一、安装VMware
官方下载VMware: https://vmware.mdsoft.top/?bd_vid=5754305114651491003
二、下载镜像文件
阿里云镜像仓库: https://mirrors.aliyun.com/centos/
本文档使用 CentOS-7-x86_64-DVD-1810-7.6.iso 搭建虚拟机
三、搭建虚拟机
1、编辑网段
打开VMware,进入虚拟网络编辑器,按照如图所示修改下网段


2、新建虚拟机
创建虚拟机hadoop-1,期间可以增加一个用户, root用户名密码和添加的账号密码一致

3、克隆虚拟机
通过克隆虚拟机再创建2个克隆的时候选择完整克隆,其他都默认下一步即可

4、调整内存
克隆完成后,有三个相同配置的虚拟机,可以将hadoop-1节点的内存设置大一些, 本案例设置4G,另外两个节点设置2G,到这里三台机器就创建出来了

5、修改节点IP
修改三台节点为固定IP
powershell
# 修改主机名
hostnamectl set-hostname hadoop-1
# 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static" #协议改为static
#添加IP配置
#增加子网掩码
IPADDR="192.168.88.101"
NETMASK="255.255.255.0"
GATEWAY="192.168.88.2"
DNS1="192.168.88.2"
# 重启网卡
systemctl stop network
systemctl start network
或者
systemctl restart network
同样操作启动hadoop-2, hadoop-3,然后
修改hadoop-2主机名为 hadoop-2,设置IP为 192.168.88.102
修改hadoop-3主机名为 hadoop-3,设置IP为 192.168.88.103hadoop-1节点配置如下图所示

6、配置主机名映射
本地Windows电脑修改好hosts文件 (C:\Windows\System32\drivers路径下)
powershell
192.168.88.101 hadoop-1
192.168.88.102 hadoop-2
192.168.88.103 hadoop-3三台Linux机器修改hosts文件,每台节点都加下(etc/hosts), 使用SCP命令复制也可以
powershell
192.168.88.101 hadoop-1
192.168.88.102 hadoop-2
192.168.88.103 hadoop-37、配置SSH免密登录
①在每一台机器都执行下
powershell
ssh-keygen -t rsa -b 4096②在每一台机器都执行下
powershell
ssh-copy-id hadoop-1
ssh-copy-id hadoop-2
ssh-copy-id hadoop-3③执行完后即可实现免密互通
8、配置JDK环境

②上传JDK
powershell
分别登录3台服务器创建目录用于安装JDK
mkdir -p /export/server
上传文件到远程服务器/export/server目录下,可视化工具直接拖拽也可以上传
scp C:\Users\zhangheqiang\Downloads\jdk-8u421-linux-x64.tar.gz root@192.168.88.101:/export/server③解压JDK
powershell
进入/export/server 解压jdk文件
tar -xzvf jdk-8u421-linux-x64.tar.gz④配置环境变量
powershell
配置环境变量,编辑文件
vim /etc/profile
添加下面内容,保存退出
export JAVA_HOME=/export/server/jdk1.8.0_421/
export PATH=$JAVA_HOME/bin:$PATH
加载配置文件
source etc/profile
验证生效
java -version
javac -version⑤到这里配置好了hadoop-1的jdk环境, 同样的操作, hadoop-2和hadoop-3也配置以下
powershell
登录hadoop-1, 使用scp命令将已安装jdk的文件复制到要安装的服务器
scp -r /export/server/jdk1.8.0_421 root@192.168.88.102:/export/server
scp -r /export/server/jdk1.8.0_421 root@192.168.88.103:/export/server
JDK复制后, 两台机器都配置环境变量,编辑文件
vim etc/profile
添加下面内容,保存退出
export JAVA_HOME=/export/server/jdk1.8.0_421/
export PATH=$JAVA_HOME/bin:$PATH
加载配置文件
source etc/profile
验证生效
java -version
javac -version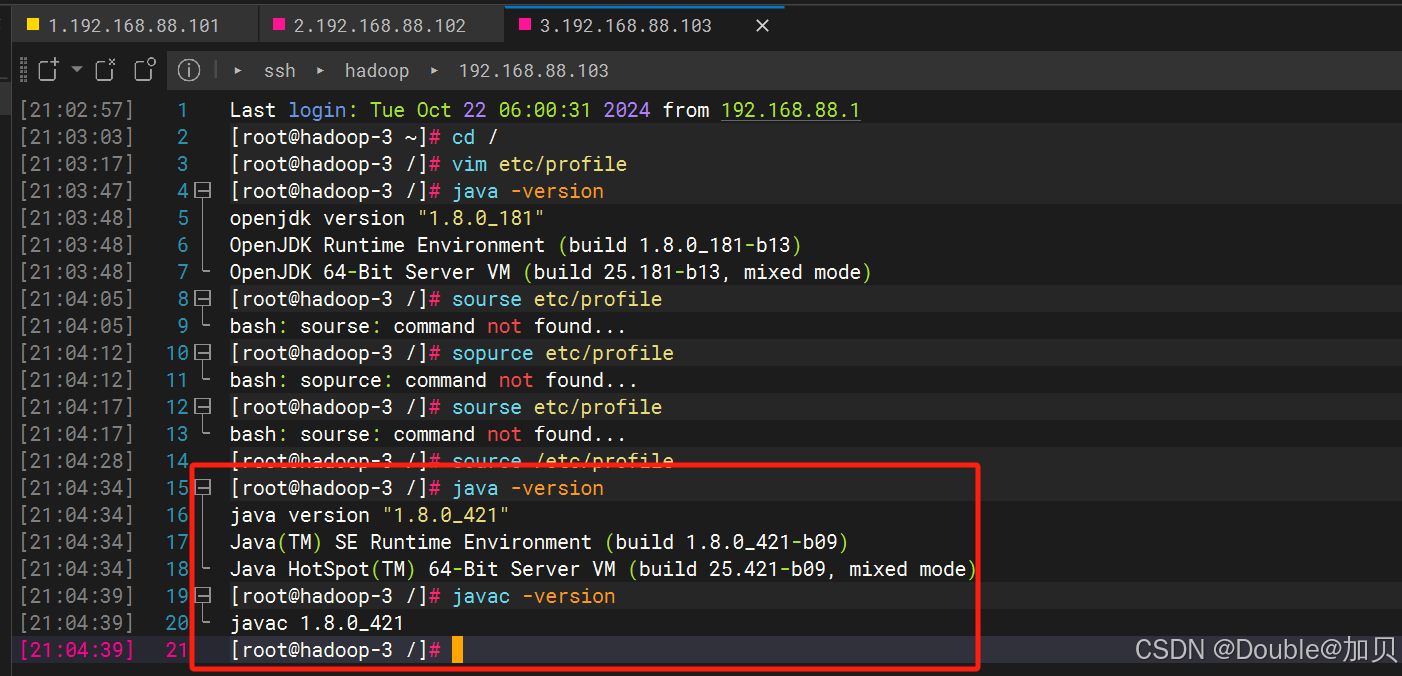
9、关闭防火墙
powershell
三台机器都执行下
systemctl stop firewalld
systemctl disable firewalld10、关闭SELinux
powershell
三台机器都执行下
vim /etc/sysconfig/selinux
将SELINUX=enforcing 改为
SELINUX=disabled
保存退出重启虚拟机
init 6 :重启
init 0 :关机11、修改时区配置自动同步时间
以下操作三台虚拟机都需要执行
powershell
安装ntp
yum install -y ntp
更新时区
rm -f /etc/localtime;sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
同步时间
ntpdate -u ntp.aliyun.com
开启ntp服务设置自动重启
systemctl start ntpd
systemctl enable ntpd或者
powershell
简单设置时区的命令
列出可用时区
timedatectl list-timezones
设置上海时区
sudo timedatectl set-timezone Asia/Shanghai
查看当前时区
timedatectl至此前期工作已经配置完成, 建议关机后, 给每台虚拟机打个快照