最近在客户环境部署的边缘服务器集群中,出现了一个的 k8s 网络连通性问题:
- ✅ Node 节点之间网络连通正常
- ✅ Pod 到对端 Node 网络连通正常
- ❌ Pod 之间网络通信异常,pod 之间无法 ping 通,tcp 无法建连

网络方案使用的是 Flannel VXLAN 覆盖网络,做了一下经过初步排查:尝试随便发送一些数据到对端的 vxlan 监听的 8472 端口,是可以抓到包的,说明网络链路是通的。
但是我们 vxlan 发送的 udp 包对端却始终收不到,于是找到了其中一个 vxlan 包(如下图所示),来手动发送。
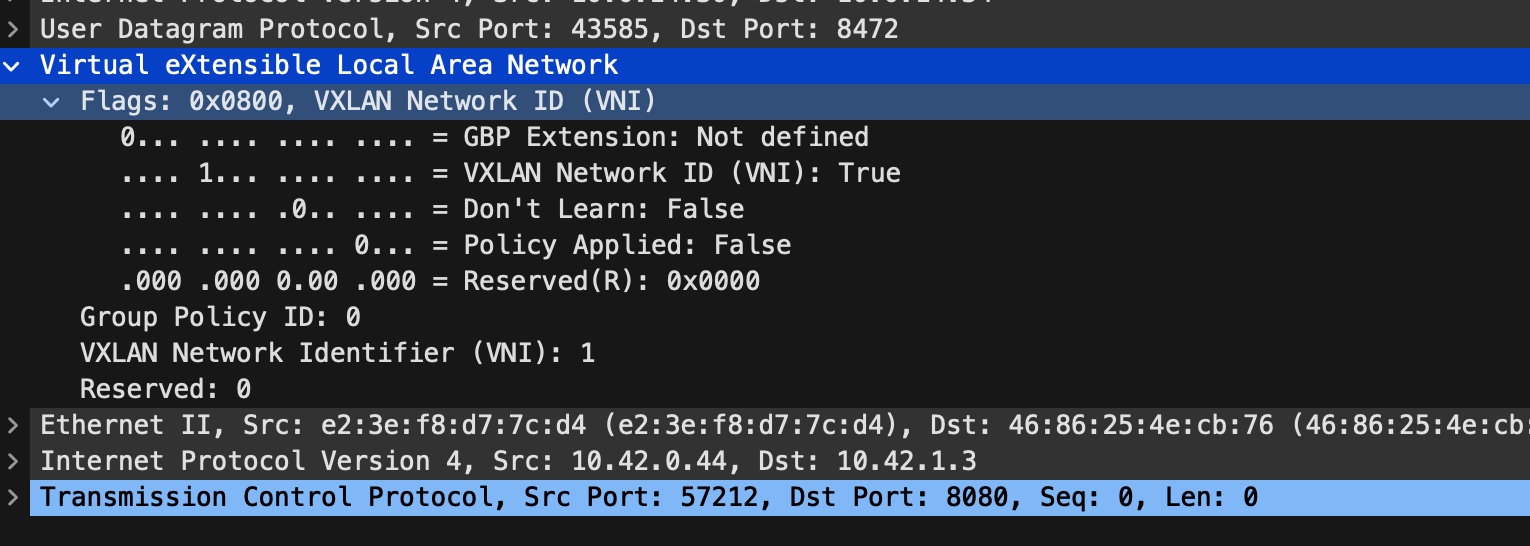
yaml
nc -u 10.0.14.34 8472 < udp_data.txt使用 nc 手动发送,通过抓包确认对端没有收到,但是随便换一个内容(里面是普通 ascii 字符串)发送,对端是可以立刻抓到包的。
yaml
nc -u 10.0.14.34 8472 < other_content.txt通过分析分析两边的丢包(使用 dropwatch、systemtap 等工具),并没有看到 udp 相关的丢包,因此推断问题可能出现在了 vxlan 包的特点上,大概率是被中间交换机等设备拦截。
反向推断,拦截设备如何可以精准识别 vxlan 的包?一定是 vxlan 包有一定的特点。
vxlan
通过 rfc(datatracker.ietf.org/doc/html/rf... vxlan 包的包头是固定的 0x08,中间交换机大概率是根据这个来判断的,于是初步的测试,把一直发送不成功的包,稍微改一下。
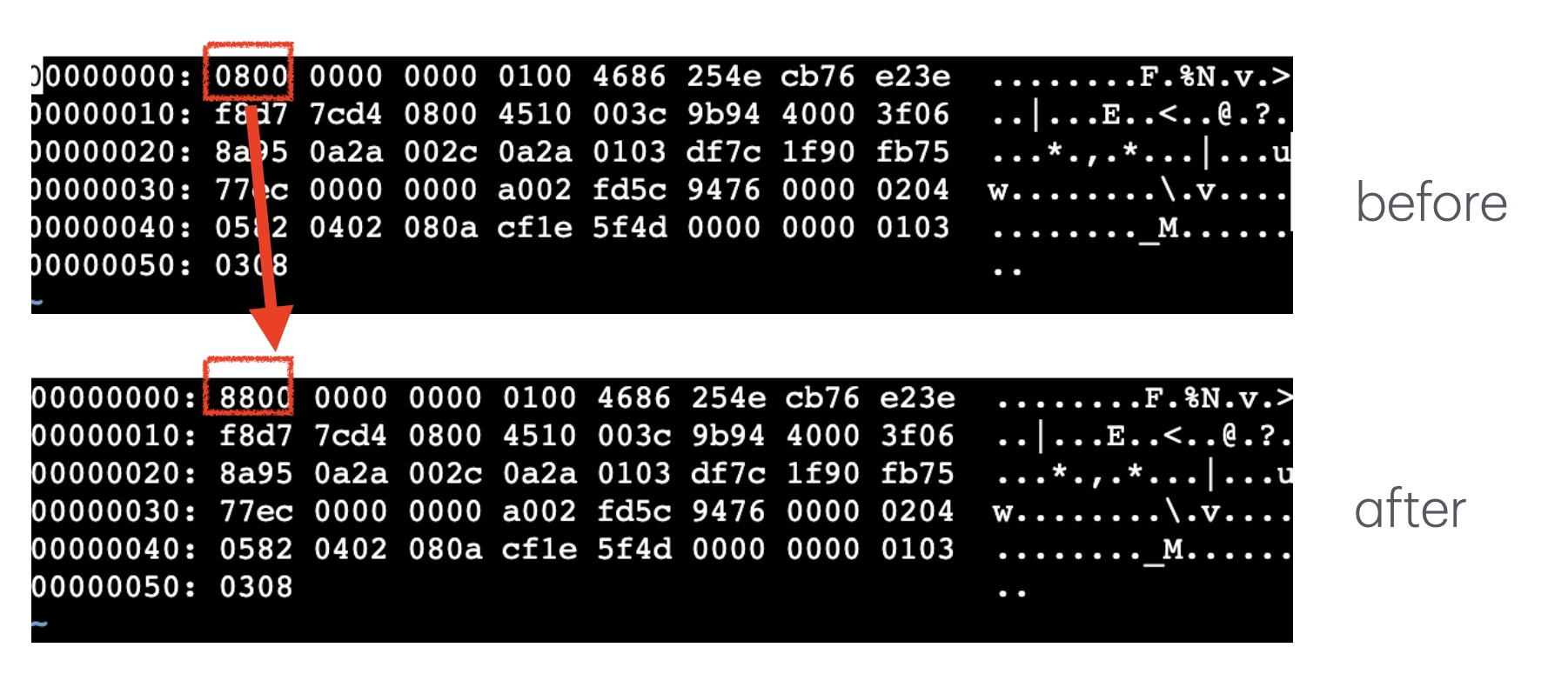
不出意外的,只改了一个字节,对端就能收到了,vxlan 的 flag 也变为了 0x88。

现在知道了问题,就有几种方案可以选择:
- 联系客户进行处理
- 切换 k8s 的网络模型
- 使用 iptables 或者 ebpf 等歪门邪道 hack
使用 ebpf 来欺骗中间交换机
接下来使用 ebpf 来把每个发出去的 vxlan 包的第一个字节从 0x08 改为 0x88(或者其它),收到对端的 vxlan 包以后,再把 0x88 还原为 0x08,交给内核处理 vxlan 包。
这里使用 rust aya 来快速开发 ebpf 程序,Aya 是一个用 Rust 编写的 eBPF 开发框架,专注于简化 Linux eBPF 程序的开发过程。它允许开发者直接在 Rust 中编写 eBPF 程序,无需使用 C 语言。通过 rustc 把 rust 直接 llvm 编译到 ebpf 字节码。同时提供了高级 API 封装,使用起来非常方便。
因为我们要同时处理出站和入站的流量,我们需要使用 ebpf 的 tc 模块。完整的代码见: github.com/arthur-zhan...
先来处理出站流量(egress),代码如下,核心逻辑就是把 vxlan 包中第一个字节从 0x08 改为 0x88
rust
const FAKE_VXLAN_FLAG_BYTE: u8 = 0x88;
const REAL_VXLAN_FLAG_BYTE: u8 = 0x08;
#[classifier]
pub fn tc_egress(ctx: TcContext) -> i32 {
let _ = try_tc_egress(ctx);
TC_ACT_PIPE
}
fn try_tc_egress(mut ctx: TcContext) -> Result<(), ()> {
let first_byte: u8 = get_vxlan_flag(&ctx)?;
if first_byte != REAL_VXLAN_FLAG_BYTE {
return Ok(());
}
if let Err(err) = ctx.store(PAYLOAD_OFFSET, &FAKE_VXLAN_FLAG_BYTE, 0u64) {
info!(&ctx, "try_tc_egress bpf_skb_store_bytes failed");
return Err(());
}
Ok(())
}
fn get_vxlan_flag(ctx: &TcContext) -> Result<u8, ()> {
let eth_hdr: EthHdr = ctx.load(0).map_err(|_| ())?;
let eth_type = eth_hdr.ether_type;
if eth_type != EtherType::Ipv4 {
return Err(());
}
// load the IPv4 header
let ipv4hdr: Ipv4Hdr = ctx.load(EthHdr::LEN).map_err(|_| ())?;
if ipv4hdr.proto != IpProto::Udp {
return Err(());
}
// load the UDP header
let udp_hdr: UdpHdr = ctx.load(EthHdr::LEN + Ipv4Hdr::LEN).map_err(|_| ())?;
// check if the destination port is VXLAN
let dst_port = u16::from_be(udp_hdr.dest);
if dst_port != VXLAN_PORT {
return Err(());
}
// load vxlan flag byte
let first_byte: u8 = ctx.load(PAYLOAD_OFFSET).map_err(|_| ())?;
Ok(first_byte)
}ingress 流量处理是完全一样的,把 0x88 改为 0x80
rust
fn try_tc_ingress(mut ctx: TcContext) -> Result<(), ()> {
let first_byte: u8 = get_vxlan_flag(&ctx)?;
if first_byte != FAKE_VXLAN_FLAG_BYTE {
return Ok(());
}
if let Err(err) = ctx.store(PAYLOAD_OFFSET, &REAL_VXLAN_FLAG_BYTE, 0u64) {
info!(&ctx, "try_tc_ingress store failed");
return Err(());
}
if let Err(err) = ctx.l4_csum_replace(UDP_CSUM_OFF as usize, FAKE_VXLAN_FLAG_BYTE as u64,
REAL_VXLAN_FLAG_BYTE as u64, 2) {
info!(&ctx, "try_tc_ingress bpf_l4_csum_replace failed");
return Err(());
}
Ok(())
}userspace 的程序比较简单,就是挂载 bpf 程序,精简的逻辑如下:
rust
#[tokio::main]
async fn main() -> anyhow::Result<()> {
let bpf_dir = std::env::var("BPF_DIR").unwrap_or("/tmp".to_string());
let Opt { iface } = opt;
let bpf_path = format!("{}/{}", bpf_dir, "vxlan-hack-tc-ebpf");
let bpf_data = std::fs::read(bpf_path).unwrap();;
let mut ebpf = aya::Ebpf::load(&bpf_data[..])?;
BpfLogger::init(&mut ebpf);
let _ = tc::qdisc_add_clsact(&iface);
let program: &mut SchedClassifier =
ebpf.program_mut("tc_egress").unwrap().try_into()?;
program.load()?;
program.attach(&iface, TcAttachType::Egress)?;
let ingress_program: &mut SchedClassifier =
ebpf.program_mut("tc_ingress").unwrap().try_into()?;
ingress_program.load()?;
ingress_program.attach(&iface, TcAttachType::Ingress)?;
let ctrl_c = signal::ctrl_c();
println!("Waiting for Ctrl-C...");
ctrl_c.await?;
Ok(())
}这样在两个机器上运行这个 bpf 程序,我们可以看到两个 pod 可以正常通信了。
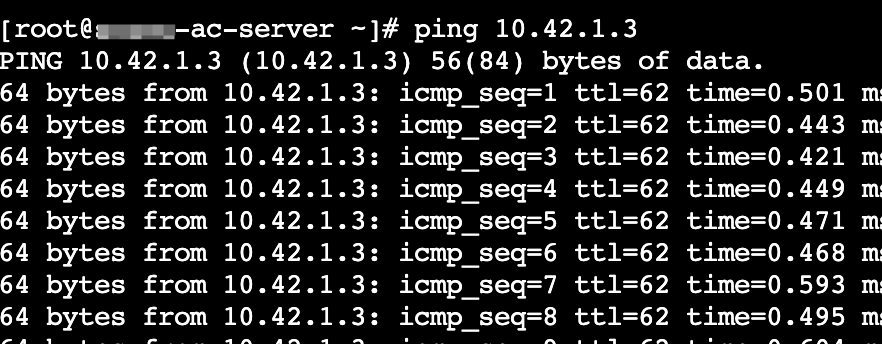
这里其实有一个坑,就是更新了 udp 包以后需要更新它的 checksum,不然可能会被操作系统处理时丢弃掉。 
在没有做 chucksum 更新时,通信异常,而且 netstat 的 InCsumErrors 值持续增长。
markdown
# netstat -s | grep InCsumErrors
InCsumErrors: 46668以下面收到的包(ingress)为例
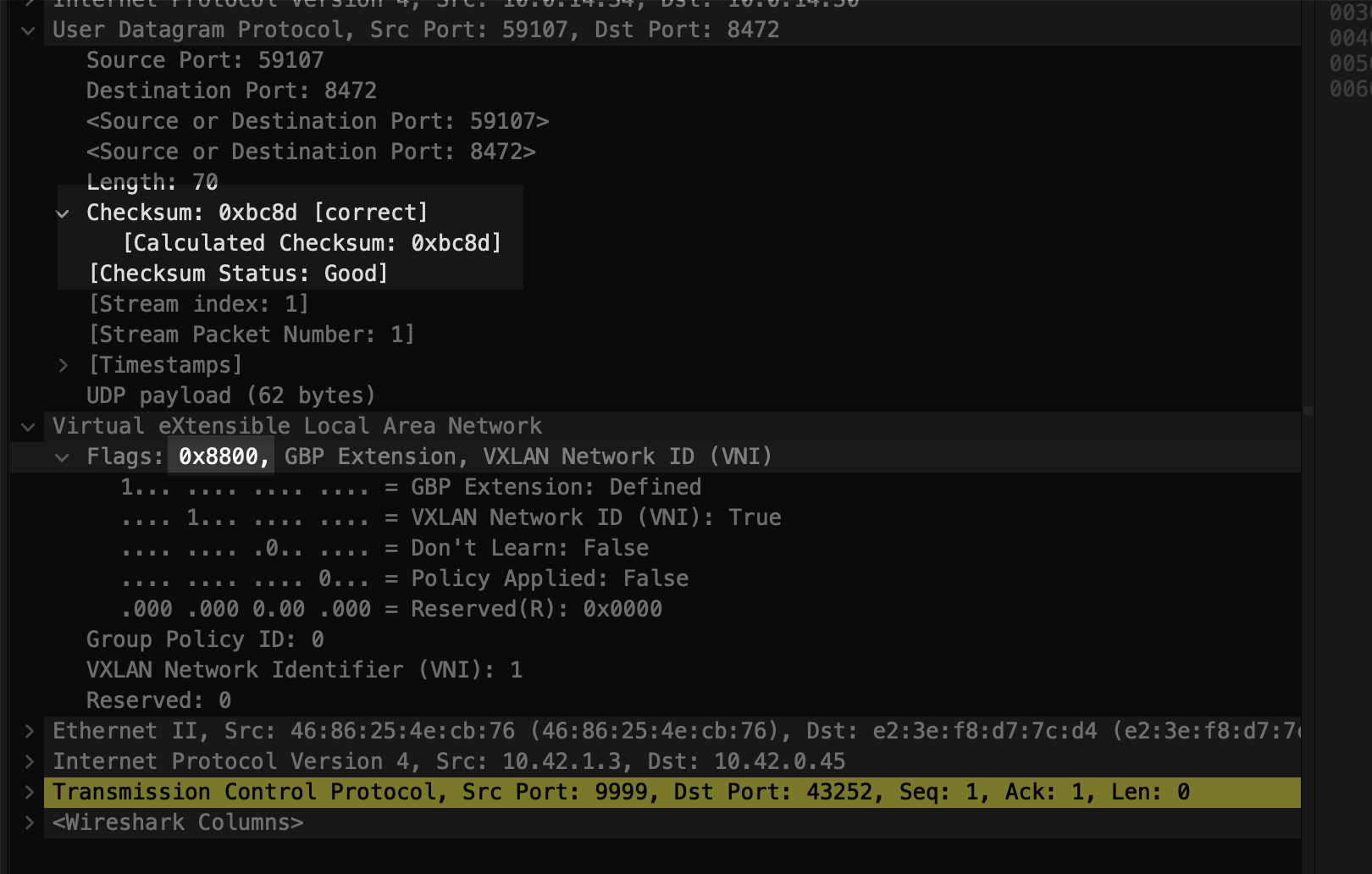
可以看到这个包的 checksum 为 0xbc8d,vxlan 的 header 位 0x88。
如果把 flag 改为 0x08,这对应的 checksum 应该为 0x3c8e,手动计算的代码如下:
rust
let payload = [
//vxlan header
0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0xe2, 0x3e, 0xf8, 0xd7, 0x7c, 0xd4, 0x46, 0x86,
0x25, 0x4e, 0xcb, 0x76, 0x08, 0x00,
0x45, 0x00, 0x00, 0x28, 0x00, 0x00, 0x40, 0x00,
0x3f, 0x06, 0x26, 0x4d, 0x0a, 0x2a, 0x01, 0x03,
0x0a, 0x2a, 0x00, 0x2d,
0x27, 0x0f, 0xa8, 0xf4, 0x00, 0x00, 0x00, 0x00,
0x03, 0xc4, 0x8f, 0x50, 0x50, 0x14, 0x00, 0x00,
0x37, 0x35, 0x00, 0x00
];
let mut buffer = vec![0u8; 1500];
let udp_packet_size = udp::MutableUdpPacket::minimum_packet_size() + payload.len();
let mut udp_packet = MutableUdpPacket::new(&mut buffer[..udp_packet_size]).unwrap();
udp_packet.set_source(59107);
udp_packet.set_destination(8472);
udp_packet.set_payload(&payload);
udp_packet.set_checksum(0);
udp_packet.set_length(payload.len() as u16 + 8);
let udp_packet = udp_packet.consume_to_immutable();
let checksum = ipv4_checksum(&udp_packet,
&Ipv4Addr::from_str("10.0.14.34").unwrap(),
&Ipv4Addr::from_str("10.0.14.30").unwrap(),
);
println!("checksum: 0x{:x}", checksum);我们需要使用 bpf 的 bpf_l4_csum_replace 更新 udp 的 checksum 字段,这样改过的 udp 包就可以正常被操作系统接收了。
那发出去的包(egress 包)我们需要手动更新 checksum 吗?egress 的包可以不用更新checksum,在包发出去之前,由硬件 NIC 重新计算。
小结
bpf 是一个好东西