Ceph 集群有故障了,你执行的第一个运维命令是什么? 我猜测是ceph -s 。无论执行的第一个命令是什么,都肯定是先检查Mon。

在开始之前我们有必要介绍下Paxos协议,毕竟Mon就是靠它来实现数据唯一性。
一: Paxos 协议
1 Ceph 集群中的监视器(Monitors)是负责维护和分发集群状态的守护进程。多个Mon(通常是奇数个,如3个或5个)形成一个Mon集群,这些Mon通过 Paxos 协议来保持一致性。
Mon 一般都是2n+1 (n>=0) 因此Mon的个数一般是 1,3,5 。集群为了保证能正常选举,如果有 2n + 1 个监视器,那么集群可以容忍最多 n 个Mon的故障(Down)。
所以,对于一个由 2n + 1 个Mon组成的集群(例如 3 个监视器,n = 1),可以容忍 1 个Mon Down;对于 5 个Mon(n = 2),可以容忍 2 个Mon Down。以上规则适用于大多数的分布式集群。
Paxos节点与monitor节点绑定,每个mon启动一个Paxos ,Paxos为Mon提供服务。其中一个Paxos节点作为leader 其余的为peon 角色。Lerder 可以发起议案,peon 根据自己的本地历史选择接受或拒绝议案,并回复leader ,leder 提交超过半数Paxos节点接收的议案,这些Paxos节点被称为quorum (法定人数)。quorum 这个词接下来会被多次提到,因为Mon只有在quorum中才能进行正常选举和投票信息。
二: 集群状态检查
我们先复习下ceph的组件和其作用。
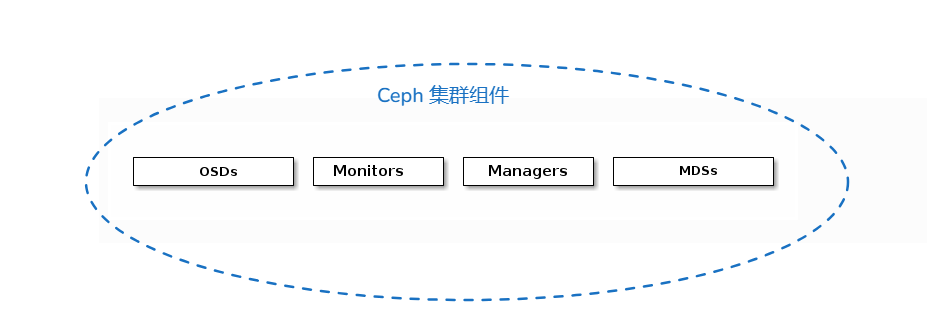
监视器(Monitors)简称Mon :Ceph 监视器(ceph-mon)维护集群状态的映射信息,包括监视器映射(Monitor Map)、管理器映射(Manager Map)、OSD 映射(OSD Map)、MDS 映射(MDS Map)和 CRUSH 映射(CRUSH Map)。这些映射是 Ceph 守护进程之间协调操作所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。
一句话总结:Mon 维护了集群5张地图(Mon Map ,Mgr Map, OSD Map MDS Map Crush Map )
所谓Map就是地图,以寻路为目标。而在Ceph中MAP 也是如此,通过Mon Map 知道集群中有哪些Mon,
管理器(Managers)简称Mgr :Ceph 管理器守护进程(ceph-mgr)负责跟踪 Ceph 集群的运行时指标和当前状态,包括存储使用情况、当前性能指标和系统负载。Ceph 管理器守护进程还托管基于 Python 的模块,用于管理和公开 Ceph 集群信息,包括基于 Web 的 Ceph Dashboard 和 REST API。通常,至少需要两个管理器以实现高可用性。
一句话总结:Mgr 复杂集群指标监控数据。
Ceph OSDs :对象存储守护进程(Ceph OSD,ceph-osd)存储数据(简称OSD),负责数据复制、恢复、重新平衡,并通过检查其他 Ceph OSD 守护进程的心跳来向 Ceph Mon和Mgr提供一些监控信息。通常,至少需要三个 Ceph OSD 以实现冗余和高可用性。
一句话总结: OSD 是真正存储数据的磁盘,可以是一个分区,也可以是磁盘。
元数据服务器(MDSs) :Ceph 元数据服务器(MDS,ceph-mds)存储 Ceph 文件系统的元数据。(简称MDS )Ceph 元数据服务器允许 CephFS 用户运行基本命令(如 ls、find 等),而不会给 Ceph 存储集群带来负担。
一句话总结:MDS 是维护文件存储中的元数据信息的(如果集群没有文件存储,则不需要MDS服务)。
每个服务都有其对应的守护进程:
mon :其结构为 ceph-mon@<mon name> 例子: ceph-mon@mon01.service
mgr: ceph-mgr@<mon name> 例子: ceph-mgr@mon01.service
osd: ceph-osd@<osd 编号> 例子: ceph-osd@0.service 因为可以使用systemd 命令来对对应服务进程重启和启动
systemctl restart ceph-mon@mon0
systemctl restart ceph-mgr@mon0
systemctl restart ceph-osd@0
systemctl restart ceph-osd@1
systemctl restart ceph-osd@2集群维护:
如果 ceph -s 命令没有返回,或一直在运行中没有结束也没有返回怎么办 ?

接下来几步将会帮你解决生产过程中90% Mon 问题。
1. 检查所有的节点服务,确保服务是正常running 状态
systemctl -t service |grep ceph
# -t 指定类型 service 搜索ceph 服务2. 检查集群网络:
#1 检查ceph的配置文件路径找到对应的默认为/etc/ceph/ceph.conf
public_network=xxx.xxx #对应ceph的外部网络
cluster_network=xxx.xxx #对应ceph的内部网络
#2 检查所有mon 节点的外部网络和内部网络的 3300和6789端口是否正常可达
nc 192.168.1.100 3300
nc 192.168.1.100 6789
#3 检查集群网络是否有丢包 延迟过高问题
ping 192.168.1.2 -i 0.01 -s 2000 -c 1000
参数说明
-i 指定了ping的间隔 默认为1s一次,此时指定了间隔为0.01 秒
-s 指定了包的大小2000 #默认不指定为1500,在实际环境中经常发现小包不丢包,
大包丢包的现象,因此建议ping 大于1500的包。
-c 指定了ping包的个数3. 检查集群状态 :
请在确保上面两步检查已经完成的情况下进行第三步,以上两步看上去很简单,但是却能解决生产环境大部分问题。
#1 ceph status 命令简称 ceph -s
#当ceph -s 命令能正常返回结果时,则表示集群正在运行。
只有在形成法定数量(quorum)的情况下,监视器才会响应状态请求,也就是说如果是3个mon节点情况
#至少2个mon 节点是正常才能返回结果。
如果ceph -s 没有返回结果,此时在确保前面简称服务正常和集群网络正常的情况下可以使用 -m 来指定mon 来查看集群状态。
正常如果不指定-m参数,客户端的请求是随机选择mon进行发送请求的。
ceph -s -m mon01以上都是ceph -s 能返回正常状态,若是mon 没有形成quorum 则不会返回输出,此时我们就需要使用 ceph tell mon.ID mon_status
ceph tell mon.0 mon_status -f json-pretty
参数说明:
-f 指定json格式来输出
注意此时mon.0 此时0 是mon等级,
ceph tell mon.0 mon_status
ceph tell mon.1 mon_status
ceph tell mon.2 mon_status
ceph tell mon.c mon_status #
{ "name": "c",
"rank": 2,
"state": "peon",
"election_epoch": 38,
"quorum": [
1,
2],
"outside_quorum": [],
"extra_probe_peers": [],
"sync_provider": [],
"monmap": { "epoch": 3,
"fsid": "5c4e9d53-e2e1-478a-8061-f543f8be4cf8",
"modified": "2013-10-30 04:12:01.945629",
"created": "2013-10-29 14:14:41.914786",
"mons": [
{ "rank": 0,
"name": "a",
"addr": "127.0.0.1:6789\/0"},
{ "rank": 1,
"name": "b",
"addr": "127.0.0.1:6790\/0"},
{ "rank": 2,
"name": "c",
"addr": "127.0.0.1:6795\/0"}]}}从上面信息可以知道 其结果是mon.c 返回的结果,其name 是 c ,quorum列表中只有【1,2】缺少等级为0 的mon ,而在 monmap 中 mons 为一个列表其中 等级为0 的name 是 a 。
因此我们可以知道mon.a 节点 mon 有问题。 由上面信息我们可以了解如下信息
-
monmap 是mon 的集群状态视图,存储是所有mon集合 。
-
quorum 是当前形成选举的mon 的节点的集合
问题1 mon 等级 编号 0,1,2 是如何确定的?
当加入或删除 monitor 时,会(重新)计算等级。计算时遵循一个简单的规则: IP:PORT 的组合值越大 , 等级越低 (等级越低,编号越大)。因此在上例中, 127.0.0.1:6789 比其他 IP:PORT 的组合值都小,
所以 mon.a 的等级是 0 。 (也许上面这句不好理解,因为上述都是来自官方文档解释) 用中国人思维方式就可以理解为 IP+端口的组合最小的是编号0,次小的为编号1 ,依次类推,编号越小等级越高。
例子 :
mon.a 10.101.24.11:6789
mon.b 10.101.24.13:6789
mon.c 10.101.24.13:6789
IP地址最后1位进行比较得知 mon.a 数字最小,编号是0 ,mon.b 次之,编号是1 mon.c 编号为2 在没有形成quorum 时,除了指定mon 使用 ceph tell mon.x mon_status 方式外 还可以使用管理套接字的方式。
管理套接字:
-
查看管理套接字路径
1.1 使用ceph-conf 工具
ceph-conf --name mon.0 --show-config-value admin_socket /var/run/ceph/ceph-mon.0.asok1.2 查看
/etc/ceph/ceph.conf的配置文件1.3 默认路径
/var/run/ceph/ceph-mon.mon01.asok -
使用管理套接字查询
1 查看mon 状态
ceph --admin-daemon /var/run/ceph/ceph-mon.mon01.asok mon_status
#2 查看quorum
ceph --admin-daemon /var/run/ceph/ceph-mon.mon01.asok quorum_status
问题2: Mon有quorum返回,但是至少有一个Mon Down ?
ceph health detail 是ceph 运维过程中最常用的命令,可以快速定位ceph的Warning 和Error 错误原因
ceph health detail
[snip]
mon.a (rank 0) addr 127.0.0.1:6789/0 is down (out of quorum)二: MON 5种状态
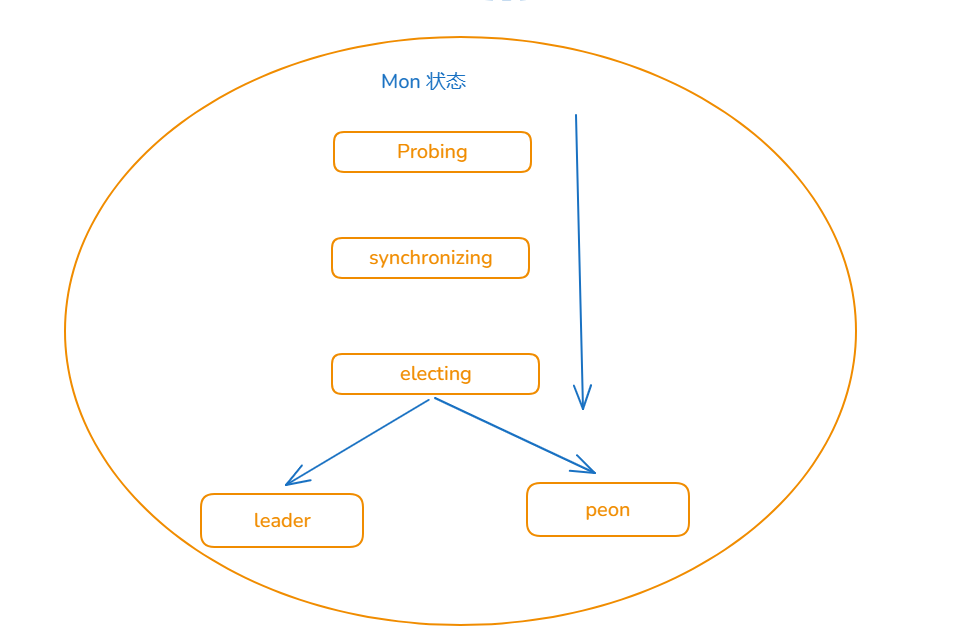
正常状态 :leader peon
其他状态 :probing electing synchronizing 也称为中间状态;
如果mon 处于quorum 列表中,那mon 状态一定是 lead 或 peon , 如果处于其他状态 则不会认为自身处于quorum中。
ceph tell mon.0 mon_status -f json-pretty |grep state生产环境截图如下

从图片中可以看到一个三节点Mon集群,一个节点状态为leader 两个节点状态 peon
probing状态 :
如果 ceph health detail 显示某个监视器的状态是 probing,那么该Mon仍在寻找其他Mon。每个Mon启动时都会在这个状态停留一段时间。
当一个Mon连接到 monmap 中指定的其他Mon后,它就会退出 probing 状态。Mon处于 probing 状态的时间长短取决于其所属集群的参数。
例如,当一个Mon属于单Mon集群时(生产环境中绝对不要这样做),它几乎会瞬间通过 probing 状态。在多Mon集群中,Mon会一直处于 probing 状态,直到找到足够的Mon形成法定数量(quorum)。
这意味着如果集群中的三个Mon有两个宕机,那么剩下的一个Mon将无限期地停留在 probing 状态,直到您启动另一个Mon为止。
如果已经建立了法定数量(quorum),那么Mon守护进程应该能够快速找到其他Mon,只要它们可以被访问。如果一个Mon卡在 probing 状态,并且已经按照上面描述的步骤排查了Mon之间的通信问题,那么可能是问题MonIP 地址或端口错误。
mon_status 会输出该监视器已知的 monmap:确定 monmap 中指定的其他MonIP是否正确。如果IP地址正确,请检查时间偏差。
一句话总结: probing状态是中间状态,Mon启动后会通过monmap 寻找其他Mon来形成quorum ,如果无法达到quorum则会卡在 probing 状态。
问题2: 怎么判断monmap IP 地址是否正确,如何查看呢?

#假如 mon卡在probing 状态,则通过 mon_status 可以查看到monmap 对应的mon IP地址信息,确保该IP地址是正确
epoch 3
fsid 5c4e9d53-e2e1-478a-8061-f543f8be4cf8
last_changed 2013-10-30 04:12:01.945629
created 2013-10-29 14:14:41.914786
0: 127.0.0.1:6789/0 mon.a
1: 127.0.0.1:6790/0 mon.b
2: 127.0.0.1:6795/0 mon.c如果一个Mon Down机时间过长,集群Mon发生了变化,导致Down机节点monmap 无法使用;此时可以选择一个集群节点monmap 来注入损坏的节点。
1 如果集群有法定的quorum 则可以选择在quorum节点的monmap
#1 导出monmap
ceph mon getmap -o /tmp/monmap
#2 查看monmap
monmaptool --print /tmp/monmap
monmaptool: monmap file /tmp/monmap
epoch 2
fsid 0bc5409d-5019-482c-a853-537d27c2114d
last_changed 2024-07-24 07:24:53.707979
created 2024-07-24 07:16:00.549039
min_mon_release 14 (nautilus)
0: [v2:192.168.1.100:3300/0,v1:192.168.1.100:6789/0] mon.mon01
#3 停止损坏节点的mon
systemctl stop ceph-mon@xxxx.service #xxxx 代表mon名字
#4 注入monmap
ceph-mon -i ID --inject-monmap /tmp/monmap
没有形成法定人数?直接从其他 monitor 节点上抓取 monmap
(这里假定你抓取 monmap 的 monitor 的 id 是 ID-FOO 并且守护进程已经停止运行):
ceph-mon -i ID-FOO --extract-monmap /tmp/monmap
将上述命令替换#1 的命令既可以,其他步骤都都一样。electing 状态
如果 ceph health detail 显示MoN的状态是 electing,这表示Mon正在进行选举。选举通常会很快完成,但有时监视器可能会陷入所谓的"选举风暴"。此时通常是时间偏差造成的,请检查时间偏差。
问题3:时间偏差怎么确定 ?
-
查看ceph日志一般会出现如下消息
mon.a (rank 0) addr 127.0.0.1:6789/0 is down (out of quorum)
mon.a addr 127.0.0.1:6789/0 clock skew 0.08235s > max 0.05s (latency 0.0045s)2015-06-04 07:28:32.035795 7f806062e700 0 log [WRN] : mon.a 127.0.0.1:6789/0 clock skew 0.14s > max 0.05s
2015-06-04 04:31:25.773235 7f4997663700 0 log [WRN] : message from mon.1 was stamped 0.186257s in the future, clocks not synchronized
synchronizing 状态
这意味着该 monitor 正在和集群中的其他 monitor 进行同步以便加入法定人数。Monitor 的数据库越小,同步过程的耗时就越短。然而,如果你注意到 monitor 的状态从 synchronizing 变为 electing 后又变回 synchronizing ,那么就有问题了:集群的状态更新的太快(即产生新的 maps ),同步过程已经无法追赶上了。这种情况说明你的Ceph Mon版本太旧了,可能需要更新新的版本来解决。
最后我们总结下Mon 的常用操作命令
#1 查看mon 状态
ceph mon stat
#使用管理套接字来查看
ceph --admin-daemon /var/run/ceph/ceph-mon.mon01.asok mon_status
ceph tell mon.0 mon_status -f json-pretty |grep state
#2 查看mon 选举状态
ceph quorum_status
#3 查看mon 映射信息
ceph mon dump
#4 查看集群状态
ceph -s
ceph health detail
ceph -s -m mon01
#5 获取monmap
ceph mon getmap -o /tmp/monmap
#6 查看monmap
monmaptool --print /tmp/monmap注:(以上所有的维护操作指导都来源官方文档加上个人注释,学习任何技术,官方文档永远是最权威的指导手册。)
写在最后:
谈到分布式存储,ceph是很多互联网公司第一选择,因此我们在接下来多个章节将一一介绍ceph的各个组件运维技巧与心得。欢迎大家与我一起学习一起成长。
