2024-09-24,由麻省理工学院、微软、丰田研究院、NVIDIA联合发布的 Faces in Things,为我们打开了研究人类视觉错觉------尤其是面部错觉(Pareidolia)的新篇章。专注于人类视觉系统如何在各种随机刺激中检测到类似面孔的结构,例如在咖啡污渍或天空中的云朵中看到面孔。
数据集地址:Faces in Things|计算机视觉数据集|人脸检测数据集
一、背景:
人类视觉与错觉 在人类视觉系统中,我们对检测面孔非常敏感,这在进化上具有明显的优势,比如更容易在灌木丛中发现未知的捕食者。然而,这也导致了错误的人脸检测。面部错觉(Face pareidolia)描述了在其他随机刺激中感知到类似面孔的结构的现象。
现有研究的局限 尽管人类和动物都会经历面部错觉,但这种现象在计算机视觉系统中尚未得到充分研究。
目前遇到的困难和挑战:
-
人类与机器的差异:人类和机器在面部错觉检测方面存在显著的行为差异。
-
进化需求:人类检测动物面孔的需求可能解释了这种差异的一部分。
数据集地址:Faces in Things|计算机视觉数据集|人脸检测数据集
二、让我们一起看一下Faces in Things 数据集
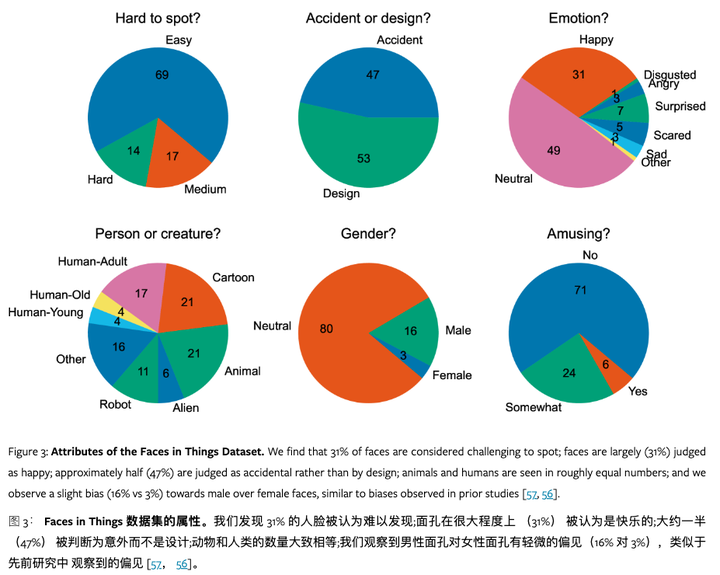
Faces in Things数据集:一个包含五千张网络图片的面部错觉图像数据集,利用这个数据集,研究人员检验了最先进的人脸检测器是否也会展现出面部错觉,并发现了一个显著的行为差距。
-
数据集的建立:首次创建了一个大规模的面部错觉数据集,为面部错觉的研究提供了直接支持。
-
行为差距的发现:通过实验发现,即使是最先进的人脸检测器,在没有经过专门训练的情况下,也难以很好地检测到面部错觉。
-
统计模型的提出:提出了一个简单的面部错觉统计模型,并通过实验验证了模型的关键预测。
数据集的构建:
-
样本收集:从LAION-5B数据集中采样候选错觉图像,并使用CLIP检索构建原始图像集。
-
详细注释:每张图片都包含了人脸的边界框和基本面部属性。
-
任务设计:数据集支持多种面部检测模型的研究。
-
数据集分割:随机将数据集分为训练集(70%)和测试集(30%)
数据集特点
-
多任务:"Faces in Things"数据集可以用于多种面部检测任务。
-
高质量:通过人工标注,确保了数据集的高质量。
-
跨数据集泛化:在不同的数据集上进行测试,验证了模型的泛化能力。


三、让我们一起展望 Faces in Thing数据集的应用
比如,我是一名心里咨询师。
哎呀,我之前做心理咨询的时候,遇到很多害怕社交的客人。他们一想到要跟人打交道,心就怦怦跳,紧张得不行。以前,我得用各种方法帮他们克服这种焦虑,比如角色扮演啊,慢慢习惯面对面的交流。
自从发现集成Faces in Things这个数据集的智能系统
我的工作就有了新的突破。这里面有成千上万的图片,都是些看起来像脸的东西,但又不完全是真正的脸。有的是在咖啡渍里,有的是在云彩里,反正就是各种奇奇怪怪的地方。
我用这些图片给来访者做训练。一开始,他们看到这些模糊的、像脸一样的图像,心里也是七上八下的。但慢慢地,他们开始学会怎么去分辨这些错觉,知道哪些是真的人脸,哪些只是看起来像而已。
这样做了一段时间后,来访者告诉我,他们在现实生活中好像也没那么害怕了。他们开始能更好地读懂别人的表情,知道什么时候该说话,什么时候该听。这就像是解锁了他们心里的一把锁,让他们在社交场合中更自在了。
通过这些面孔错觉的练习,我的来访者现在可以更自信地面对人群,享受社交的乐趣了。这种感觉真的是太棒了!