今天我们继续学习新的数据结构-散列表。
01、定义
我们先来了解一些常见概念名词解释。
散列:散列表的实现叫做散列,是一种实现以常数级时间复杂度执行查找、插入和删除的技术;
散列值:通过散列函数对输入值(key)计算出来的结果,用来表示key的唯一性,它通常是一个长度固定的值,即无论key多大,散列值的长度都是固定的;
散列地址:通过散列值计算出来的存储位置,即存储value的位置,通常使用散列值和散列表的大小取模得到散列地址。
碰撞 :也叫冲突,指两个不同的key,经过散列函数计算后得到相同的散列值;
负载系数 :也叫负载因子,用来衡量散列表填充程度,通过散列表已存储的元素个数除以散列表的大小计算可得;
散列函数 :也叫哈希函数,指将key映射为散列值的函数;
散列表又称哈希表,是以「key-value」形式存储数据的数据结构。可以理解为任意的key都可以唯一对应到内存中的某个地址,而这个地址就存放着value,通过key快速查找到value。也可以把散列表理解为一种高级的数组,其中key就相当于数组下标,此数组下标不但可以是整数,还可以是浮点数、字符串、结构体等,其中value就相当于数组元素值。
通过前面的数据结构学习,我们知道数组是查找容易、插入和删除困难;链表是查找困难、插入和删除容易;而散列表是集两者之大成,做大查找、插入、删除都容易的一种数据结构。
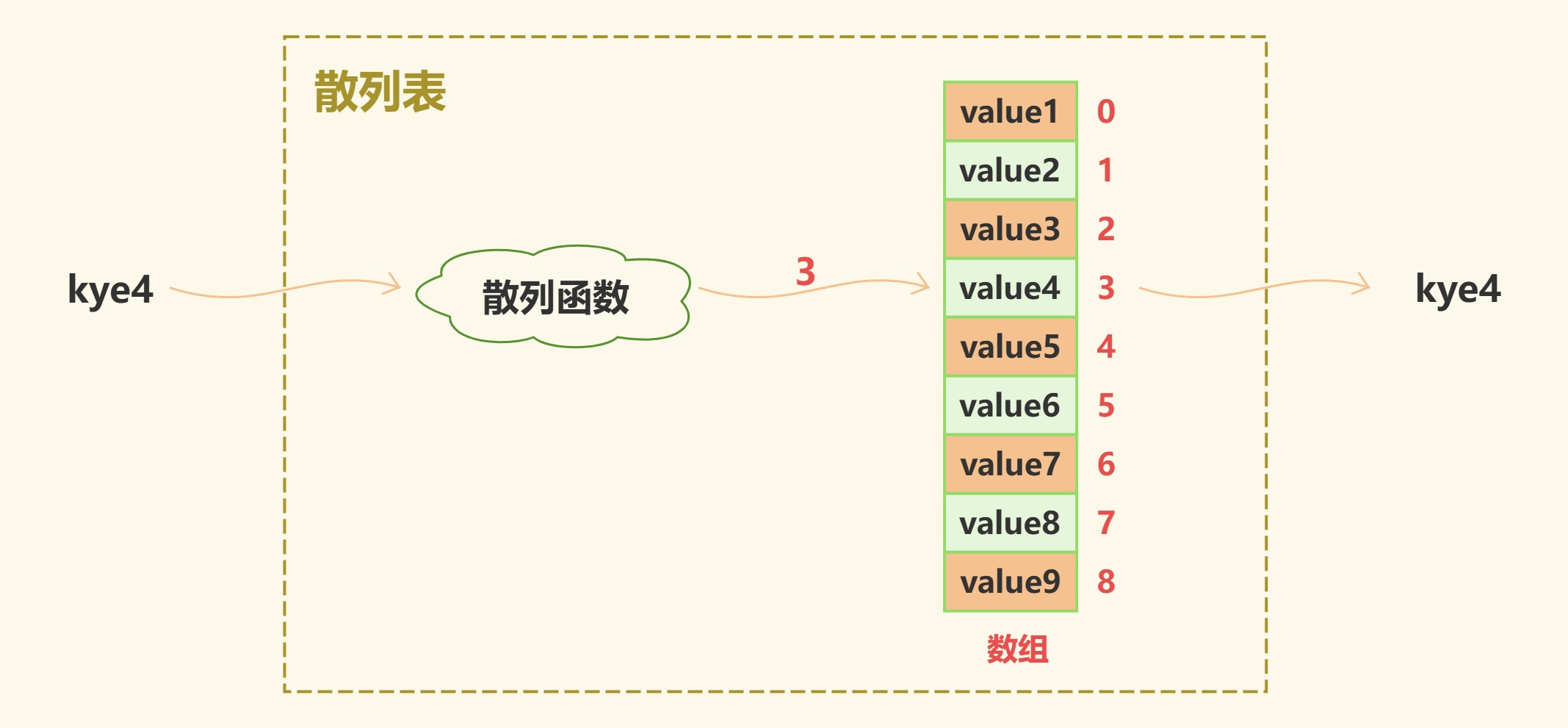
本质上来说散列表就是一个数组。虽然上面把key比作数组下标,但是key并不真的是数组下标。因此这中间就需要一个转换工具把key转换为数组下标,而这个工具就是散列函数。
如下图,展示了在散列表中如何通用key获取到value的过程。输入key4通过散列函数计算得到数组索引3,最后通过数组下标取出value4。
02、散列函数
散列技术核心难点之一就是如何设计一个准确、快速、均匀、抗碰撞的散列函数。而一个好的散列函数对散列表是至关重要的,这影响散列表的存储和检索效率。
1、四大特性
(1)确定性:指相同的输入key总能输出相同的结果;
(2)快速计算:指计算散列值的速度尽可能的快;
(3)均匀分布:指尽量将输入key均匀的映射到散列表中,以减少碰撞;
(4)抗碰撞性:指尽量减少不同的输入key生成出相同的散列值概率;
2、常见散列函数算法
(1)取模算法
该算法是一种最简单且常用的散列函数构造方法。
原理:通过将key取模散列表的大小(通常是质数)来计算散列值;
公式:hash(key) = key % m;
优点:简单易实现,计算速度快;
缺点:如果m不是质数,会增加碰撞概率,因此m最好选用质数来减少碰撞概率。
示例:假设我们有个散列表,大小为10,分别散列以下key:11,23,4,19
hash(11) = 11 % 10 = 1
hash(23) = 23 % 10 = 3
hash(4) = 4 % 10 = 4
hash(17) = 17 % 10 = 7
则最终生成的散列值分别为1、3、4、7,而这些值就可以作为散列表的索引。
(2)乘法算法
该算法是通过乘法来降低碰撞概率,以使散列值均匀分布;
原理:通过将key与一个固定常数 A(通常是黄金比例的倒数)相乘,取其乘积的小数部分,再乘以散列表的大小(通常是质数),所得结果的整数部分即为散列值;
公式:hash(key) = ⌊m * (key * A % 1)⌋;
优点:简单易实现,散列值分布更均匀;
缺点:常数A的选择对计算结果散列值影响很大,选择不好很容易增加碰撞概率;
示例:假设我们有个散列表,大小为10,常数A为0.618,分别散列以下key:11,23,4,19
hash(11) = ⌊10 * (11 * 0.618 % 1)⌋ = 7
hash(23) = ⌊10 * (23 * 0.618 % 1)⌋ = 2
hash(4) = ⌊10 * (4 * 0.618 % 1)⌋ = 4
hash(17) = ⌊10 * (17 * 0.618 % 1)⌋ = 5
则最终生成的散列值分别为7、2、4、5,而这些值就可以作为散列表的索引。
(3)DJB2算法
DJB2 是一种使用广泛的字符串散列算法,它简单而高效,由 Daniel和J. Bernstein 提出。其核心公式:hash = hash * 33 + c,其中 33 是常用的基数。
原理:使用一个初始散列值(通常是5381),然后通过对key的每一个字符的ASCII值进行逐步加权处理,最终得到散列值;
公式:hash(key) = {
hash = 5381
for character c in string:
hash = ((hash << 5) + hash) + c
return hash & 0xFFFFFFFF
}
优点:简单易懂,速度快,底碰撞;
缺点:基数(33)的选择对散列性能有一定影响,虽然普遍表现良好,但并不是最佳选择;散列值的输出通常需要进行掩码操作(如 & 0xFFFFFFFF),这可能导致部分信息丢失,尤其在处理较大数据时。
上面的公式中没有使用hash * 33 + c,而是使用((hash << 5) + hash) + c是因为位运算效率更高。
(4)其他算法
除了以上三种算法还有很多其他算法,比如和DJB2算法类似的BKDR算法、PJW算法,比如还有诸如:直接定算法、数字分析算法、平方取中算法、折叠算法、随机数算法等等,这里就不一一细说了,有兴趣的可以自己研究研究。
注 :测试方法代码以及示例源码都已经上传至代码库,有兴趣的可以看看。https://gitee.com/hugogoos/Planner