由于多尺度特征融合的有效性能,路径聚合FPN(PAFPN)被广泛应用于YOLO检测器中。
然而,它不能同时高效且自适应地融合高级语义信息与低级空间信息。本文提出了一种名为MAF-YOLO的新模型,这是一个具有多功能 Neck 网络的新颖目标检测框架,名为多分支辅助FPN(MAFPN)。
在MAFPN中,设计了表面辅助融合(SAF)模块,以将 Backbone 网络的输出与 Neck 网络相结合,保留适量的浅层信息以促进后续学习。同时,高级辅助融合(AAF)模块深植于 Neck 网络内,向输出层传递更为丰富的梯度信息。
此外,作者提出的重参化异构高效层聚合网络(RepHELAN)模块确保了整体模型架构和卷积设计对异构大型卷积核的利用。因此,这保证了在同时实现多尺度感受野的同时保留与小目标相关的信息。
最后,以MAF-YOLO的nano版本为例,它可以在COCO数据集上达到42.4%的AP,相较于YOLOv8提高了大约5.1%。
1 Introduction
为了实现高性能的实时目标检测,近年来已经开发了各种算法。其中,从YOLOv1到YOLOv9的一系列YOLO算法,因其速度与准确度的折衷而发挥了越来越重要的作用。然而,YOLO系列算法的一个共同缺点是多功能尺度特征融合的限制。尽管特征金字塔网络(FPN)13的改进版------路径聚合特征金字塔网络(PAFPN)22已经被广泛集成到YOLO中,该机制采用双路径方法增强特征整合,从而提高准确度的同时控制计算成本。在图1(a)中,P3、P4和P5表示主干网不同层级的输出信息。YOLO系列算法的 Neck 结构采用传统的PAFPN,包含两个主要用于多尺度特征融合的主要路径。
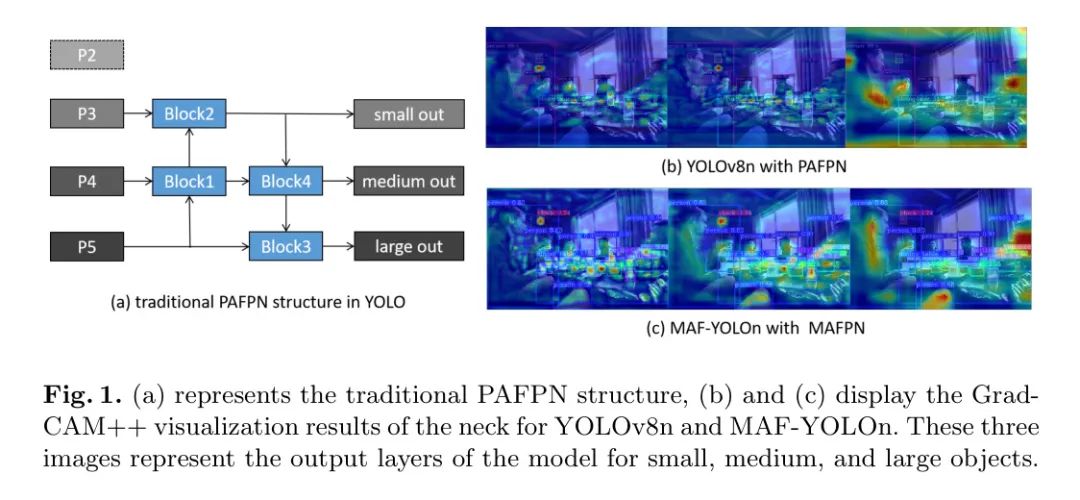 图1:(a)表示传统的PAFPN结构,(b)和(c)展示了YOLOv8n和本文提出的MAF-YOLOn Neck Grad-CAM++ 可视化结果。这三幅图像表示了模型对小、中、大目标输出层的激活情况。
图1:(a)表示传统的PAFPN结构,(b)和(c)展示了YOLOv8n和本文提出的MAF-YOLOn Neck Grad-CAM++ 可视化结果。这三幅图像表示了模型对小、中、大目标输出层的激活情况。
然而,PAFPN仍存在两个主要限制。首先,PAFPN倾向于合并同质尺度特征图,缺乏对不同分辨率层多尺度信息的集成处理和融合。例如,在PAFPN的Block1中,输入包括上采样的P5层和同级的P4层,这忽略了P3层中浅层低级空间信息的重要性。同样,在Block2中,没有直接融合含有小目标重要信息的P2层。这个缺陷在最后两个区块中同样存在。其次,该架构针对小目标检测层的策略是通过单一的下至上路径和两个区块制定的,这大大降低了模型在学习和表示微小目标特征方面的效率。如图1(b)和(c)所示,基于PAFPN的YOLOv8n在不同尺度目标的激活能力上,相较于本文提出的MAFPN要低。
本文的主要贡献如下:
- 作者提出了一种新的即插即用的 Neck 结构------多分支辅助FPN(MAFPN),以实现更丰富的特征交互和融合。在MAFPN中,表面辅助融合(SAF)通过双向连接维护浅层主干信息,增强了网络检测小目标的能力。此外,高级辅助融合(AAF)通过多向连接丰富了输出层的梯度信息。此外,MAFPN可以无缝地集成到任何其他检测器中,以增强其多尺度表征能力;
- 作者设计了轻量级的重参化异构高效层聚合网络(RepHELAN)模块,它结合了重参化异构大卷积的概念。该模块通过将大核卷积与几个小核卷积并行化,在不产生额外推理成本的同时,扩展了感知范围,并保留了小目标的信息;
- 作者提出了一种全局异构核选择机制(GHSK),它通过调整网络架构中不同分辨率特征层的RepHELAN中的核大小,自适应地扩大整个网络的有效感受野;
- 多分支辅助融合YOLO(MAF-YOLO)在MS COCO数据集上展示了在各种方面的优越目标检测性能,超过了现有的实时目标检测器。
2 Related works
2.1 Real-time object detectors
目标检测任务是在特定场景中识别目标。尽管两阶段2, 15和基于 Transformer 25, 27的检测器在准确度上取得了很高的表现,但它们复杂的结构常常伴随着大量的参数和计算开销,这影响了实时性能。大多数实时目标检测网络采用单阶段方法,其中YOLO系列尤其突出。PPYOLOE 23 和 YOLOv6 11 探索了重参化技术,并在标签分配中采用了任务对齐学习(TAL)7策略,显著提升了性能。YOLOv7 提出了ELAN方案,以优化从YOLOv4 1中的跨阶段部分网络结构,并设计了几种可训练的免费礼包方法,用于无损模型优化。YOLOv8 9 结合并优化了当前先进YOLO算法的策略,以实现速度与准确度之间更好的平衡,在工业界得到了广泛应用。最新的YOLOv9 21 引入了通用高效层聚合网络(GELAN)结构以及可编程梯度信息(PGI)的概念,以解决网络中的信息瓶颈问题。YOLOv9在参数利用效率上非常高,达到了当前YOLO家族的最高水平。
2.2 Multi-scale features fusion for object detection
FPN背后的原始想法是通过融入跨尺度连接和信息交换,来增强网络的多元检测能力。大量研究致力于优化和扩展FPN结构,以提高特征融合的效率。在YOLOv6-v3 中,双向拼接(BIC)机制被用于更好地利用 Backbone 网络浅层信息,而DAMO-YOLO 24采用重参化广义FPN(RepGFPN)以在 Backbone 和 Neck 进行更丰富的融合。Gold-YOLO 19引入了高级的聚集与分发机制,该机制通过卷积和自注意力操作在 Neck 内同时整合局部和全局信息。这些方法在很大程度上缓解了这一问题,但仍有进一步的优化空间。
3 Methodology
3.1 Macroscopic architecture
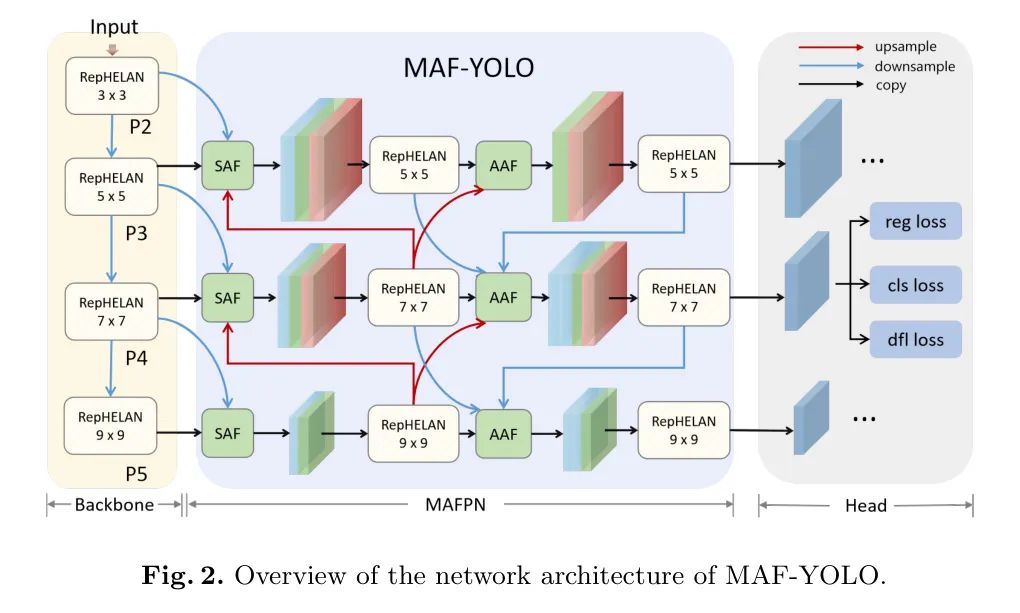 图2:MAF-YOLO的网络架构概览。
图2:MAF-YOLO的网络架构概览。
如图2所示,作者将一阶段目标检测器的宏观架构分解为三个主要部分: Backbone 网络、 neck(特征融合部分)和 head(预测部分)。
在MAF-YOLO中,输入图像首先通过 Backbone 网络,该网络包含四个阶段:P2、P3、P4和P5。作者设计了一个MAFPN作为neck结构。在第一条自底向上的路径中,SAF模块负责从 Backbone 网络中提取多尺度特征,并在neck的浅层进行初步辅助融合。
同时,AAF通过第二条自顶向下的路径中的密集连接收集每层的梯度信息,最终指导head在三个分辨率上获得多样化的输出信息。上述两个结构都采用RepHELAN模块进行特征提取,该模块使用动态大小的卷积核以实现自适应感受野。
最后,检测Head根据每个尺度的特征图预测物体边界框及其对应类别,以计算其损失。
3.2 全局异构核选择机制
Transformer 有效性的重要因素之一是它们的自注意力机制,该机制在全局或更大的窗口尺度上进行 Query -键-值操作。同样,大的卷积核可以捕捉到局部和全局特征,而使用适度大的卷积核来增加有效感受野已在几项工作中被证明是有效的。Trident网络12的研究表明,具有较大感受野的网络更适合检测较大的物体,反之,较小尺度的目标则从较小的感受野中受益。YOLO-MS3引入了异构核选择(HKS)协议的概念。
在 Backbone 网络中使用增量卷积核设计(3、5、7和9)以平衡性能和速度。受到这一工作的启发,作者将其扩展到全局异构核选择(GHKS)机制,将异构大型卷积核的概念整合到整个MAF-YOLO架构中。除了在 Backbone 网络的RepHELAN中逐步增加卷积核外,作者还引入了5、7和9的大卷积核到MAFPN中以适应不同分辨率的需求,从而逐步获得多尺度感知场信息。
3.3 Multi-Branch Auxiliary FPN
精确的定位依赖于从浅层网络中获得的详细边缘信息,而精确的分类则需要更深层网络来捕捉粗粒度信息18。作者认为,一个有效的特征金字塔网络(FPN)应该支持浅层和深层网络信息流的充分和充足融合。
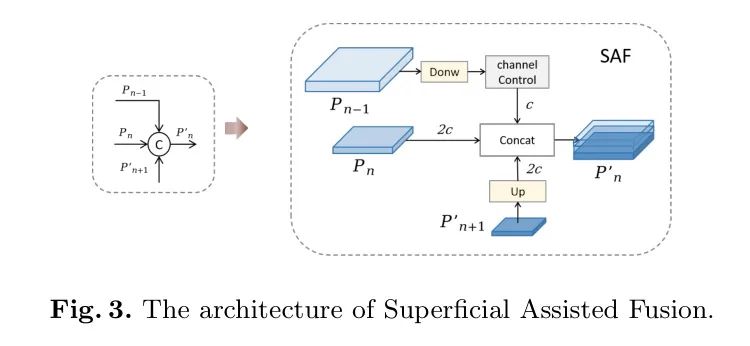
3.3.1 表层辅助融合
在 Backbone 网络中保留浅层空间信息对于增强较小目标的检测能力至关重要。然而, Backbone 网络提供的信息相对基础,容易受到干扰。因此,作者将浅层信息作为辅助分支融入到深层网络中,以确保后续层学习的稳定性。遵循这些原则,作者开发了SAF模块,如图3所示。SAF的主要目标是整合深层信息与来自同一层次 Level 以及 Backbone 网络中的高分辨率浅层特征,旨在保留丰富的定位细节,以增强网络的空间表现。此外,作者使用卷积来控制浅层信息中的通道数,确保在拼接操作中占比较小,不影响后续学习。令、和表示不同分辨率的特征图,其中、和分别表示 Backbone 网络的特性层以及MAFPN的两条路径。符号表示上采样操作。表示带有批量归一化层的下采样卷积,而代表函数,表示控制通道数的卷积。应用SAF后的输出结果如下:

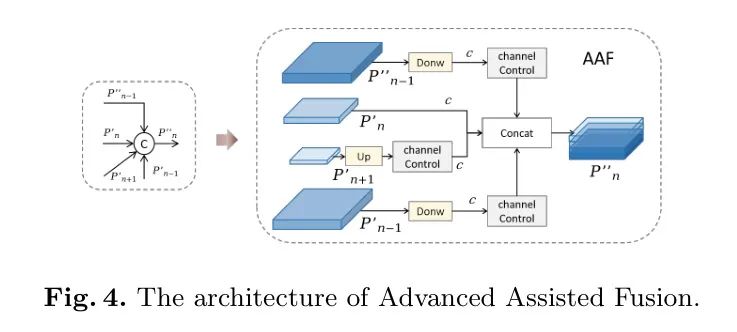
3.3.2 Advanced Assisted Fusion
为了进一步提高特征层信息的交互式利用,作者在MAFPN的更深层次采用了AAF模块进行多尺度信息融合。具体来说,图4展示了在中的AAF连接,这些连接跨越了浅层的高分辨率层、浅层的低分辨率层、同级的浅层以及前一层进行信息聚合。在这一环节,最终的输出层P4能够同时融合来自四个不同层的信息,从而显著提升中等大小目标的性能。AAF还使用了卷积控制通道来调节每一层对结果的影响。通过实验,作者发现当采用SAF中的策略时,即三个浅层的通道数设置为深层通道数的一半,这会导致性能略有下降。借鉴FPN的传统单路径架构,作者推测初始的引导信息已经嵌入到MAFPN的浅层中。因此,作者使每一层的通道数相等,以确保模型获得多样化的输出。应用AAF后的输出结果如下:

3.4 Re-parameterized Heterogeneous Depthwise Convolution
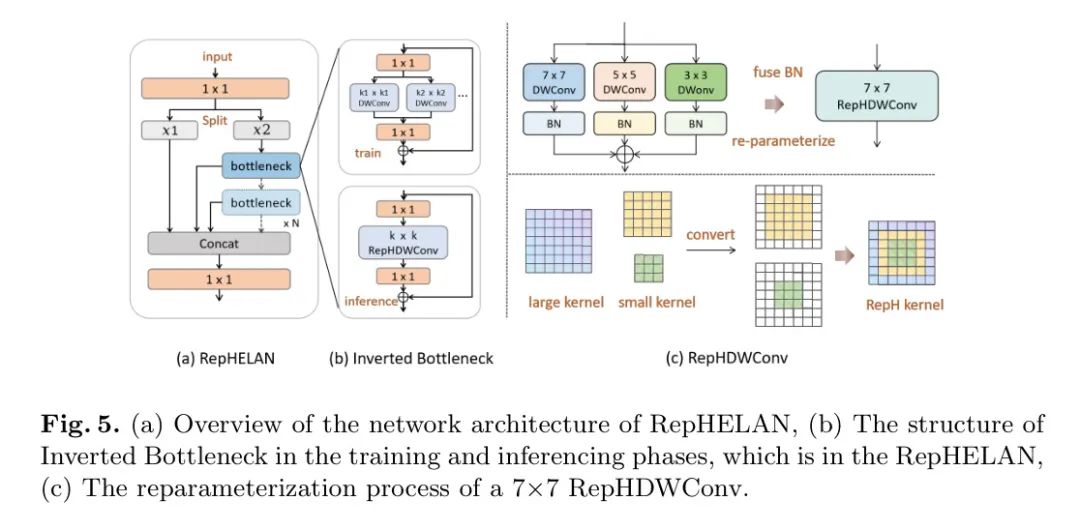
在前一节设计了MAFPN结构之后,另一个挑战在于在整个架构中高效设计特征提取块。在本节中,作者介绍了一种强大的编码器架构设计,它能够高效学习具有表现力的多尺度特征表示。RepHELAN的结构如图5(a)所示。最初,输入信息经过卷积和Split操作,分为两个流。一个流保留原始信息,然后直接进入Concat操作,而另一个流经过N个倒置瓶颈单元的处理。由于ELAN的机制,分支以及通过每个倒置瓶颈的输出被保留并最终连接在一起。倒置瓶颈的具体结构如图5(b)所示,输入顺序通过卷积来扩展通道数,接着是的RepHDWConv操作,最后通过的点卷积来减少通道数并补偿DWConv可能造成的信息损失。
首先,作者在全局架构中采用了大核的深度卷积来实现前述的GHKS机制。作者的研究还表明,尽管更大的卷积核可能通过编码更广泛的区域来提高性能,但它们可能会无意中模糊与小目标相关的细节,从而留有改进的空间。因此,作者将全局架构中的异构理念转移到单个卷积中,并融入了重参化的思想5, 6,以实现RepHConv。具体来说,作者通过同时运行大核和小核的卷积来补充对小目标的检测。不同大小的卷积核增强了网络的扩展感受野(ERF)和特征表示的多样性。如图5(b)所示,在训练和推理阶段,倒置瓶颈表现出一定的差异。在训练期间,网络并行运行n个不同大小的深度卷积(DWConv),而在推理期间,这些卷积被合并为一个,不会降低推理速度。作者认为,RepHDWConv是一种卓越的卷积策略,能够在多尺度上增强表示能力,同时损失最小。
图5(c)展示了重参化一个 RepHDWConv的步骤。首先,在RepHDWConv中并行一个k1*k1的大DWConv和多个k2*k2的小DWConv,每个DWConv后面跟一个批量归一化(bn)层,并将每个卷积核的参数与其对应的bn层参数合并。第二步,通过类似于填充的过程,这些小DWConv被同化到一个大DWConv中,然后进行重参化。这些异构DWConv的参数和偏置被累积形成一个新RepHDWConv。设为输入特征图I,Kn和Bn分别表示n*n核的卷积权重和偏置。得到的输出特征图O为:

4 Experiments
4.1 Experimental Setup
4.1.1 Datasets
作者在微软COCO 201714数据集上进行了广泛的实验,以验证所提出的MAF-YOLO的有效性。具体来说,所有方法的训练都是在115k训练图像上进行的,并且作者在5000张验证图像上进行了消融研究。作者报告了在不同IoU阈值和目标尺度下的标准平均精度(AP)结果。
4.1.2 Implimentation details
作者的实现基于YOLOv6-2.0框架。所有实验都是在8块NVIDIA GeForce RTX 2080Ti GPU上进行的,并且MAF-YOLO的所有尺度都是从头开始训练300个周期,不依赖于其他大规模数据集,如ImageNet4,或者预训练权重。此外,作者还采用了更强大的基于动态缓存的混合增强26和马赛克机制,并简单地将YOLOv6输出 Head 的两个卷积替换为轻量级的RepHDWConv。更多的实现细节可以在补充材料中找到。
4.2 Analysis of RepHELAN
在本小节中,作者将对RepHELAN模块进行一系列消融研究。默认情况下,作者所有的实验均采用MAF-YOLO nano模型。
4.2.1 Different computational blocks
作者首先在表1中对RepELAN模块进行了消融实验,实验中采用了来自其他先进YOLO模型的各种计算块。相比于其他模块,作者的RepHELAN不仅具有更高的参数利用率,同时还实现了更高的准确度。
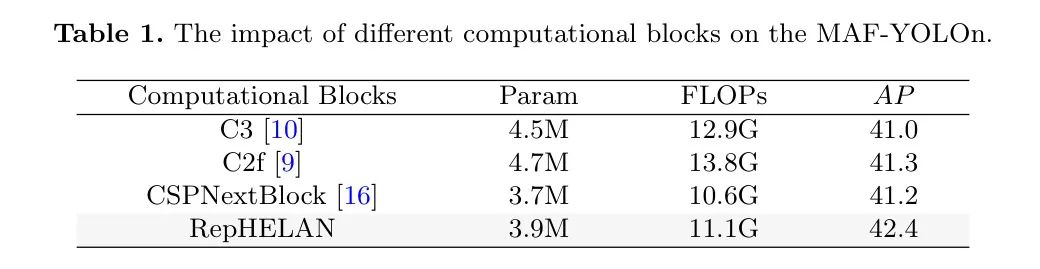
4.2.2 Ablation study on RepHELAN
如表2所示,作者对RepHELAN模块进行了消融研究,其中表示在Inverted Bottleneck中是否采用了大卷积核的思想。每个Bottleneck默认包含一个的DWConv。在使用大卷积核时,网络遵循GMSK策略,在架构的RepHELAN中使用、、和的DWConvs。首先,作者添加了ELAN机制,这带来了0.2%的AP提升,并且只增加了少量的计数器。
表中的第三行意味着,在不增加采用大卷积核的额外开销的情况下,RepHConv实现了0.4%的性能提升,同时保持了模型大小不变。此外,仅使用大卷积核和ELAN策略会导致显著的性能提升(+1% ),尽管对小目标的性能有所下降(-0.3% )。
最终,当用RepHConv替换大DWConv时,作者在小、中、大目标类别上实现了42.4% AP的最佳性能,并显著提高了性能。
4.3 MAFPN分析
在本小节中,作者对MAFPN的每个模块进行了消融实验,并通过在不同实验中将不同算法替换为 Neck 结构,展示了MAFPN即插即用的能力。
4.3.1 Ablation study on MAFPN
如表3所示,本实验的结果表明,模型的默认 Neck 设置为PAFPN,其中包括六个RepHELAN块。首先,作者在 Backbone 网络和 Neck 的浅层中融入了SAF模块,这使得性能提升了0.3%,同时参数增加了0.3M。值得注意的是,通过SAF,作者对小目标实现了1%的性能提升。其次,仅通过添加AAF模块,作者观察到对所有尺度物体性能的增强。最终,当SAF和AAF结合使用时,模型的性能达到最优。

4.3.2 Ablation study on other models
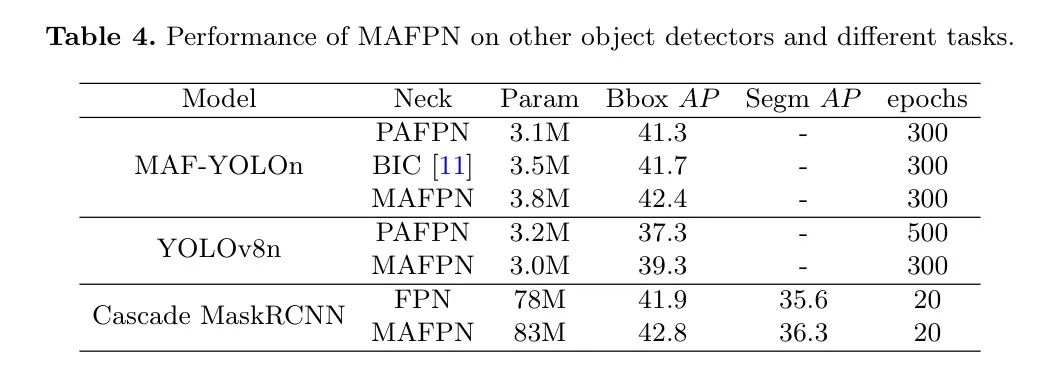
MAFPN可以作为其他模型的即插即用模块,其结果列于表4中。首先,作者在主流的单阶段检测器YOLOv8n中用MAFPN替换了PAFPN,并改变了通道数以保持模型较小。YOLOv8n-MAFPN使用的训练轮次更少(减少了200轮),参数也更少,同时获得了2%的AP提升,反映出MAFPN的卓越性能。更重要的是,作者还通过在实例分割任务中使用两阶段检测器Cascade MaskRCNN 2验证了MAFPN的有效性。
4.4 对 MAF-YOLO 的消融研究
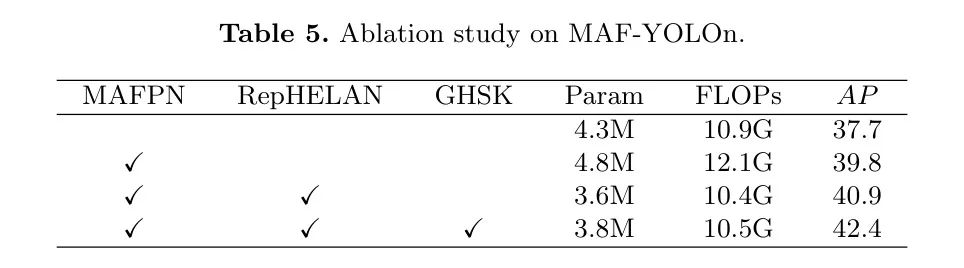
MAF-YOLO包括MAFPN、RepHELAN模块和GHSK策略,作者按顺序进行了消融实验,结果如表5所示。
作者首先添加了MAFPN结构,这增加了0.5M的参数并提升了2.1%的AP性能,随后通过添加轻量级的RepHELAN模块,在减少1.2M参数的同时,性能反而提高了1.1%的AP,最后,GHSK方法在几乎不增加参数的情况下,将模型准确度提升了1.2%的AP。
4.5 与最先进技术的比较
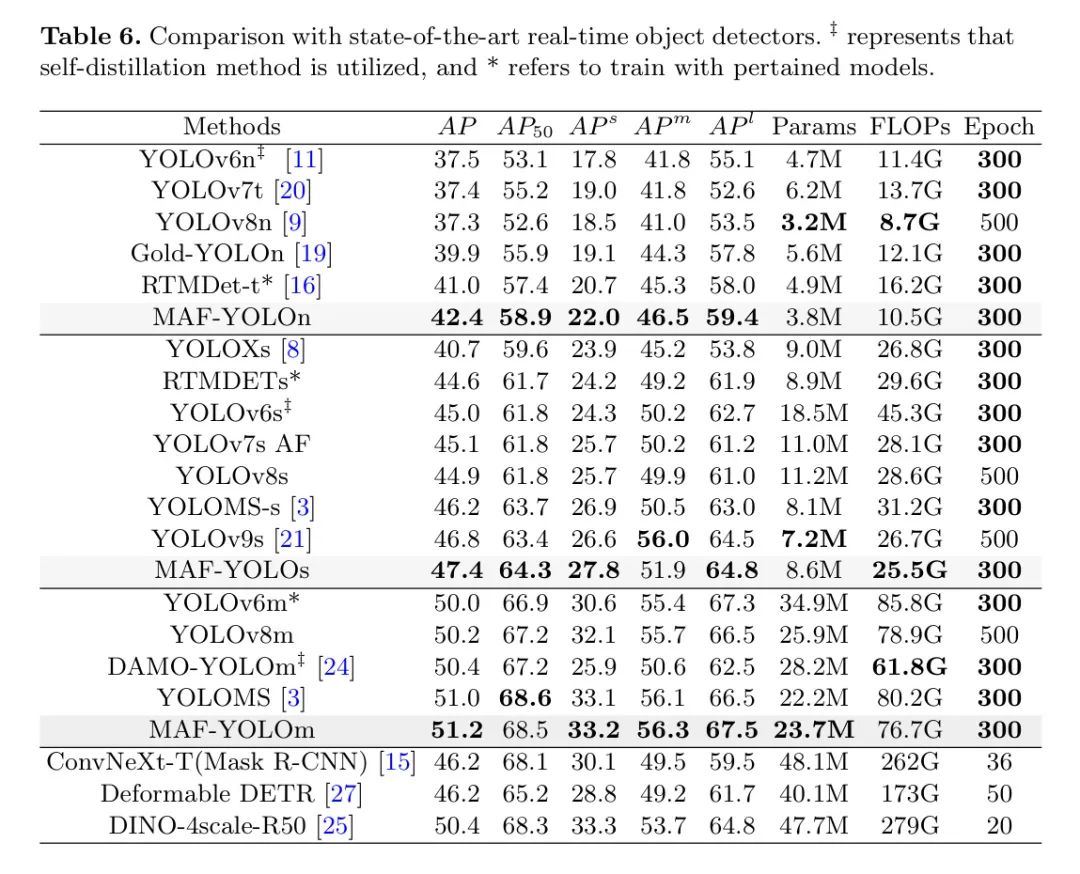
表6和图6展示了作者提出的MAF-YOLO与其他SOTA实时目标检测器的比较。与纳米级模型相比,MAF-YOLOn的参数数量略多于YOLOv8n,但AP提升了5.1%。
与当前较新的Gold-YOLOn相比,MAF-YOLOn减少了约36%的参数和13%的计算量,但AP仍提高了2.5%。对于小规模模型,作者的模型也具有很大的优势,与YOLOv7s的 Anchor 点无关版本相比,MAF-YOLOs的参数减少了22%,AP显著提高了2.3%。
同样值得注意的是,作者的MAF-YOLOs在与当前SOTA模型YOLOv9s参数和计算量相当的情况下,取得了与之相当的结果,并且比YOLOv9s的AP高出0.6。
此外,作者展示了几个两阶段和基于Transformer的检测器,在这些检测器中,作者的模型表现出更优越的性能,并且更加轻量化。
不同算法在COCO验证集上的部分检测结果展示在图7中。

5 Conclusions
在本文中,作者提出了MAFPN作为解决传统YOLO中PAFPN局限性的方案,该方案包含两个关键组成部分:SAF和AAF。SAF用于有效保留 Backbone 网络中的浅层信息,而AAF通过增强信息融合使输出层保持多样的多尺度信息。此外,作者将GMSK整合到MAF-YOLO中,动态地扩大整个架构中的卷积核,从而显著扩展网络的感知领域。同时,作者引入了RepHELAN模块,该模块利用重参化的异构卷积大幅提升多尺度表征能力。因此,MAF-YOLO在保持参数数量相当的同时,展现了卓越的整体性能。