目录
3.通过Xinference部署本地glm4-chat-1m
1.浏览器输入http://localhost:80启动Dify页面
前言
本文档在基于Windows10的本地电脑上部署使用Dify,其中必要用到的Xinference大模型管理框架,使用的大模型为GLM4-Chat-1m。
前置条件:确保已安装Anaconda、Python、Cuda。
一、安装必要项
1.安装Docker和AnaConda
Docker: Accelerated Container Application Development![]() https://www.docker.com/
https://www.docker.com/
下载 Anaconda Distribution |蟒蛇![]() https://www.anaconda.com/download
https://www.anaconda.com/download
2.安装Xinference
打开Anaconda命令行页面
输入命令:
- conda create --name xinference python==3.12
- conda activate xinference
- pip install xinferencetransformers
- pip install xinferencevllm,有问题,只装transformers也行
- xinference-local --host 本机IPV4地址 --prot 9997(ps:查询本机IP:cmd输入ipconfig)
浏览器输入本机IP:9997后如下图:
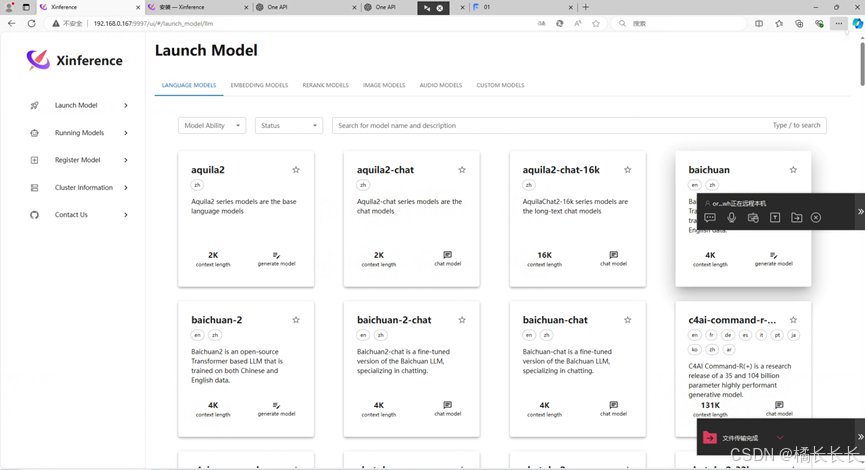
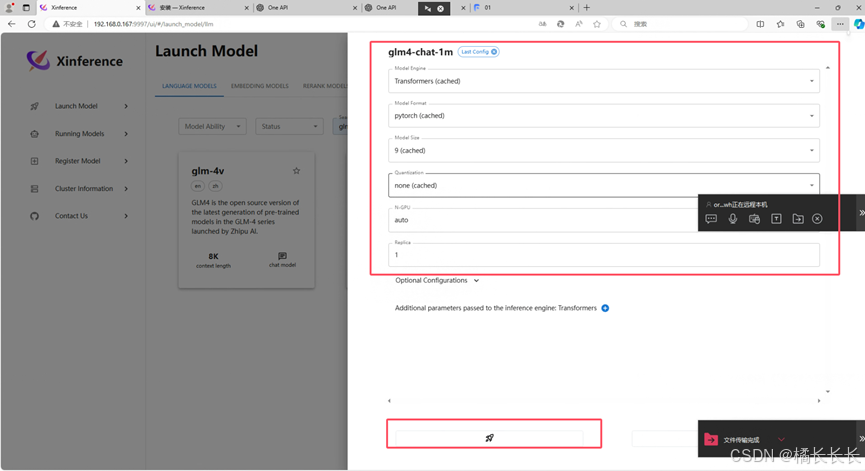
3.通过Xinference部署本地glm4-chat-1m
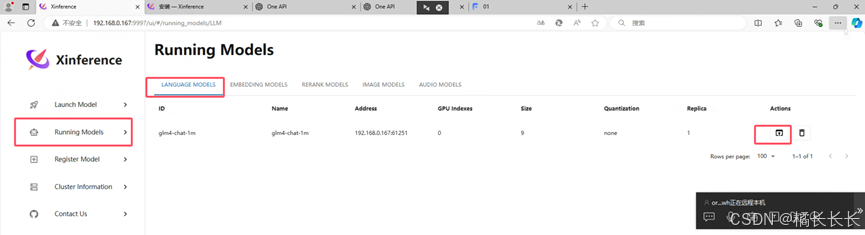
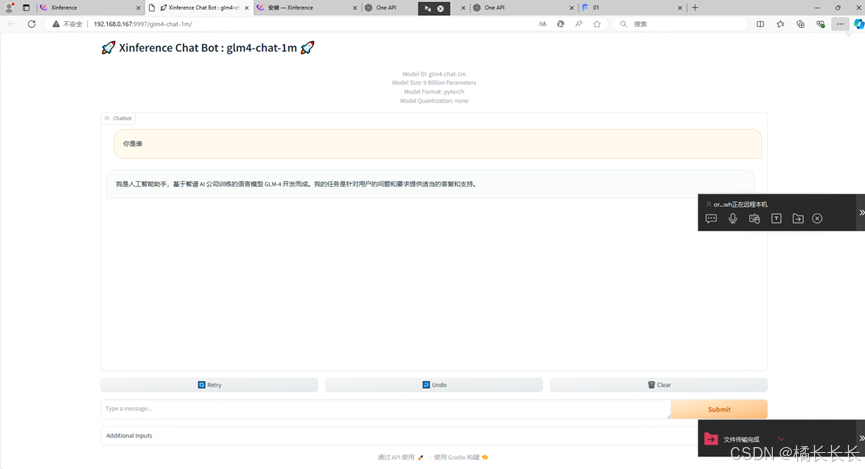
4.验证glm4-chat-1m是否部署完成
5.安装Dify
官网下载源码https://github.com/langgenius/dify,例如下载到D:\dify
打开cmd,执行以下代码
- cd D:\dify\docker
- docker compose up -d
Docker中查看是否部署成功,启动即可
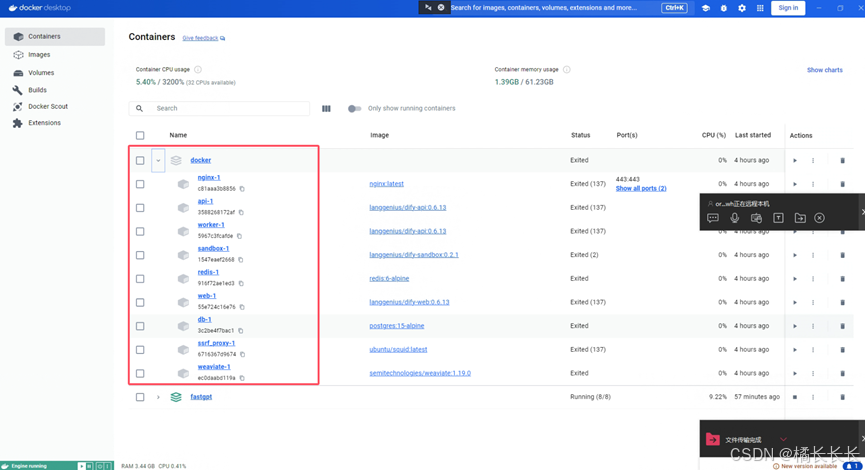
三、Dify中配置大模型
1.浏览器输入http://localhost:80启动Dify页面
2.随便注册账户登录
3.配置Xinference
前置条件:Xinference正常运行中
点击右上角头像---设置---模型供应商---XorbitsInference---添加模型
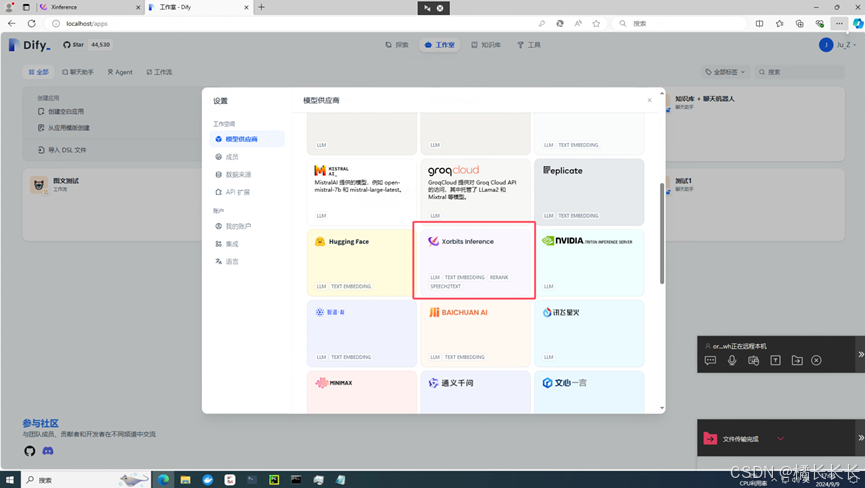
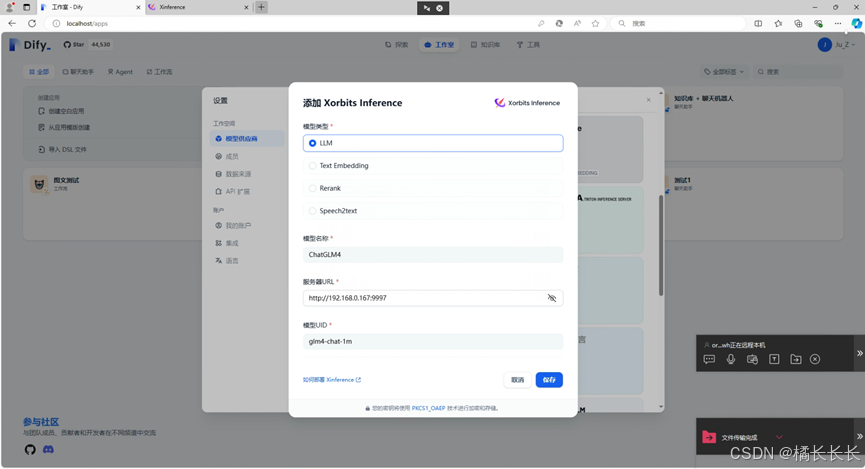
- 模型类型选择LLM
- 模型名称随便填,自己看的
- 服务器URL填写Xinference的IPV4地址+端口:http://192.168.0.167:9997
- 模型UID填写Xinference中的模型ID:glm4-chat-1m
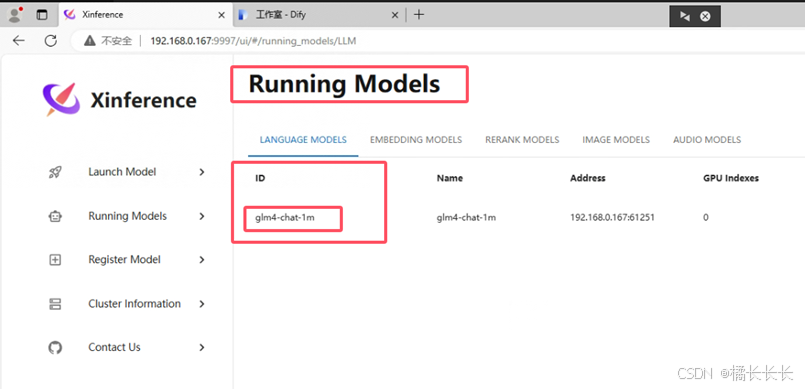
- 选择保存
四、运行Dify
1.设置系统推理模型
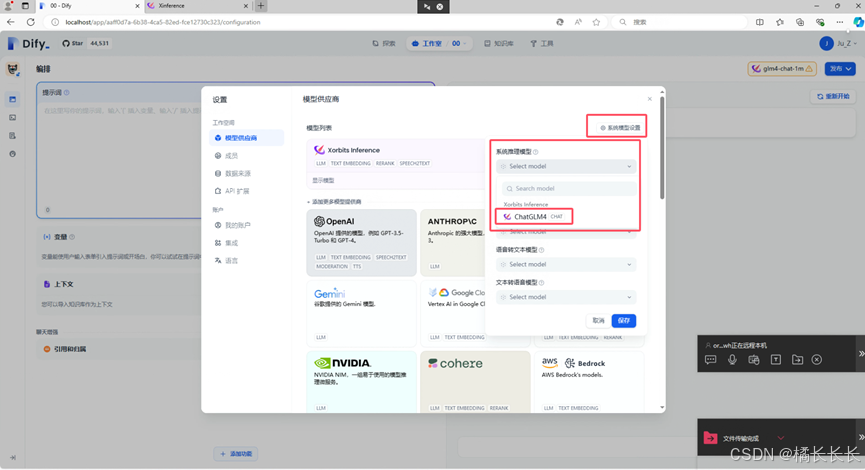
2.对话窗口验证
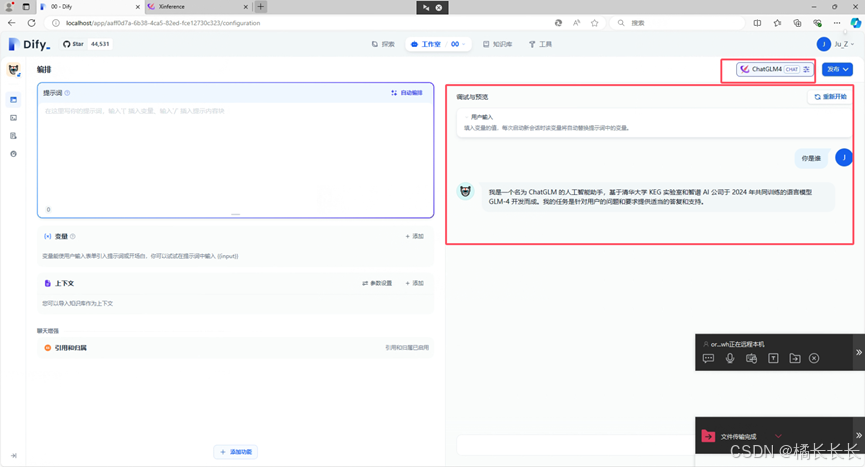
总结
以上就是在Windows 10环境下部署本地的Dify和Xinference,因为笔者是玩Unity出身,当前只是业余时间研究,有问题欢迎指正和探讨~