本文来源: 《华为云 DTSE 》第五期开源专刊, **作者:**向宇,华为云数据库高级研发工程师、黄飞腾,博士,openGemini存储引擎架构师
在时序数据场景中,大部分的解决方案是以时间线为粒度对时序数据进行管理,这类解决方案在时间线数量不断增长的情形下,面临着诸多困难,包括内存膨胀、读写性能下降等,华为云开源时序数据库openGemini 针对该场景,提出了全新的列存引擎(HSCE),以解决海量时间线所带来的问题。
高基数问题长期困扰时序数据库
时序数据是一种常见的数据类型,广泛应用于车联网、工业物联网、航空航天、电力、DevOps 等领域。这类场景需要衡量事物状态随时间的变化,以便进行监控、分析和预测。例如,在DevOps中,我们需要监控服务的并发请求量;在工业物联网中,我们需要监控设备运行状态。鉴于时序数据产生频繁,且数据量很大,时序业务对实时性和查询效率要求高,通常会使用时序数据库对数据进行管理。
但在实际应用场景中,我们发现随着设备(例如车辆、终端设备等)数量达到一定量级后,时序数据库的读写性能会有明显的下降,延时波动剧烈,通过升级机器规格也无明显提升。导致这一现象的原因是海量时间线 带来的高基数问题。
什么是时间线?
在时序数据库中,时间线是对时间序列数据的建模,一条时间线的数据指同一数据源产生的一系列数据点的集合,可以简单理解为一台设备或者一辆车就是一条时间线。举个例子,有如下6条时序数据,由标签(A、B)、指标(C)和时间戳(Timestamp)组成。
A="a1",B="b1" C=2.82 1566000000
A="a2",B="b1" C=10.72 1566000000
A="a1",B="b2" C=15.82 1566000000
A="a1",B="b2" C=23.72 1568600000
A="a2",B="b3" C=1.36 1567000000
A="a2",B="b4" C=9.77 1568000000存在5条时间线,分别是
A="a1",B="b1"
A="a1",B="b2"
A="a2",B="b1"
A="a2",B="b3"
A="a2",B="b4"什么是高基数问题(High Cardinality)?
在数据库中,基数是指数据库的特定列或字段中包含的唯一值的数量。时间序列数据往往包含描述该数据的元数据(习惯称为"标签 或 TAG")。通常,主要时间序列数据或元数据会被索引,以提高查询性能,以便使用者可以快速找到与之匹配的所有值。时间序列数据集的基数通常由每个单独索引列的基数的交叉乘积定义。如果有多个索引列,每个列都有大量唯一值,那么交叉乘积的基数可能会变得非常大。这就是软件开发人员在谈论具有"高基数"的时间序列数据集时通常的意思。
比如,以智能电表为例,它会关联设备 ID、城市 ID、厂商 ID 和模型 ID 等标签。几百个城市,百万级设备,再加上不同的厂商、模型,基数轻松超过百亿级。再比如,以网络监控为例,记录访问源到目的端经过的链路,它会关联源IP、目的IP、运营商、路由设备IP等标签,上百万IP地址产生大量链路信息,基数很容易达到千亿。
高基数问题根因在于时间线的倒排索引膨胀
倒排索引是时序数据库常用的一种索引技术,主要记录TAG和时间线之间的对应关系,给定一个或多个TAG,就可以快速找到相关的时间线,从而实现数据过滤,提升数据检索效率。
以如下数据为例
A="a1",B="b1" C=2.82 1566000000
A="a2",B="b1" C=10.72 1566000000
A="a1",B="b2" C=15.82 1566000000
A="a1",B="b2" C=23.72 1568600000
A="a2",B="b3" C=1.36 1567000000
A="a2",B="b4" C=9.77 1568000000时序数据库中倒排索引的组织方式如下图所示:
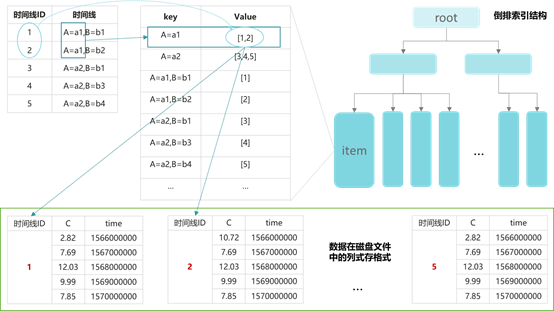
现有大部分时序数据管理解决方案,通常会将数据按照时间线(即标签值的组合)进行聚簇,时间线相同的数据再按照时间进行排序,同时构建了标签(A)+标签值(如a1)到时间线的倒排索引,这种存储方式在时间线数量相对有限的情形下,可以提供极致的写入与查询性能,但是在处理高基数场景时,例如图中的A和B两个标签列下各有数百万不同值,那么总体时间线数量巨大,由于倒排索引与时间线数量相关,索引项激增,会导致内存膨胀、读写性能下降等问题。
高基数问题的解决方案剖析
高基数问题的核心在于优化索引结构,以提高索引的检索效率并减少内存占用。目前,稀疏索引被认为是一种高效的解决方案。ClickHouse数据库提供了一个实际的应用案例,用于我们研究这一问题。
Clickhouse在时序场景下存在局限性
以ClickHouse为例,分析其稀疏索引结构。
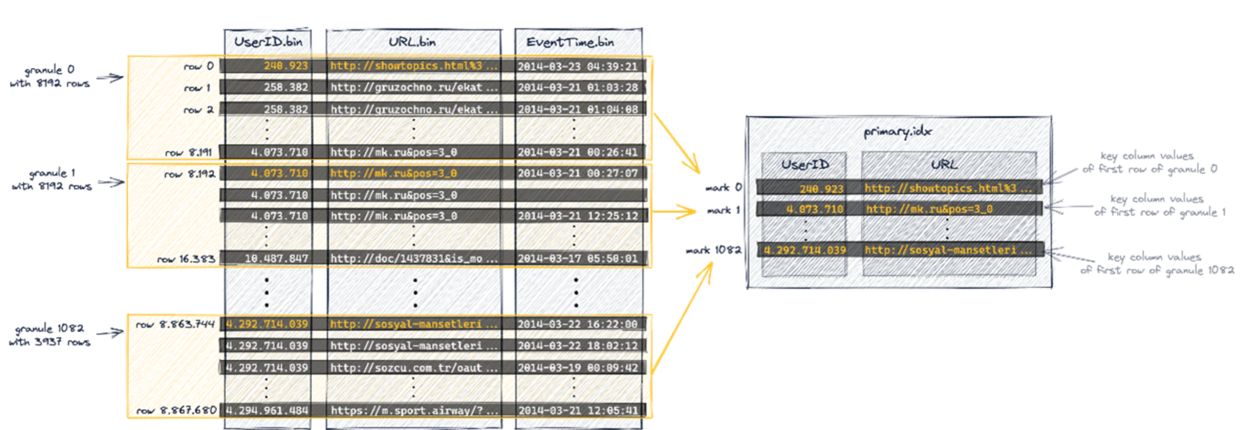
ClickHouse的稀疏索引不是为每一行数据创建一个索引条目,而是为一组数据行Granular(称为颗粒)构建一个索引条目。上图显示了官方如何将表中的887万行(列值)组织成1083个颗粒,每个颗粒对应主索引的一个条目,主索引被用来选择颗粒,就可以在主索引的支持下执行查询。
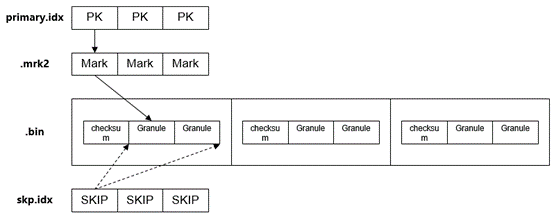
primary.idx 作为主键(稀疏)索引,可以用以加速查询,mrk2 文件作用类似主键索引,用于定位特定 column(bin文件) 对应的主键行所在的位置。
虽然ClickHouse的稀疏索引特别适用于处理大规模数据集,但ClickHouse数据库可能并不总是最适合时序数据的场景。例如,时序数据通常需要对时间序列进行特定的优化,如时间序列索引、窗口函数和时间序列聚合,这些可能在ClickHouse中不如专门的时序数据库那样得到优化。此外,时序数据的写入模式可能与ClickHouse的优化方向不完全一致,特别是在需要高吞吐量写入时。
openGemini结合了AP数据库优势与时序数据库特性,更加平衡高效
尽管如此,ClickHouse的稀疏索引技术仍然值得借鉴。通过将这种技术应用于时序数据库,可以更有效地管理时间线数据,减少内存空间的使用,同时保持快速的查询性能。因此,在openGemini在解决高基数问题时,考虑结合AP数据库的优势和专门的时序数据库特性,提供一个更加平衡和高效的解决方案。
openGemini 列存引擎解决该问题的核心思路主要包括:
-
调整数据排序与索引方式:不再维护与时间线的关系,而是通过设置排序键对数据进行排序,在此基础上,将数据按列存储,并构建稀疏的聚簇索引,以支持数据的过滤查询。
-
量化操作降低高基数列的基数:针对高基数列进行量化,以降低基数,这样可以进一步提高数据的局部有序性,提升索引的查询过滤效果。
-
兼容 Apache Arrow Flight 协议:Apache Arrow Flight 是一种列式数据传输协议,可以实现高效的数据传输和写入。openGemini 利用该协议,消除了数据在写入流程中的转换开销,从而提升了数据写入性能。

假设有如下数据:
其中 A、C的基数较低,同时大部分查询需要对 A、C、Time 等列进行过滤,那么可以考虑将排序键设置为 A, C, Time 等,数据按照排序键排序之后变成:
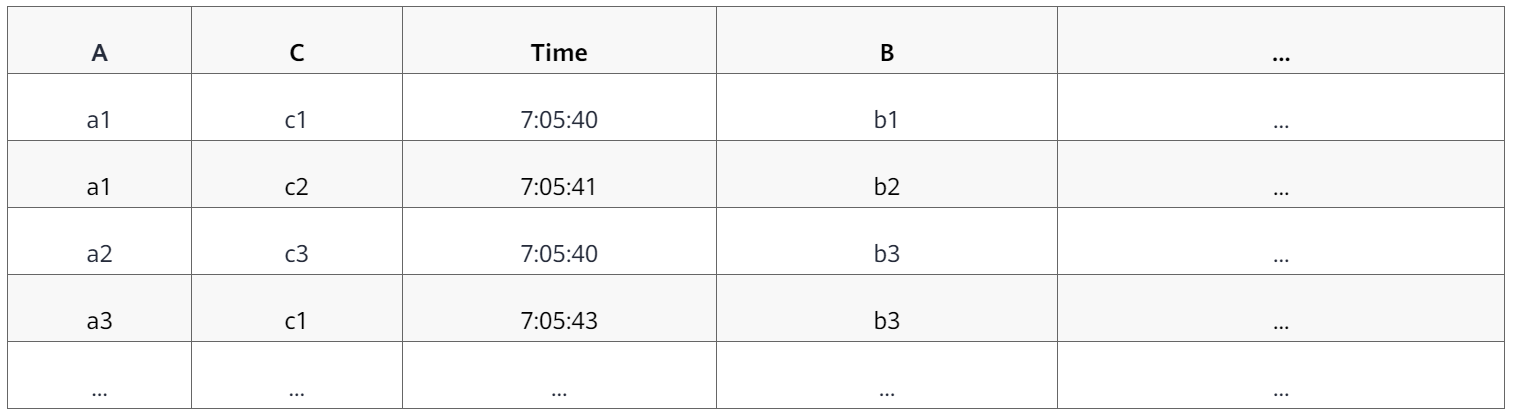
排序完成之后,将数据按列存储,存储时以若干行(如 8192 行)为一个 Block 进行数据压缩并序列化,在此基础上,选取每个 Block 的第一条记录构建稀疏的聚簇索引。
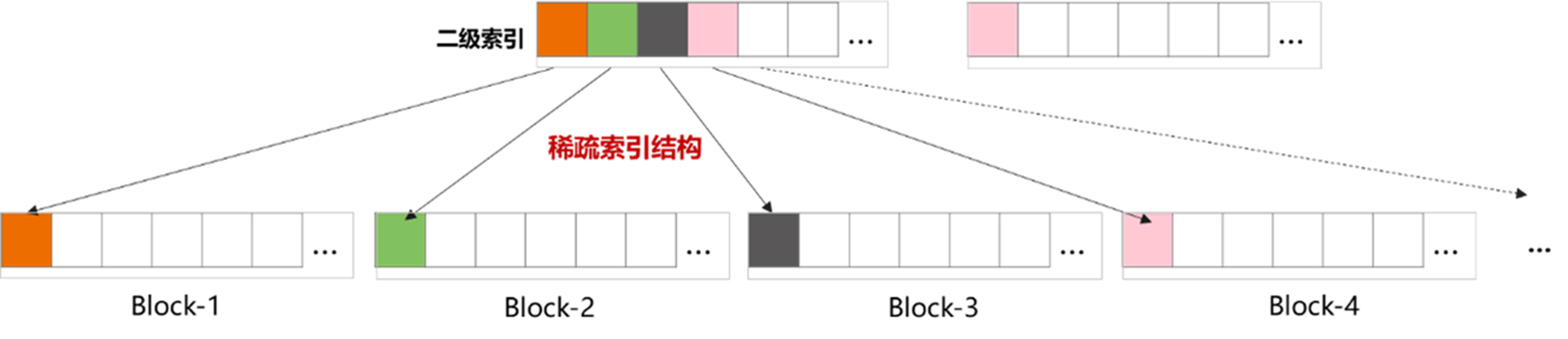
可以看到,按照这种方式组织数据,位于第一个排序键的列是整体有序的,位于其他位置的排序键则是局部有序的,因此如果将低基数列放在排序键的前面,则可以使得数据的局部有序性更好,在此基础上,上述的稀疏聚簇索引就可以较好反映若干行或者一个 Block 的数据范围,进而有效支持数据过滤。
考虑到如果有多个列都包含有高基列,那么无论如何选择排序键,数据的有序性可能都不会特别理想,在这种情况下,可以考虑对其中部分高基列进行量化操作,降低该列的基数,以时间列为例,假设原始数据是以秒级进行采用生成的,那么即使仅考虑一个小时内的数据,时间列的基数都可能是数以千计,如果将时间列进行量化,使其对齐到小时粒度,那么这一个小时内的时间列基数就会降到1或者2,在这一基础上,使用量化过的时间列进行排序,无论将时间列放在排序键的哪个位置,都不会使得数据有序性劣化。同理,可以对需要排序的列进行类似的量化操作,这样就可以保证数据的整体有序性。
总体而言,openGemini 通过上述数据排序与索引方式,可以保证索引的构建不受时间线的影响, 同时数据的有序性也可以保证索引的查询过滤效果。同时在此基础上, openGemini 也通过兼容 Apache Arrow Flight 协议,一种列式数据传输协议,消除了数据在写入流程中的转换开销,极大提升了数据写入性能。
openGemini在华为云网络运维业务的实践
华为云网络运维服务的核心是基于广域网运维业务场景,提供基于运维诉求的测量数据,包括真实业务流RTT时延、丢包率、异常测量指标等,以实现对网络带宽的精准测量和实时分析。
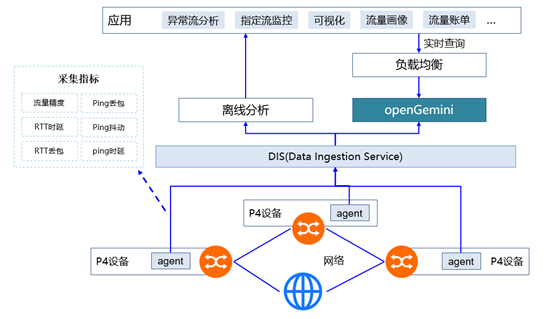
华为云网络运维业务是一个典型的高基数场景,具有千亿级时间线规模。业务通过Agent采集通过设备的实时流量、实时流源目的地址、RTT时延等信息,以方便平台进行异常流分析、数据可视化分析等。
openGemini列存引擎(HCSE)成功解决了网络数据的高基数问题,为平台构筑了海量网流实时数据存储底座,相比原有解决方案,实现了端到端成本降低60%。数据处理吞吐量提升6+倍,数据分析性能(如Group By分组聚合分析)提升10+倍。
总结和展望
openGemini 通过引入新的数据排序与索引方式,开发了全新列存引擎,以解决海量时间线场景对于现有时序数据管理方案带来的问题。通过调整数据排序与索引方式,采用量化操作降低高基数列的基数,以及兼容 Apache Arrow Flight 协议等措施,成功解决了海量时间线数据管理中的内存膨胀、索引构建成本高等问题。这一创新提高了数据管理的效率和性能,为时序数据应用场景带来了新的解决方案。
通过全新列存引擎以及已有的时序引擎,openGemini 可以很好解决不同场景下的指标数据管理问题,未来 openGemini 还会针对日志、调用链等数据提供存储解决方案,以实现对可观测性数据的统一管理,为上层应用实现可观测性提供一个统一存储底座。
华为开发者空间是为全球开发者打造的专属开发者空间,致力于为每位开发者提供一台云主机、一套开发工具和云上存储空间。汇聚昇腾、鸿蒙、鲲鹏、GaussDB、欧拉等各项根技术的开发资源及工具,总有一款适合你! 点击链接:领取您的专属开发者云主机!