图像分割笔记
1、源码下载
bash
git clone https://github.com/ultralytics/ultralytics.gitgit回到对应版本:
方式一:使用 git checkout(临时查看旧版本)
bash
git checkout <commit-hash>
git checkout v8.3.170方式二:使用 git reset(永久回退当前分支)
bash
git reset --hard <commit-hash>查看距离哪个标签最近
bash
# 查看某个提交的最近标签
git describe abc1234
# 只显示标签名(忽略距离)
git describe --tags --abbrev=0 abc1234
# 查看当前提交的最近标签
git describe2、数据获取
1、yolo官方分割数据集: https://docs.ultralytics.com/zh/datasets/segment/#ultralytics-yolo-format
https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8-seg.zip
2、 自己标注数据集
通过网盘分享的文件:马
链接: https://pan.baidu.com/s/1vX9WokV8Nx-MzHXZt8Ppnw?pwd=4xca 提取码: 4xca
3、参考链接
(1)基于YOLOv11的语义分割模型训练自己的数据集:
https://blog.csdn.net/qq_51828120/article/details/147215779
(2)基于yolo11-seg的水果桃子语义分割:
https://mp.weixin.qq.com/s/a2Ln_zGvO07lep5oJqhZ4w?login=from_csdn
2、人工标注数据集后转yolo
2.1 文件夹划分
datadir_preprocess.py
python
import os
import shutil
# 原始文件夹路径
source_folder = r"D:\songlin\data\8.图像分割相关\马"
# 创建目标文件夹
json_folder = os.path.join(source_folder, "json")
image_folder = os.path.join(source_folder, "image")
# 如果目标文件夹不存在,则创建
os.makedirs(json_folder, exist_ok=True)
os.makedirs(image_folder, exist_ok=True)
# 遍历文件夹中的所有文件
for filename in os.listdir(source_folder):
file_path = os.path.join(source_folder, filename)
# 如果是JSON文件,移动到json_files文件夹
if filename.endswith(".json"):
shutil.move(file_path, os.path.join(json_folder, filename))
# 如果是图片文件(常见格式),移动到image_files文件夹
elif filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
shutil.move(file_path, os.path.join(image_folder, filename))
print("文件分类完成!")2.2 数据集格式处理
json2yolo_seg.py
python
import os
import json
# 指定JSON文件夹路径和YOLO保存文件夹路径
json_folder = r"D:\songlin\data\8.图像分割相关\马\json" # 替换为实际的JSON文件夹路径
yolo_save_folder = r"D:\songlin\data\8.图像分割相关\马\yolo_txt" # 替换为实际保存YOLO txt文件的文件夹
name = ["horse"] #标签名
# 如果保存文件夹不存在,创建它
if not os.path.exists(yolo_save_folder):
os.makedirs(yolo_save_folder)
# 将实例分割数据转换为YOLO格式
def convert_to_yolo_format(json_data, image_width, image_height):
yolo_data = []
shapes = json_data['shapes']
for shape in shapes:
label = shape['label']
points = shape['points']
# 获取分割边界框的x和y的最大最小值
x_coords = [p[0] for p in points]
y_coords = [p[1] for p in points]
x_min = min(x_coords)
x_max = max(x_coords)
y_min = min(y_coords)
y_max = max(y_coords)
# 计算中心点,宽度和高度(归一化到[0, 1]范围)
x_center = (x_min + x_max) / 2 / image_width
y_center = (y_min + y_max) / 2 / image_height
bbox_width = (x_max - x_min) / image_width
bbox_height = (y_max - y_min) / image_height
# 归一化分割点
normalized_points = [(x / image_width, y / image_height) for x, y in points]
# 创建YOLO格式的字符串 (格式: class_id x_center y_center width height seg_points)
if label not in name:
name.append(label)
class_id = name.index(label)
yolo_format = f"{class_id} {x_center} {y_center} {bbox_width} {bbox_height} "
# 添加分割坐标点
yolo_format += " ".join([f"{x} {y}" for x, y in normalized_points])
yolo_data.append(yolo_format)
return yolo_data
# 遍历文件夹中的所有JSON文件
for filename in os.listdir(json_folder):
if filename.endswith(".json"):
json_path = os.path.join(json_folder, filename)
with open(json_path, 'r', encoding='utf-8') as f:
json_data = json.load(f)
# 获取图像大小
image_width = json_data['imageWidth']
image_height = json_data['imageHeight']
# 转换为YOLO格式
yolo_data = convert_to_yolo_format(json_data, image_width, image_height)
# 保存为txt文件
txt_filename = os.path.splitext(filename)[0] + ".txt"
txt_save_path = os.path.join(yolo_save_folder, txt_filename)
with open(txt_save_path, 'w', encoding='utf-8') as f:
for line in yolo_data:
f.write(line + "\n")
print("转换完成并保存为YOLO格式!")3、 数据集划分
python
import os
import shutil
# 原始文件夹路径
source_folder = r"D:\songlin\data\8.图像分割相关\马"
# 创建目标文件夹
json_folder = os.path.join(source_folder, "json")
image_folder = os.path.join(source_folder, "image")
# 如果目标文件夹不存在,则创建
os.makedirs(json_folder, exist_ok=True)
os.makedirs(image_folder, exist_ok=True)
# 遍历文件夹中的所有文件
for filename in os.listdir(source_folder):
file_path = os.path.join(source_folder, filename)
# 如果是JSON文件,移动到json_files文件夹
if filename.endswith(".json"):
shutil.move(file_path, os.path.join(json_folder, filename))
# 如果是图片文件(常见格式),移动到image_files文件夹
elif filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
shutil.move(file_path, os.path.join(image_folder, filename))
print("文件分类完成!")参考链接:
1、https://blog.csdn.net/zqq19980906_/article/details/143092674
3、环境配置
bash
conda create -n yolov11 python==3.8.10 -y
conda activate yolov11
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu118
conda install cudatoolkit==11.8.0
# 找到cudnn地址,解压进对应环境里的library文件夹下,将解压后的cudnn文件夹直接复制进去替换
E:\software_install\miniconda\envs\yolov11\Library
pip install opencv-python tqdm pyyaml requests matplotlib pandas scipy4、模型训练
python
from ultralytics import YOLO
if __name__ == '__main__':
# model = YOLO(r'ultralytics/cfg/models/11/yolo11-seg.yaml')
model = YOLO(r'yolo11n-seg.pt')
model.train(data=r'data.yaml',
imgsz=640,
epochs=100,
single_cls=True,
batch=16,
workers=10,
device='0',
)5、模型推理
python
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/segment/train/weights/best.pt')
model.predict(
source=r'D:\songlin\data\8.图像分割相关\马\dataset\val\images\19302950_164550132000_2.jpg',
imgsz=640,
device='0',
save=True,
conf=0.25,
line_width=4,
box=True,
show_labels=True,
show_conf=True,
retina_masks=True,
show=True # 新增,实时显示预测结果窗口
)6、模型部署
6.1 yolov5_flask学习
1、 环境配置
bash
conda create -n yolov5_flask python=3.8 -y
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu118
pip install flask opencv-python pyyaml matplotlib scipy tqdm下载yolov5_v3.0版本,这个不需要操作,yolov5版本不能setup.py安装
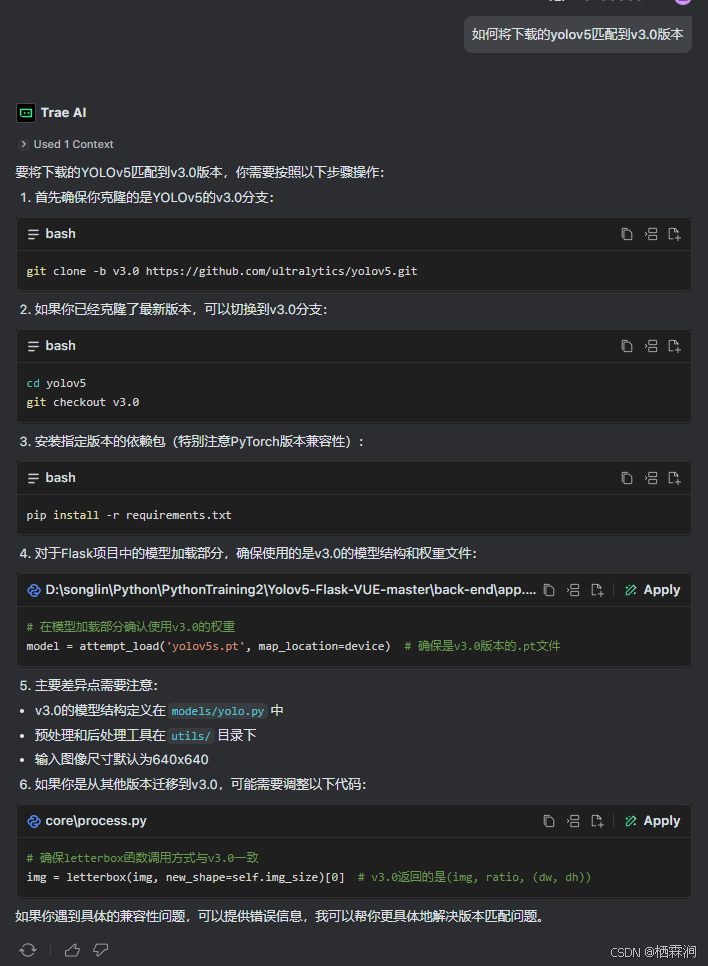
代码存储链接:https://gitee.com/songyulining/yolov5_flask_vue
2、npm前端环境配置
安装Node.js
https://nodejs.org/zh-cn
安装依赖
bash
npm install7、版本上传
bash
git remote set-url origin https://gitee.com/songyulining/yolov11_seg_run.git
git push origin HEAD:refs/heads/v8.3.170