系列文章目录
运维监控平台搭建
运维监控平台监控标签
golang_Consul代码实现Prometheus监控目标的注册以及动态发现与配置V1版本
Prometheus运维监控平台之监控指标注册到consul脚本开发、自定义监控项采集配置调试(三)
golang开发alertmanagerWebhook,实现prometheus+alertmanagerWebhook告警
golang实现mysql实例存活检查及全量备份是否完成检查工具开发
文章目录
前言
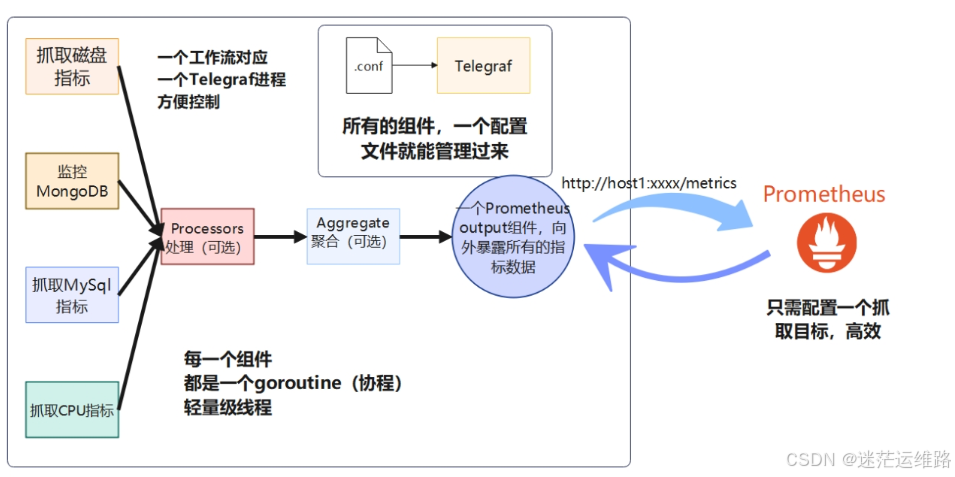
为什么需要配置自定义监控?当采用telegraf作为agent采集监控信息时,虽然telegraf的inputs插件提供了不少封装好的监控配置文件,但是在生产环境下,直接使用telegraf提供好的配置文件来监控相应的指标总是不全面的。例如:自己编写了一个azkaban组件监控脚本,实现对其中的任务状态及任务数进行监控,那么这时候telegraf提供的开源inputs插件就实现不了这个监控过程,那么怎么办?因此本篇文章主要针对telegraf的自定义监控实现方式进行展示
一、telegraf引入
telegraf的安装可参考顶部文章<运维监控平台搭建>,这篇文章中有搭建过程,在本篇中不做过多描述
1、定义
yaml
Telegraf 是一个用Go语言编写的插件驱动的开源软件代理,用于收集和发送来自数据库、系统的所有包括不限于指标、事件等数据.
拥有了多达 200 余种采集插件以及 40 余种导出插件,几乎覆盖了所有的监控项,例如机器监控、服务监控甚至是硬件监控
同时Telegraf 提供了4种基本的插件类型,常用的是输入插件input:
输入插件(Input)用于从各种来源(系统、服务、第三方API等)收集数据,
处理插件(Process)在发送之前转换、清洗、过滤数据,
聚合插件(Aggregate)使用聚合计算获得聚合值例如平均值,最小值和最大值等,从你已经收集和处理的度量。
输出插件(Output)可以将数据发送到数据存储、服务和消息队列,如InfluxDB、Graphite、OpenTSDB、Datadog、Kafka、MQTT、NSQ等。2、telegraf配置解析
定义telegraf全局配置文件如下所示
shell
[root@python2 telegraf.d]# vim ../telegraf.conf
[global_tags]
[agent]
interval = "60s"
round_interval = true
metric_batch_size = 30000
metric_buffer_limit = 100000
collection_jitter = "5s"
flush_interval = "60s"
flush_jitter = "5s"
precision = ""
hostname = ""
omit_hostname = false
[[outputs.prometheus_client]]
listen = ":9273"
[[inputs.cpu]]
percpu = true
totalcpu = true
collect_cpu_time = false
report_active = false
[[inputs.disk]]
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
[[inputs.diskio]]
[[inputs.kernel]]
[[inputs.mem]]
[[inputs.processes]]
[[inputs.swap]]
[[inputs.system]]
[[inputs.netstat]]
interval = "1m"
fielddrop = ["tcp_none","tcp_closing","tcp_close*"]
[[inputs.net]]
interval = "60s"
fieldpass = ["packets_*","bytes_*","drop_*","err_*"]
yaml
配置文件涉及到3个主要配置块
[ agent ]
这里面是一些涉及全局的配置。此处我们设置interval="60s",
意思是让配置文件中的所有input插件每隔60秒去采集一次指标。interval的默认值是10秒。
[[ inputs.cpu ]]
这是一个input输入组件,这里的配置是说我们导出的指标会包含每一个CPU核的使用情况,
而且还包含所有CPU总的使用情况。
[[ outputs.prometheus_client ]]
这是一个output输出组件,这里我们用了一个名为prometheus_client 的输出组件,
且prometheus_client 参数设为了:9273,这样程序运行起来我们通过http://ip:9273/metrics查看到对应的信息,
如上图所示。运行telegraf
shell
[root@python2 telegraf.d]# ../../../usr/bin/telegraf --config ../telegraf.conf --test
观察运行信息得知:
加载了多个输入插件、0个处理插件、0个聚合插件、0个输出插件(test模式不加载输出插件)
从下图可以看到输入插件的数据都是未聚合和处理的原始数据

在上述Telegraf的配置内容输出完毕后,可以看到一堆密密麻麻的数据。会发现它不像json,也不像csv格式。这其实是Telegraf内置的数据结构,叫做InfluxDB行协议。接下来专门讲解这种数据结构
二、Telegraf内部数据结构(InfluxDB行协议)
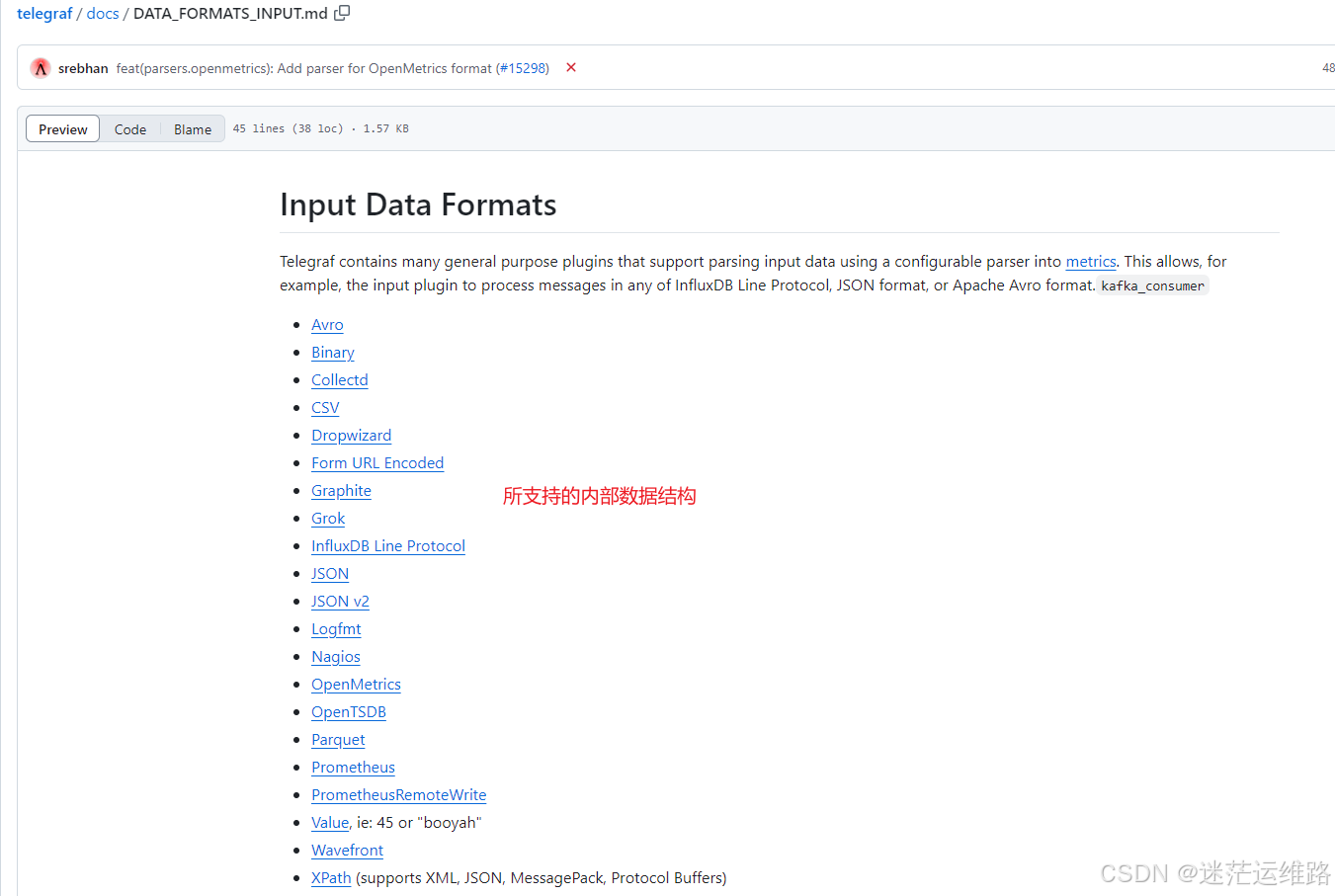
1.支持的内部数据结构类型
如下(示例):从官方文档中获取到的所支持的数据结构类型
2.使用示例
任何包含该选项的输入插件都可以使用它来选择 所需的解析器:data_format

yaml
[[inputs.exec]]
## Commands array
commands = ["/tmp/test.sh", "/usr/bin/mycollector --foo=bar"]
## measurement name suffix (for separating different commands)
name_suffix = "_mycollector"
## Data format to consume.
data_format = "json"指定的返回格式

yaml
echo 'example,tag1=a,tag2=b i=42i,j=43i,k=44i'
i 明确指示该字段的类型为整数解释一下这个返回格式的构成部分
yaml
接下来介绍一下上述几个构成部分。
example(测量名称)
目前,你可以将它理解为存放数据的容器。这个名称自定义即可
必需
测量的名称。每个数据点都必须声明自己是哪个测量里面的 ,不可省略。
大小写敏感
不可以下划线 _ 开头
Tag(标签集)
标签应该用在一些值的范围有限的,不太会变动的属性上。
比如传感器的类型和id等等。在InfluxDB中一个Tag相当于一个索引。
给数据点加上Tag有利于将来对数据进行检索。但是如果索引太多了,就会减慢数据的插入速度。
可选
键值关系使用 = 表示
多个键值对之间使用英文逗号 , 分隔
标签的键和值都区分大小写
标签的键不能以下划线 _ 开头
键的数据类型:字符串
值的数据类型:字符串
Field (字段集)
必需
一个数据点上所有的字段键值对,键是字段名,值是数据点的值。
一个数据点至少要有一个字段。
字段集的键是大小写敏感的。
字段
键的数据类型:字符串
值的数据类型:浮点数 | 整数 | 无符号整数 | 字符串 | 布尔值
Timestamp(时间戳)
可选。若不指定,则默认使用当前时间。
数据点的Unix时间戳,每个数据点都可以指定自己的时间戳。
如果时间戳没有指定。那么InfluxDB就使用当前系统的时间戳。
数据类型:Unix timestamp
如果你的数据里的时间戳不是以纳秒为单位的,那么需要在数据写入时指定时间戳的精度。
空格
行协议中的空格决定了InfluxDB如何解释数据点。第一个未转义的空格将测量值&Tag Set (标签集)与 Field Set(字段集) 分开。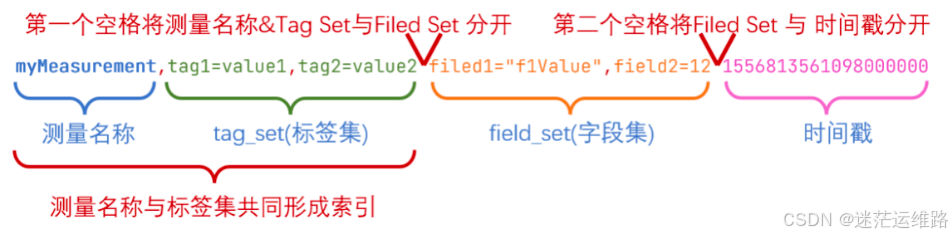
3.InfluxDB行协议
yaml
Telegraf的内部数据结构叫做InfluxDB行协议。Telegraf本身是InfluxData公司专门为InfluxDB开发的数据采集器。
上面这种数据格式是InfluxDB数据库使用的,只要数据符合上面这种格式,
就能通过InfluxDB的API将数据导入数据库。所以,自家的插件当然支持自家的生态了InfluxDB三、自定义监控示例
需求一:监控某台主机的系统内核参数是否是指定的阈值,如果不是则通过配置的告警规则文件进行告警通知
shell
1、在192.168.56.131机器的/opt/monitor/telegraf/scripts/目录下,增加一个探测的脚本文件test.sh,并授权执行权限。脚本内容如下
[root@python2 telegraf.d]# cat ../../../scripts/test.sh
#!/bin/bash
value=$(sysctl fs.file-max| awk '{print $3}')
echo "FS_fileMax,host=192.168.56.131 status=${value}i" #其中FS_fileMax为监控项,也就是使用它可以在prometheus的web界面中查看对应的数据,即它就是一个自定义的PromQL.host为标签 status为整型类型的字段
2、在192.168.56.131机器的/opt/monitor/telegraf/etc/telegraf/telegraf.d/目录下新增类似zabbix中的conf文件,配置如下
[[inputs.exec]] #使用telegraf的exec插件,它还有inputs.中间件名 的插件
#指定脚本位置
commands = ["/opt/monitor/telegraf/scripts/test.sh"]
#探测超时时间
timeout = "5s"
#数据格式,通常为influx类型
data_format = "influx"
3、在192.168.56.131机器的/opt/monitor/telegraf/etc/telegraf/telegraf.conf主配置文件中,必须添加以下配置.配置Prometheus从Telegraf抓取对应的指标
[[outputs.prometheus_client]]
listen = ":9273"
4、在监控机器中配置对应的yml告警规则
增加 /opt/monitor/prometheus/rules/test_rules.yml文件,配置文件如下
groups:
- name: fsFile_check
rules:
- alert: fsFile
expr: FS_fileMax_status != 65535
for: 1m
labels:
severity: warning
annotations:
summary: "FS_fileMax is not disabled (host {{ $labels.instance }})"
description: "FS_fileMax is expected to be 0 but is {{ $value }} on {{ $labels.instance }}"
5、重启prometheus、telegraf组件,查看prometheus-ui界面是否产生告警明为fsFile的告警消息,如下图所示
用这个expr: FS_fileMax_status != 65535表达式在promQL中查看结果

需求二:在顶部文章<golang实现mysql实例存活检查及全量备份是否完成检查工具开发>博客中,通过golang语言编写了一个mysql实例存活探测和mysql全量备份检查工具,现在想通过自定义脚本的方式对其进行监控
shell
#mysql alive check
[[inputs.exec]]
commands = ["/opt/monitor/telegraf/scripts/mysqlCheckTools mysqlpingcheck -H 192.168.56.131 -P 3306 -p dbbackup -u dbbackup"]
timeout='5s'
data_format="influx"
#mysql backup check
[[inputs.exec]]
commands = ["/opt/monitor/telegraf/scripts/mysqlCheckTools mysqlbackupcheck -d /export/servers/data/mybackup/my3306/xtrabackup/data -L /export/servers/data/mybackup/my3306/xtrabackup/log"]
timeout='5s'
data_format="influx"脚本执行结果如下所示

配置告警规则
yml
- alert: mysqlbackupcheck
expr: mysqlbackupcheck_status == 0
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.host }} {{ $labels.port }} "
- alert: mysqlPing
expr: mysqlping_status == 0
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.host }} {{ $labels.port }} "重启prometheus和telegraf组件,关闭数据库测试并查看web界面是否产生告警

通过告警表达式查看promQL返回的值


注意事项:
在下方的自定义监控中设置的返回格式是 echo "tcp_timestamps value=$value",当写告警规则的表达式时,直接用名称tcp_timestamps就可以采集到监控数据了。
但是在上方的两个需求示例中,当返回形式为mysqlbackupcheck,port=3306 status=0i, 含有status字段时,则告警规则就是名称_status才可以获取到监控指标的值,如上所示。否则会获取不到
yaml
需求:
需要通过监控telegraf组件实现对10.192.10.14服务器的/etc/sysctl.conf中配置的内核参数进行监控
实现过程:
1、联想到zabbix监控可以通过agent端编辑相关的conf文件,且conf文件中编写脚本或者其他采集发送,实现某个时刻组件的监控,因此再telegraf/scripts目录下也用同样方式测试是否能实现
2、在10.192.10.14机器的/opt/monitor/telegraf/scripts/目录下,增加一个探测的脚本文件check_tcp_timesmaps.sh,并授权执行权限。脚本内容如下
#!/bin/bash
# 读取net.ipv4.tcp_timestamps的值
value=$(sysctl net.ipv4.tcp_timestamps | awk '{print $3}')
# 输出为InfluxDB格式的指标
echo "tcp_timestamps value=$value" #其中tcp_timestamps为监控项,也就是使用它可以在prometheus的web界面中查看对应的数据,即它就是一个自定义的PromQL.
3、在10.192.10.14机器的/opt/monitor/telegraf/etc/telegraf/telegraf.d/目录下新增类似zabbix中的conf文件,配置如下
[[inputs.exec]] #使用telegraf的exec插件,它还有inputs.中间件名 的插件
#指定脚本位置
commands = ["/opt/monitor/telegraf/scripts/check_tcp_timestamps.sh"]
#探测超时时间
timeout = "5s"
#数据格式,通常为influx类型
data_format = "influx"
4、在10.192.10.14机器的/opt/monitor/telegraf/etc/telegraf/telegraf.conf主配置文件中,必须添加以下配置.配置Prometheus从Telegraf抓取对应的指标
[[outputs.prometheus_client]]
listen = ":9273"
5、在监控机器中配置对应的yml告警规则
增加 /opt/monitor/prometheus/rules/sysctl_tcp_timesamps.yml文件,配置文件如下
groups:
- name: tcp_timestamps_check
rules:
- alert: TCPTimestampsDisabled
expr: tcp_timestamps != 0
for: 1m
labels:
severity: warning
annotations:
summary: "TCP Timestamps is not disabled (host {{ $labels.instance }})"
description: "net.ipv4.tcp_timestamps is expected to be 0 but is {{ $value }} on {{ $labels.instance }}"至此telegraf自定义监控演示完成