一、前言:为什么我们需要 GraphRAG?
你有没有遇到过这种情况:问大模型一个很专业的问题,它回答得头头是道,但其实全是错的,也就是一本正经地胡说八道,即大模型的幻觉现象。出现这种现象的原因是大模型的知识是静态的,它依赖于训练数据,而无法实时地获取训练之外的数据。
为了解决幻觉问题,RAG 诞生了,它的思路简单来说就是先检索再生成,即先从知识库中检索出相关内容,再把这些结果和问题一起交给大模型生成答案。有关 RAG 的详细原理和实践在我之前的文章(从原理到实战:基于SpringAI的RAG应用探索)已经阐述。而 RAG 的缺陷也很明显,其只能处理"一步到位"的问题,无法处理多跳推理或实体关联的问题,这里举个简单的例子:
erlang
知识库内容:
文档 1:小明的爸爸是老王。
文档 2:老王的女儿是小红。
文档 3:小红是北京大学的学生。
文档 4:.....
问题:
小明的爸爸的女儿在哪里上学?这个问题实际需要 3 步推理:
- 小明的爸爸是老王(从文档 1 获得)
- 老王的女儿是小红(从文档 2 获得)
- 小红在北京大学上学(从文档 3 获得)
对于 RAG,由于存在相似度阈值,一次检索时一般很难把三条文档全部都找到,所以大模型无法把这些信息都串起来,最终依旧会胡说八道。
为了解决这一问题,GraphRAG 诞生了,它将知识图谱引入 RAG 流程,把知识表示成"节点 + 边"的形式,把不同文档中的实体及其关系连接起来。在查询时,不仅会查询出相似度最高的文档,还会基于知识图谱查询出与其关联的文档,因此大模型就能够拥有更加完整的上下文来回答问题。以上面的例子作为示例,在 GraphRAG 中会存在如下的知识图谱:
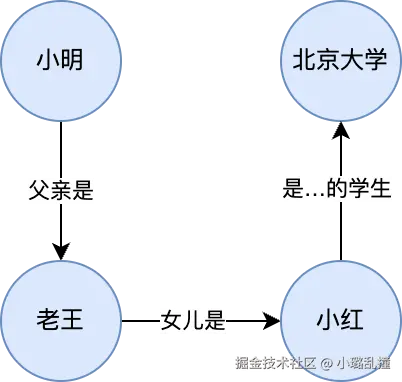
后续讲解使用微软 GraphRAG 版本(github.com/microsoft/g...),相比其他 GraphRAG 实现,其优势在于精细的实体与关系抽取能力、基于图结构的逻辑推理增强、社区检测带来的高效信息聚合,以及可视化报告生成功能,同时与微软生态系统高度兼容,便于在企业知识管理和复杂问答场景中快速部署和应用。
二、GraphRAG 详细流程
与传统 RAG 类似,GraphRAG 的流程总体上也可以分为索引和查询,但二者在实现细节上存在很大的区别。GraphRAG 的详细流程如下图所示:
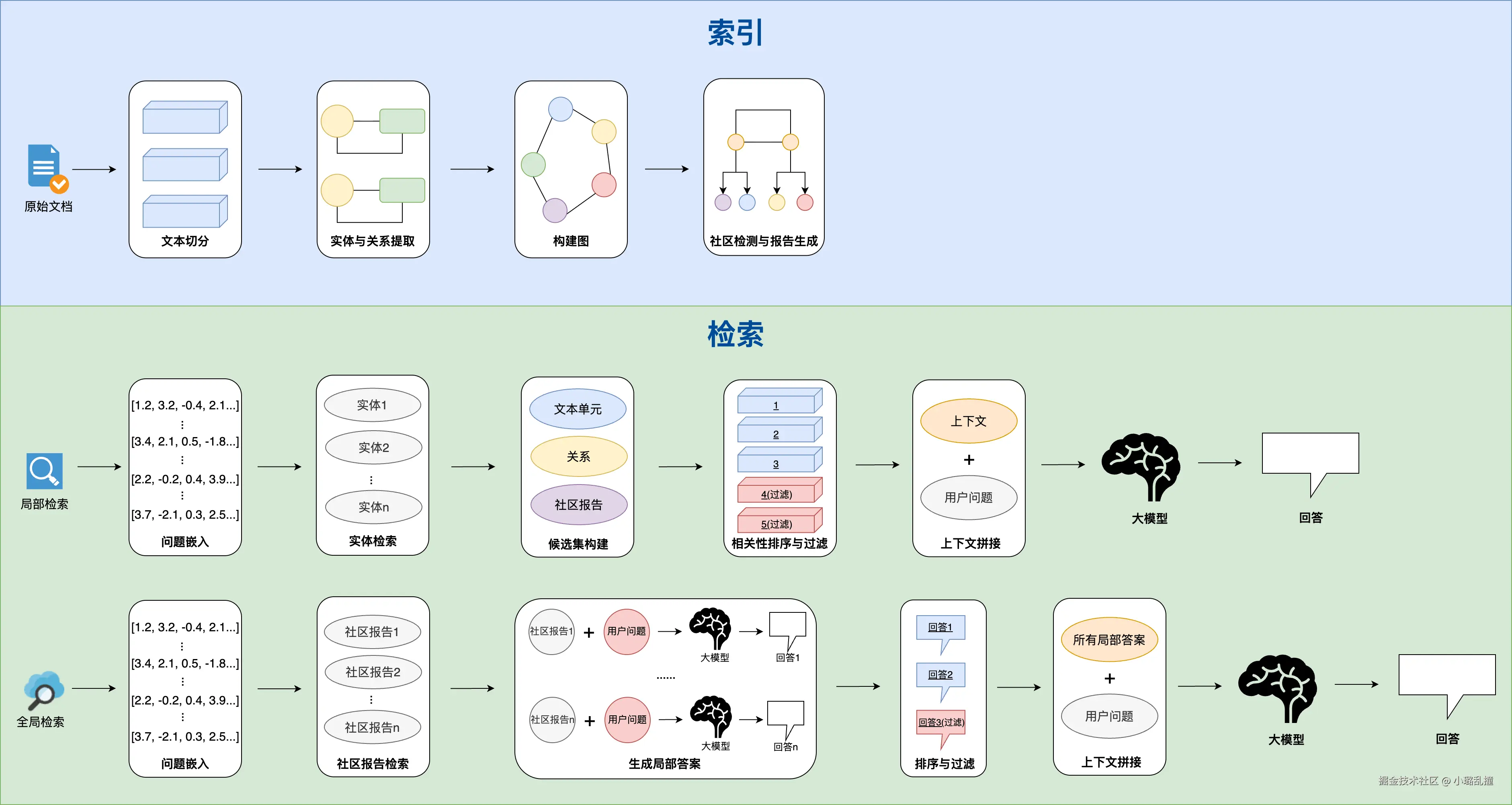
2.1 索引
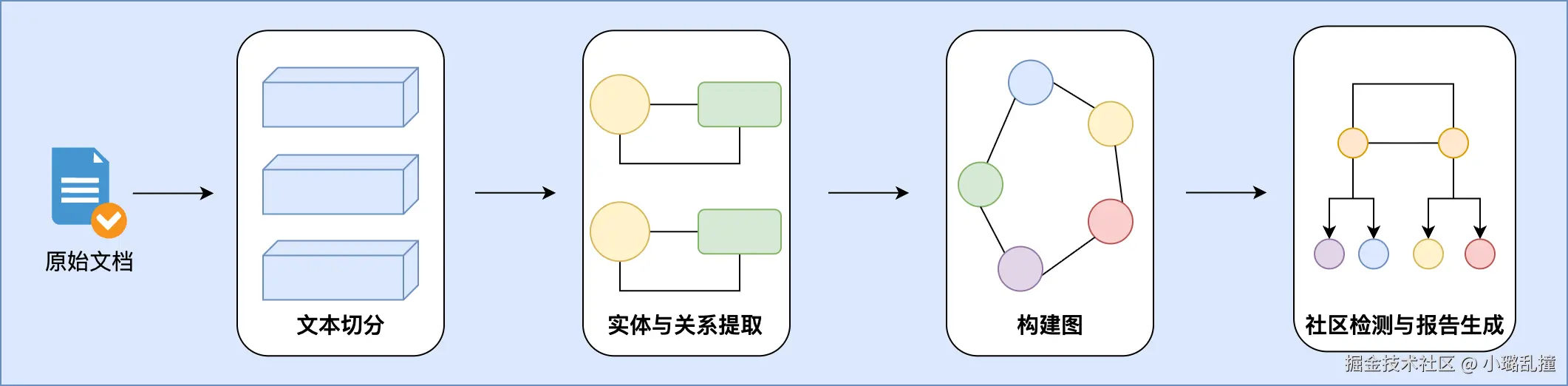
为了更清晰地叙述每个索引流程,这里使用一个简单的示例来贯穿所有的流程来讲解,示例如下:
在2025年春季科技大会上,知名人工智能研究员小明与清北大学计算机学院合作,发布了一款名为"知澜"的多模态大模型。该模型在自然语言处理、图像识别以及语音交互领域均表现出色,能够实现文本、图像和语音信息的无缝理解与生成,支持跨模态知识融合与智能推理。
2.1.1 文本切分
文本切分指的是将原始文本拆分成更小的、可分析的文本单元(TextUnits),文档切分的质量将直接决定了后续检索的准确性和大模型回答的效果,且能够避免超过大模型上下文窗口大小的问题,这一步与传统 RAG 是类似的。
常见的切分策略如下:
| 名字 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 固定大小拆分 | 按指定字数或 token 数来切分 | 实现简单、速度块 | 可能会割裂语句,打断语义完整性 |
| 结构拆分 | 基于文档格式(如 Html、Markdown)拆分,本质上是借助这些文档特有的格式来拆分语句 | 可以保留原始文档的结构逻辑,语义完整度高 | 依赖于结构清晰、规范的文档,对于无结构的语句(如纯文本)无法使用 |
| 语义拆分 | 根据语义边界(如段落、句子、主题变化等)拆分,可以采用 NLP 方法,如如分句、主题检测或 Embedding 聚类 | 最符合人类理解,可保留语义一致性 | 实现复杂,需要依赖 NLP 模型、Embedding 计算或聚类等,且计算开销大,效率低 |
| 递归拆分 | 先按大分隔符(如段落)拆分,再按句子等进行拆分,直到拆分得到的块满足长度限制 | 在语义完整性和长度控制两个度量之间保持平衡 | 设计较复杂,需要合适的层级和递归停止条件 |
以固定 40 token 大小切分策略演示,上面的示例可以切分成如下文本单元表:
| id | human_readable_id | text | n_tokens | document_ids |
|---|---|---|---|---|
| 8df60f2f66c3 | 1 | 在2025年春季科技大会上,知名人工智能研究员小明与清北大学计算机学院合 | 40 | 6db8fe3d86d |
| a2b7b0e354fd | 2 | 清北大学计算机学院合作,发布了一款名为"知澜"的多模态大模型。该模型在自然语言处理 | 40 | 6db8fe3d86d |
| 256254a9806f | 3 | 。该模型在自然语言处理、图像识别以及语音交互领域均表现出色,能够实现文 | 40 | 6db8fe3d86d |
| a723cbe34299 | 4 | 现出色,能够实现文本、图像和语音信息的无缝理解与生成,支持跨模态知识融合 | 40 | 6db8fe3d86d |
| 21232021dc6c | 5 | 模态知识融合与智能推理。 | 17 | 6db8fe3d86d |
- id:全局唯一标识符。
- human_readable_id:便于人类查看的序号,相比 id 会更加直观。
- text:文本单元对应的原始文本。仔细看的话会发现相邻文本单元中出现了重叠的情况,原因是 GraphRAG 采用了重叠窗口切分策略,即在相邻文本单元之间保留一部分重叠内容,以避免语义被硬性截断、保证实体与关系的完整抽取,并在后续检索时提升召回率和准确性。
- n_tokens:文本单元的 token 总数。
- document_ids:表示文本单元来自于哪些文档列表。
2.1.2 实体与关系提取
实体:文本中可以作为"独立对象"存在的东西。它往往是名词或名词短语,比如人物(马斯克)、组织(微软)、地点(北京)、事件(世界杯)、甚至抽象概念(人工智能)。
关系:不同实体之间的联系。它通常表现为动词、介词或逻辑关系,比如"马斯克「创立」特斯拉","微软总部「位于」西雅图"。
文本切分后,GraphRAG 会使用大模型提取出每个文本单元中的实体与关系,并建立实体表和关系表,这样可以让信息的逻辑关系更清晰,方便后续检索、推理和知识图谱构建。
上面的示例的实体系表如下所示:
| id | human_readable_id | title | type | description | text_unit_ids |
|---|---|---|---|---|---|
| cf196a73 | 0 | 2025年春季科技大会 | 事件 | 2025 年春季人工智能研究员小明与清北大学计算机学院合作举办的科技大会 | 8df60f2f66c3 |
| e9933f7b | 1 | 小明 | 人物 | 一位在 2025 年春季科技大会上发表演讲或参与合作的知名人工智能研究员 | 8df60f2f66c3 |
| d0b0b927 | 2 | 清北大学计算机学院 | 组织 | 与人工智能研究员小明合作参加 2025 春季科技大会的清北大学计算机学院 | 8df60f2f66c3 |
| 50d0eff5 | 3 | 知澜 | 项目 | 是一款多模态大模型,由清北大学计算机学院合作发布 | a2b7b0e354fd |
- id:全局唯一标识符。
- human_readable_id:便于人类查看的序号,相比 id 会更加直观。
- title:实体名。
- type:实体类别。
- description:实体描述。
- text_unit_ids:表示实体来自于哪些文本单元列表。
关系如下所示:
| id | human_readable_id | source | target | description | text_unit_ids |
|---|---|---|---|---|---|
| c7c70281 | 0 | 2025年春季科技大会 | 小明 | 小明参加了 2025 年春季科技大会,是该大会的参与者,并可能担任演讲者 | 8df60f2f66c3 |
| ad37582e | 1 | 2025年春季科技大会 | 清北大学计算机学院 | 清北大学计算机学院参加 2025 年春季科技大会 | 8df60f2f66c3 |
| ea303919 | 2 | 小明 | 清北大学计算机学院 | 小明在活动现场与清北大学计算机学院合作 | 8df60f2f66c3 |
| 688cada1 | 3 | 清北大学计算机学院 | 知澜 | 清北大学计算机学院合作发布了"知澜"多模态大模型 | a2b7b0e354fd |
| 4d4ef204 | 4 | 小明 | 知澜 | 小明合作发布了"知澜"多模态大模型 | 8df60f2f66c3,a2b7b0e354fd |
- id:全局唯一标识符。
- human_readable_id:便于人类查看的序号,相比 id 会更加直观。
- source:关系的起点实体。
- target:关系的终点实体。
- description:关系描述。
- text_unit_ids:表示关系来自于哪些文本单元列表。
2.1.3 构建图
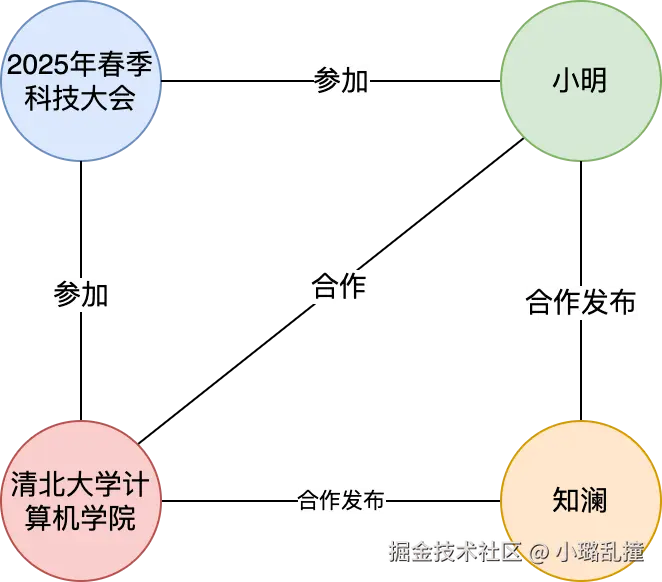
构建图指的是将前一步抽取出的实体和关系组织成知识图谱的过程,每个实体作为图中的节点,实体间通过关系形成边,从而把文本信息结构化为图形表示,这样不仅保留了原始文本的语义,还便于后续进行图搜索和关系推理。
上面的示例的图结构如下所示:
2.1.4 社区检测与报告生成
构建完图后,GraphRAG 会对其构建的图进行结构化分析与信息整理。
首先会进行社区检测,即通过分析图中节点(实体)与边(关系)的连接密度,将图划分为若干社区(社区指的是图结构中紧密关联的节点集合),每个社区内部的节点连接紧密、相关性高,而不同社区之间的连接相对稀疏。具体来说,微软 GraphRAG 使用 Leidan 聚类算法来完成社区检测的动作。社区检测的核心价值在于降低图查询的复杂度,并揭示知识图中的热点区域和关键关系,为后续检索和知识分析提供基础。
在完成社区划分后,会生成社区报告,将社区检测结果转化为可读的分析报告。报告通常包含社区概览、核心节点与关系统计、社区间关系分布、可视化图表以及文本摘要等内容。通过统计每个社区的节点数量、关系密度及主要实体,并结合可视化工具展示社区结构图或热点节点图,用户可以直观理解知识图的结构和信息分布,进而辅助知识发现和决策分析。
上面的示例检测出的社区如下所示,由于示例只有一段文本,因此最终只存在一个社区。
| id | human_readable_id | community | level | title | entity_ids | relationship_ids | text_unit_ids |
|---|---|---|---|---|---|---|---|
| 5ebd0d55 | 0 | 0 | 0 | 社区 0 | cf196a73,e9933f7b,d0b0b927,4d4ef204 | c7c70281,ad37582e,ea303919,688cada1,4d4ef204 | 8df60f2f66c3,a2b7b0e354fd |
- id:全局唯一标识符。
- human_readable_id:便于人类查看的序号,相比 id 会更加直观。
- community:社区编号。
- level:层级,指的是社区在知识图谱中的深度,值越大表示在划分层次中处于更细粒度的层级,如 level = 1 是 level = 0 的子社区。
- title:社区的简短标题。
- entity_ids:属于社区的实体节点列表。
- relationship_ids:属于社区的关系列表。
- text_unit_ids:与社区相关联的文本单元列表。
对应的社区报告如下所示:
| id | human_readable_id | community | level | title | summary |
|---|---|---|---|---|---|
| 1ded1bd0b | 0 | 0 | 0 | 知澜多模态大模型发布 | 在2025年春季科技大会上,人工智能研究员小明与清北大学计算机学院合作,发布了"知澜"多模态大模型。该模型在自然语言处理、图像识别和语音交互方面表现出色,能够实现跨模态知识融合与智能推理。 |
- id:社区报告编号,保证全局唯一。
- human_readable_id:便于人类理解或引用的社区报告编号,在展示时更直观,但不一定保证全局唯一。
- community:该报告所属社区的编号。
- level:报告所属社区的层级。
- title:社区报告的简短标题。
- summary:社区报告总结内容。
2.2 检索
GraphRAG 主要提供了两种查询方法,分别为局部检索和全局检索,局部检索一般会针对问题相关的部分内容进行检索,而全局检索则针对整个知识图谱或所有社区的内容进行检索,类比而言,局部检索就像是在"书的一章里找答案",而全局检索则更像是在"整本书里找答案"。
2.2.1 局部检索

局部检索的流程如下:
- 问题嵌入:通过 Embedding 模型将问题向量化,将问题文本转换成一个固定长度的浮点型数组。
- 实体检索:在知识图谱中寻找与查询向量相似的实体。
- 候选集构建:从找寻到的实体出发,遍历图并收集构建候选集,候选集内容包括原始文本单元(Text Unit)、实体、关系。
- 相关性排序与过滤:将候选结果按照相似度分数、重要性等维度进行排序,保留 top-k 的候选集。
- 上下文拼接:将所有筛选得到的候选集拼接成上下文,与用户的问题拼接起来,共同构成提示词(Prompt)。
- 生成最终答案:将构成的提示词交给大模型处理,并生成最终的结果。
2.2.2 全局检索

全局检索采用了类似于 MapReduce 的策略来完成检索任务,流程如下:
- 问题嵌入:与局部检索类似,也是通过 Embedding 模型将问题向量化,将问题文本转换成一个固定长度的浮点型数组。
- 社区报告检索:检索出与查询向量相似的社区报告。
- 生成局部答案:对每个社区摘要,使用 LLM 生成局部答案,输入的提示词会包括社区摘要内容和用户问题。LLM 除了会生成答案,还会生成对答案的评分,以评估其相关性。这个过程类似于 MapReduce 中的 Map 阶段。
- 排序与过滤:通过先前的分数来对生成的社区级答案进行排序,并过滤掉分数过低的答案。
- 上下文拼接:将之前过滤得到的所有局部答案拼接成上下文,与用户的问题拼接起来,共同构成提示词(Prompt)。这个过程类似于 MapReduce 的 Reduce 阶段。
- 生成最终答案:将构成的提示词交给大模型处理,并生成最终的结果。
2.2.3 局部检索 or 全局检索?
| 局部检索 | 全局检索 | |
|---|---|---|
| 适用场景 | 针对特定实体或事件的具体细节查询 | 需要整体理解整个数据集的抽象性问题 |
| 数据处理方式 | 基于实体进行查询,利用图遍历构建上下文 | 使用预先计算的社区摘要进行查询 |
| 查询方式 | 从最相关的实体开始,逐步构建上下文以生成回答 | 对每个社区生成独立的回答,然后将相关回答汇总成最终结果 |
| 计算效率 | 计算量较小,适合快速响应 | 可能需要处理大量社区摘要,计算资源消耗较大 |
| 适用数据规模 | 适用于小规模数据集,关注具体细节 | 适用于大规模数据集,能够提供全局视角 |
| 优缺点 | 优点:计算效率高,响应快速缺点:可能忽略全局上下文 | 优点:提供全面的视角缺点:计算资源消耗大,可能导致信息冗余 |
三、GraphRAG 实战
3.1 前置环境搭建
在使用 GraphRAG 之前,需要先安装对应的环境:
bash
# python version = 3.10-3.12
pip install graphrag
# 后续用于解析 parquet 格式文件
pip install pandas然后配置数据集,这里使用的数据集示例如下:
scss
在计算机科学的发展过程中,出现了大量不同类型的排序算法。
冒泡排序(Bubble Sort)是一种基础的排序方法,它通过不断比较和交换相邻元素来完成排序,时间复杂度为 O(n²)。
快速排序(Quick Sort)则由托尼·霍尔在 1960 年提出,它采用分治法,将数组分为两个子数组分别排序,平均复杂度 O(n log n)。
除了这两种常见算法,希尔排序(Shell Sort)是一种基于插入排序的改进算法,它通过设置一个步长逐渐缩小直到 1 来提高效率。
在稳定性方面,归并排序(Merge Sort)表现良好,尤其适合处理链表等结构。
另外,堆排序(Heap Sort)利用了堆这种数据结构,能够在 O(n log n) 的时间内完成排序。
近些年,在某些特定场景下,人们也会使用基数排序(Radix Sort)和计数排序(Counting Sort),它们都属于非比较排序,能在 O(n) 时间内完成排序,但对输入有一定限制。
在一些学术研究中,还讨论过鸽巢排序(Pigeonhole Sort),尽管它较少用于实际应用。文件结构(GrpahRAG 在索引构建时默认会访问 input 文件夹下的文件,所以数据集一般放在 Input 文件夹下,顶层文件夹可以自定义,后续的命令中都修改为对应的目录名即可):
css
rag_demo
└── input
└── file.txt然后初始化 GraphRAG 项目:
bash
graphrag init --root ./rag_demo
初始化过程中如果遇到报错:ImportError: cannot import name 'Function' from 'openai.types.chat.chat_completion_message_tool_call',需要修改 GraphRAG 源代码中 aliases.py 文件(路径:site-packages/fnllm/openai/types/aliases.py)的以下内容:
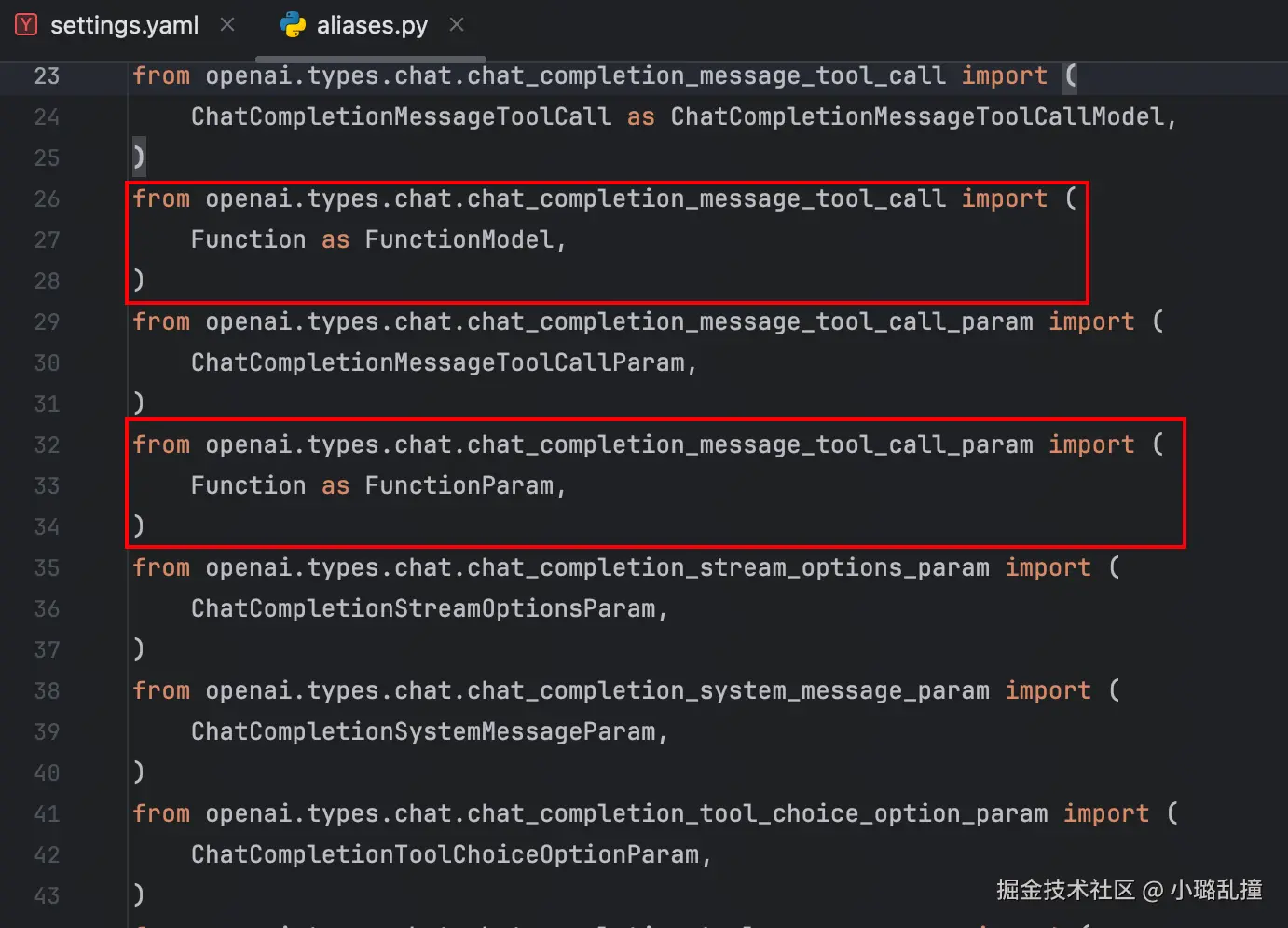
修改为如下内容,原因是在 OpenAI Python SDK 版本 1.99.2 中,原本位于 chat_completion_message_tool_call 模块中的 Function 类被移至 chat_completion_message_function_tool_call 模块。
javascript
from openai.types.chat.chat_completion_message_function_tool_call import (
Function as FunctionModel,
)
from openai.types.chat.chat_completion_message_function_tool_call_param import (
Function as FunctionParam,
)执行完后,目录中会变成以下内容:
bash
rag_demo
├── input
│ └── file.txt
├── prompts
│ ├── basic_search_system_prompt.txt
│ ├── community_report_graph.txt
│ ├── community_report_text.txt
│ ├── drift_reduce_prompt.txt
│ ├── drift_search_system_prompt.txt
│ ├── extract_claims.txt
│ ├── extract_graph.txt
│ ├── global_search_knowledge_system_prompt.txt
│ ├── global_search_map_system_prompt.txt
│ ├── global_search_reduce_system_prompt.txt
│ ├── local_search_system_prompt.txt
│ ├── question_gen_system_prompt.txt
│ └── summarize_descriptions.txt
├── settings.yaml
└── .env- prompts:存放 GraphRAG 内置的提示词模板,对应不同阶段的任务,如 extract_graph.txt 用于抽取实体与关系,构建知识图谱;community_report_text.txt、community_report_graph.txt 用于为每个社区生成报告。
- settings.yaml:配置文件,包含 LLM 配置(模型、温度)、索引参数(chunk 大小、阈值)等。
- .env:环境变量文件,存放密钥、连接配置等信息。
这里给出 settings.yaml 核心配置的示例参数和 .env 脱敏后内容:
yaml
models:
default_chat_model:
type: openai_chat
api_base: ${GRAPHRAG_BASE_URL} # base-url
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY} # api-key
model: gpt-4.1 # LLM 模型
encoding_model: cl100k_base
model_supports_json: true
concurrent_requests: 25
async_mode: threaded
retry_strategy: native
max_retries: 10
tokens_per_minute: auto
requests_per_minute: auto
default_embedding_model:
type: openai_embedding
api_base: ${GRAPHRAG_BASE_URL} # base-url
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY} # api-key
model: text-embedding-3-large # Embedding 模型
encoding_model: cl100k_base
model_supports_json: true
concurrent_requests: 25
async_mode: threaded
retry_strategy: native
max_retries: 10
tokens_per_minute: null
requests_per_minute: null
chunks:
size: 50 # 分块大小
overlap: 10 # 相邻分块重叠部分
group_by_columns: [id]
ini
GRAPHRAG_API_KEY=[填写API_KEY]
GRAPHRAG_BASE_URL=[填写BASE_URL]3.2 索引构建
使用下面的命令构建索引:
bash
graphrag index --root ./rag_demo
执行完后目录会多出以下内容:
lua
rag_demo
├── cache
│ ├── community_reporting
│ ├── extract_graph
│ ├── summarize_descriptions
│ └── text_embedding
├── logs
│ └── logs.txt
└── output
├── communities.parquet
├── community_reports.parquet
├── context.json
├── documents.parquet
├── entities.parquet
├── lancedb
├── relationships.parquet
├── stats.json
├── text_units.parquet
└── summarize_descriptions.txt- cache:索引过程中调用 LLM 或 Embedding API 的中间结果缓存,避免重复调用,如 community_reporting 用于生成社区报告时的中间结果;extract_graph 用于存储从文本抽取出的实体、关系的中间结果。
- logs:索引过程中的运行日志。
- output:最终构建的知识索引,如 communities.parquet 存放社区的结构数据,记录每个社区包含哪些实体、文本单元等信息;text_units.parquet 存放切分后的文本单元结构数据,记录 Embedding 信息。
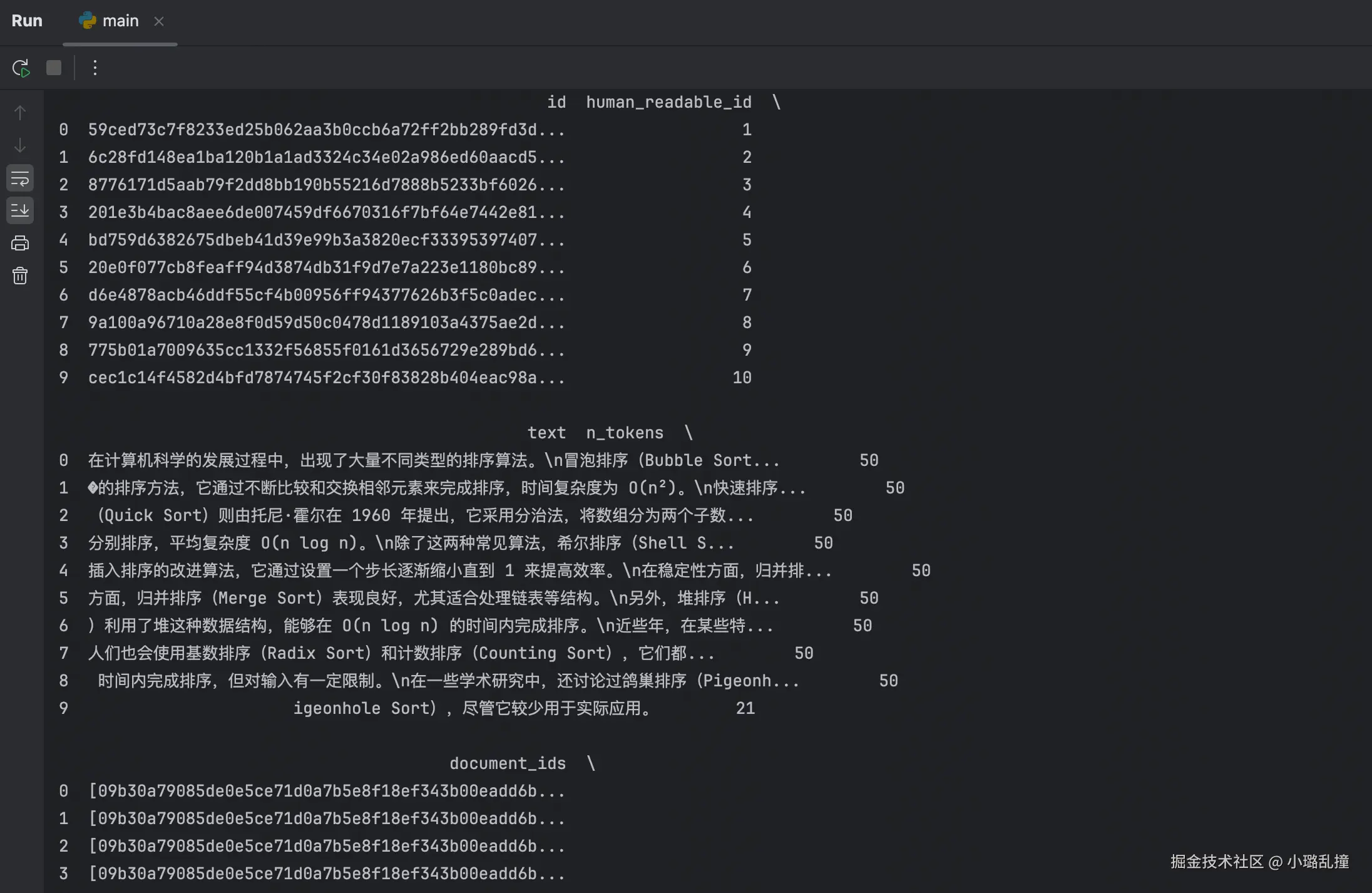
可以使用 pandas 库来解析 parquet 格式的文件内容:
python
import pandas as pd
pd.set_option('display.max_columns', None) # 显示所有列
df = pd.read_parquet('rag_demo/output/text_units.parquet')
print(df)在控制台中可以看到如下的表格数据:
3.3 检索
局部检索示例:
bash
graphrag query --root ./rag_demo --method local --query "文中一共提到了多少种排序算法?它们分别是什么"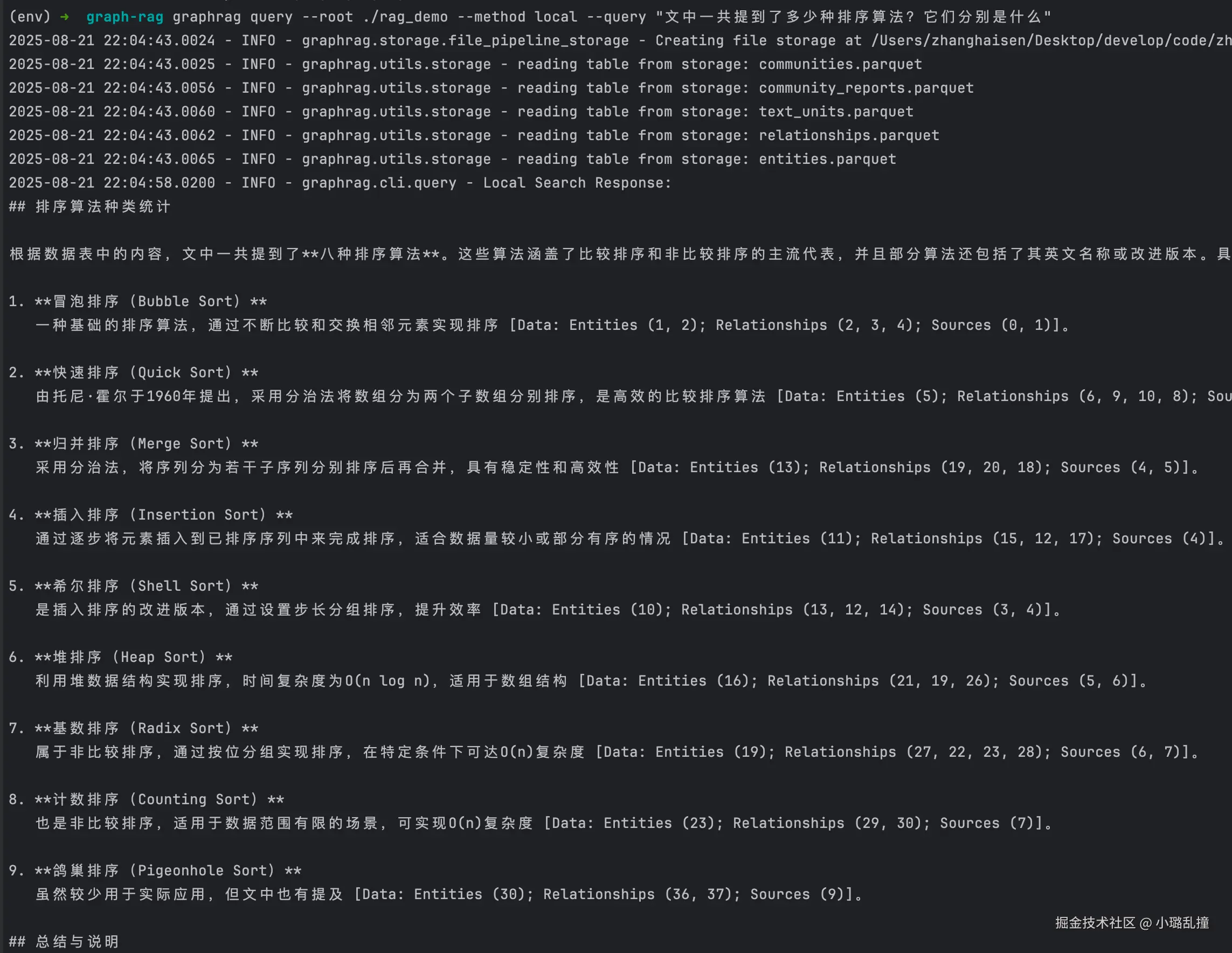
全局检索示例:
bash
graphrag query --root ./rag_demo --method global --query "文中一共提到了多少种排序算法?它们分别是什么"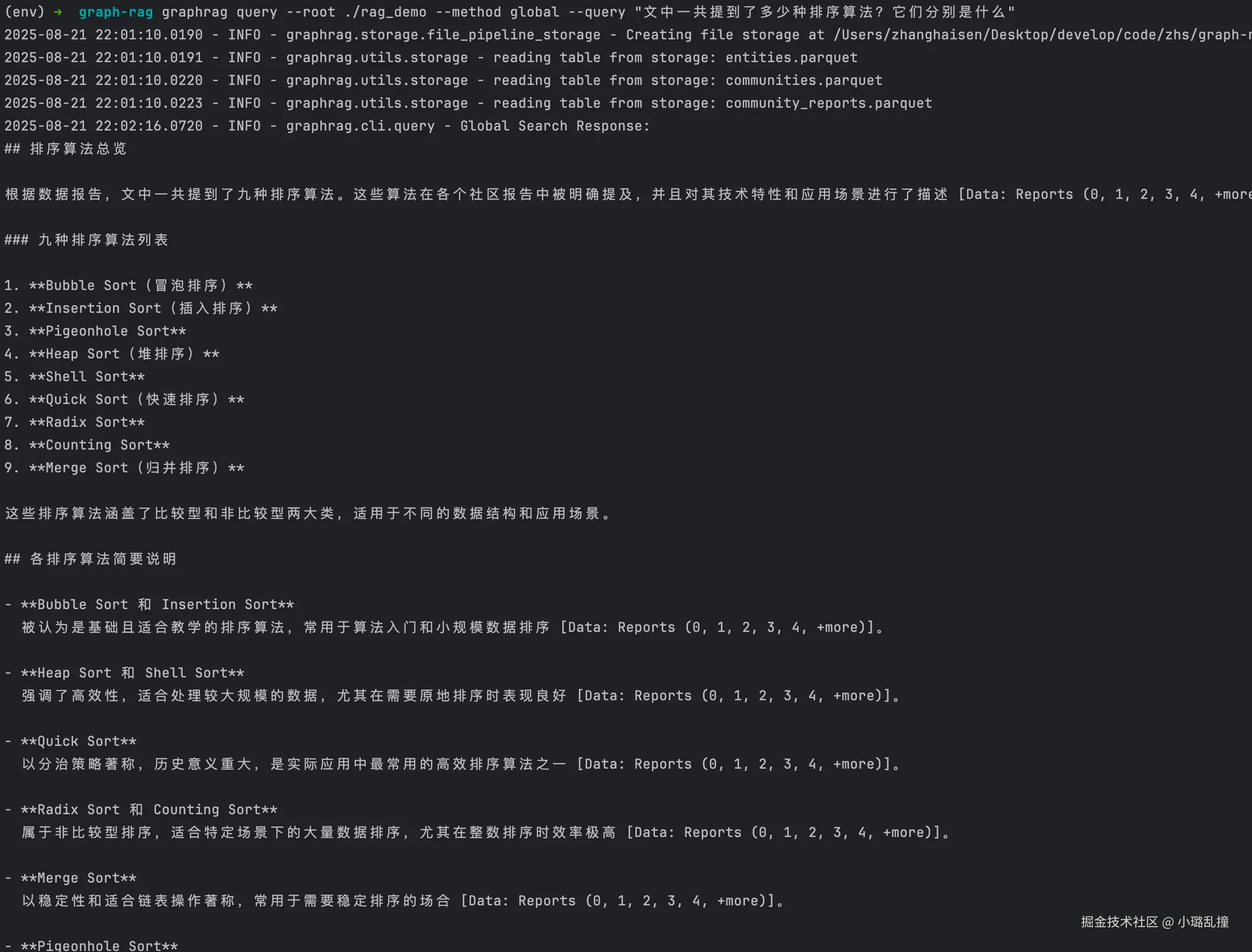
3.4 GraphRAG vs 传统 RAG
这里使用 Spring AI 构建传统 RAG,分块大小和相似度阈值分别设置为 50 和 0.8,对同样的数据集和问题进行测试,得到如下答案:
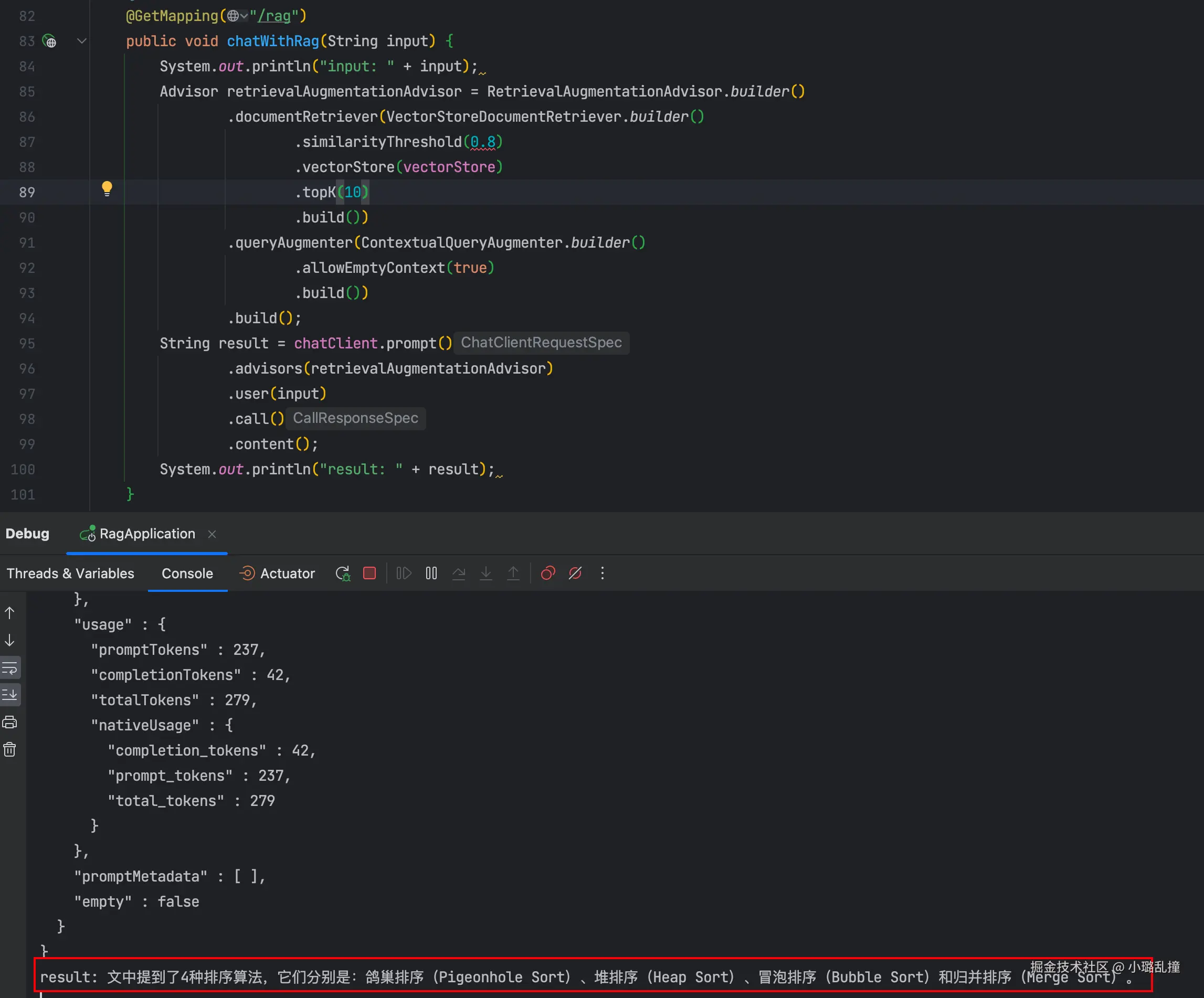
可以看到,回答的数量是缺失的,原因是这里没有检索出所有的文档片段,即存在一些相似度小于 0.8 的片段。这里给出所有片段及其对应的相似度(按相似度倒序排序),可以看到有 5 个片段相似度小于 0.8,这 5 个片段中包含了未检索出的五种排序算法。
| 序号 | 原始文本 | 相似度 |
|---|---|---|
| 1 | 在计算机科学的发展过程中,出现了大量不同类型的排序算法。 | 0.8741232454776764 |
| 2 | 在一些学术研究中,还讨论过鸽巢排序(Pigeonhole Sort),尽管它较少用于实际应用。 | 0.8343409448862076 |
| 3 | 另外,堆排序(Heap Sort)利用了堆这种数据结构,能够在 O(n log n) 的时间内完成排序。 | 0.8265917748212814 |
| 4 | 冒泡排序(Bubble Sort)是一种基础的排序方法,它通过不断比较和交换相邻元素来完成排序,时间复杂度为 O(n²)。 | 0.8247129768133163 |
| 5 | 1 来提高效率。\n在稳定性方面,归并排序(Merge Sort)表现良好,尤其适合处理链表等结构。 | 0.8229770809412003 |
| 6 | 除了这两种常见算法,希尔排序(Shell Sort)是一种基于插入排序的改进算法,它通过设置一个步长逐渐缩小直到 | 0.7995658218860626 |
| 7 | 近些年,在某些特定场景下,人们也会使用基数排序(Radix Sort)和计数排序(Counting Sort),它们都属于非比较排序,能在 | 0.7992490231990814 |
| 8 | 快速排序(Quick Sort)则由托尼·霍尔在 1960 年提出,它采用分治法,将数组分为两个子数组分别排序,平 | 0.799128457903862 |
| 9 | O(n) 时间内完成排序,但对输入有一定限制。 | 0.7923547178506851 |
| 10 | 均复杂度 O(n log n)。 | 0.7816332429647446 |
而从 3.3 节的检索看出,GraphRAG 是能回答正确这个问题的,原因就是他不仅仅只是检索相似度高的片段,还会检索与其关联的实体、关系等信息,进而能提供给大模型更完整的上下文。虽然对于这个示例来说,若将传统 RAG 中把相似度阈值设置为 0.7,大模型也能回答出正确的答案,但是其检索过程依然依赖于局部匹配,缺乏全局视角与关系推理的能力,毕竟我们不可能提前预知到相似度阈值设置为多少时,合适的文档才会被检索出来(这就类似于从答案推过程)。相比之下,GraphRAG 的优势在于即便在更复杂、跨片段甚至跨文档的场景下,也能够保持较高的回答准确性和稳定性。
四、GraphRAG 可视化
通过将 GraphRAG 索引阶段产生的 parquet 文件导入至图数据库 neo4j,可以实现 GraphRAG 可视化的效果,让我们看到 GraphRAG 构建的整个知识图谱样貌。
neo4j 是一个高性能的图数据库,专门用来存储、管理和查询图数据。它以"节点"和"关系"为核心概念,将实体和实体之间的连接关系进行建模,使得复杂的关联数据可以自然、直观地表示和高校操作。
首先需要在本机上安装 neo4j,mac 可以使用 brew 直接安装:brew install neo4,此外还需要安装 APOC 插件(参考Installation - APOC Core Documentation)。
然后导入 parquet 文件到 neo4j,而由于 neo4j 本身不支持直接导入这种格式的文件,因此我们可以先使用 python 的 pandas 库读取 parquet 文件,转换成 DataFrame 后再批量导入至 neo4j。具体做法如下:
bash
# neo4j sdk 安装
pip install neo4j
python
import pandas as pd
from neo4j import GraphDatabase
import time
# 将 DataFrame
def batched_import(statement, df, batch_size=1000):
total = len(df)
start_s = time.time()
for start in range(0,total, batch_size):
batch = df.iloc[start: min(start + batch_size,total)]
result = driver.execute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary.counters)
print(f'{total} rows in {time.time() - start_s} s.')
return total
# neo4j 环境配置
NEO4J_URI = "neo4j://localhost"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = "neo4j"
NEO4J_DATABASE = "neo4j"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
# parquet 文件存储目录
GRAPHRAG_FOLDER = "./rag_demo/output"
text_units = pd.read_parquet(GRAPHRAG_FOLDER + "/text_units.parquet")
entities = pd.read_parquet(GRAPHRAG_FOLDER + "/entities.parquet")
relationships = pd.read_parquet(GRAPHRAG_FOLDER + "/relationships.parquet")
communities = pd.read_parquet(GRAPHRAG_FOLDER + "/communities.parquet")
community_reports = pd.read_parquet(GRAPHRAG_FOLDER + "/community_reports.parquet")
# 导入 text_units
statement = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .n_tokens}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""
batched_import(statement, text_units)
# 导入 entities
entity_statement = """
MERGE (e:__Entity__ {id:value.id})
SET e += value {.human_readable_id, .description, name:replace(value.title,'"','')}
WITH e, value
CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield node
UNWIND value.text_unit_ids AS text_unit
MATCH (c:__Chunk__ {id:text_unit})
MERGE (c)-[:HAS_ENTITY]->(e)
"""
batched_import(entity_statement, entities)
# 导入 relationships
relationships_statement = """
MATCH (source:__Entity__ {name:replace(value.source,'"','')})
MATCH (target:__Entity__ {name:replace(value.target,'"','')})
// not necessary to merge on id as there is only one relationship per pair
MERGE (source)-[rel:RELATED {id: value.id}]->(target)
SET rel += value {.weight, .human_readable_id, .description, .text_unit_ids}
RETURN count(*) as createdRels
"""
batched_import(relationships_statement, relationships)
# 导入 communities
communities_statement = """
MERGE (c:__Community__ {id:value.id})
SET c += value {.level, .title, .community}
/*
UNWIND value.text_unit_ids as text_unit_id
MATCH (t:__Chunk__ {id:text_unit_id})
MERGE (c)-[:HAS_CHUNK]->(t)
WITH distinct c, value
*/
WITH *
UNWIND value.relationship_ids as rel_id
MATCH (start:__Entity__)-[:RELATED {id:rel_id}]->(end:__Entity__)
MERGE (start)-[:IN_COMMUNITY]->(c)
MERGE (end)-[:IN_COMMUNITY]->(c)
RETURN count(distinct c) as createdCommunities
"""
batched_import(communities_statement, communities)
# 导入 community_reports
community_reports_statement = """
MERGE (c:__Community__ {community:value.community})
SET c += value {.level, .title, .rank, .rank_explanation, .full_content, .summary}
WITH c, value
UNWIND range(0, size(value.findings)-1) AS finding_idx
WITH c, value, finding_idx, value.findings[finding_idx] as finding
MERGE (c)-[:HAS_FINDING]->(f:Finding {id:finding_idx})
SET f += finding
"""
batched_import(community_reports_statement, community_reports)导入完成后,可以进入 http://localhost:7474/ 查看,这里给出以下几个示例:
- 查询所有的节点和关系
css
MATCH (a)-[r]->(b)
RETURN a, r, b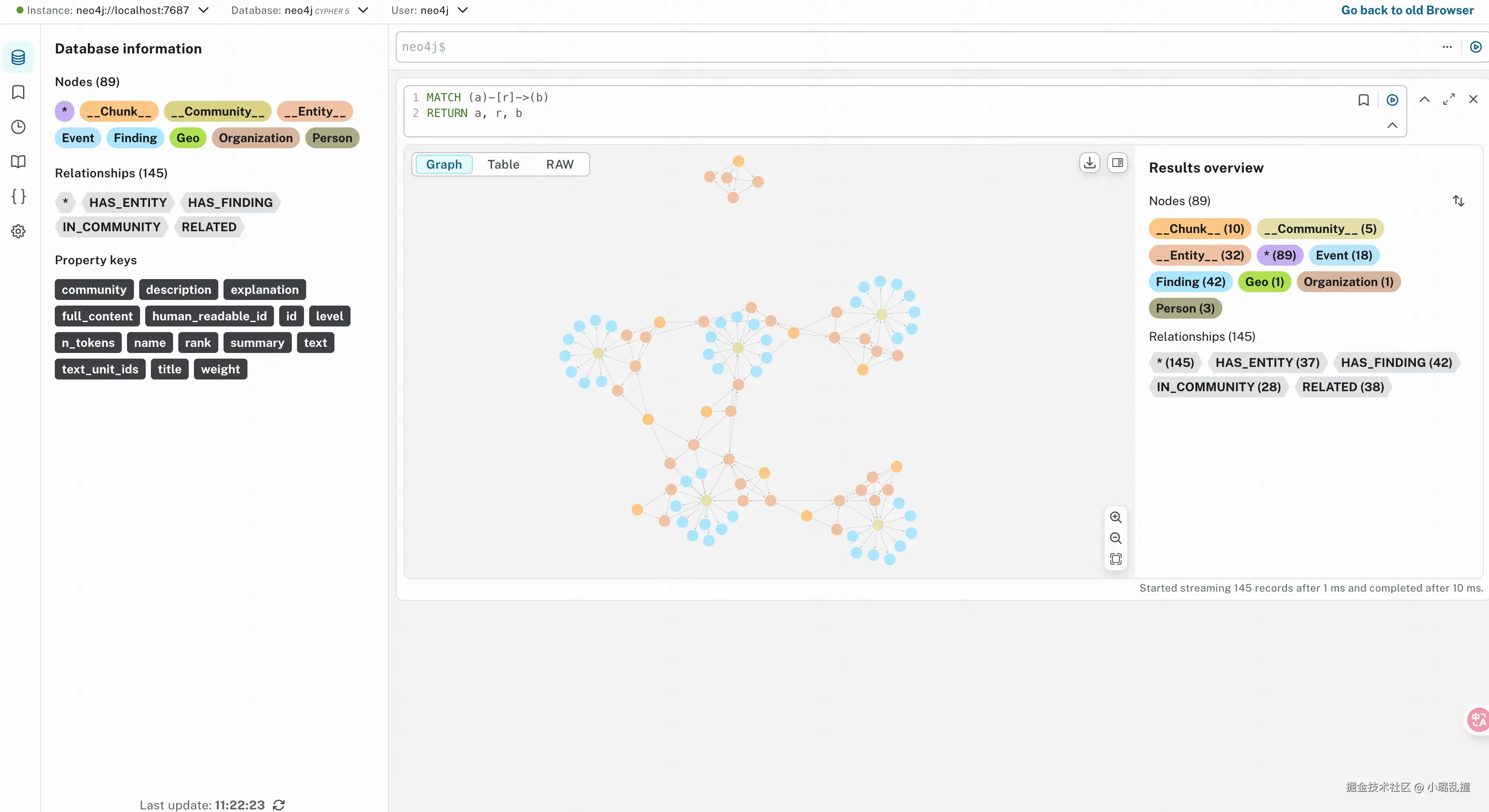
- 查询"冒泡排序"实体关联的所有实体
ini
MATCH (source:__Entity__)-[rel:RELATED]-(target:__Entity__)
WHERE source.name = "冒泡排序" OR target.name = "冒泡排序"
RETURN source, rel, target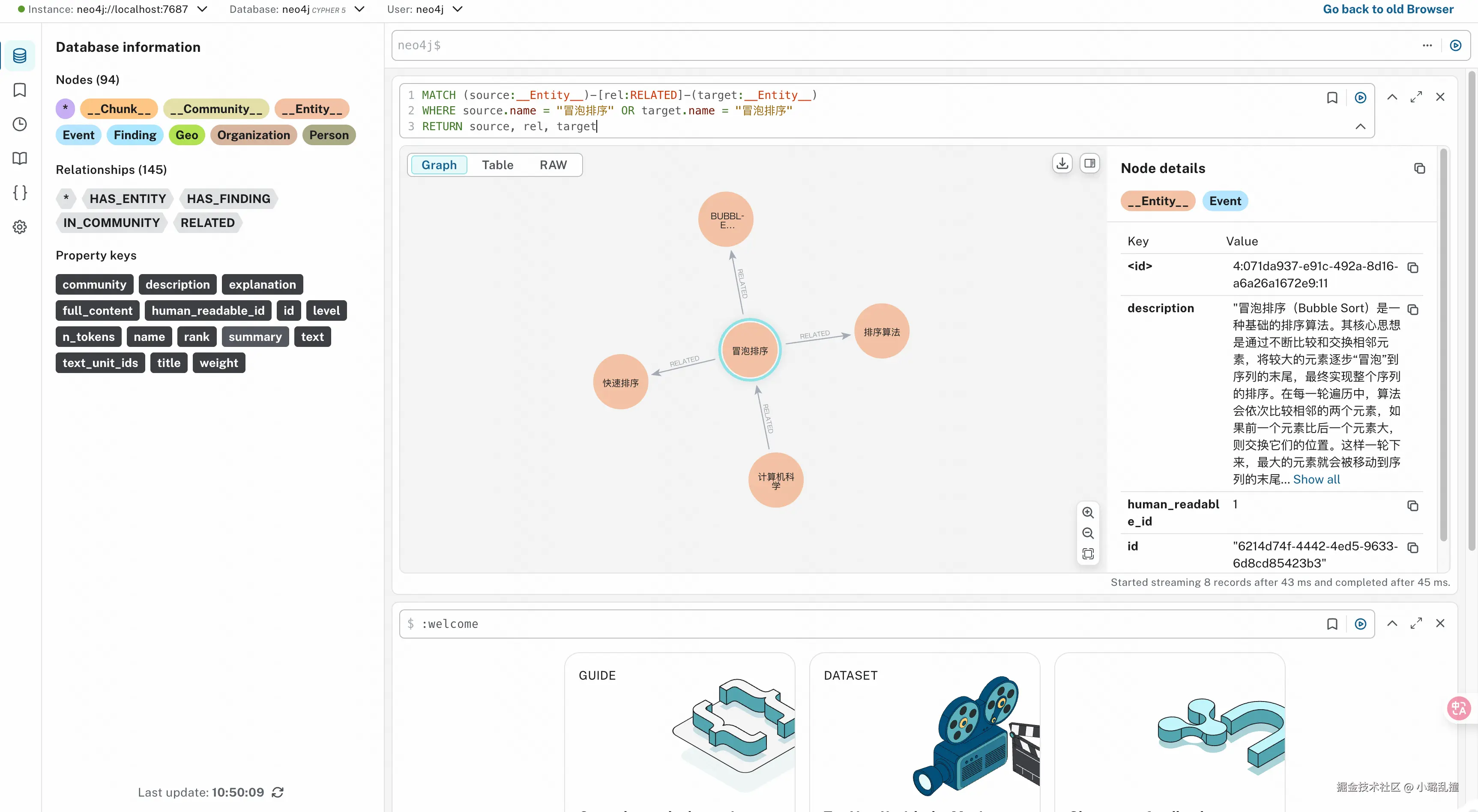
- 查询编号为 2 的社区中的所有实体
scss
MATCH (c:__Community__ {community:2})
MATCH (e:__Entity__)-[r:IN_COMMUNITY]->(c)
RETURN c, e, r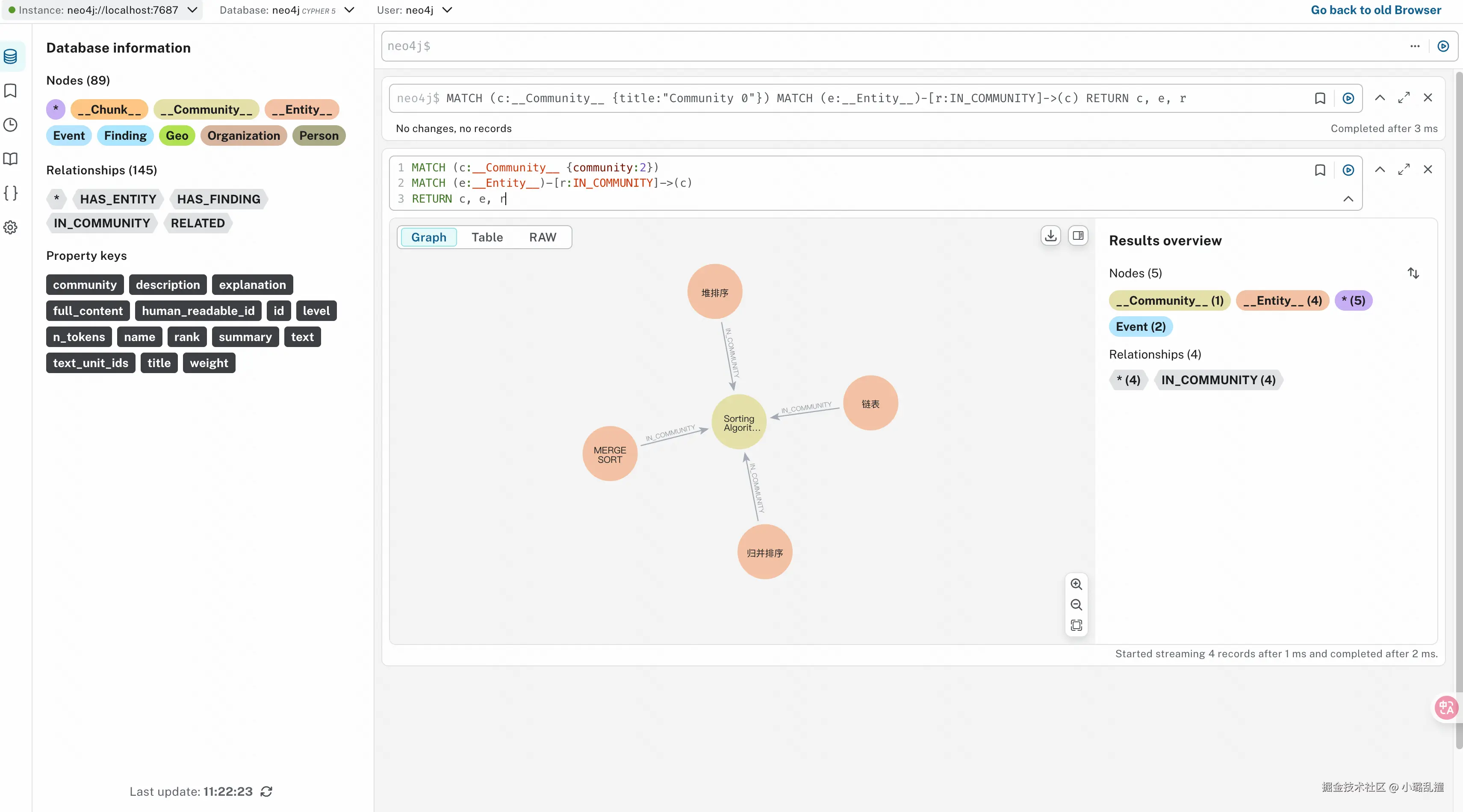
五、总结
从 GraphRAG 索引和检索的流程中不难看出,由于其构建了一个很完整的知识图谱,因此在检索时能够更精准地定位与问题相关联的上下文,从而提高生成结果的相关性和准确性。同时,知识图谱结构使得复杂关系和多跳推理成为可能,这在传统基于向量检索的 RAG 方法中往往难以实现。尤其在大规模知识库或跨领域信息整合场景下,GraphRAG 能有效降低信息遗漏的风险,并提升对复杂问题的回答能力,为实际应用提供了更可靠的支持。
然而,正因为知识图谱需要完整的实体与关系构建,这不可避免地带来了额外的成本与复杂性。大规模图谱的维护与更新会增加计算资源的消耗,同时随着图规模的增长,查询效率也可能受到影响。在微软 GraphRAG 中,知识图谱的生成完全依赖大模型完成,这意味着整个索引过程会消耗大量的 token,而图谱生成的质量高度依赖基座大模型本身的能力,若大模型本身的能力较差,最终生成的知识图谱质量也会较低。并且,若后续有新的内容加入,需要重新绘制整个知识图谱,这会进一步增加成本。
总的来说,尽管 GraphRAG 在构建与维护知识图谱上存在一定成本与复杂性,但随着后续大模型能力的不断提升、图谱自动化生成技术的优化,这些挑战最终有望得到有效缓解。未来,GraphRAG 有潜力在更大规模、更多领域的知识整合中展现出更强的适应性和可靠性,为智能问答、知识推理以及跨模态信息处理等应用提供坚实的技术基础。