中。如果想要验证自定义算子在神经网络中的效果,或者需要算子支持反向传播(Back Propagation)参与训练,我们就必须跨越 C++ 与 Python 之间的鸿沟。
PyTorch Adapter 正是这座桥梁。本期文章将带你实战开发一个 PyTorch C++ 扩展,将自定义的 AddCustom 算子"伪装"成 PyTorch 的原生算子,实现无缝调用。
一、 架构解析:从 Python 到 NPU 的调用链路
在 PyTorch 生态中,调用一个 NPU 算子的链路远比我们想象的要复杂。为了保证灵活性和性能,PyTorch 采用了一套分发机制(Dispatcher)
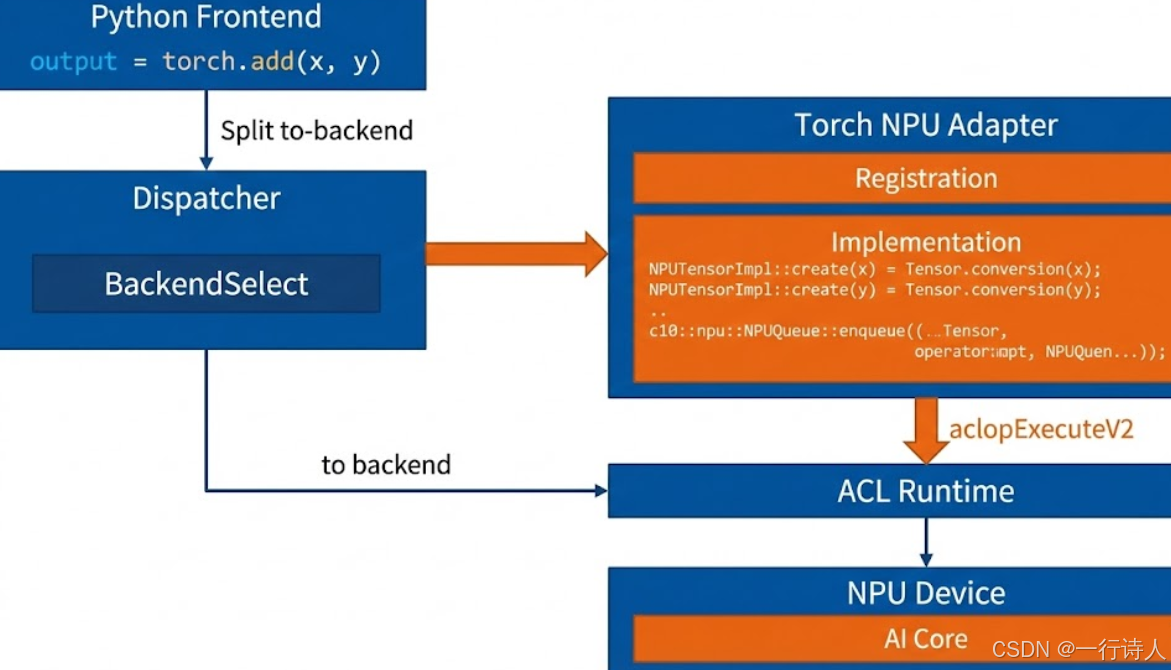
二、 核心开发流程:四步走
要在 PyTorch 中注册一个自定义 NPU 算子,通常遵循以下步骤:
-
算子编译 :确保 Ascend C 算子已编译并安装到系统路径(生成
.om或注册到 OPP)。 -
C++ 绑定实现 :编写 C++ 代码,接收
at::Tensor,将其转换为 ACL 资源,并调用 NPU 算子。 -
算子注册 :使用
TORCH_LIBRARY宏将 C++ 函数注册到 PyTorch 的算子库中。 -
Python 封装 :编写
setup.py编译扩展,并在 Python 侧封装autograd.Function。
三、 实战:编写 PyTorch Extension
我们将创建一个独立的 PyTorch 扩展项目 add_custom_npu。
3.1 C++ 核心逻辑 (adapter.cpp)
我们需要编写一个 C++ 函数,它的输入和输出都是 PyTorch 的 at::Tensor。
#include <torch/extension.h>
#include "acl/acl.h"
#include <vector>
// 辅助函数:将 at::Tensor 的元数据转换为 ACL 兼容格式
// 实际工程中通常使用 torch_npu 提供的 NPUTensorDesc 工具类
// 这里为了演示原理,简化为伪代码逻辑
void run_npu_op(const at::Tensor& x, const at::Tensor& y, at::Tensor& z) {
// 1. 获取 Tensor 的物理地址 (NPU Device Ptr)
// 注意:必须确保 Tensor 位于 NPU 设备上且内存连续
void* x_ptr = x.data_ptr();
void* y_ptr = y.data_ptr();
void* z_ptr = z.data_ptr();
// 2. 构造 ACL 资源 (TensorDesc, DataBuffer)
// 具体逻辑参考上一期 ACL 开发文章,此处复用逻辑
// ... aclCreateTensorDesc ...
// ... aclCreateDataBuffer ...
// 3. 获取当前 NPU Stream
// 这一步很关键,PyTorch 维护了自己的 Stream 池,必须复用
aclrtStream stream = c10::npu::getCurrentNPUStream();
// 4. 调用算子
aclopExecuteV2("AddCustom",
2, inputDesc, inputBuff,
1, outputDesc, outputBuff,
nullptr, stream);
// 5. 资源清理 (Desc, Buffer)
// ...
}
// 暴露给 PyTorch 的接口函数
at::Tensor npu_add_custom(const at::Tensor& x, const at::Tensor& y) {
// 1. 检查设备
TORCH_CHECK(x.device().is_npu(), "x must be a NPU tensor");
TORCH_CHECK(y.device().is_npu(), "y must be a NPU tensor");
// 2. 构造输出 Tensor
auto z = at::empty_like(x);
// 3. 调用核心执行逻辑
run_npu_op(x, y, z);
return z;
}
// --- 算子注册 ---
// 使用 PyTorch 提供的宏,将 C++ 函数绑定到 Python 可见的符号
TORCH_LIBRARY(myops, m) {
m.def("add_custom(Tensor x, Tensor y) -> Tensor");
}
TORCH_LIBRARY_IMPL(myops, PrivateUse1, m) {
// PrivateUse1 是 PyTorch 为第三方设备(如 NPU)预留的 Dispatch Key
m.impl("add_custom", &npu_add_custom);
}3.2 编译脚本 (setup.py)
使用 PyTorch 提供的 CppExtension 进行编译。
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CppExtension
setup(
name='add_custom_npu',
ext_modules=[
CppExtension(
name='add_custom_npu',
sources=['adapter.cpp'],
# 链接 ACL 库
libraries=['ascendcl'],
include_dirs=['/usr/local/Ascend/ascend-toolkit/latest/include'],
library_dirs=['/usr/local/Ascend/ascend-toolkit/latest/lib64'],
extra_compile_args=['-std=c++17']
)
],
cmdclass={
'build_ext': BuildExtension
}
)执行安装:
python3 setup.py install四、 进阶:实现自动微分 (Autograd)
现在的算子只能进行前向计算(Forward)。为了支持模型训练,我们需要告诉 PyTorch 如何计算它的梯度(Backward)。
在 Python 侧,继承 torch.autograd.Function:
import torch
import add_custom_npu # 导入刚才编译的 C++ 扩展
class AddCustomFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x, y):
# 1. 调用 C++ 实现的前向计算
# torch.ops.myops.add_custom 是我们在 C++ TORCH_LIBRARY 中定义的
return torch.ops.myops.add_custom(x, y)
@staticmethod
def backward(ctx, grad_output):
# 2. 定义反向传播逻辑
# z = x + y
# dz/dx = 1, dz/dy = 1
# 所以输入的梯度等于输出的梯度
grad_x = grad_output
grad_y = grad_output
return grad_x, grad_y
# 封装成易用的函数
def add_custom(x, y):
return AddCustomFunction.apply(x, y)现在,这个 add_custom 函数就可以直接放入神经网络中,参与反向传播了!
x = torch.randn(10, device='npu', requires_grad=True)
y = torch.randn(10, device='npu', requires_grad=True)
# 前向
z = add_custom(x, y)
loss = z.sum()
# 反向
loss.backward()
print(x.grad) # 应该全是 1五、 避坑指南:内存连续性 (Contiguous)
这是 PyTorch 适配中最常见的性能陷阱。
问题现象 : 当输入的 Tensor 经过了 transpose 或 slice 操作后,其内存物理上是不连续的。如果我们直接获取 data_ptr() 传给 ACL,ACL 默认按连续内存处理,会导致读取到错误的数据,计算结果完全错误。
解决方案: 在 C++ 代码中,必须强制 Tensor 连续化。
at::Tensor npu_add_custom(const at::Tensor& x, const at::Tensor& y) {
// 强制转为连续内存
at::Tensor x_contig = x.contiguous();
at::Tensor y_contig = y.contiguous();
// ... 使用 x_contig 调用 ACL ...
}注:虽然 contiguous() 会触发内存拷贝,但在 Ascend C 算子不支持 Strided 读写的情况下,这是保证正确性的必要步骤。
六、 总结
通过 PyTorch Adapter,我们将底层的 Ascend C 算子能力无缝注入到了顶层的 AI 生态中。
-
开发链路:Ascend C Kernel -> ACL C++ Wrapper -> PyTorch Registration -> Python Autograd。
-
核心机制 :利用
TORCH_LIBRARY将自定义实现绑定到 PyTorch 的分发键(Dispatch Key)上。 -
注意事项:时刻警惕 Tensor 的内存连续性问题。
至此,我们的【昇腾CANN训练营】系列文章已经涵盖了从底层算子原理、工程开发、Tiling 策略到上层应用调用的全栈知识。掌握了这一套方法论,你已经具备了应对绝大多数 NPU 开发场景的能力。
希望这一系列实战笔记能成为你探索昇腾 AI 开发之路的坚实基石!
参考资料