01 骨架提取的任务引入
骨架(或中轴线)具有在二进制形状和自然图像中提供紧凑而有意义的对象表示的潜力(以下简称为"形状"和"图像"),适用于图像表示和各种多媒体应用。在实践中,对象骨架通常以图形格式编码,即"骨架图",以便于骨架修剪、匹配、分类和分析任务。为了术语的清晰,通常将各种骨架图组件定义如下:
1) 端点:骨架点只有一个相邻点。
2) 交叉点:有三个或更多相邻点。
3) 连接点:既不是端点也不是交叉点。
4) 骨架分支:两个直接连接的骨架点之间的连接点序列。

02 相关方法与现存问题
传统的骨架提取方法主要依赖于图形操作。近年来,由于卷积神经网络(CNN)方法的崛起,采用像素级二进制分类来处理这个问题取得了显著的改进。尽管这些方法取得了部分进展,但仍然存在明显的质量和鲁棒性问题。例如,输出的骨架分支可能出现噪声、不连贯、不完整,并且对变形不够鲁棒。
BlumNet 的引入有效地缓解了这些缺点。具体而言,它将骨架图分解为有组织的组件,通过将任务分割为涉及图形组件检测和组装的独立过程来实现这一目标。
尽管这项任务是优雅而有效的,但仍然存在一些不足之处,比如在细节方面的精度不足和推理时间过长 。向分解和重构骨架提取过程的转变提出了新的挑战,特别是在组件检测的准确性和在分解后的数据集上进行训练的有效性方面。高分辨率图像 凸显了这些问题,特别是在线交叉点处,预测精度出现了不足,这表面了在处理高分辨率数据的细节时存在问题。
BlumNet 采用了基于 Transformer 的架构(如下图所示)来进行输出特征的编码和解码,然而,未能充分设计 Transformer 以更好地匹配输入和输出数据的具体性。因此,对检测模型进行适当修改可以实现更高的准确性和更稳健的结果。此外,尽管与过去的工作相比,BlumNet 可以获得更高的准确性,但其推理时间更长,可能并不适用于所有应用情景。
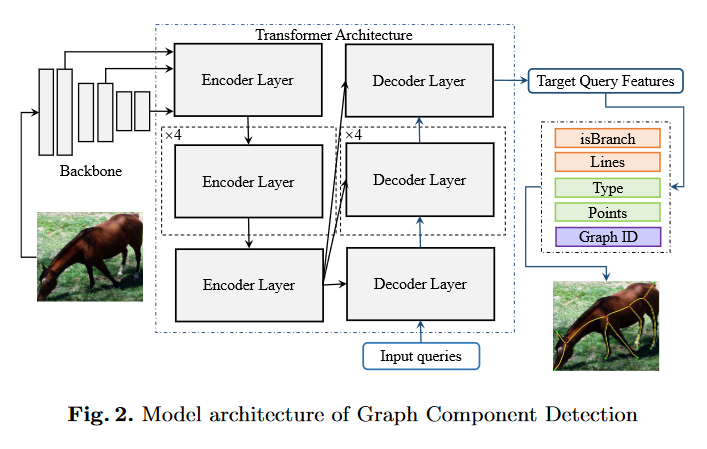
03 预测任务的转移
由于高分辨率图像中信息的丰富性,对骨架细节的预测特别容易受到周围复杂信息的干扰。这种干扰可能导致锯齿状或有问题的骨架,表明在这种情况下无法获得精确的预测。为了有效处理这些复杂信息,模型需要更多的候选选项,以从中选择更准确的一个。因此,增加预测数量是解决这个问题的直观选择。
此外,考虑到一个极端的情况,即图像上的每个像素最初都覆盖线的端点,问题就变成了一个像素级的二进制分类问题 。然而,由于模型在开始时无法准确区分正确的检测对象,在匈牙利匹配的影响下,错误的对象可能会移向骨架。因此,在训练的后期阶段,大量的预测结果将累积在目标骨架的边缘周围。在这一点上,模型只需要从这些结果中进行选择。这种方法与以前的方法的不同之处在于,它将分类区域从整个图像缩小到骨架附近。
以上分析揭示了更多的预测输出也会导致训练过程的变化。在训练的初期阶段,学习的重点是预测点的精确位置。随着训练的进行,预测点逐渐接近真实值,训练的重点将转移到区分预测结果是否在骨架上。从以前的工作中得知,像素级的二进制分类可以在整个图像上取得良好的结果。因此,我们认为在骨架附近对更多的候选选项进行分类将减少模型预测的难度。后续的实验证实了这一分析。
04 实验结果
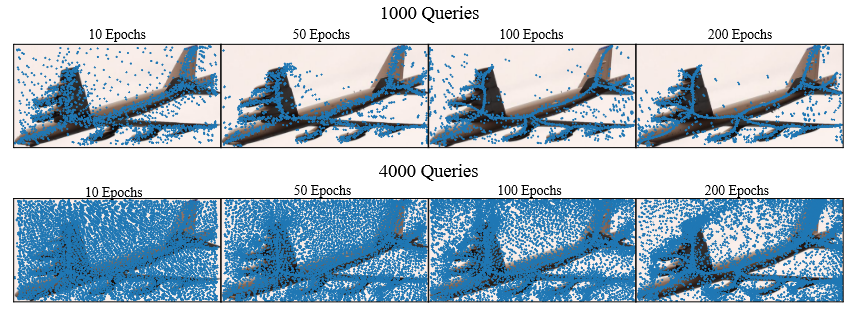
上述四幅图像分别代表在训练 20 个周期、50 个周期、100 个周期和 200 个周期的情况下,使用 1000 个查询时的所有预测输出线。以下四个图显示了在 4000 个查询的情况下的输出情况。图中的蓝色点是成对出现的,因为这些点对代表了预测线的两个端点。在图中呈现点而不是线段使得观察预测分布更加方便。
模型训练的过程可以看作是将离散点聚集到骨架上的过程。在 1000 个查询的情况下,最终预测的点大部分集中在骨架上,但在 4000 个查询的情况下,仍然有大量点散布在图上的各个区域。
在计算损失之前进行匈牙利匹配的前提下,骨架上邻近点的数量越多,在训练过程中预测点与目标点之间的距离就越小。这有助于训练点的位置。更多的预测点会使得训练模型更难以识别输出,但从直觉上看,这似乎比前者更容易学习。
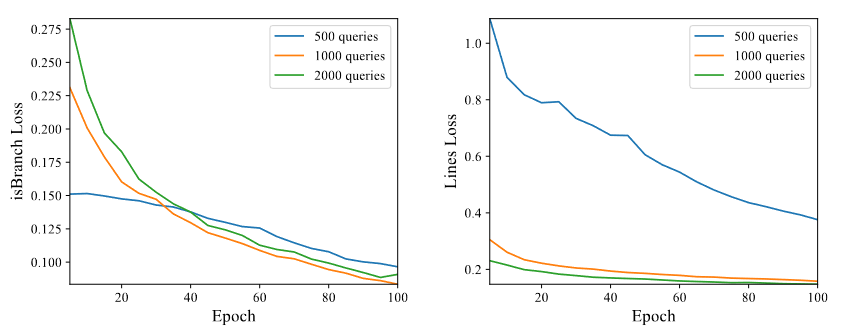
图中绘制了不同查询情况下最重要的两种损失的曲线。IsBranch Loss 限制了输出线的置信度,而 Lines Loss 则指导输出线朝向骨架。与我们的分析一致,增加查询数量有效地降低了 Lines Loss。即使要训练的查询数量增加,模型只需要对更准确的点分配更高的置信度。
因此,isBranch Loss 最初会增加,但随着训练的进行,损失会减小到接近较少查询结果的结果。可以看出,增加查询数量将任务的重点从定位转移到分类。

利用 SK1491 数据集,我们比较了六种不同 query 数量的情况下的结果。如表所示,在使用 VGG16 和 Swin-base 骨干网络的情况下,在 SK1491 数据集上达到了最佳性能,分别获得了 0.805 和 0.836 的得分。另一方面,在使用 Resnet50 和 3000 个查询的条件下,获得的最佳性能为 0.804。
可以观察到,初始时,随着查询数量的增加,准确性显著提高。在达到 1000 个查询后,准确性提升的速度减缓,但仍然存在稳定的提升。基于 CNN 的骨干网络通常受到查询数量的影响,需要一定数量的查询才能达到最佳结果。相比之下,Swin-Transformer 即使在较少的 query 数量下也能表现良好。

上图是不同查询下图像骨架提取的比较。结果在红色框内放大显示。
05 总结
增加预测数量显著提高了 BlumNet 内的训练效果和检测准确性。最初,模型专注于定位任务,随后过渡到骨架附近的细节导向预测通过分类任务。这使得模型能够有效处理高分辨率图像中的复杂信息,从而实现更准确的骨架提取。通过调整输入查询,增强了 BlumNet 对不同操作条件的适应能力。