我是娜姐 @迪娜学姐 ,一个SCI医学期刊编辑,探索用AI工具提效论文写作和发表。

关于用ChatGPT润色论文的注意事项,我之前写过一篇:
在学员使用过程中,我又发现一些认知和使用方法上的误区,总结如下:
误区1:ChatGPT润色会不会出现语法错误?
如果还在纠结语法错误,那说明你还没懂大模型的运作机制。
1700亿的优质文本数据训练再加上训练后的RLHF微调(人类反馈强化学习),语法正确对于ChatGPT来说是最基本的,它还上知天文下知地理。知识储备也比一般人丰富。
就像咱们在中国出身长大的人,你不用教ta中文的主谓宾,ta说中文也不会出现语法错误。ChatGPT经过人类文本预训练和对齐微调,语法准确性也是同理。
误区2: ChatGPT润色完AI率会不会太高,被编辑看出来?
ChatGPT出现以后,论文除了重复率又有了AI率。AI检测率通常根据一些特定特征来判断,比如词汇分布、句子结构的单一性、连贯性和内容的可预测性。
与人类写作相比,AI生成的文本可能会显得呆板、平淡,缺少创造力。在学术论文中,常见的高频词汇包括"delve into""holistic""afflict""advocate"等。
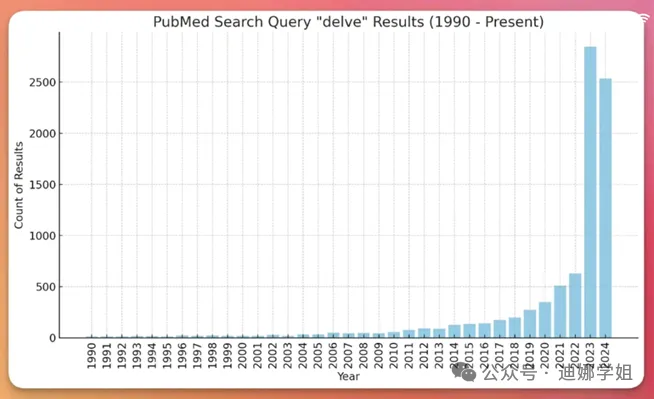
但是涉及到论文润色、中译英,基础文本是你自己写的文章,并不是AI创作的,AI只是帮你纠正语法、理顺逻辑、使之更符合学术规范。
所以AI率高,根本原因是提示语不对,对风格和用词的定义规范不够细致精准,或改动过大。 如果提示语精准,它就和人工润色的效果是一样的。
因为AI的语料库来自于人类作品,原理上它是可以做到和人的输出风格一样,Science的主编也曾公开说过AI率不准确也毫无意义。
误区3: ChatGPT润色完不放心,还是更相信传统的润色工具Grammarly, DeepL, Quillbot
ChatGPT 为代表的大模型(LLM)和传统的润色工具Grammarly, Quillbot相比,它们的底层技术原理是不一样的:
大模型LLM基于 Transformer 架构,以及庞大的参数量和数据集训练。Grammarly, Quillbot则是基于传统的机器学习和规则引擎。

(大模型的自注意力机制让它能够超越句子,对更长文本的上下文作为整体来关联理解,从而提升文本的逻辑性和连贯性。)
Grammarly等传统工具可以用来纠正语法错误,同义词替换等。相比之下,大模型LLM用于润色,有如下优势:
·语义理解:ChatGPT等大模型可以更好地理解复杂学术句式,尤其在处理跨句、跨段的长文本时,可以通过语境预测出更加符合原意的表达。比如帮你的摘要部分加一个结尾,陈述该项研究的意义。之前的文章中我还举过一个上下文关联的出色例子:
摘要中我描述过"蛋白的定量分析",然后,ChatGPT在Methods部分的Western Blot Analysis(蛋白印记分析)部分给我补充了关于该部分实验的描述"The protein bands were quantified with ImageJ software"。
·连贯性和逻辑性:大模型生成的润色文本通常在连贯性和逻辑性上表现更好,能适应学术论文的特殊需求。
比如主语是"The protein",放到更长的上下文,ChatGPT也许会帮你改成which/it/that等,让文章更连贯,整体性更好。
·专业术语:大模型可以结合上下文更精确地调整和应用学术术语,对学术类型文本更加友好。比如我之前举过的GPT润色的惊艳时刻:
原文:Following antigen clearance and resolution of inflammation, most activated T cells die.
GPT把cells die改成了cells undergo programmed cell death(细胞程序性死亡)。上下文并没有出现过一次"细胞程序性死亡",但是GPT又改的非常精准。可以说,95分的水平,润色公司也不一定能改成这样了。要想达到这个水平,一是要能理解上下文,二是要有领域内的背景知识。
所以,如果你用ChatGPT润色完,再用Grammarly改一遍,是弄巧成拙了。