ClickHouse作为高性能列式存储数据库,其引擎机制是实现高效数据存储与查询的核心。本文将从库引擎、合并树表引擎系列到其他常用表引擎,结合实操案例,带你全面掌握ClickHouse引擎的特性与应用场景。
一、库引擎:数据库级别的存储与交互规则
库引擎定义了ClickHouse数据库的基础行为,包括数据存储方式、跨系统交互逻辑等。ClickHouse默认使用Atomic库引擎,同时支持多种对接外部数据库的引擎,以下是核心库引擎的详细说明。
1.1 核心库引擎特性总览
| 库引擎 | 核心特点 |
|---|---|
| Atomic库引擎 | 支持非阻塞的drop tables和rename table操作,ClickHouse默认库引擎 |
| MySQL库引擎 | 映射远程MySQL表,查询自动转为MySQL语法并转发,不存储本地数据 |
| MaterializedMySQL库引擎 | 作为MySQL副本,读取binlog同步DDL/DML(实验版本,不建议生产使用) |
| Lazy库引擎 | 数据仅在内存保留指定时间(如日志表场景) |
| SQLite/PostgreSQL库引擎 | 分别对接SQLite/PostgreSQL数据库,支持双向数据交换 |
| Replicated库引擎 | 基于Atomic引擎,通过ZooKeeper同步DDL日志,实现数据库元数据副本一致性 |
1.2 重点库引擎实操案例
1.2.1 MySQL库引擎:实时对接MySQL数据
MySQL库引擎适用于需实时查询MySQL数据,但无需本地存储的场景。其核心逻辑是"查询转发",所有数据仍存于MySQL,ClickHouse仅作为查询入口。
实操步骤:
-
MySQL端准备:创建测试库表与授权用户
sql-- 1.创建测试库表 create database test01; create table test01.t1( `id` int NOT NULL AUTO_INCREMENT, `a` int DEFAULT NULL, `b` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; -- 插入测试数据 insert into test01.t1(a,b) values (1,1),(2,2); -- 2.创建ClickHouse访问用户 create user 'test01_rw'@'192.168.%' identified with mysql_native_password by 'Idy8Gda6Q^d'; grant all on test01.* to 'test01_rw'@'192.168.%'; -
ClickHouse端创建MySQL引擎库
sql-- 登录ClickHouse(-m支持多命令输入) clickhouse-client -m -- 创建MySQL引擎库,指定MySQL地址、库名、用户名、密码 create database mysql_test engine=MySQL('192.168.12.161:3306','test01','test01_rw','Idy8Gda6Q^d');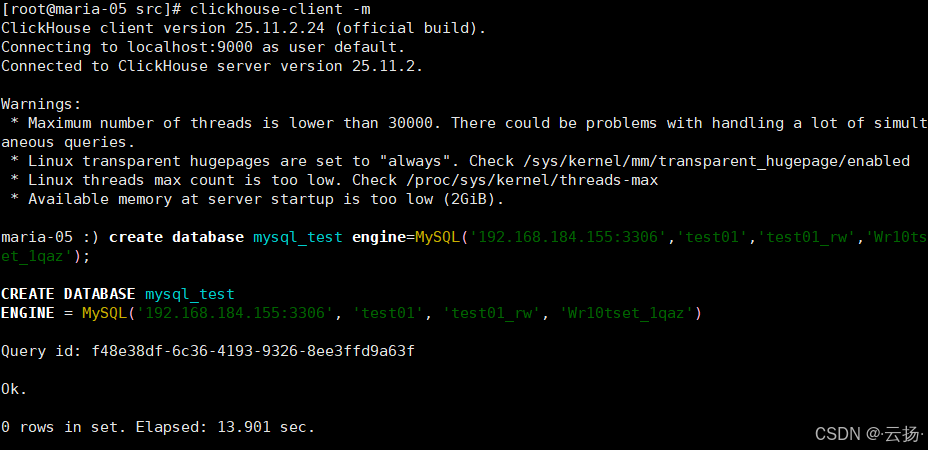
-
验证数据查询
sql-- 切换到MySQL引擎库 use mysql_test; -- 查看MySQL中的表 show tables; -- 查询MySQL表数据(结果与MySQL实时同步) select * from t1;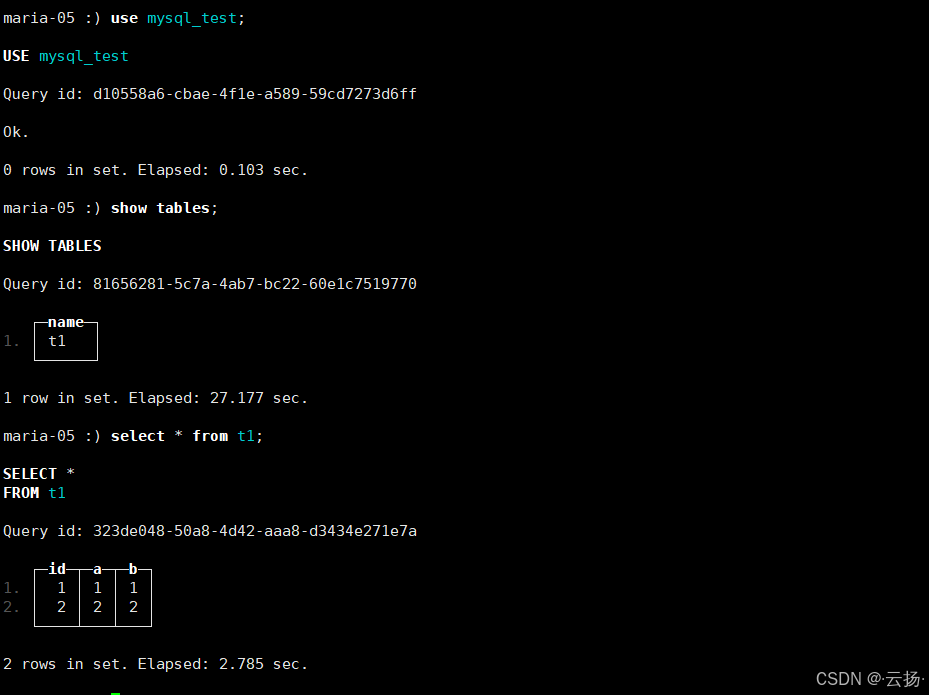
注意事项:MySQL库引擎不存储本地数据,若需将数据落地ClickHouse,需搭配"物化视图"使用。
1.2.2 MaterializedMySQL库引擎:同步MySQL数据到本地
该引擎将ClickHouse作为MySQL副本,通过读取MySQL的binlog同步数据(实验版本),适合需本地存储MySQL同步数据的场景。
关键前提:MySQL需开启GTID与原生密码认证
-
查看MySQL参数配置
sqlshow global variables like "%auth%"; show global variables like "%gtid_mode%"; show global variables like "%enforce_gtid%";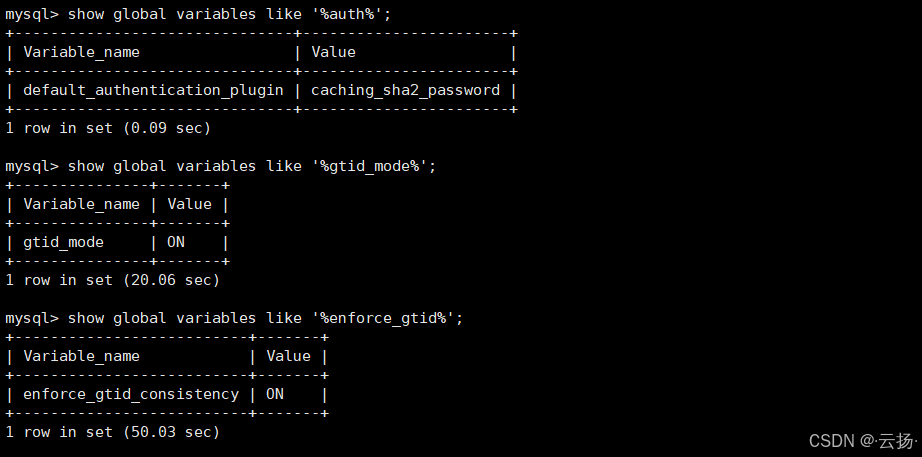
-
修改MySQL配置
sql-- 编辑MySQL配置文件 vim /data/mysql/conf/my.cnf -- 添加以下参数 default_authentication_plugin = mysql_native_password # 原生密码认证 gtid_mode = on # 开启GTID enforce_gtid_consistency = on # 强制GTID一致性 -- 重启MySQL /etc/init.d/mysql.server restart -
MySQL端准备测试数据
sql-- 创建测试库表test02.t2,并插入测试数据 create database test02; create table test02.t2( `id` int NOT NULL AUTO_INCREMENT, `a` int DEFAULT NULL, `b` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into test02.t2(a,b) values (1,1); -- 创建测试用户test02_rw并授予权限 create user 'test02_rw'@'192.168.%' identified with mysql_native_password by 'IdcaTa6Q^d'; grant all on *.* to 'test02_rw'@'192.168.%'; -
ClickHouse端开启并创建引擎库
sql-- 开启实验性引擎(临时生效) set allow_experimental_database_materialized_mysql = 1; -- 创建MaterializedMySQL引擎库 create database m_mysql_test engine=MaterializedMySQL('192.168.184.155:3306','test02','test02_rw','IdcaTa6Q^d'); -
验证数据同步
sql-- MySQL端插入增量数据 insert into test02.t2(a,b) values (2,2); -- ClickHouse端查询同步结果 select * from m_mysql_test.t2; -- 可看到新增数据
注意:MaterializedMySQL存储引擎是clickhouse的实验版本,最新的clickhouse可能会不支持该存储引擎,官方也不推荐在生产环境实验该存储引擎,了解即可。

二、表引擎:合并树引擎系列(高性能核心)
合并树(MergeTree)系列是ClickHouse最核心的表引擎,支持列式存储、分区、索引、数据合并等特性,是高负载场景(如大数据分析)的首选。
2.1 合并树引擎系列特性总览
| 表引擎 | 核心特点 |
|---|---|
| MergeTree | 单节点默认表引擎,支持分区、索引、数据压缩,无特殊数据处理逻辑 |
| ReplacingMergeTree | 基于MergeTree,合并时自动删除"相同排序键"的重复数据 |
| SummingMergeTree | 基于MergeTree,合并时将"相同主键"的行聚合,求和指定字段 |
2.2 重点合并树引擎实操案例
2.2.1 MergeTree:基础且高效的单节点表引擎
MergeTree是所有合并树引擎的基础,需指定排序键(ORDER BY) ,支持可选的分区键(PARTITION BY)与主键(PRIMARY KEY)。
实操步骤:
-
创建MergeTree表
sql-- 连接clickhouse客户端(-m表示允许多行查询,不加的话,默认就是一行表示一条命令。) clickhouse-client -m -- 创建数据库 create database maria; -- 创建MergeTree表(排序键必选,分区键可选) create table if not exists maria.user_info ( userid UInt64, -- 用户ID username String, -- 用户名 age int, -- 年龄 createtime DateTime -- 创建时间 ) ENGINE = MergeTree() ORDER BY (userid, username); -- 排序键(必选,决定数据排序与去重维度) -- 可选:添加分区键(如按创建时间分区) -- PARTITION BY toYYYYMM(createtime) -- 可选:添加主键,作用主要是为了加快查询速度,不要求主键具有唯一性。 -- PRIMARY KEY 主键 -
插入与查询数据
sql-- 插入测试数据 insert into maria.user_info values (1,'a',20,'2024-05-12 12:00:00'), (2,'b',22,'2024-05-12 13:00:00'); -- 查询数据 select * from maria.user_info;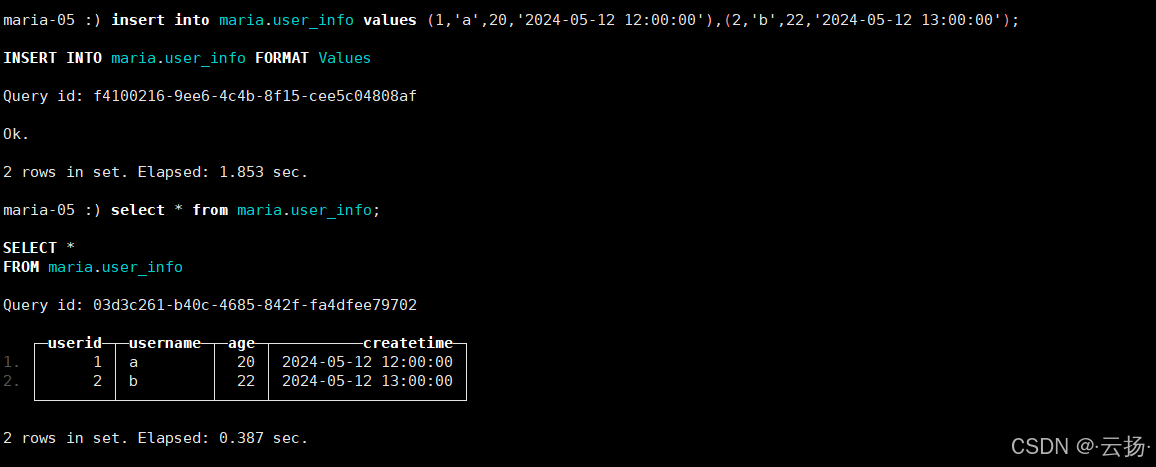
-
理解数据文件结构
查看表结构文件:
bashcd /var/bin/clickhouse/matedata/maria cat user_info.sql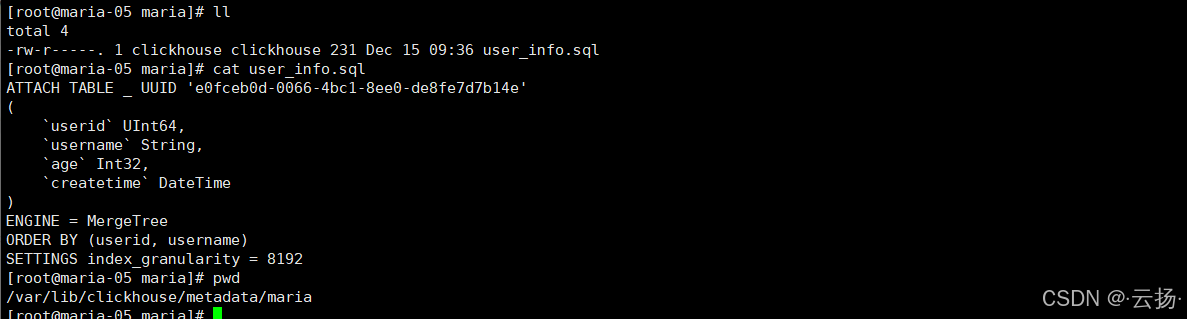
查看表数据文件:
bashcd /var/lib/clickhouse/data/maria/user_info/all_1_1_0/ ll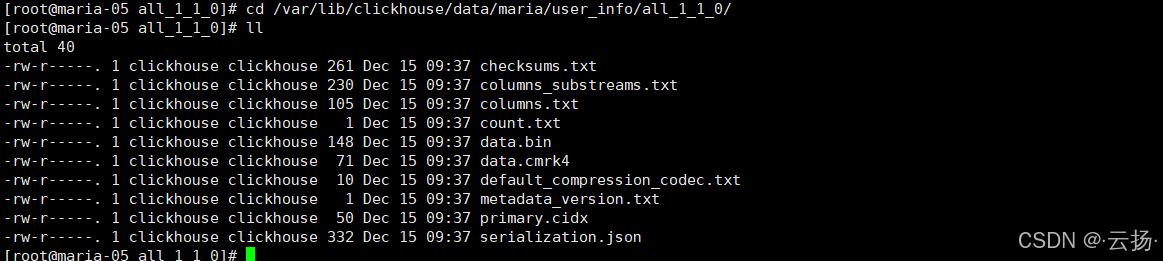
USER_INFO表核心文件及功能如下表:文件名 功能说明 checksums.txt 存储校验信息,用于验证数据完整性 columns.txt 列出表的所有字段 count.txt 记录表格数据量,支持快速获取统计信息 data.bin 实际存储表数据的文件,已压缩 data.cmrk3 存储data.bin文件的压缩标记 default_compression_codec.txt 记录表使用的默认压缩编解码器名称 metadata_version.txt 包含表的元数据版本信息 primary.cidx 存储表的主键索引 serialization.json 存储表数据的序列化细节(含数据写入/读取规则)
2.2.2 ReplacingMergeTree:自动去重的表引擎
ReplacingMergeTree在MergeTree基础上,通过"数据合并"阶段删除重复数据,去重维度由排序键(ORDER BY) 决定。
实操步骤:
-
创建ReplacingMergeTree表
sqlcreate table if not exists maria.user_info_01 ( userid UInt64, username String, age int, createtime DateTime ) ENGINE = ReplacingMergeTree() -- 无版本列时,保留最后一条重复数据 ORDER BY (userid, username); -- 按userid+username去重
-
验证去重逻辑
sql-- 插入重复数据(userid=1, username=a出现两次) insert into maria.user_info_01 values (1,'a',20,'2024-05-12 12:00:00'), (1,'a',30,'2024-05-12 12:00:00'); -- 查询:重复数据被删除(保留最后一条) select * from maria.user_info_01;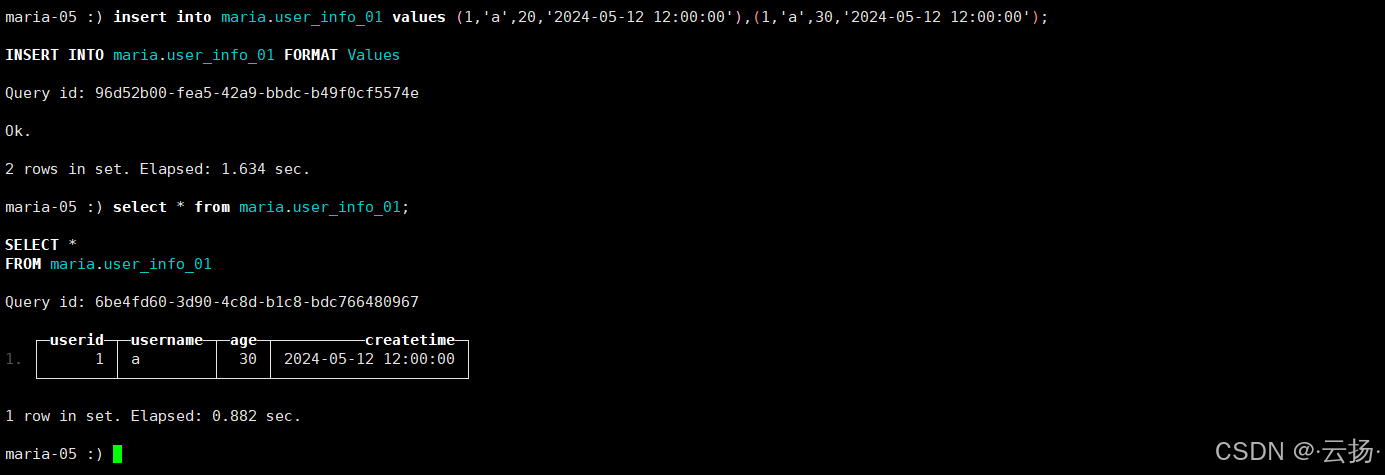
注意事项:按order by 排序键来进行去重,且仅对同一分区内的数据去重。
2.2.3 SummingMergeTree:自动聚合的表引擎
SummingMergeTree适用于"按维度聚合求和"场景(如统计用户总分),合并时将"相同排序键"的行聚合,求和指定字段。
实操步骤:
-
创建SummingMergeTree表
sqlcreate table if not exists maria.user_info_02 ( userid UInt64, username String, subject String, -- 科目 score int, -- 分数(需聚合的字段) createtime DateTime ) ENGINE = SummingMergeTree(score) -- 指定求和字段为score ORDER BY (userid, username); -- 按userid+username聚合
-
验证聚合逻辑
sql-- 插入用户分数数据 insert into maria.user_info_02 values (1,'a','one',91, '2024-05-12 12:00:00'), (1,'a','two',90, '2024-05-12 12:00:00'), (2,'b','one',88, '2024-05-12 12:00:00'), (2,'b','two',80, '2024-05-12 12:00:00'); -- 触发合并后查询:同一userid+username的score被求和 select * from maria.user_info_02;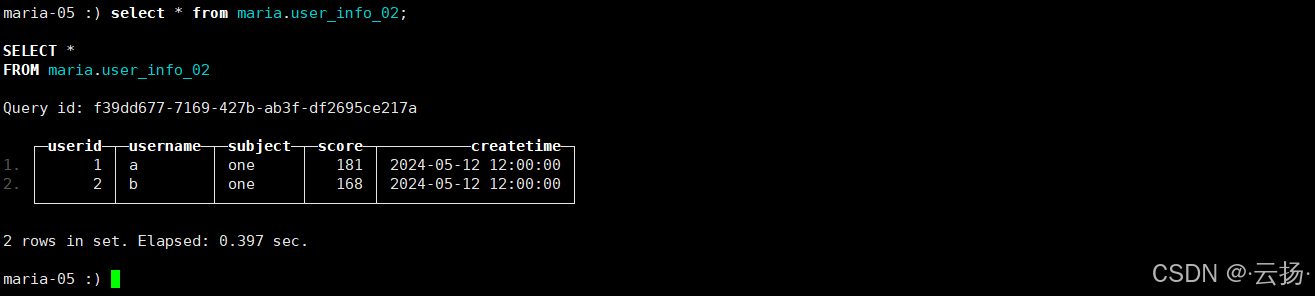
三、其他常用表引擎:适配特殊场景
除合并树系列外,ClickHouse还提供多种轻量级或跨系统表引擎,满足日志存储、外部系统对接、分布式查询等需求。
3.1 其他表引擎特性总览
| 表引擎 | 核心特点 |
|---|---|
| 日志引擎系列(如TinyLog) | 轻量级引擎,无索引,适合快速写入小表(如临时日志) |
| 集成引擎(如HDFS) | 对接外部存储系统(HDFS、S3等),直接读写外部数据 |
| MySQL表引擎 | 仅对接单张MySQL表(区别于MySQL库引擎),查询转发至MySQL |
| Distributed | 分布式表引擎,不存储数据,负责分发查询到多个节点,合并结果 |
3.2 重点表引擎实操:MySQL表引擎
MySQL表引擎与MySQL库引擎的核心区别是"粒度"------前者仅对接单张MySQL表,灵活性更高,是生产中对接MySQL的推荐方式。
实操步骤:
-
MySQL端准备:创建表与授权
sqlcreate database test03; create table test03.t3( `id` int NOT NULL AUTO_INCREMENT, `a` int DEFAULT NULL, `b` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into test03.t3(a,b) values (1,1); -- 创建授权用户 create user 'test03_rw'@'192.168.%' identified with mysql_native_password by 'Ra8Gda6Q^d'; grant all on test03.* to 'test03_rw'@'192.168.%';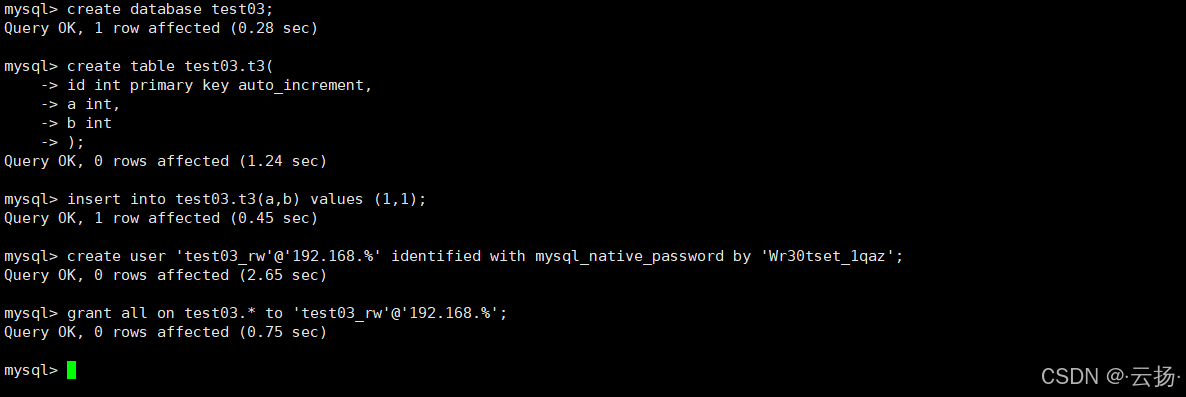
-
ClickHouse端创建MySQL表引擎表
sqlcreate table maria.t3 ( id int, a int, b int ) ENGINE = MySQL('192.168.184.155:3306', 'test03', 't3', 'test03_rw', 'Ra8Gda6Q^d');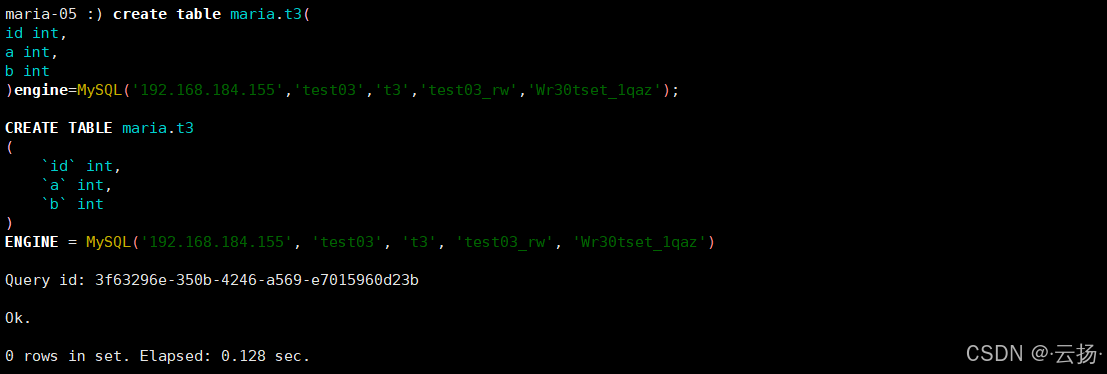
-
验证数据同步
sql-- MySQL插入增量数据 insert into test03.t3(a,b) values (2,2); -- ClickHouse查询(实时同步MySQL数据) select * from maria.t3;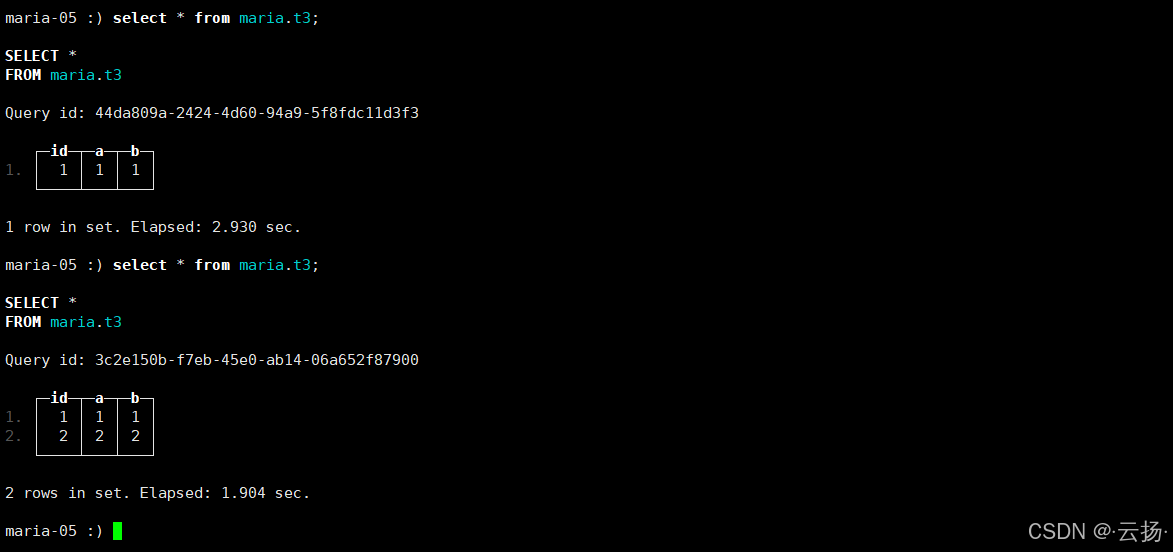
四、引擎选择总结
ClickHouse引擎的选择需结合业务场景,以下是核心建议:
- 单节点数据存储 :优先使用
MergeTree(基础)、ReplacingMergeTree(去重)、SummingMergeTree(聚合); - 对接外部数据库 :连MySQL用
MySQL表引擎(单表),连PostgreSQL/SQLite用对应库引擎; - 分布式场景 :用
Distributed表引擎分发查询,底层节点搭配合并树引擎存储数据; - 轻量临时表 :日志类小表用
TinyLog等日志引擎。
通过合理选择引擎,可充分发挥ClickHouse的高性能优势,满足不同业务的数据存储与查询需求。