#Linux基础环境搭建(CentOS7)- 安装Scala和Spark
Linux基础环境搭建(CentOS7)- 安装Scala和Spark
大家注意以下的环境搭建版本号,如果版本不匹配有可能出现问题!(spark不要下2.4版本的 会报错,下载3.0的)
一、Scala下载及安装
Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性。 
Scala的下载
Scala下载链接:通过网盘分享的文件:scala-2.11.8.tgz.zip
链接: https://pan.baidu.com/s/1IArx9RTfmV3ipwcxH1Vsew?pwd=vbha 提取码: vbha
将下载的安装包通过Xftp传输到Linux虚拟机中
Scala安装
创建工作路径/usr/scala,下载scala安装包到/opt/software中,然后解压至工作路径。
mkdir /usr/scala #创建工作路径
cd /opt/software #进入安装包的文件夹
tar -zxvf scala-2.11.12.tgz -C /usr/scala/ #解压zookeeper
cd /usr/scala/scala-2.11.12/二、配置Scala环境变量
修改/etc/profile文件,配置scala环境变量。
vim /etc/profile
#set scala
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile #生效环境变量
scala -version #查看scala是否安装成功
如果出现版本号,表示scala安装成功
三、同步其他虚拟机
以上已经在主节点master上配置完成Scala,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下:(在master执行)
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /usr/scala root@slave1:/usr/ #将scala文件分发到slave1节点
scp -r /usr/scala root@slave2:/usr/ #将scala文件分发到slave2节点
上述是第一次安装没创建过的因为我创建过单独的文件所以是
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /export/servers/scale root@slave1:/export/servers/ #将scala文件分发到slave1节点
scp -r /export/servers/scale root@slave2:/export/servers/ #将scala文件分发到slave2节点生效两个从节点的环境变量
source /etc/profile #slave1和slave2都要执行四、Spark下载及安装
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是------Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。

Spark的下载
Spark下载链接: https://pan.baidu.com/s/1TsKDtHtPwSCX3d00mZhD7g?pwd=f83p
提取码: f83p
将下载的安装包通过Xftp传输到Linux虚拟机中
Spark安装
创建工作路径/usr/spark,下载spark安装包到/opt/software中,然后解压至工作路径。
mkdir /usr/spark #创建工作路径
cd /opt/software #进入安装包的文件夹
tar -zxvf spark-2.4.1-bin-hadoop2.7.tgz -C /usr/spark/ #解压spark
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/
因为我之前已经创建过了 所以就不按照上面的了
spark-3.0.0-bin-hado.tgz
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /export/servers/spark
mv spark-2.4.0-bin-without-hadoop spark-2.4.0
cd spark-2.4.0/五、配置spark-env.sh文件
配置文件spark-env.sh,进入spark配置文件夹conf,将spark-env.sh.template文件拷贝一份命名为spark-env.sh,spark在启动时会找这个文件作为默认配置文件。
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh对spark-env.sh文件配置如下:(在master执行)
vim spark-env.sh添加如下内容:
export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop
因为之前已经创建过了 所以就不再按照上面的了
export SPARK_MASTER_IP=master
export SCALA_HOME=/export/servers/scale/scala-2.11.8
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
六、配置Spark从节点,修改slaves文件
注意slaves节点中只包含节点信息,其他注释不需要
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/conf/
cp slaves.template slaves
vim slaves添加如下内容:
master
slave1
slave2七、配置Spark环境变量
修改/etc/profile文件,配置Spark环境变量。
vim /etc/profile
#set spark
export SPARK_HOME=/usr/spark/spark-2.4.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
这里我之前创建过文件所以就不按照上面的了
#set spark
export SPARK_HOME=/export/servers/spark/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile #生效环境变量八、同步其他虚拟机
以上已经在主节点master上配置完成spark,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下:(在master执行)
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /usr/spark root@slave1:/usr/ #将scala文件分发到slave1节点
scp -r /usr/spark root@slave2:/usr/ #将scala文件分发到slave2节点
这里我改成自己之前创建的地方了
scp -r /export/servers/spark root@slave1:/export/servers/
scp -r /export/servers/spark root@slave2:/export/servers/生效两个从节点的环境变量
source /etc/profile #slave1和slave2都要执行九、开启Spark环境(master节点)
/usr/spark/spark-2.4.1-bin-hadoop2.7/sbin/start-all.sh
jps #三个节点
/export/servers/spark/spark-2.4.0/sbin/start-all.shmaster节点 
slave1节点 
slave2节点 
因为我们只设置了slave1和slave2两个Worker 所以只要master节点的进程有Master,slave1和slave2节点都有Worker,即代表启动成功!
十、Spark客户端连接
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/bin/
spark-shell --master spark://master:7077若出现以下界面,则代表连接成功 
十一、查看Spark集群状态
在浏览器输入localhost:8080,如图: 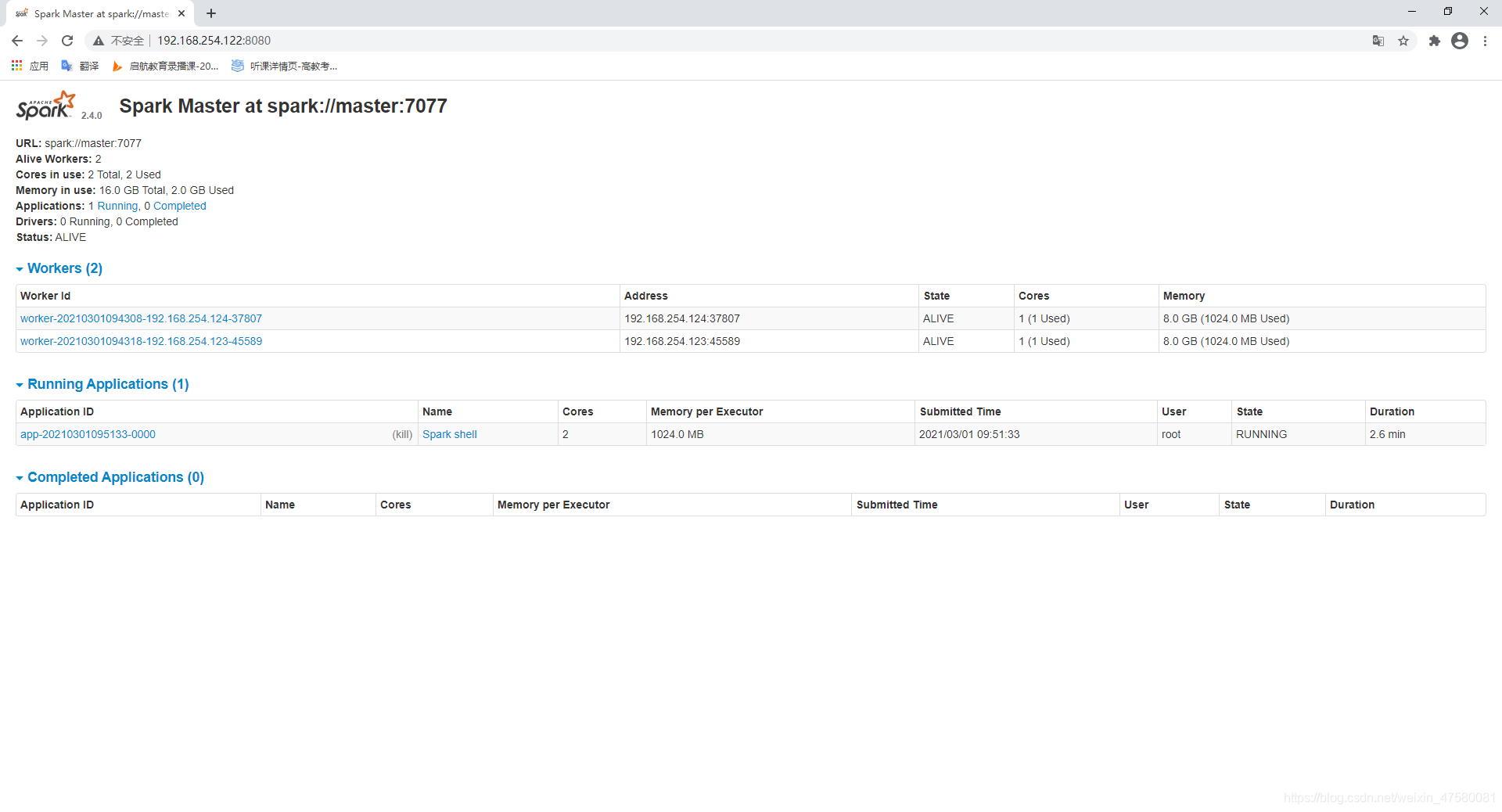 如果情况一样的话,就成功安装好scala和spark啦~
如果情况一样的话,就成功安装好scala和spark啦~