上篇文章对总统设计介绍,本文主要核心功能关键实现代码
-
原始数据解析
-
数据发送到kafka
-
kafka 数据源
-
聚合操作
-
自定义Sink
总体技术架构
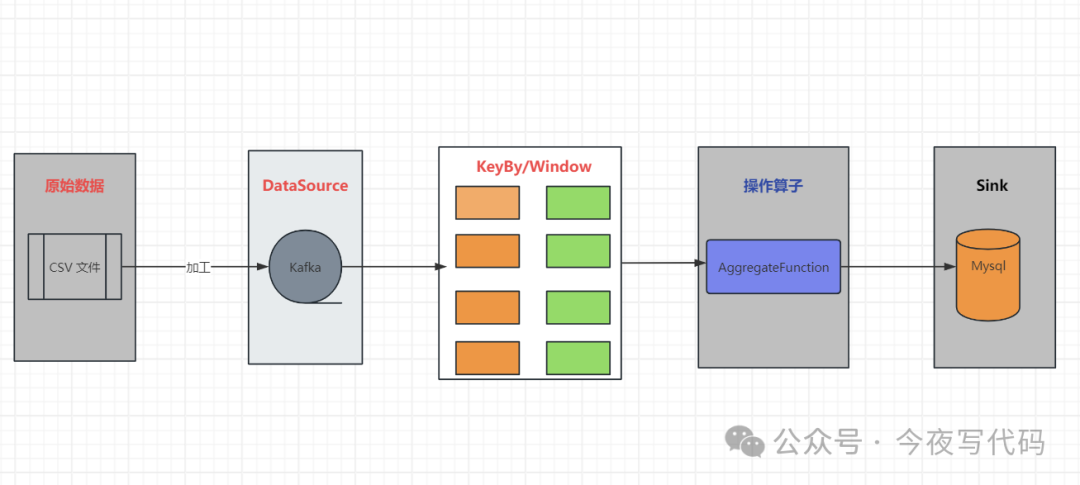
技术架构图
原始数据解析
前面文章介绍使用opencsv解下原始的数据,由于cvs 数据量过大,一次性将所有数据加载出来很容易oom。们没必要一次将所有数据加载处理,完全可以读取一行处理一行数据,这就是Iterator 思想
以下是一次加载所有数据的错误代码,抛出OutOfMemoryError
java
CSVReader reader = new CSVReaderBuilder(new BufferedReader(new FileReader(dataSourcePath))).withSkipLines(1).build();
reader.readAll();
java
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.Arrays.copyOfRange(Arrays.java:3664)
at java.lang.String.<init>(String.java:207)
at java.lang.String.substring(String.java:1969)
at com.opencsv.CSVParser$StringFragmentCopier.peekOutput(CSVParser.java:486)
at com.opencsv.CSVParser$StringFragmentCopier.takeOutput(CSVParser.java:493)
at com.opencsv.CSVParser.parseLine(CSVParser.java:234)
at com.opencsv.AbstractCSVParser.parseLineMulti(AbstractCSVParser.java:66)
at com.opencsv.CSVReader.primeNextRecord(CSVReader.java:271)
at com.opencsv.CSVReader.flexibleRead(CSVReader.java:598)
at com.opencsv.CSVReader.readNext(CSVReader.java:204)
at com.opencsv.CSVReader.readAll(CSVReader.java:186)正确的数据处理方式
定义一个通用的CVS 文件解析器,实现Iterator接口,达到逐条处理的目的,避免一次加载大量数据。
parseRow 将csv 对应行的所有列数据转换为具体业务对象。该方法由具体业务实现
java
public abstract class CSVLineIterator<OUT> implements Iterator<OUT> ,Serializable {
private transient CSVReader reader;
public CSVLineIterator(String csvFile) throws IOException {
this.reader = new CSVReaderBuilder(new BufferedReader(new FileReader(csvFile))).withSkipLines(1).build();
advance();
}
public abstract OUT parseRow(String[] cells);
@Override
public OUT next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
String[] line = reader.readNext();
return parseRow(line);
}
}数据发送到kafka
csv 中原始数据转换为对象,逐条发送到kafka , flink 程序订阅kafka 进行数据分析。
我们发送到 kafka 中的消息内容是 json 字符串。
kafka 发送相关学习可以看之前文章kafka合集
java
public class ProduceMain {
public static void main(String[] args) throws IOException {
String dataSourcePath = "D:\\flink学习测试数据\\job_descriptions.csv\\job_descriptions.csv";
JobDescriptionProduce jobDescriptionProduce = new JobDescriptionProduce();
CSVLineIterator<JobDescription> iter = new CSVLineIterator<JobDescription>(dataSourcePath) {
@Override
public JobDescription parseRow(String[] cells) {
return JobDescriptionUtil.parseRow(cells);
}
};
for (CSVLineIterator<JobDescription> it = iter; it.hasNext(); ) {
JobDescription jobDescription = it.next();
System.out.println("send " + jobDescription.getJobId());
jobDescriptionProduce.sendMessage(jobDescription);
}
System.out.println(" send message end");
}
}Flink Kafka Source
前面我们发送到kafka 中内容是 json 字符串,因此拿到的数据DataStreamSource 中元素是String类型,需要通过map 操作转换为对象。
通过KeyBy 按照我们需要分析的维度分组, 这里分组是 岗位发布日期 + 工作经验
每1小时 更新一下统计数据,避免数据重复,我们使用 Tumbling Windows,而不是Sliding Windows 。统计数据刷新时间依据机器时间,而不是事件时间。因此选择TumblingProcessingTimeWindows。
java
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(Constants.BOOTSTRAP_SERVER)
.setTopics(Constants.TOPIC)
.setGroupId(Constants.CONSUMER_GROUP)
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");聚合操作
统计分组后所有薪资总和、以及总数。平均岗位薪资 = 薪资总和 / 总数
java
public class JobAggregateFunction implements AggregateFunction<JobDescription, JobSalarySumDTO, JobSalarySumDTO> {
@Override
public JobSalarySumDTO createAccumulator() {
return new JobSalarySumDTO();
}
@Override
public JobSalarySumDTO add(JobDescription jobDescription, JobSalarySumDTO jobSalarySumDTO) {
if(jobSalarySumDTO.getCount() == null || jobSalarySumDTO.getCount() == 0){
jobSalarySumDTO.setYear(jobDescription.getJobPostYear());
jobSalarySumDTO.setExperience(jobDescription.getExperience());
jobSalarySumDTO.setCount(0);
jobSalarySumDTO.setSumSalary(0.0);
}
jobSalarySumDTO.setCount(jobSalarySumDTO.getCount() + 1);
jobSalarySumDTO.setSumSalary(jobSalarySumDTO.getSumSalary() + jobDescription.getSalary());
return jobSalarySumDTO;
}
@Override
public JobSalarySumDTO getResult(JobSalarySumDTO jobSalarySumDTO) {
return jobSalarySumDTO;
}
@Override
public JobSalarySumDTO merge(JobSalarySumDTO acc1, JobSalarySumDTO acc2) {
acc1.setCount(acc1.getCount() + acc2.getCount());
acc1.setSumSalary(acc1.getSumSalary()+ acc2.getSumSalary());
return acc1;
}
}结果写到Mysql
我们使用自定义使用Sink ,没有采用JDBC Sink,这样我们可以更加,灵活的实现我们自己的逻辑。
invoke 方法增量更新统计数据核心逻辑
-
当统计数据库不存在之前的统计数据时 则直接插入到数据库
-
将当前汇总的sumSalary 与 数据库已有的累加;将当前汇总的总数与已有的总数相加 得到
新的sumSalary和新的总数,并计算新的平均值。
java
public abstract class MySqlSink<IN> extends RichSinkFunction<IN> {
public void invoke(IN value, Context context) throws Exception {
super.invoke(value, context);
IN oldValue = queryOldValue(value);
if(oldValue == null){
doInsert(value);
return;
}
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(updateSql);
setUpdateParam(ps, oldValue, value);
ps.execute();
// 提交
conn.commit();
} finally {
if (ps != null) {
ps.close();
}
}
}
}
java
public void setUpdateParam(PreparedStatement ps, JobSalarySumDTO oldValue, JobSalarySumDTO deltaValue) throws SQLException {
int oldCount = oldValue.getCount();
double oldSumSalary = oldValue.getSumSalary();
int newCount = oldCount + deltaValue.getCount();
double newSumSalary = oldSumSalary + deltaValue.getSumSalary();
double avgSalary = newSumSalary/newCount;
ps.setDouble(1,newSumSalary);
ps.setDouble(2,avgSalary);
ps.setInt(3,newCount);
ps.setString(4,deltaValue.getYear());
ps.setInt(5,deltaValue.getExperience());
}核心代码
java
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(Constants.BOOTSTRAP_SERVER)
.setTopics(Constants.TOPIC)
.setGroupId(Constants.CONSUMER_GROUP)
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
kafkaStream.map(new MapFunction<String, JobDescription>() {
@Override
public JobDescription map(String s) throws Exception {
return JSON.parseObject(s,JobDescription.class);
}
}).keyBy(new KeySelector<JobDescription, YearExperienceKey>() {
@Override
public YearExperienceKey getKey(JobDescription jobDescription) throws Exception {
return new YearExperienceKey(jobDescription.getJobPostYear(),jobDescription.getExperience());
}
}).window(TumblingProcessingTimeWindows.of(Time.minutes(1))).
aggregate(new JobAggregateFunction())
.addSink(JobAggregateSink.create());
env.execute();总结
本文通过一个完整的例子展示了完整的操作流程。当然如果一些操作您还不熟悉,请查看以往文章或者查看官方文档。