【Android】浅析OkHttp(1)
OkHttp 是一个高效、轻量级的 HTTP 客户端库,主要用于 Android 和 Java 应用开发。它不仅支持同步和异步的 HTTP 请求,还支持许多高级功能,如连接池、透明的 GZIP 压缩、响应缓存、WebSocket 等。OkHttp3 是 OkHttp 的第三个大版本,在稳定性和功能性方面进行了很多改进。
今天主要介绍OkHttp3。
OkHttp基本用法
使用前
配置gradle
java
implementation ("com.squareup.okhttp3:okhttp:3.2.0")异步 GET 请求
最简单的 GET 请求,请求博客地址,代码如下所示:
java
Request.Builder requestBuilder = new Request.Builder().url("http://blog.csdn.net/itachi85");
requestBuilder.method("GET", null);
Request request = requestBuilder.build();
OkHttpClient mOkHttpClient = new OkHttpClient();
Call mcall = mOkHttpClient.newCall(request);
mcall.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
String str = response.body().string();
Log.d(TAG str);
}
});其基本步骤就是创建 OkHttpClient、Request 和 Call,最后调用 Call 的 enqueue()方法。但是 每次这么写很麻烦,肯定是要进行封装的。需要注意的是 onResponse 回调并非在 UI 线程。如 果想要调用同步 GET 请求,可以调用 Call 的 execute 方法。
同步 GET 请求
代码示例如下:
java
OkHttpClient client = new OkHttpClient();
// 创建Request对象
Request request = new Request.Builder()
.url("https://jsonplaceholder.typicode.com/posts")
.build();
// 同步发送请求
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
// 打印响应内容
System.out.println(response.body().string());
} else {
System.out.println("Request Failed");
}
} catch (IOException e) {
e.printStackTrace();
}在同步请求中,execute() 方法会阻塞线程,直到服务器返回响应。这里 Response 通过 try-with-resources 自动关闭流。
异步 POST 请求
OkHttp 3 异步 POST 请求和 OkHttp 2.x 有一些差别,就是没有 FormEncodingBuilder 这个类, 替代它的是功能更加强大的 FormBody。这里访问淘宝 IP 库,代码如下所示:
java
RequestBody formBody = new FormBody.Builder()
.add("ip", "59.108.54.37")
.build();
Request request = new Request.Builder()
.url("http://ip.taobao.com/service/getIpInfo.php")
.post(formBody)
.build();
OkHttpClient mOkHttpClient = new OkHttpClient();
Call call = mOkHttpClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
String str = response.body().string();
Log.d(TAG, str);
}
});这与异步 GET 请求类似,只是多了用 FormBody 来封装请求的参数,并传递给 Request。
设置超时时间和缓存
和 OkHttp 2.x 有区别的是 OkHttp 3 不能通过 OkHttpClient 直接设置超时时间和缓存了,而 是通过 OkHttpClient.Builder 来设置。通过 builder 配置好 OkHttpClient 后用 builder.build()来返回 OkHttpClient。所以我们通常不会调用 new OkHttpClient()来得到 OkHttpClient,而是通过 builder.build()得到 OkHttpClient。另外,OkHttp 3 支持设置连接、写入和读取的超时时间,如下 所示:
java
File sdcache = getExternalCacheDir();
int cacheSize = 10 * 1024 * 1024;
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.connectTimeout(15, TimeUnit.SECONDS)
.writeTimeout(20, TimeUnit.SECONDS)
.readTimeout(20, TimeUnit.SECONDS)
.cache(new Cache(sdcache.getAbsoluteFile(), cacheSize));
mOkHttpClient = builder.build();取消请求
使用 call.cancel()可以立即停止一个正在执行的 call。当用户离开一个应用时或者跳到其他 界面时,使用 call.cancel()可以节约网络资源;另外,不管同步还是异步的 call 都可以取消,也 可以通过 tag 来同时取消多个请求。当构建一个请求时,使用 Request.Builder.tag(Object tag)来 分配一个标签,之后你就可以用 OkHttpClient.cancel(Object tag )来取消所有带有这个 tag 的 call。 具体代码如下所示:
java
private ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
private void cancel() {
final Request request = new Request.Builder()
.url("http://www.baidu.com")
.cacheControl(CacheControl.FORCE_NETWORK)//1
.build();
Call call = null;
call = mOkHttpClient.newCall(request);
final Call finalCall = call;
//100ms 后取消 call
executor.schedule(new Runnable() {
@Override
public void run() {
finalCall.cancel();
}
}, 100, TimeUnit.MILLISECONDS);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (null != response.cacheResponse()) {
String str = response.cacheResponse().toString();
Log.d(TAG, "cache---" + str);
} else {
String str = response.networkResponse().toString();
Log.d(TAG, "network---" + str);
}
}
});
}创建定时线程池,100 ms 后调用 call.cancel()来取消请求。为了能让请求耗时,在上面代码 注释 1 处设置每次请求都要请求网络,运行程序并且不断地调用 cancel 方法。Log 打印结果如 图 5-13 所示。
源码解析OkHttp
首先来学习一下 OkHttp 的请求网络流程。
OkHttp的请求网络流程
大致流程
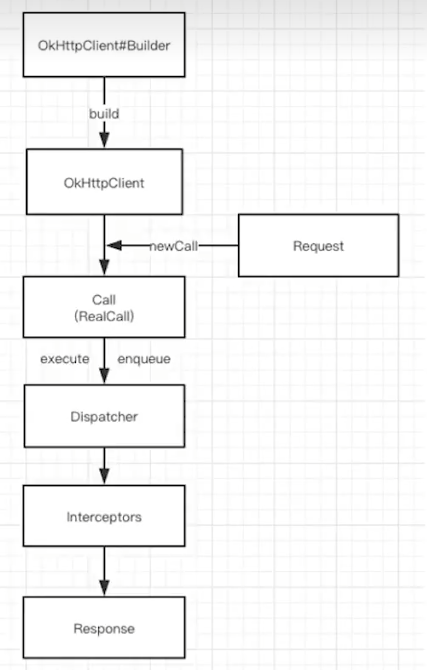
首先创建出OkHttpClient,而后创建出Request对象,通过这两个对象,获取到Call对象。使用Call开始执行请求后,请求的任务会首先经过Dispatcher(分发器)进行任务的调配,而后Interceptors(拦截器)完成请求的过程。
- 通过建造者模式构建
OKHttpClient与Request OKHttpClient通过newCall发起一个新的请求- 通过分发器维护请求队列与线程池,完成请求调配
- 通过五大默认拦截器完成请求重试,缓存处理,建立连接等一系列操作
- 得到网络请求结果
分发器:内部维护队列以及线程池,完成请求调配。
拦截器:完成整个请求过程。
关于分发器Dispatcher
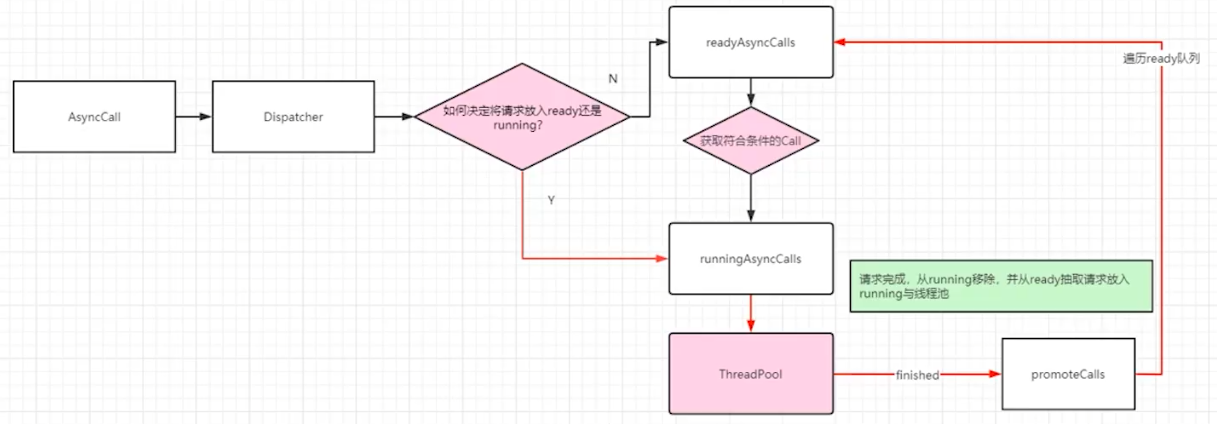
RunningAsyncCalls:正在执行的异步请求队列
ReadyAsyncCalls:等待执行的异步请求队列
RunningSyncCalls:正在执行的同步请求队列
关于拦截器Interceptor
重试重定向拦截器
桥接拦截器
缓存拦截器
连接拦截器
请求服务器拦截器
- 重试拦截器:负责判断用户是否取消了请求;获得结果之后,会根据响应码判断是否需要重定向,如果满足条件就会重启执行所有拦截器
- 桥接拦截器在交出之前,负责将Http协议必备的请求头加入其中;获得结果之后,调用保存cookie接口并解析GZIP数据
- 缓存拦截器,交出之前读取并判断是否使用缓存;获得结果之后判断是否缓存。
- 连接拦截器,交出之前负责找到或者新建一个链接,并获取对应的socket流,在获得结果之后,不进行额外处理。
- 请求服务器拦截器进行真正的与服务器的通信,向服务器发送数据,解析读取的相应数据
从execute/enqueue开始
当我们要请求网络的时候需要用 OkHttpClient.newCall(request)进行 execute 或者 enqueue 操 作;当调用 newCall 方法时,会调用如下代码:
java
@Override
public Call newCall(Request request) {
return new RealCall(this, request);
}其实际返回的是一个RealCall类。我们调用 enqueue 异步请求网络实际上是调用了 RealCall 的 enqueue 方法。查看 RealCall 的 enqueue 方法,如下所示:
java
void enqueue(Callback responseCallback, boolean forWebSocket) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
client.dispatcher().enqueue(new AsyncCall(responseCallback, forWebSocket));
}可以看到最终的请求是 dispatcher 来完成的,接下来就开始分析 dispatcher。
Dispatcher 任务调度
Dispatcher 主要用于控制并发的请求,它主要维护了以下变量:
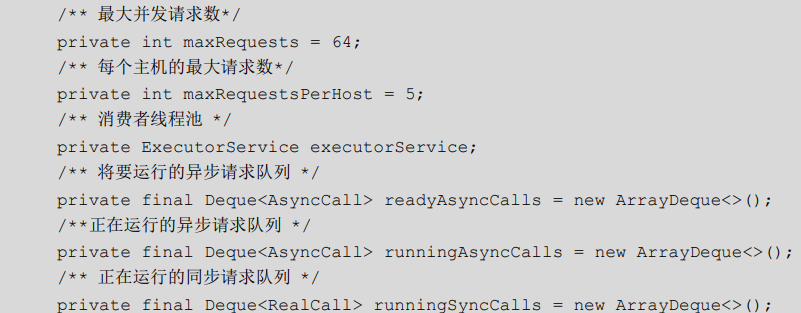
接下来看看 Dispatcher 的构造方法,如下所示:
java
public Dispatcher(ExecutorService executorService) {
this.executorService = executorService;
}
public Dispatcher() {
}
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60,
TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), Util.threadFactory
("OkHttp Dispatcher", false));
}
return executorService;
}复习:
synchronized关键字可以确保同一时间内只有一个线程可以访问共享资源,从而避免竞争条件(race condition)的问题。同步方法
可以将整个方法标记为
synchronized,这样该方法在某一时刻只允许一个线程访问。同步代码块
可以使用
synchronized块来同步特定的代码块,而不是整个方法。这样可以减少锁的持有时间,提升程序的并发性能。
Dispatcher 有两个构造方法,可以使用自己设定的线程池。如果没有设定线程池,则会在请 求网络前自己创建默认线程池。这个线程池类似于 CachedThreadPool,比较适合执行大量的耗 时比较少的任务。前面讲过,当调用 RealCall 的 enqueue 方法时,实际上是调用了 Dispatcher 的 enqueue 方法,它的代码如下所示:
java
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}当正在运行的异步请求队列中的数量小于 64 并且同一个主机的请求最大数小于 5 时,把请求 加载到runningAsyncCalls中并在线程池中执行,否则就加入到readyAsyncCalls中进行缓存等待。 线程池中传进来的参数是 AsyncCall,它是 RealCall 的内部类,其内部也实现了 execute 方法, 如下所示:
java
protected void execute() {
boolean signalledCallback = false;
try {
...
} catch (IOException e) {
...
} finally {
client.dispatcher().finished(this);//1
}
}在上面代码注释 1 处,无论这个请求的结果如何,都会执行 client.dispatcher().finished(this), finished 方法如下所示:
java
synchronized void finished(AsyncCall call) {
if (!runningAsyncCalls.remove(call)) throw new AssertionError("AsyncCall wasn't running!");
promoteCalls();
}finished 方法将此次请求从 runningAsyncCalls 移除后还执行了 promoteCalls 方法:
java
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return;
if (readyAsyncCalls.isEmpty()) return;
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return;
}
}最关键的一点就是会从 readyAsyncCalls 取出下一个请求,加入 runningAsyncCalls 中并交由 线程池处理。好了,让我们再回到上面 AsyncCall 的 execute 方法:
java
@Override
protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain(forWebSocket);//1
if (canceled) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
logger.log(Level.INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}在上面代码注释 1 处,getResponseWithInterceptorChain 方法返回了 Response,这是在请求网络。
Interceptor 拦截器
接下来查看 getResponseWithInterceptorChain 方法,如下所示:
java
private Response getResponseWithInterceptorChain(boolean forWebSocket)
throws IOException {
Interceptor.Chain chain = new ApplicationInterceptorChain(0, originalRequest,forWebSocket);
return chain.proceed(originalRequest);
}getResponseWithInterceptorChain 方法中创建了 ApplicationInterceptorChain,这是一个拦截器链。这个类也是 RealCall 的内部类,接下来执行了它的 proceed 方法:
java
public Response proceed(Request request) throws IOException {
if (index < client.interceptors().size()) {
Interceptor.Chain chain = new ApplicationInterceptorChain(index + 1, request, forWebSocket);
//从拦截器列表中取出拦截器
Interceptor interceptor = client.interceptors().get(index);
Response interceptedResponse = interceptor.intercept(chain);//1
if (interceptedResponse == null) {
throw new NullPointerException("application interceptor " + interceptor + " returned null");
}
return interceptedResponse;
}
return getResponse(request, forWebSocket);
}proceed 方法每次从拦截器列表中取出拦截器。当存在多个拦截器时都会在上面代码注释 1 处阻塞,并等待下一个拦截器的调用返回。下面分别以拦截器链中有一个、两个拦截器的场景加以模拟,如图 5-14 所示。
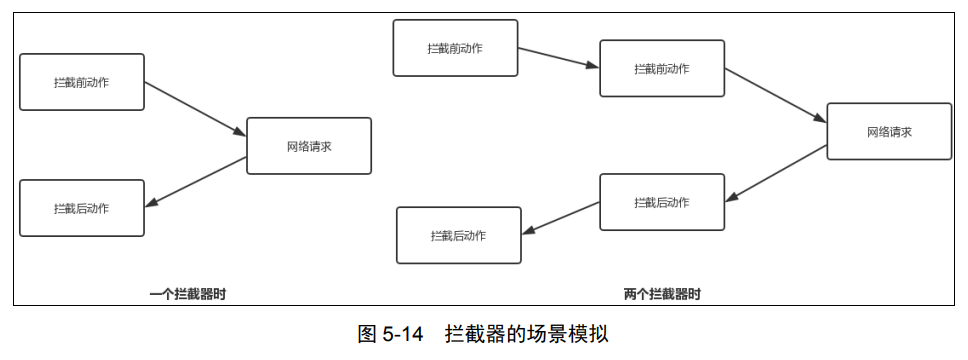
拦截器是一种能够监控、重写、重试调用的机制。通常情况下,拦截器用来添加、移除、 转换请求和响应的头部信息。比如将域名替换为 IP 地址,在请求头中添加 host 属性;也可以添 加我们应用中的一些公共参数,比如设备 id、版本号,等等。回到代码上来,查看最后一行 return getResponse(request, forWebSocket),如果没有更多拦截器的话,就会执行网络请求。现在查看 getResponse 方法做了什么,代码如下所示:
java
Response getResponse(Request request, boolean forWebSocket) throws IOException {
...
engine = new HttpEngine(client, request, false, false, forWebSocket, null, null, null);
int followUpCount = 0;
while (true) {
if (canceled) {
engine.releaseStreamAllocation();
throw new IOException("Canceled");
}
boolean releaseConnection = true;
try {
engine.sendRequest();
engine.readResponse();
releaseConnection = false;
} catch (RequestException e) {
throw e.getCause();
} catch (RouteException e) {
...
}
}getResponse 方法比较长,这里省略了一些代码,在此可以看到创建了 HttpEngine 类并且调 用了 HttpEngine 的 sendRequest 方法和 readResponse 方法。
缓存策略
首先来看看 HttpEngine 的 sendRequest 方法,如下:
java
public void sendRequest() throws RequestException, RouteException, IOException {
if (cacheStrategy != null) return; // Already sent.
if (httpStream != null) throw new IllegalStateException();
Request request = networkRequest(userRequest);
//获取 client 中的 Cache,同时 Cache 在初始化时会读取缓存目录中曾经请求过的所有信息
InternalCache responseCache = Internal.instance.internalCache(client);
Response cacheCandidate = responseCache != null? responseCache.get(request): null;//1
long now = System.currentTimeMillis();
cacheStrategy = new CacheStrategy.Factory(now, request, cacheCandidate).get();
//网络请求
networkRequest = cacheStrategy.networkRequest;
//缓存的响应
cacheResponse = cacheStrategy.cacheResponse;
if (responseCache != null) {
//记录当前请求是网络发起还是缓存发起
responseCache.trackResponse(cacheStrategy);
}
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body());
}
//不进行网络请求并且缓存不存在或者过期,则返回 504 错误
if (networkRequest == null && cacheResponse == null) {
userResponse = new Response.Builder()
.request(userRequest)
.priorResponse(stripBody(priorResponse))
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(EMPTY_BODY)
.build();
return;
}
// 不进行网络请求而且缓存可以使用,则直接返回缓存
if (networkRequest == null) {
userResponse = cacheResponse.newBuilder()
.request(userRequest)
.priorResponse(stripBody(priorResponse))
.cacheResponse(stripBody(cacheResponse))
.build();
userResponse = unzip(userResponse);
return;
}
//需要访问网络时
boolean success = false;
try {
httpStream = connect();
httpStream.setHttpEngine(this);
...
}
}上面的代码显然是在发送请求,但是最主要的是做了缓存的策略。上面代码注释 1 处的 cacheCandidate 是上次与服务器交互时缓存的 Response,这里的缓存均基于 Map。key 是请求中 url 的 md5,value 是在文件中查询到的缓存,页面置换基于 LRU 算法,我们现在只需要知道 cacheCandidate 是一个可以读取缓存 Header 的 Response 即可。根据 cacheStrategy 的处理得到了 networkRequest 和 cacheResponse 这两个值,根据这两个值的数据是否为 null 来进行进一步的处 理。在 networkRequest 和 cacheResponse 都为 null 的情况下,也就是不进行网络请求并且缓存 不存在或者过期,这时返回 504 错误;当 networkRequest 为 null 时也就是不进行网络请求,如 果缓存可以使用时则直接返回缓存,其他情况则请求网络。
接下来查看 HttpEngine 的 readResponse 方法,如下所示:

这个方法主要用来解析 HTTP 响应报头。如果有缓存并且可用,则用缓存的数据并更新缓存,否则就用网络请求返回的数据。再来查看上面代码注释 1 处的 validate 方法是如何判断缓存是否可用的:
java
private static boolean validate(Response cached, Response network) {
//如果服务器返回 304,则缓存有效
if (network.code() == HTTP_NOT_MODIFIED) {
return true;
}
//通过缓存和网络请求响应中的 Last-Modified 来计算是否是最新数据。如果是,则缓存有效
Date lastModified = cached.headers().getDate("Last-Modified");
if (lastModified != null) {
Date networkLastModified = network.headers().getDate("Last-Modified");
if (networkLastModified != null&& networkLastModified.getTime() < lastModified.getTime()) {
return true;
}
}
return false;
}如果缓存是有效的,则返回 304 Not Modified,否则直接返回 body。如果缓存过期或者强 制放弃缓存,则缓存策略全部交给服务器判断,客户端只需要发送条件 GET 请求即可。条件 GET 请求有两种方式:一种是 Last-Modified-Date,另一种是 ETag。这里采用了 Last-ModifiedDate,通过缓存和网络请求响应中的 Last-Modified 来计算是否是最新数据。如果是,则缓存有效。
失败重连
最后我们再回到 RealCall 的 getResponse 方法,如下所示:
java
Response getResponse(Request request, boolean forWebSocket) throwsIOException {
...
boolean releaseConnection = true;
try {
engine.sendRequest();
engine.readResponse();
releaseConnection = false;
} catch (RequestException e) {
throw e.getCause();
} catch (RouteException e) {
HttpEngine retryEngine = engine.recover(e.getLastConnectException(), null);//1
if (retryEngine != null) {
releaseConnection = false;
engine = retryEngine;
continue;
}
throw e.getLastConnectException();
} catch (IOException e) {
HttpEngine retryEngine = engine.recover(e, null);//2
if (retryEngine != null) {
releaseConnection = false;
engine = retryEngine;
continue;
}
throw e;
} finally {
if (releaseConnection) {
StreamAllocation streamAllocation = engine.close();
streamAllocation.release();
}
}
...
engine = new HttpEngine(client, request, false, false, forWebSocket, streamAllocation, null, response);
}}在上面代码注释 1 和注释 2 处,当发生 IOException 或者 RouteException 时都会执行 HttpEngine 的 recover 方法,它的代码如下所示:
java
public HttpEngine recover(IOException e, Sink requestBodyOut) {
if (!streamAllocation.recover(e, requestBodyOut)) {
return null;
}
if (!client.retryOnConnectionFailure()) {
return null;
}
StreamAllocation streamAllocation = close();
return new HttpEngine(client, userRequest, bufferRequestBody,
callerWritesRequestBody,forWebSocket,streamAllocation, (RetryableSink)requestBodyOut, priorResponse);
}通过最后一行可以看到,其就是重新创建了 HttpEngine 并返回,用来完成重连。