A gated cross-domain collaborative network for underwater object detection

摘要
水下物体检测 (UOD) 在水产养殖和海洋环境保护中发挥着重要作用。考虑到水下环境中低对比度和低光照条件带来的挑战,已经提出了几种水下图像增强 (UIE) 方法来提高水下图像的质量。然而,仅使用增强图像并不能提高 UOD 的性能,因为它可能会不可避免地删除或改变水下物体的关键图案和细节。相反,我们认为探索来自两个域的互补信息对 UOD 是有益的。原始图像保留了场景的自然特征和物体的纹理信息,而增强图像提高了水下物体的可见性。基于这个观点,我们提出了一个门控跨域协作网络 (GCC-Net) 来解决水下环境中能见度差和对比度低的挑战,它由三个专用组件组成。首先,采用实时 UIE 方法生成增强图像,可以提高低对比度区域物体的可见性。其次,引入跨域特征交互模块,以促进原始图像特征和增强图像特征之间的交互和挖掘互补信息。第三,为了防止不可靠的生成结果的污染,提出了一个门控特征融合模块来自适应地控制跨域信息的融合率。我们的方法从跨域信息交互和融合的角度提出了一种新的 UOD 范式。实验结果表明,所提出的 GCC-Net 在四个水下数据集上实现了最佳性能。
1. 引言
海洋是地球上最重要的自然资源之一,在维持地球气候、生物多样性和经济平衡方面发挥着至关重要的作用。水下环境是一个广阔而复杂的生态系统,其独特的物理和生物特征使得研究和监测变得具有挑战性1-3。目前,水下环境的探索依赖于各种类型的设备,包括声纳、视觉引导的自主水下航行器(AUV)和遥控水下航行器(ROV)。通过配备水下摄像头,AUV和ROV可以检测和观察水下物体4,5。为了使AUV或ROV能够进行物体感知,水下物体检测是一项至关重要的计算机视觉任务,旨在定位和识别海洋生物或海洋垃圾。
水下物体检测(UOD)与通用物体检测(GOD)7-9 之间最大的区别在于不同的检测环境。水下图像不可避免地受到能见度差、光线折射、吸收和散射的影响4。一些研究1,10,11专注于提高水下图像的质量,结果表明,通过水下图像增强(UIE)处理的图像对后续的物体检测任务是有帮助的。然而,一些研究2,6,12指出,仅使用增强图像可能不会提高检测的有效性,甚至可能导致性能严重下降。这是因为尽管这些UIE方法在人的感知中实现了更好的视觉恢复,但算法对场景的感知与人眼不同。简单地校正水下场景的颜色和对比度并不一定有助于理解场景。此外,增强过程可能不可避免地去除或改变关键模式和细节,这可能会在图像中引入噪声或伪影2,6。因此,一些研究2,6,13探索了水下视觉增强与物体检测之间的关系。这些方法大致可以分为两种不同的方式:(1)预处理方式 和(2)多任务学习方式,如图1所示。在预处理方式中,UIE方法作为预处理步骤来生成增强图像,如图1(a)所示。然而,检测算法的有效性无法显著提高,因为UIE方法可能引入噪声或伪影,从而妨碍检测过程。在多任务学习方式中,一些研究6,14将视觉恢复和物体检测优化为一个多任务联合学习问题,以引导增强朝向有利于检测的方向,如图1(b)所示。然而,这些方法需要配对的退化图像和清晰图像来训练UIE模型,而在实践中获取配对图像是困难的。
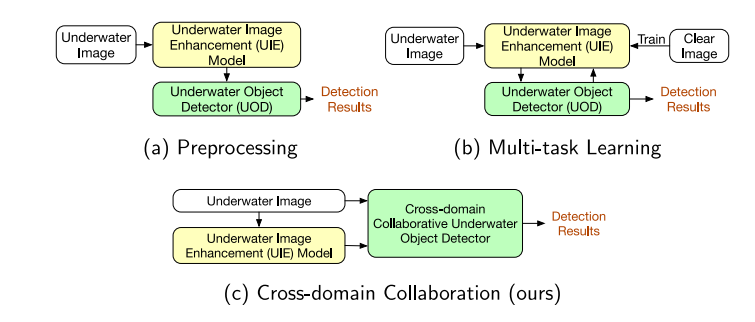
与之前的方法不同,我们提出了一种新颖的跨域协作范式,涉及来自UIE生成的增强图像域和原始图像域的特征的交互与融合,如图1©所示。受到UIE研究4,12的启发,增强图像可以改善能见度质量。我们的工作动机是探讨为什么这些视觉上更清晰的增强图像会降低水下物体检测的性能,这可能是因为图像增强过程丢失了一些对物体检测有用的原始信息。因此,我们尝试整合来自原始域和增强域的特征,以改善UOD任务。由于增强图像有助于提高水下图像的视觉质量,提供更清晰和更易辨别的物体边界,这对解决UOD中遇到的低对比度和低光照问题是有益的。另一方面,原始图像保留了场景的自然特征,并提供了关于物体的清晰纹理信息。UIE生成的增强图像域和原始图像域对水下物体检测都是有益的,因为每个域提供了独特而有价值的信息。我们认为,探索原始图像与增强图像之间的交互与融合将有助于准确识别水下物体。在协作过程中有两个主要挑战:(1)如何有效获取有前景的增强图像并提取增强特征?(2)如何与从增强图像和原始图像中提取的特征进行交互和融合?
在本文中,我们提出了一种门控跨域协作网络(GCC-Net),该网络学习来自两个域的图像特征之间的交互与融合。我们的方法提供了一种新颖的方式,将UIE和UOD整合到一个统一的框架中,如图1©所示。所提出的统一框架具有三个专门的组件,以解决上述挑战。具体而言,对于挑战(1),由于缺乏丰富的配对清晰和失真水下图像,以及合成数据无法完全模拟所有水下条件,因此很难为UOD任务重新训练新的UIE模型。因此,我们开发了一种名为"water-MSR"的实时UIE模型,基于现有的多尺度Retinex模型15和IMSRCP16。所提出的模型通过逐步减小图像大小并递归调用快速滤波算法来加速基础模型。它使得UIE模型能够实时集成到物体检测框架中。对于挑战(2),我们提出了一种基于变换器的跨域特征交互(CFI)模块,以捕获多域特征的交互与协作。此外,我们设计了一种门控特征融合(GFF)机制,使用门控函数自适应地控制原始域和增强域信息的融合速率。门控机制减轻了由water-MSR生成的一些不可靠结果造成的负面影响。
我们的主要贡献可以总结如下:
- 我们提出了一种门控跨域协作网络(GCCNet),以解决水下环境中能见度差和对比度低的问题。我们的模型同时并行处理原始图像和增强图像,然后在一个单一框架内交互和融合来自两个域的信息。
- 开发了一种实时UIE方法water-MSR,用于生成增强图像,可以提高低光照区域水下物体的能见度。同时从原始和增强图像域学习特征有助于在低对比度和低光照条件下识别水下物体。
- 设计了一种新颖的跨域特征交互(CFI)模块,以促进特征交互并探索增强图像和原始图像之间的互补信息。此外,提出了一种门控特征融合(GFF)机制,以自适应地控制跨域信息的融合比例,从而避免一些不可靠生成结果的污染。
- 在四个公共水下数据集上进行了广泛的实验:DUO 17、Brackish 18、TrashCan 19和WPBB 5,证明了所提出模型的有效性。所提出的GCCNet在这四个数据集上达到了最先进的性能。我们的代码将发布在 https://github.com/Ixiaohuihuihui/GCC-Net。
2. 相关工作
2.1. 水下图像增强
现有的水下相机通常安装在视觉引导的自主水下航行器(AUV)上。尽管使用了高质量的相机,但水下图像仍受到水中光吸收和散射的影响。因此,原始水下图像和视频很少能满足视觉质量的期望,这将影响模式识别和物体检测的性能。由于深度学习网络是通过高质量图像进行训练的,基于学习的算法假设输入是清晰的图像。现有的水下图像增强(UIE)模型通常利用关于场景的先验知识或统计假设。Chiang等人20提出了一种水下图像形成模型,通过去雾算法增强水下图像。所提出的水下图像退化模型在各种UIE方法中得到了广泛应用。Li等人21采用生成对抗网络(GAN)和图像形成模型合成退化/清晰图像对,以重建清晰图像。Li等人22设计了一种水下图像合成算法,可以模拟不同的水下类型和退化水平,然后重建清晰的潜在水下图像。Islam等人4提出了一种基于条件生成对抗网络的实时水下图像增强模型。
Sea-thru方法23通过估计反向散射来恢复水下图像中丢失的颜色。Zhang等人24提出了一种最小颜色损失和局部自适应对比度增强(MMLE)方法,用于水下图像增强,该方法利用基于最小颜色损失原则和最大衰减图指导的融合策略,局部调整颜色和细节。此外,它采用积分和平方积分映射来实现局部图像块均值和方差的自适应调整,从而增强对比度。为了应对现有UIE数据集的局限性,如图像稀缺、有限的水下场景或缺乏真实场景,Peng等人25引入了一个名为LSUI的大规模水下图像数据集。此外,他们提出了一种U形变换器,以提高UIE任务的性能。尽管许多研究提到它们作为高层下游任务(例如物体检测和分割)的预处理步骤的潜在价值,但据我们所知,没有人将这些方法应用于水下物体检测(UOD)任务。由于UIE数据集(如EUVP数据集4)与UOD数据集之间存在显著的领域转移,以及UOD数据集中缺乏相应的清晰场景数据集,在UOD数据集上重新训练UIE模型似乎非常具有挑战性。
与将现有基于深度学习的UIE方法视为离线预处理步骤不同,我们的方法将UIE模型和UOD模型同时集成到一个统一框架中,使UIE模型能够辅助UOD模型。我们的方法是首次从跨域数据交互和融合的角度提高水下物体检测的性能。
2.2 水下物体检测
在过去几年中,水下物体检测因其在海洋工程和水下机器人中的广泛应用而受到许多研究的关注。目前,水下物体检测中最广泛使用的方法是基于深度学习的。由于现有的水下数据集数量有限,一些研究26--30旨在通过数据增强来增加数据的多样性。例如,Lin等人26提出了一种名为ROIMIX的增强方法,以在多个图像之间进行提议级别的融合。Poisson GAN 30也是一种数据增强方法,它使用泊松混合来改变图像中物体的数量、位置甚至大小。一些研究31,32通过提高特征提取能力来改善检测性能。例如,Chen等人31提出了SWIPENET,该网络由高分辨率和语义丰富的超特征图组成。Song等人32提出了一种两阶段检测器Boosting R-CNN,它可以提供高质量的提议,并考虑物体性和IoU预测的不确定性,以建模物体的先验概率。UOD模型需要安装在电池供电的AUV上,因此检测模型应轻量且实时。Yeh等人13提出了一种颜色转换模块,将彩色图像转换为相应的灰度图像,以解决水下颜色吸收的问题,从而在降低计算复杂度的同时提高物体检测性能。Zocco等人5通过改变EfficientDet 33的层分布和架构,提出了一种高效的海洋垃圾检测器。
由于水下环境固有的挑战,如低对比度、各种光照条件和水质变化,图像增强是必要的。现有的方法2,6尝试将水下图像增强作为预处理步骤,并在增强后的图像上进行物体检测。然而,检测性能并不令人满意,甚至导致严重的性能下降。Fu等人12揭示,将水下物体检测(UOD)和水下图像增强(UIE)视为级联独立过程可能对水下检测产生负面影响。由于算法对场景的感知与人眼不同,纠正水下图像的颜色和对比度可能并不一定有助于理解场景,而增强后的图像可能会丢失一些对物体检测有益的重要细节和潜在价值。一些研究如34捕捉参考帧和目标帧之间的相似关系,以准确分割视频序列中每一帧的感兴趣物体。相反,我们的方法侧重于学习两个领域之间特征的交互和融合。Fu等人12还探讨了将UOD和UIE视为联合学习过程的好处,以增强水下物体检测的性能。这涉及在水下物体检测数据集的训练子集上同时训练检测和增强模块,以减少检测损失。Liu等人6通过将该问题视为多任务优化问题来解决这一问题。他们提出了一种对象引导的双重对抗和对比学习网络,以实现视觉恢复和检测精度之间的良好平衡。然而,该方法需要成对的失真-清晰图像来训练UIE模型,并将物体检测任务视为验证任务。在实践中,合成训练样本无法完全模拟所有水下条件,重新训练一个全新的水下增强模型并不能保证对UOD任务的性能提升。
受到最近方法6,12的启发,我们认为增强图像可以纠正水下场景的颜色和对比度,而原始水下图像可以保留场景的自然特征和物体的纹理信息。因此,我们提出了一个统一框架,将现有的图像增强模型集成到物体检测模型中。所提出的方法通过探索互补信息并促进两个图像域之间的交互和融合,从而提高水下物体检测性能。
3. 方法
3.1 概述
所提方法的框架如图2所示,主要由四个组成部分构成:(1) 在线UIE模型waterMSR用于生成所需的增强图像;(2) 提出了跨域特征交互(CFI)模块,以促进增强图像和原始图像之间的特征交互,并探索互补信息;(3) 引入了门控特征融合(GFF)模块,以控制两个域的融合速率;(4) 使用检测头输出结果。
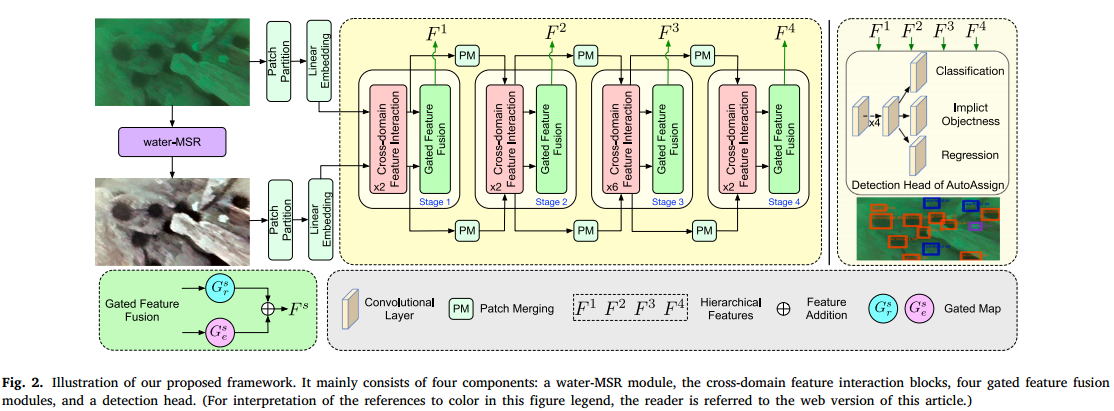
图 2. 我们提出的框架的说明。它主要由四个组件组成:
waterMSR模块、跨域特征交互块、四个门控特征融合模块和一个检测头。
所提出的方法以水下图像为输入,预测物体的标签和位置。给定一幅图像,首先使用在线UIE模型waterMSR生成增强图像作为清晰域。为了促进跨域交互和融合,我们采用Swin Transformer作为主干网络,该网络构建了层次特征图,并且对图像大小具有线性计算复杂度。这两幅图像将分别通过一个pacth划分模块被分割成不重叠的patch。线性嵌入层用于将原始特征投影到任意维度。
然后,这些pathc令牌将被送入所提出的跨域特征交互CFI模块,随后经过一个包含GELU非线性的两层多层感知器MLP。通过所提出的CFI模块,我们可以促进清晰域和原始域之间的信息交互和整合。接下来,我们需要融合两个域的互补信息。为了避免由于不可靠的增强图像而导致的图像区域噪声,我们使用所提出的门控特征融合GFF机制来控制融合比例。在所提出的方法中,共有四个阶段,对应于四个GFF模块。根据Swin-T的设计,跨域特征交互模块的数量分别为{2, 2, 6, 2}。如图2所示,绿色线条表示GFF模块的输出。这四个特征随后被输入到检测头中。最后,检测头用于输出定位和分类结果。
3.2. 在线UIE模型waterMSR
由于水质存在显著的变化,并且在实际操作中难以获取配对的训练样本,因此重新训练UIE方法无法满足所有水质条件下的检测需求。我们希望利用现有的物理UIE模型,并将其整合到UOD任务中。因此,我们选择多尺度Retinex和IMSRCP作为基础UIE方法。为了在UOD框架中实时嵌入UIE模型,我们提出了一种实时UIE模型water-MSR,通过递归调用快速滤波实现。
首先,我们简要回顾多尺度Retinex(MSR)模型。Retinex理论通过将物体的成像过程分为两个组成部分:照明光源和反射率,来建模物体的成像过程,从而消除入射光的影响,以便从噪声图像中恢复物体的特征。多尺度Retinex算法是Retinex的一种变体,能够在不同尺度上捕捉光照变化,并去除输入图像中的照明影响,同时实现动态范围压缩、色彩一致性和亮度重现。接下来,我们提出通过用基于递归图像金字塔的快速滤波替代高斯滤波操作,从而加速基础UIE模型。
给定一幅水下原始图像 I 1 I_1 I1,在线水-MSR算法被开发用于生成增强图像 I 2 I_2 I2。在线 water-MSR算法主要由两个步骤组成。首先,进行颜色预校正,以均衡退化的水下图像并减少主导颜色。设 I mean I_{\text{mean}} Imean 和 I var I_{\text{var}} Ivar 分别为原始图像 I 1 I_1 I1的均值和标准差,则每个RGB通道的最小值 I min I_{\text{min}} Imin和最大值 I max I_{\text{max}} Imax 可以通过以下方式提取:

其中 i ∈ { R , G , B } i \in \{R, G, B\} i∈{R,G,B} 表示RGB图像的颜色通道, I I I 是经过颜色预校正的图像。
其次,我们采用加权融合的多尺度Retinex模型,以平衡动态范围压缩与颜色再现。为了加速算法速度,我们采用快速高斯滤波器,采用递归方法,可以逐步下采样图像并减小相应的高斯核大小,从而降低处理的计算复杂度。基于Retinex理论15,37,38,我们感知到的图像/场景的颜色等于场景的反射率与场景的照明的乘积。给定图像 I ( x , y ) I(x, y) I(x,y) 可以分解为两幅不同的图像:反射图像 R ( x , y ) R(x, y) R(x,y) 和照明像 L ( x , y ) L(x, y) L(x,y)。其公式可表示为:

其中 ⋅ \cdot ⋅ 表示逐元素相乘, ( x , y ) (x, y) (x,y) 是图像上的像素位置。根据单尺度Retinex 37 和多尺度Retinex 38,39,我们使用高斯环绕函数通过对图像进行卷积来找出照明。其数学表达式可以写为:
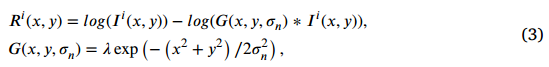
这里, i ∈ { R , G , B } i \in \{R, G, B\} i∈{R,G,B} 是RGB图像的颜色通道, ( x , y ) (x, y) (x,y) 是图像上的像素位置。符号 ( * ) 表示卷积,G(x, y, \\sigma_n) 是高斯滤波器。最后,我们使用多尺度Retinex算法来计算增强后的图像 I 2 I_2 I2,其表达式如下:

其中, N N N是尺度的数量,我们在该方法中设定 N = 3 N = 3 N=3。这里, ω n \omega_n ωn是每个尺度的权重,满足 ω 1 + ω 2 + ⋯ + ω n = 1 \omega1 + \omega2 + \cdots + \omega_n = 1 ω1+ω2+⋯+ωn=1,在本文中我们设定 ω 1 = ω 2 = ⋯ = ω n \omega_1 = \omega_2 = \cdots = \omega_n ω1=ω2=⋯=ωn。本文采用三个尺度 σ n ∈ 30 , 150 , 300 \sigma_n \in 30, 150, 300 σn∈30,150,300, n ∈ 1 , 2 , 3 n \in {1, 2, 3} n∈1,2,3。较小的高斯核(例如, σ = 30 ) \sigma = 30 ) σ=30)能够更好地保留图像细节,适合于细节增强和纹理保留。而较大的高斯核(例如, σ = 150 , 300 ) \sigma = {150, 300} ) σ=150,300)则可以提供更广泛的平滑效果,适合于去噪。这确保了最终图像是各个尺度上最重要信息的组合。该高效策略允许加速滤波,同时保留图像的基本细节。我们递归调用公式(4)以实现快速滤波。图像尺寸逐渐减半,同时滤波器 σ n \sigma_n σn 的尺寸也减半。递归过程持续进行,直到滤波器尺寸达到设定的最小值 σ m i n \sigma_{min} σmin,在我们的方法中设定为10。图像的下采样和滤波器尺寸的减小确保了计算效率,而不影响整体滤波质量。改进的UIE模型water-MSR能够实时生成水下恢复图像,从而产生更清晰、更自然的水下图像。
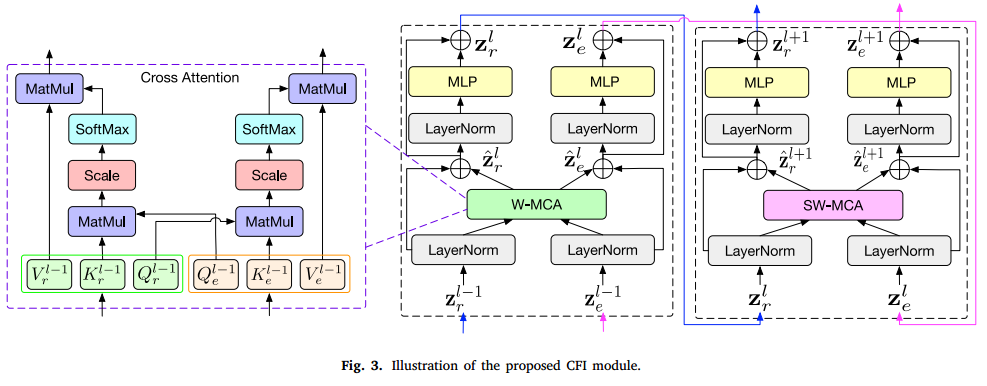
3.3. 跨域特征交互模块
由于增强后的水下图像显示出更多的外观和区分信息,并且能够改善低对比度区域小物体的可见性,而原始水下图像则能够保留场景的自然特征并提供清晰的物体纹理信息,因此在水下物体检测UOD中,交互这两个领域的信息是非常重要的。为了关联这两个领域并利用互补信息,我们设计了一个基于多头交叉注意力MCA的跨域特征交互CFI模块,如图3所示。该模块以原始图像 I 1 ∈ R H × W × C i n I_1 \in \mathbb{R}^{H \times W \times C_{in}} I1∈RH×W×Cin 和增强图像 I 2 ∈ R H × W × C i n I_2 \in \mathbb{R}^{H \times W \times C_{in}} I2∈RH×W×Cin 为起点,其中 H H H, W W W 和 C i n C_{in} Cin 分别是输入图像的高度、宽度和通道数。我们首先通过使用一个补丁划分模块将输入重塑为 H W M 2 × M 2 × C i n \frac{HW}{M^{2}}\times M^{2}\times C_{in} M2HW×M2×Cin的特征。该模块将输入划分为不重叠的 M × M M \times M M×M 局部窗口,其中 H W M 2 \frac{HW}{M^{2}} M2HW是窗口的总数。窗口大小默认设定为 M = 7 M = 7 M=7。然后,对这些特征应用线性嵌入层,将其投影到所需的维度(记作 C C C)。接着,这些补丁标记将被送入所提出的CFI模块。
为了生成分层表示,随着网络的加深,我们通过补丁合并层减少标记的数量。为了实现多域信息之间的交互,我们提议使用多头交叉注意力机制,而不是自注意力机制。由于MCA的计算复杂度与图像大小的平方成正比,这在高分辨率图像上将是不可行的。因此,我们通过将标准的多头交叉注意力模块替换为基于Swin Transformer 35 的移位窗口模块来构建CFI模块。CFI模块由一个基于移位窗口的MCA模块组成,后面跟随一个包含GELU非线性的两层MLP。在每个MCA模块和每个MLP之前应用层归一化(LayerNorm, LN)层,并在每个模块之后应用残差连接。与原始的基于移位窗口的自注意力不同,CFI模块接受两个输入向量,从而实现跨域全局上下文的交换。
具体而言,给定原始图像的特征 z_r 和增强图像的特征 z_e ,它们的大小均为 H \\times W \\times C 。对于每个局部窗口特征 { Z r , Z e } ∈ R M 2 × C \{Z_r,Z_e\}\in\mathbb{R}^{M^2\times C} {Zr,Ze}∈RM2×C,我们使用三个可学习的权重矩阵 { W r Q , W e Q } ∈ R C × C \{W_r^Q,W_e^Q\}\in\mathbb{R}^{C\times C} {WrQ,WeQ}∈RC×C, { W r K , W e K } ∈ R C × C \{W_r^K,W_e^K\}\in\mathbb{R}^{C\times C} {WrK,WeK}∈RC×C, { W r V , W e V } ∈ R C × C \{W_r^V,W_e^V\}\in\mathbb{R}^{C\times C} {WrV,WeV}∈RC×C,这些权重矩阵在不同窗口之间是共享的,用于将其投影到查询 { Q r , Q e } \{Q_r,Q_e\} {Qr,Qe}、键 { K r , K e } \{K_{r},K_{e}\} {Kr,Ke} 和值 { V r , V e } \{V_r,V_e\} {Vr,Ve} 中,具体通过以下方式实现:
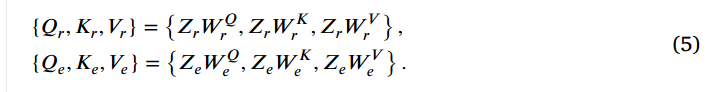
然后,交叉注意力函数本质上计算查询与所有键的点积,然后使用softmax运算符对结果进行归一化,以生成注意力分数。我们遵循文献35,在计算相似性时为每个头部包含一个相对位置偏置 B\\in\\mathbb{R}^{M^{2}\\times M\^{2}}。交叉注意力机制定义为:
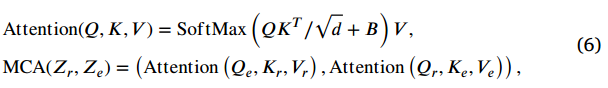
其中, Q , K , V ∈ R M 2 × d Q,K,V\in\mathbb{R}^{M^{2}\times d} Q,K,V∈RM2×d分别是查询、键和值矩阵; d d d是查询/键的维度,M\^2 是窗口中补丁的数量。
在我们的实现中,多头跨域融合单元的过程定义为:
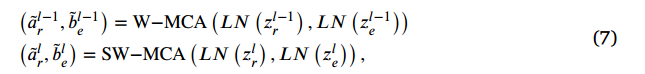
其中, a ~ r l − 1 \tilde{a}_r^{l-1} a~rl−1和 b ~ r l − 1 \tilde{b}_r^{l-1} b~rl−1 分别表示原始图像特征和增强图像特征的第 l − 1 l-1 l−1块窗口基础的多头交叉注意力(MCA)输出特征。而 a ~ r l \tilde{a}_r^{l} a~rl和 b ~ r l \tilde{b}_r^{l} b~rl 则表示第 l l l块移位窗口基础的多头交叉注意力(SW-MCA)的输出特征。W-MCA 和 SW-MCA 分别表示使用常规和移位窗口划分配置的窗口基础多头交叉注意力 35。基于MCA,跨域特征交互的整个过程定义为:

其中, z ^ r l \hat{z}r^l z^rl和 z r l z_r^l zrl分别表示原始图像特征第 l l l块的残差块和多层感知器(MLP)模块的输出特征。而 z ^ e l \hat{z}{e}^l z^el 和 z e l z_e^l zel则表示增强图像特征第 l l l块的残差块和多层感知器(MLP)模块的输出特征。
如公式 (7) 和 (8) 所示,对于来自增强图像的 Q e Q_e Qe,它通过与来自原始域的 K r K_r Kr 和 V r V_r Vr 进行注意力加权,融入跨域信息,同时通过残差连接保留增强图像中的信息,反之亦然。我们的模型能够整合全局跨域交互。
3.4. 门控特征融合模块
在上一节中,我们扩展了Swin-Transformer编码骨干网络,添加了CFI模块,以在两个域之间进行全局信息交换。在这一融合阶段,我们将来自两个域的特征合并为一个单一的特征图。考虑到可能存在来自不可靠生成结果waterMSR的污染,直接整合跨域信息可能会导致负面结果。为了解决这些问题,我们设计了一个门控特征融合GFF)模块,通过使用门控函数来控制跨域信息的融合率。具体而言,输出交互特征图 z r z_r zr和 z e z_e ze分别与门控图 G r ∈ 0 , 1 H × W × C G_{r}\in0,1^{H\times W\times C} Gr∈0,1H×W×C 和 G e ∈ 0 , 1 H × W × C G_e\in0,1^{H\times{W\times C}} Ge∈0,1H×W×C相关联。利用这些门控图,GFF模块的机制可以用以下方程表示:

其中, F s {\boldsymbol{F}}^{s} Fs是GFF模块第 s s s 阶段的输出特征。这里, s ∈ { 1 , 2 , 3 , 4 } s\in\{1,2,3,4\} s∈{1,2,3,4}, ⊕ \oplus ⊕ 表示特征加法操作, ⊙ \odot ⊙ 表示特征乘法操作。 w r s w_r^{s} wrs和 w e s w_e^s wes分别由卷积层进行参数化。
通过学习到的门控函数,我们可以有效地聚合原始图像和增强图像的跨域优势信息,而门控函数控制器则专注于调节跨域信息的融合率。如图2所示,GFF模块的数量为4。四个阶段的输出分辨率分别为 ( H 4 × W 4 ) \left(\frac{H}{4}\times\frac{W}{4}\right) (4H×4W)、 ( H 8 × W 8 ) \left(\frac{H}{8}\times\frac{W}{8}\right) (8H×8W)、 ( 16 4 × W 16 ) \left(\frac{16}{4}\times\frac{W}{16}\right) (416×16W) 和 ( H 32 × W 32 ) \left(\frac{H}{32}\times\frac{W}{32}\right) (32H×32W)。这里, H H H 和 W W W 是输入图像的高度和宽度。这些阶段共同生成一个分层表示,并可以方便地利用不同的现有检测头进行检测任务。
3.5. 检测头
我们的方法可以应用于许多现有的流行两阶段或单阶段检测器,通过与不同的检测头结合。在获取分层特征图后,这些特征图将被发送到检测头,以输出定位和分类结果。在本文中,我们采用了AutoAssign 7 的检测头,如图2所示。AutoAssign的检测头通过完全可微的加权机制实现了外观感知。而AutoAssign的置信度加权可以用于调整每个物体实例的特定分配策略。该检测头能够很好地适应UOD任务中各种大小和形状的水下物体。在我们的实验中,我们还验证了将所提方法与其他检测头(例如,Faster R-CNN 40 和 Deformable DETR 41)结合的性能,并取得了良好的效果。所提框架以端到端的方式进行优化。不同的检测头配备了不同的损失函数。例如,当我们使用AutoAssign检测头时,损失函数与AutoAssign中的损失函数相同。
4. 实验
4.1. 数据集
我们在四个具有挑战性的水下数据集上(DUO 17、Brackish 18、Trashcan 19 和 WPBB 5)进行实验,以验证我们方法的性能。
DUO 17 是一个新发布的水下数据集,包含多种水下场景和更合理的标注。它是UTDAC2020数据集 31 的精炼版本,该数据集来源于2020年水下目标检测算法竞赛。该数据集包含7782张图像(6671张用于训练;1111张用于测试),并在4个常见类别中包含74,515个实例:海胆、海参、海星和扇贝。数据集中的图像具有四种分辨率:3840 × 2160、1920 × 1080、720 × 405和586 × 480。
Brackish 18 是第一个在温带咸水中捕获的带注释的水下图像数据集。它包含6个类别:大鱼、螃蟹、水母、虾、小鱼和海星。训练集、验证集和测试集分别随机分割为9967、1467和1468张图像。图像大小为960 × 540。
TrashCan 19 是第一个带有实例分割注释的水下垃圾数据集。它包含16个类别,包括垃圾、遥控潜水器(ROVs)以及各种海洋植物和动物等。训练集和测试集分别随机分割为6008和1204张图像。
WPBB 5 是一个水中塑料袋和瓶子的检测数据集,包含带注释的图像(目前有900张图像)。该数据集包含2个常见类别:塑料袋和塑料瓶。训练集和测试集分别随机分割为720张和180张图像。
4.2. 实验细节和评估指标
实验细节:我们的方法是在 MMdetection 42 上实现的。对于我们的主要结果,我们使用多尺度训练,长边设置为 1300,短边设置为 800。训练计划为 36 个时期,初始学习率为 2.5 × 10−3,学习率分别在 27 个和 33 个时期后降低 0.1。 我们的方法在 2 个 GeForce RTX 3090 GPU 上进行训练,总批次大小为 4(每个 GPU 2 个图像)用于训练,单个 3090 GPU 用于推理。我们采用 AdamW 43 进行训练优化,其中权重衰减为 0.0001,动量为 0.9。在实验中,除了传统的水平翻转外,没有使用任何数据增强。所有其他超参数都遵循 MMdetection 中的设置。
评估指标:本文报告的主要结果遵循标准 COCO 样式平均精度 (AP) 指标,包括 𝐴𝑃50(IoU = 0.5)、𝐴𝑃75(IoU = 0.75)和 AP。AP 通过对多个 IoU 阈值取平均值来测量,范围从 0.5 到 0.95,间隔为 0.05。
4.3. 最佳方法比较
我们在四个水下数据集上将 GCC-Net 与一些最佳方法进行了比较。结果如表 1 和表 2 所示。
4.3.1. DUO数据集的结果
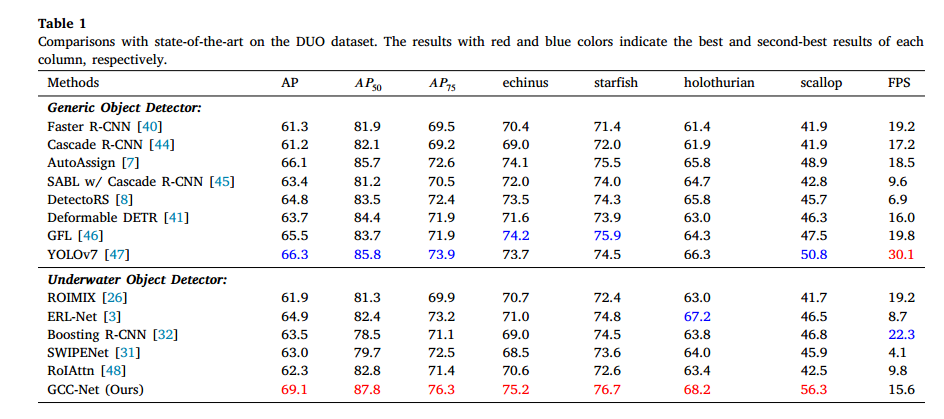
我们评估了GCC-Net的有效性,并与基线方法 7 及最先进的方法进行了比较。为了公平比较,我们将比较的方法分为两组,即通用目标检测器和水下目标检测器。表1总结了DUO数据集的结果,我们得出两个观察结果。
首先,在AP(平均精度)测量的准确性方面,我们达到了69.1%的AP。将GCC-Net与基线方法AutoAssign 7 进行比较,所提方法比AutoAssign高出3.0%(66.1%对比69.1%)。在使用相同的主干网络Swin-T 35 的情况下,GCC-Net在通用目标检测(GOD)方法(例如DetectoRS 8 和YOLOv7 47)以及水下目标检测(UOD)方法(例如SWIPENET 31 和Boosting R-CNN 32)中取得了最佳结果。具体而言,GCC-Net比DetectoRS高出4.3%(64.8%对比69.1%)、比Deformable DETR高出5.4%(63.7%对比69.1%)、比GFL高出3.6%(65.5%对比69.1%),以及比YOLOv7高出2.8%(66.3%对比69.1%),这都是一个显著的差距。
关于与UOD方法的比较,我们选择了最近的开源方法进行比较。所提方法在这些方法中也取得了最佳结果。具体而言,GCC-Net超越了SWIPENET 6.1%(63.0%对比69.1%)、Boosting RCNN 5.6%(63.5%对比69.1%)、RoIAttn 6.8%(62.3%对比69.1%)和ERL-Net 4.2%(64.9%对比69.1%)。实验结果证明了我们方法在水下目标检测中的优越性能。复杂的水下环境给目标检测带来了新的挑战,例如低对比度和不平衡的光照条件。我们的方法有效地解决了这些问题,使低对比度区域中的物体清晰可见,从而提高了水下目标检测任务的性能。
其次,在相同设置下,我们比较了不同方法在DUO数据集上的推理速度。测试的硬件平台为GeForce RTX 3090,批处理大小为1。我们在实验中采用单尺度测试。如表1所示,我们达到了15.6 FPS。我们的方法展示了与其他方法相当的处理速度,满足实时操作的要求。
4.3.2. TrashCan和WPBB数据集的结果
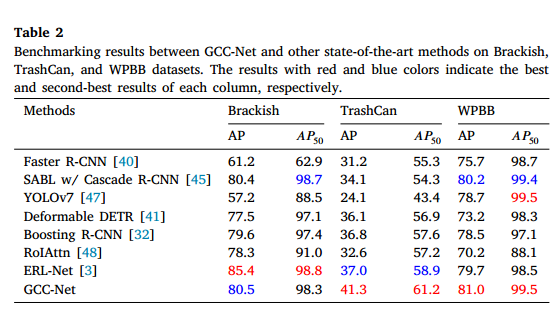
这两个数据集均包含各种类型的水下垃圾。实验结果如表2所示。这些结果在两个数据集上均表现出色,超越了Faster R-CNN 40、SABL 45、YOLOv7 47、Deformable DETR 41、Boosting R-CNN 32、RoIAttn 48 等方法。具体而言,GCC-Net在TrashCan数据集上达到了41.3%的AP,超越了最先进的方法ERL-Net 4.3%。在WPBB数据集上,GCC-Net达到了81.0%的AP,超越了最先进的方法SABL 0.8%。
TrashCan数据集中的水域环境主要为深蓝色,悬浮颗粒浓度较高,导致图像相对模糊。相比之下,WPBB数据集包含在浅蓝水域中捕获的水下图像。实验结果表明,我们的方法在各种水下环境中均能实现出色的检测性能,无需重新训练UIE模型,从而突显了所提方法的有效性和鲁棒性。
4.3.3. Brackish数据集的结果
Brackish数据集的比较结果如表2所示。GCC-Net在该数据集上达到了80.5%的AP和98.3%的 A P 50 AP_{50} AP50,超越了大多数通用目标检测(GOD)和水下目标检测(UOD)方法。值得注意的是,我们的方法在Brackish数据集上未能超越ERL-Net 3,我们认为这可能是由于Brackish数据集 18 是在咸水环境中收集的,该环境的特征是灰色或黑色外观,而不是水下环境中常见的蓝色或绿色。因此,UIE模型在这种环境中的效果可能有所降低。ERL-Net通过采用多层次特征的方法在咸水数据集上实现了性能提升,但牺牲了检测效率。相比之下,我们提出的方法在推理速度上优于ERL-Net,这对于水下机器人平台的实际部署是一个关键因素。这一优势使我们的方法更适合于实际应用。
4.4. 消融研究
在本节中,我们在DUO数据集上进行了一系列消融实验,以评估我们所提方法的有效性。我们选择AutoAssign 7 作为消融实验的基线,原因在于其出色的性能和高效的推理速度。
4.4.1. 水下图像增强(UIE)模型的影响
为了展示UIE方法在水下目标检测(UOD)任务中的作用,我们进行两项实验:(1)探索仅使用增强图像作为UOD输入的性能,如表3所示;(2)使用不同UIE或颜色抖动方法生成的图像作为另一图像域。该设置旨在验证性能提升源于原始图像和增强图像之间的交互与协作,而非仅仅由于输入图像和网络参数的增加,如表4所示。
在第一次消融实验中,我们使用三种水下图像增强(UIE)方法(MMLE 24、FUnIE-GAN 4 和所提的水-MSR)来生成增强图像并评估目标检测性能。在此实验中使用AutoAssign 7 作为基线。MMLE是一种物理UIE模型,依据最小颜色损失原则和最大衰减图引导融合策略来调整输入图像的颜色和细节。由于MMLE 24 的代码经过加密并在Matlab中实现,因此我们在离线模式下运行该模型。FUnIE-GAN 4 是一种基于深度学习的实时UIE方法,由于缺乏成对的失真和清晰图像集,我们使用其预训练模型。如表3所示,仅使用增强图像作为输入的性能不如直接使用原始图像。这一结果归因于增强图像可能会丢失关键模式或引入噪声,从而妨碍检测过程。此外,MMLE的处理时间约为每幅图像1.72秒,这不符合实时性能的要求。此外,我们比较了基线UIE模型IMSRCP与所提水-MSR模型之间的速度。当我们对一幅1300 × 750大小的图像应用具有300的高斯核大小的IMSRCP方法时,处理时间为20秒。然而,使用我们改进的水-MSR方法时,单幅图像的处理时间降至0.12秒。这表明递归快速滤波策略显著提高了模型的处理速度。
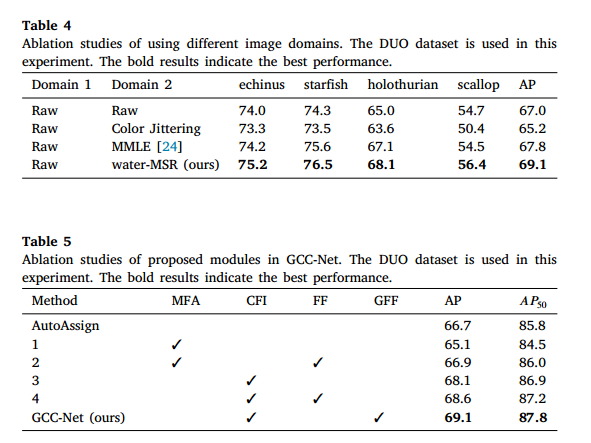
在第二次消融实验中,我们进行了四种设置,如表4所示。在第一种配置中,我们将原始图像输入两次,以调查性能差异是否由网络结构的不同引起。该配置下的准确率为67.0%,与仅输入一幅原始图像(66.1%)所获得的结果相似。该结果表明,我们的方法的性能提升并不单纯依赖于改变网络结构和参数。在第二种配置中,我们使用随机颜色抖动来随机改变原始图像的亮度、颜色、对比度和饱和度,该配置的平均精度(AP)为65.2%。这一结果证明,我们的方法并不依赖于增加输入数据来实现性能的提升。接下来,我们比较了使用水-MSR和其他UIE方法(如MMLE 24)生成的不同增强图像作为另一图像域的性能。其AP分别为69.1%和67.8%。结果表明,原始图像与增强图像之间的交互与融合在水下目标检测中具有优势。
4.4.2. 跨域特征交互(CFI)模块的影响
为了探讨CFI模块的重要性,我们对不同的交互策略进行了研究。我们比较了两种特征交互策略的性能:多层特征相加(MFA)和所提的CFI模块。对于MFA策略,不同图像域的特征在每个变换器阶段直接相加。以Swin-T模型为例,MFA策略的实现可以总结如下:一个主干网络用于提取原始图像的特征,而另一个主干网络用于提取增强图像的特征。然后,我们对每一层的特征进行逐元素相加,以获得融合特征。如表5所示,使用MFA策略的性能为65.1%,低于使用所提CFI模块的性能。使用CFI模块的性能为68.1%,实现了3.0%的性能提升。此外,MFA策略旨在利用两个独立的主干网络生成多域特征,并在每一层进行融合。与所提的CFI模块相比,MFA策略涉及参数数量的显著增加,因为每个主干网络都有其独立的参数集。相对而言,我们采用统一模块与来自不同域的特征进行交互,保持与AutoAssign相同的参数数量,同时实现更优的性能。
为了更好地理解所提模块的作用,我们使用Grad-CAM 49 可视化了主干网络中有无CFI模块的特征图,如图4所示。这些注意力图是基于主干网络第二阶段每个空间单元的激活值计算得出的,有效地指示了网络在分类和定位输入图像中的物体时所关注的区域。显然,所提模块对物体区域的关注度更高,尤其是在对比度较低的区域。我们的方法能够在具有挑战性的条件下准确识别物体。

4.4.4. 不同检测头的影响
我们的方法可以轻松扩展到各种目标检测框架。在本实验中,我们将所提方法应用于不同的检测头,包括无锚(AutoAssign 7)、基于锚点(Faster R-CNN 40)和基于变换器(Deformable DETR 41)的方法,以验证其性能。如表6所示,所提的GCC-Net与Faster R-CNN结合后,性能超过原始Faster R-CNN 4.3个百分点(65.6%对61.3%);GCC-Net与Deformable DETR结合后,性能超出原始Deformable DETR 3.2个百分点(66.9%对63.7%);GCC-Net与AutoAssign结合后,性能超出原始AutoAssign 3.0个百分点(69.1%对66.1%)。此外,我们还比较了所提GCC-Net与基线方法在参数数量和FLOPs(浮点运算)方面的差异。参数表示模型中的可学习参数数量,包括权重、偏置和其他可训练参数。FLOPs作为衡量计算负载的指标,指示程序执行过程中所需的浮点运算次数。较高的FLOPs值通常表明计算负载较重。从表6中可以看出,所提方法的计算负载较高,因为其FLOPs数量较基线方法有所增加。值得强调的是,尽管计算复杂度增加,参数数量保持不变。FLOPs的差异表明我们的方法在训练过程中需要更多的计算资源。然而,重要的是要注意,直接影响内存消耗的参数数量保持一致。此外,我们的方法在所有基线方法中始终表现出色,提升近5个百分点,显示出显著的性能增强。这些结果表明我们方法的强大可扩展性,使其在该领域有潜力成为新的基准。凭借其即插即用的特性,我们的方法可以作为未来工作的可应用模块。
通过这些消融研究,我们得出结论,在 GCC-Net 设计中:在线water-MSR 模型、跨域特征交互和门控特征融合模块都在最终性能中发挥着至关重要的作用。
4.5. 错误分析
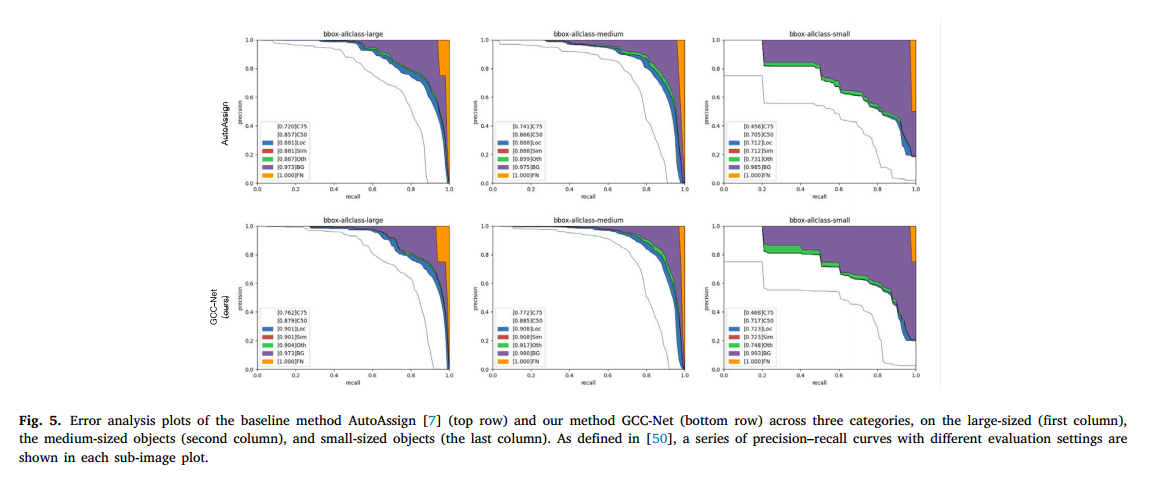
为了进一步分析错误类型,我们利用了mmdetection 42 提供的错误分析工具。图5展示了DUO数据集上的错误图表。每个子图中的图表表示一系列不同评估设置下的精确度-召回曲线。为了计算精确度-召回(PR)曲线,(i) 我们首先设置一系列得分阈值,从0.0到1.00,步长为0.01。
对于每个得分阈值,我们使用公式计算精确度和召回率:
P r e c i s i o n = T P T P + F P P_{recision} = \frac{TP}{TP + FP} Precision=TP+FPTP
R e c a l l = T P T P + F N R_{ecall} = \frac{TP}{TP + FN} Recall=TP+FNTP
(ii) 然后,我们使用计算得到的精确度值和相应的召回率值绘制精确度-召回曲线。召回率值绘制在 x x x轴上,精确度值绘制在 y y y轴上。 (iii) 对于图表标题,"bbox-allclass-large"表示面积大于962的物体,"bbox-allclass-medium"表示面积在322到962之间的中型物体,而"bbox-allclass-small"表示面积小于322的小型物体。 (iv) 指标C75表示严格评估指标IoU = 0.75,我们计算每个检测框与真实框之间的IoU。如果 I o U ≥ 0.75 IoU \geq 0.75 IoU≥0.75,则该检测框被视为真正阳性(TP),否则为假阳性(FP)。然后,我们计算精确度-召回曲线下的面积,以获得C75的AP。其他IoU阈值的AP计算方法与上述步骤相同。
如图5所示,GCC-Net在大和中型子集上的整体AP(即C75)分别为76.2%和77.2%,大幅超出基线方法AutoAssign(即4.2%和3.1%),这表明我们的方法在检测更多水下物体方面的有效性。对于小型子集,我们的方法的AP75为46.8%,而AutoAssign为45.6%。这代表了1.2%的显著提升,突显了我们的方法在有效检测小物体方面的能力。在PASCAL IoU指标IoU = 0.50的情况下,我们的方法在小型子集上的AP50为71.7%,而AutoAssign为70.5%。在忽略定位错误(IoU = 1.0)的情况下,GCC-Net在小型子集上的AP为72.3%,超出基线方法(即71.2%)1.1%,这表明所提方法具有比基线方法更好的回归能力。对于指标Oth,在不考虑类别混淆的情况下计算AP,这意味着如果一个检测匹配任何其他物体,则不再是FP(或TP)。在小型子集上,我们的AP提高到74.8%,而基线方法AutoAssign为73.1%。在去除所有背景和类别混淆假阳性后(指标BG),所提方法在小型子集上实现了99.3%的AP性能,绝对超出基线方法0.8%(99.3%对98.5%)。指标FN表示在去除所有剩余错误后(显然AP = 1)的PR。结果表明我们的方法在不同物体尺度上具有强大的检测能力,特别是在小物体方面。我们认为原因在于UIE模型的集成使得在低对比度的水下区域能够清晰可见物体。
4.6. 定性结果
图6和图7展示了来自DUO、Brackish、TrashCan和WPBB数据集的样本图像的定性结果。我们可以看到,所提方法能够应对水下物体检测(UOD)任务中的各种挑战,包括不同的水下环境、低对比度和小物体以及密集排列的物体。例如,如图6所示,我们展示了真实标注、由水MSR生成的增强图像以及GCC-Net在DUO数据集上的检测结果。可以看出,增强图像提高了低对比度区域中小物体的可见性。结果清楚地表明了我们的方法在密集小物体定位和分类方面的优越性能。我们还展示了GCC-Net在Brackish、TrashCan和WPBB数据集上的定性结果,如图7所示。这些令人鼓舞的结果验证了我们方法在各种水环境中的多样性。


4.7. 限制与未来工作
为了帮助未来的研究者在水下物体检测领域开发更好的算法,我们提供了一些失败案例,如图8所示。所提方法在以下情况下可能导致假检测(用蓝色椭圆表示)或漏检(用黄色椭圆表示):
- 图像极其模糊,特别是当目标隐藏在隐蔽位置时。例如,如第一行所示,一些远处的海胆可能隐藏在岩石缝隙中,使得判断海胆是否存在变得困难。
- 由于携带相机的水下机器人(ROV)的运动,图像出现运动模糊,导致捕获的帧可能模糊。如第二行所示,模型可能错误地将岩石或扇贝分类。此外,模型检测到海胆,但真实标注中并不包含海胆。
- 扇贝的检测准确性需要提高,因为很难区分某些物体是白色岩石还是扇贝。未来的工作可以集中在解决运动模糊问题以及探索生成方法以应对样本数量不足的失衡问题。

5. 结论
在本文中,我们提出了一种端到端的门控跨域协作网络(GCC-Net),旨在解决水下物体检测(UOD)任务中低对比度和可见性差的挑战。我们的方法从一个新的视角整合了图像增强(UIE)和水下物体检测方法,挖掘并融合两个图像域之间的有利信息。我们的研究是首次从跨域数据交互和融合的角度提升水下物体检测性能的工作。所提的GCC-Net包含多个专用组件,包括在线UIE模型"waterMSR"、跨域特征交互模块和门控特征融合模块。与近期的水下目标检测(GOD)和UOD方法相比,GCC-Net在水下数据集(DUO、Brackish、TrashCan和WPBB数据集)上实现了最先进的性能。此外,我们希望这一跨域协作范式能促进未来在水下物体检测及其他多模态计算机视觉任务上的研究工作。