映射:Nested 类型
- [1.为什么需要 Nested 类型](#1.为什么需要 Nested 类型)
- [2.如何定义 Nested 类型](#2.如何定义 Nested 类型)
- 3.相关操作
-
- [3.1 索引包含 Nested 数据的文档](#3.1 索引包含 Nested 数据的文档)
- [3.2 查询 Nested 数据](#3.2 查询 Nested 数据)
- [3.3 聚合 Nested 数据](#3.3 聚合 Nested 数据)
- [3.4 排序 Nested 数据](#3.4 排序 Nested 数据)
- [3.5 更新 Nested 文档中的特定元素](#3.5 更新 Nested 文档中的特定元素)
- [4.Nested 类型的高级操作](#4.Nested 类型的高级操作)
-
- [4.1 内嵌 inner hits](#4.1 内嵌 inner hits)
- [4.2 多级嵌套](#4.2 多级嵌套)
- 5.注意事项
Nested(嵌套)类型是 Elasticsearch 中一种特殊的数据类型,用于处理 对象数组(object arrays)中对象的独立性。在默认情况下,Elasticsearch 会将对象数组 扁平化(flattened),这会导致 数组内对象之间的关联丢失。Nested 类型解决了这个问题,它使数组中的每个对象被独立索引和查询。
1.为什么需要 Nested 类型
考虑以下文档结构:
json
{
"user": "John",
"comments": [
{
"text": "Great product!",
"votes": 5
},
{
"text": "Terrible experience",
"votes": 1
}
]
}默认情况下(使用 object 类型)查询 text 包含 Great,且 votes 等于 1 会错误地匹配这个文档,因为 Elasticsearch 将数组扁平化为:
comments.text: ["Great product!", "Terrible experience"]
comments.votes: [5, 1]使用 nested 类型可以保持数组内对象的独立性。
2.如何定义 Nested 类型
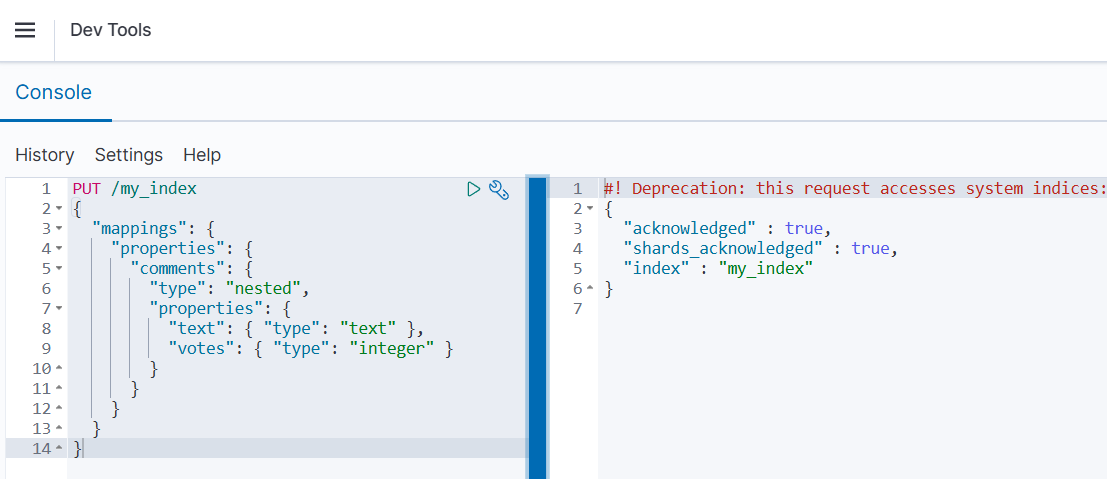
在映射中明确声明字段为 nested 类型:
json
PUT /my_index
{
"mappings": {
"properties": {
"comments": {
"type": "nested",
"properties": {
"text": { "type": "text" },
"votes": { "type": "integer" }
}
}
}
}
}
3.相关操作
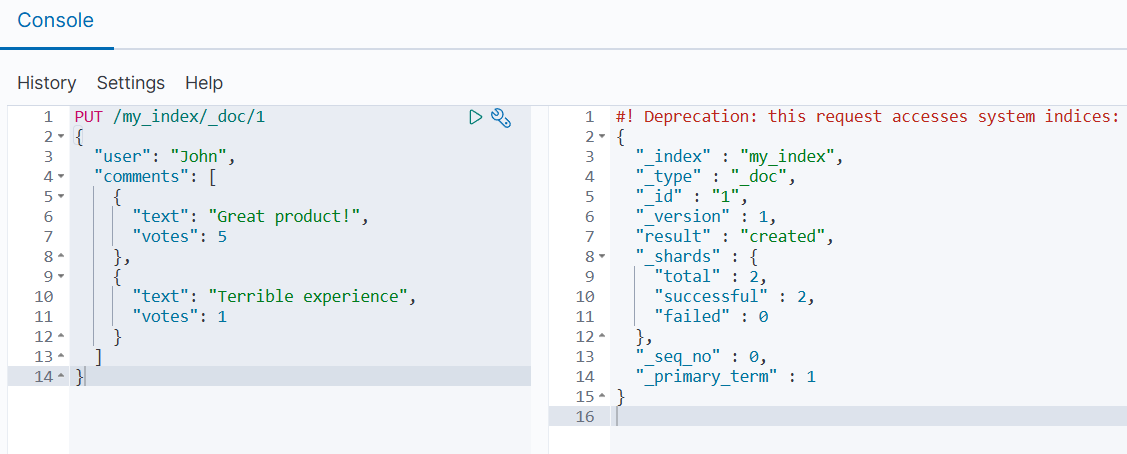
3.1 索引包含 Nested 数据的文档
json
PUT /my_index/_doc/1
{
"user": "John",
"comments": [
{
"text": "Great product!",
"votes": 5
},
{
"text": "Terrible experience",
"votes": 1
}
]
}
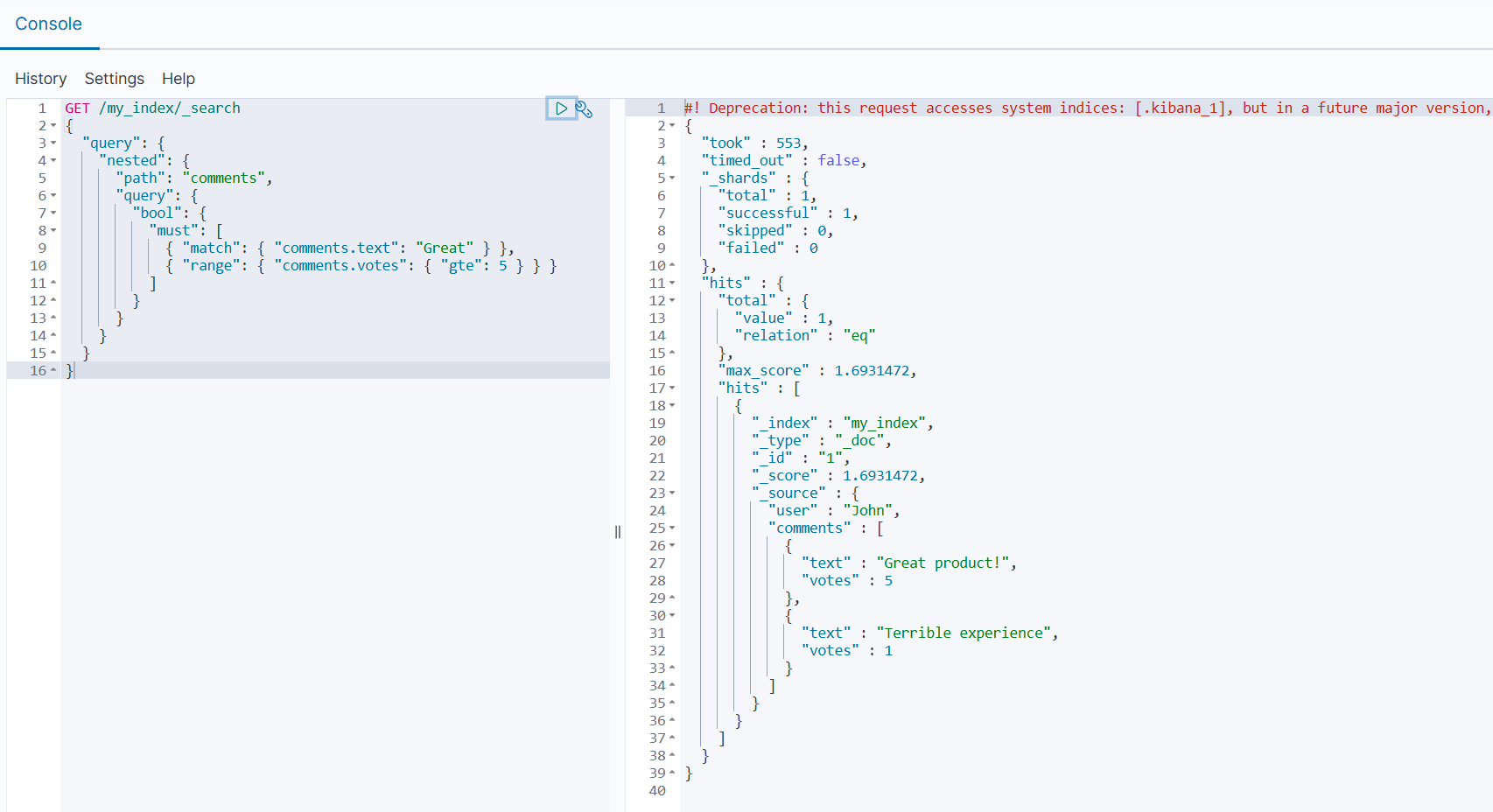
3.2 查询 Nested 数据
使用 nested 查询来查询嵌套对象:
json
GET /my_index/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{ "match": { "comments.text": "Great" } },
{ "range": { "comments.votes": { "gte": 5 } } }
]
}
}
}
}
}
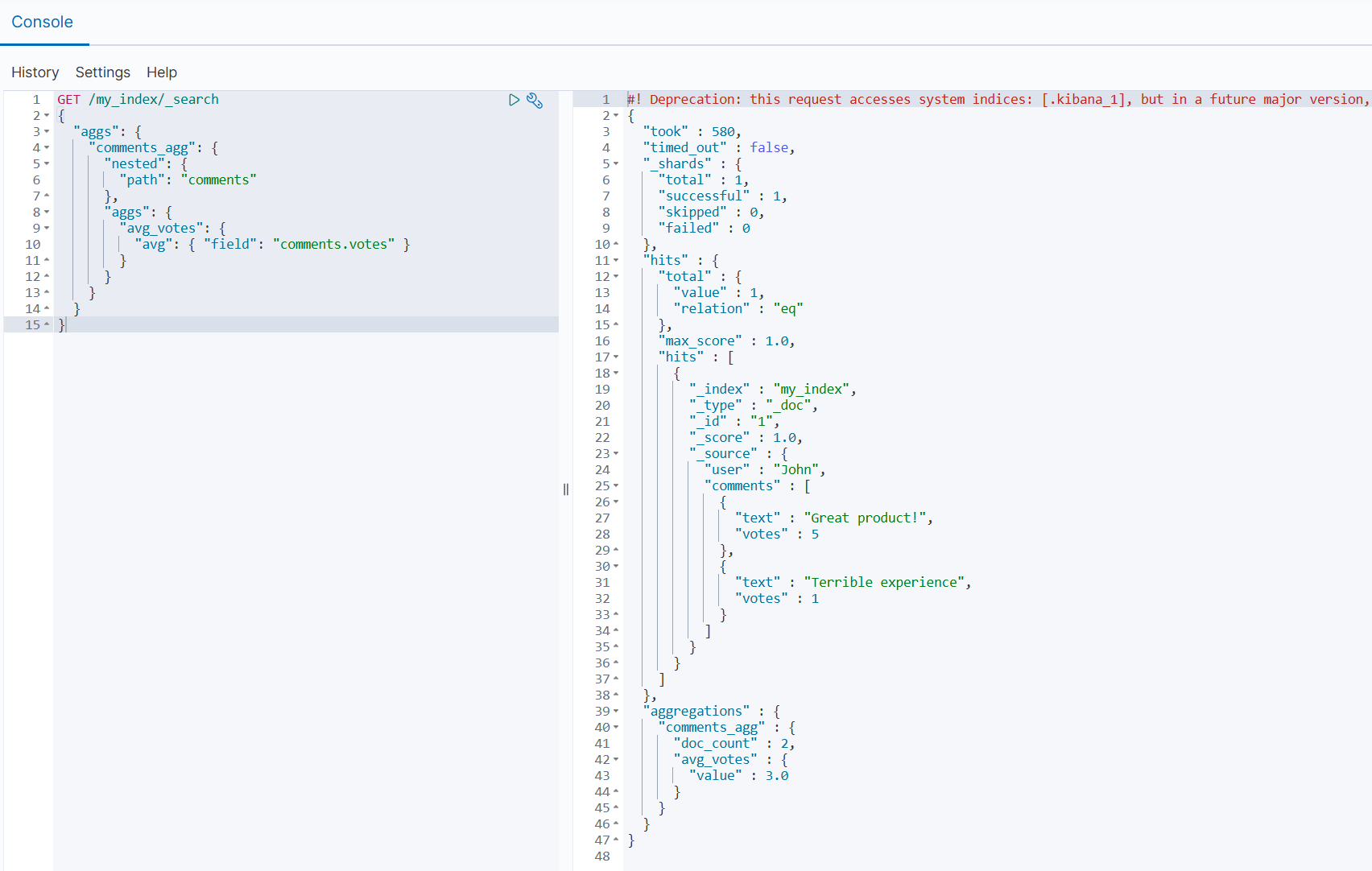
3.3 聚合 Nested 数据
使用 nested 聚合分析嵌套字段:
json
GET /my_index/_search
{
"aggs": {
"comments_agg": {
"nested": {
"path": "comments"
},
"aggs": {
"avg_votes": {
"avg": { "field": "comments.votes" }
}
}
}
}
}
3.4 排序 Nested 数据
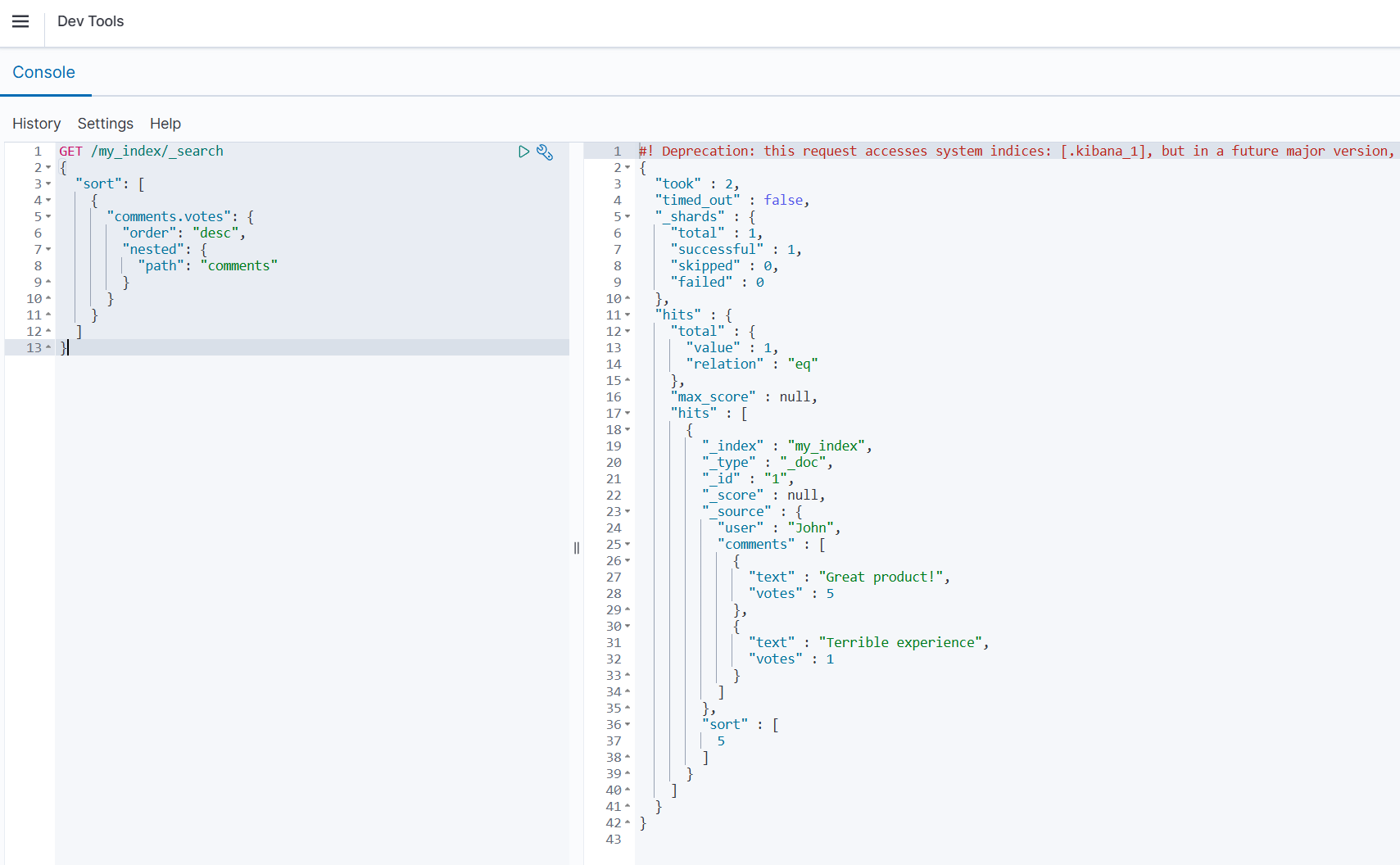
使用 nested 排序:
json
GET /my_index/_search
{
"sort": [
{
"comments.votes": {
"order": "desc",
"nested": {
"path": "comments"
}
}
}
]
}
3.5 更新 Nested 文档中的特定元素
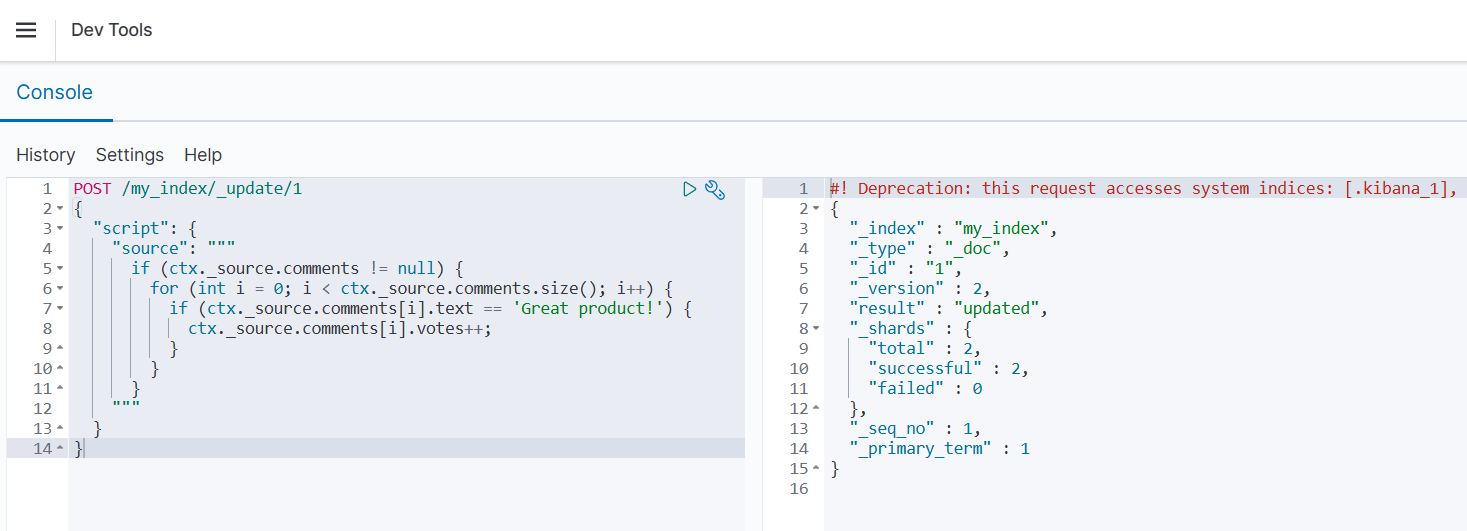
需要使用脚本更新:
json
POST /my_index/_update/1
{
"script": {
"source": """
if (ctx._source.comments != null) {
for (int i = 0; i < ctx._source.comments.size(); i++) {
if (ctx._source.comments[i].text == 'Great product!') {
ctx._source.comments[i].votes++;
}
}
}
"""
}
}
返回结果说明如下:
核心字段
字段 含义 _index文档所属的索引名称(这里是 "my_index")。_type文档类型(Elasticsearch 7.x 后默认为 "_doc",表示单类型索引)。_id被更新文档的唯一 ID(这里是 "1")。_version文档的当前版本号(从 1变为2,表示这是第二次修改)。result操作结果( "updated"表示文档已成功更新)。
分片信息(
_shards)
字段 含义 total需要更新的分片总数(主分片 + 副本分片,这里是 2)。successful成功更新的分片数(这里是 2,表示主分片和副本分片均更新成功)。failed更新失败的分片数(这里是 0,表示无失败)。
- 如果集群有副本分片,
total可能大于1(例如主分片 + 1个副本 =2)。- 若
failed > 0,需检查集群健康状态或分片分配问题。
并发控制字段
字段 含义 _seq_no序列号(Sequence Number),用于乐观并发控制(每次修改递增)。 _primary_term主分片任期(Primary Term),用于区分主分片是否发生过切换(如节点重启)。
这两个字段可用于实现 乐观锁(Optimistic Concurrency Control)。
例如,下次更新时可通过指定
if_seq_no和if_primary_term避免并发冲突。
业务含义总结文档更新成功 :
- 版本号
_version从1变为2,说明这是对文档的第二次修改。result: "updated"确认了更新操作已生效(如果是首次创建,会返回"created")。集群状态健康 :
- 所有分片(
total: 2)均成功更新(successful: 2),无失败(failed: 0)。后续操作依据 :
_seq_no和_primary_term可用于后续的并发更新控制。
常见问题如果
result是noop:表示脚本执行后未实际修改文档(例如条件不满足或值未变化)。如果
failed > 0:需检查副本分片是否不可用(如节点宕机或网络问题)。
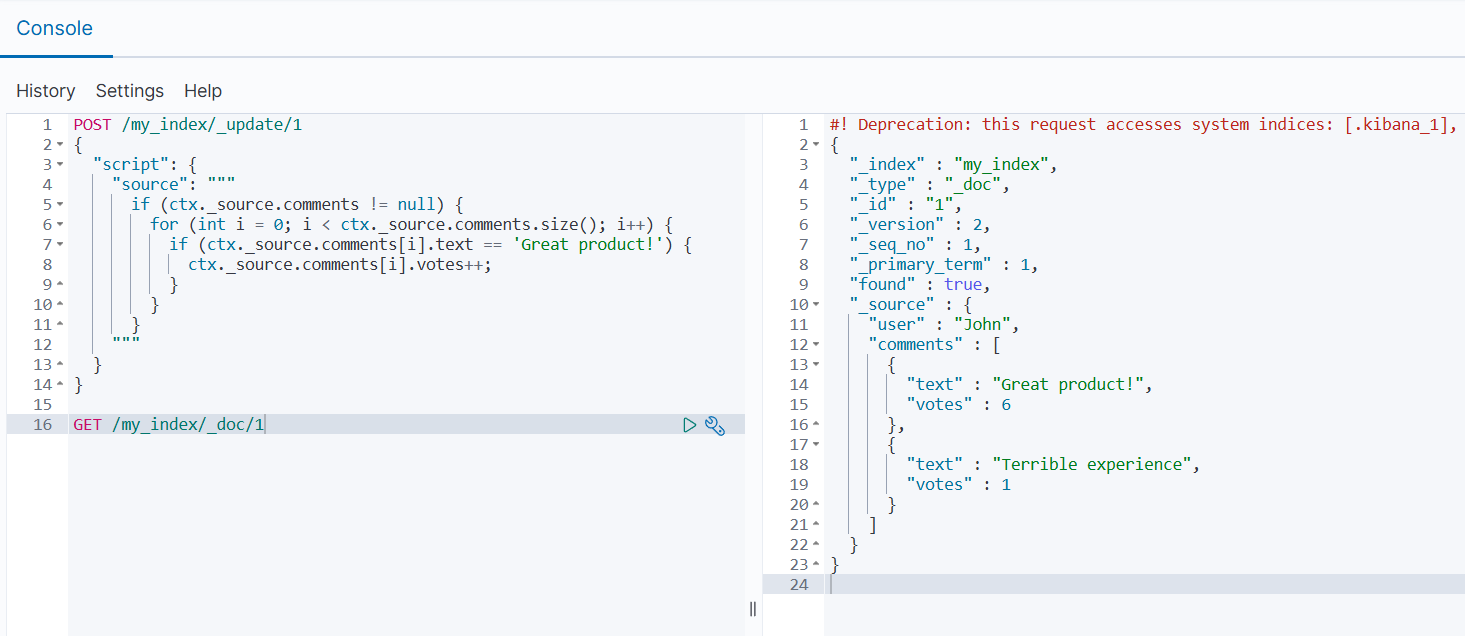
如果需要进一步验证更新内容,可以通过 GET /my_index/_doc/1 查询文档最新状态。
4.Nested 类型的高级操作
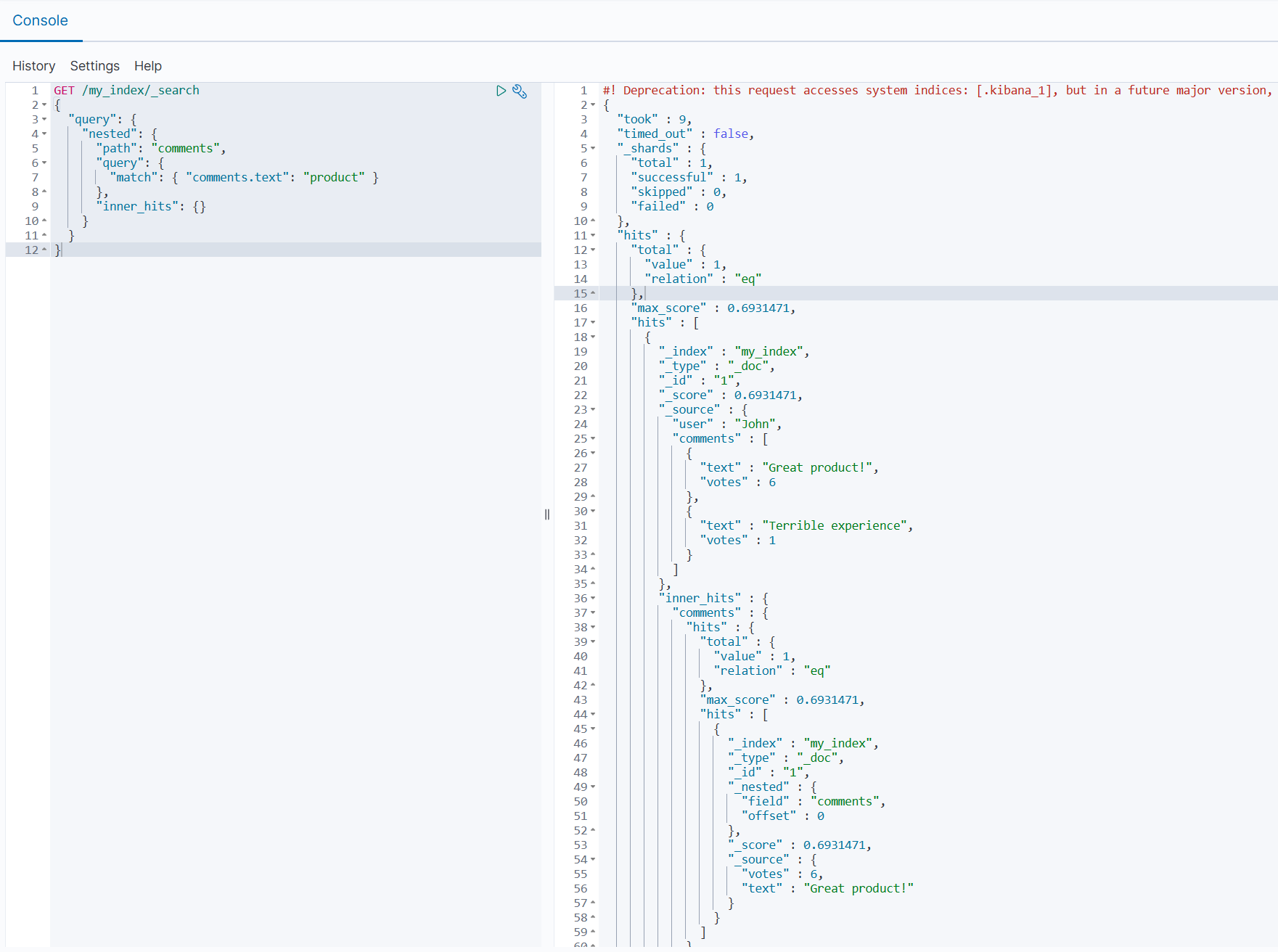
4.1 内嵌 inner hits
🚀
inner_hits是 Elasticsearch 中的一个功能,它允许你在查询嵌套对象或父子文档时,获取匹配的内部嵌套结果或子文档的详细信息。
获取匹配的嵌套对象详情:
json
GET /my_index/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": { "comments.text": "product" }
},
"inner_hits": {}
}
}
}
4.2 多级嵌套
Elasticsearch 支持多级嵌套,但要注意性能影响:
json
PUT /my_index
{
"mappings": {
"properties": {
"users": {
"type": "nested",
"properties": {
"name": { "type": "text" },
"comments": {
"type": "nested",
"properties": {
"text": { "type": "text" },
"votes": { "type": "integer" }
}
}
}
}
}
}
}5.注意事项
- 性能考虑
- Nested 文档会作为独立文档索引,增加索引大小
- 查询
nested字段比普通字段更耗资源 - 避免过度嵌套(通常不超过 2 2 2 级)
- 限制
- 一个索引默认最多包含 50 50 50 个
nested字段(index.mapping.nested_fields.limit) - 一个文档中所有
nested对象数默认不超过 10000 10000 10000 个(index.mapping.nested_objects.limit)
- 一个索引默认最多包含 50 50 50 个
- 与父子文档对比
- Nested 适合小规模、紧密关联的数据
- 父子文档(
join类型)适合大规模、松散关联的数据
- 更新开销
- 更新父文档会替换整个
nested数组 - 频繁更新
nested字段会影响性能
- 更新父文档会替换整个
- 查询特殊性
- 必须使用
nested查询来查询nested字段 - 普通查询无法正确匹配
nested对象间的关系
- 必须使用
通过合理使用 nested 类型,可以准确建模和查询复杂的一对多关系数据,但要注意其对性能的影响。