在数字媒体技术日新月异的今天,视频处理已成为我们日常生活和工作中不可或缺的一部分。其中,视频人声分离技术凭借其独特的魅力和广泛的应用场景,逐渐走进了大众的视野。本文将深入探讨视频人声分离技术的原理、应用及其未来发展。

一、视频人声分离技术简介
视频人声分离,顾名思义,是指从视频文件中将人声与背景音乐或环境声等其他声音分离开来的技术。这一技术的实现,主要依赖于音频信号处理领域的深入研究和人工智能技术的快速发展。通过精确的算法,视频人声分离技术能够识别并提取出人声音频,同时保留或去除其他音频成分,从而满足用户在不同场景下的需求。

二、视频人声分离技术的应用场景
卡拉OK伴奏制作:对于卡拉OK爱好者来说,视频人声分离技术无疑是一大福音。通过这项技术,他们可以轻松去除原唱人声,获得纯净的伴奏音乐,从而尽情享受歌唱的乐趣。
1.音乐创作与改编:音乐制作人在创作或改编音乐作品时,经常需要提取出人声或伴奏部分进行单独处理。视频人声分离技术为他们提供了便捷的工具,有助于激发创作灵感。

2.短视频制作与编辑:在社交媒体平台上,短视频已成为人们分享生活的重要方式。利用视频人声分离技术,用户可以轻松实现人声和背景音乐的自定义搭配,创作出更具创意和个性的短视频内容。
3.版权保护与内容审核:在某些情况下,为了避免音乐版权纠纷或满足内容审核要求,需要对视频中的人声进行特殊处理。视频人声分离技术能够帮助实现这一目标,保护创作者的合法权益。
三、视频人声分离技术的实现原理
视频人声分离技术的实现主要依赖于音频信号处理和机器学习算法的结合。首先,系统会对视频文件中的音频信号进行采集和预处理,包括去除噪声和干扰等。接着,利用频谱分析等方法找出人声和背景音乐的频率特性差异。

在此基础上,采用数字滤波器、独立成分分析等技术手段对音频信号进行分离处理。最后,通过机器学习算法对分离结果进行优化和调整,确保提取出的人声音频质量上乘。
四、视频人声分离技术的操作实例
以易我人声分离这款可在线使用的AI人声分离工具为例,来给大家演示一下如何做到一键分离视频里的人声:
**步骤1.**访问并登录易我人声分离官网页面,选择"人声分离"功能。
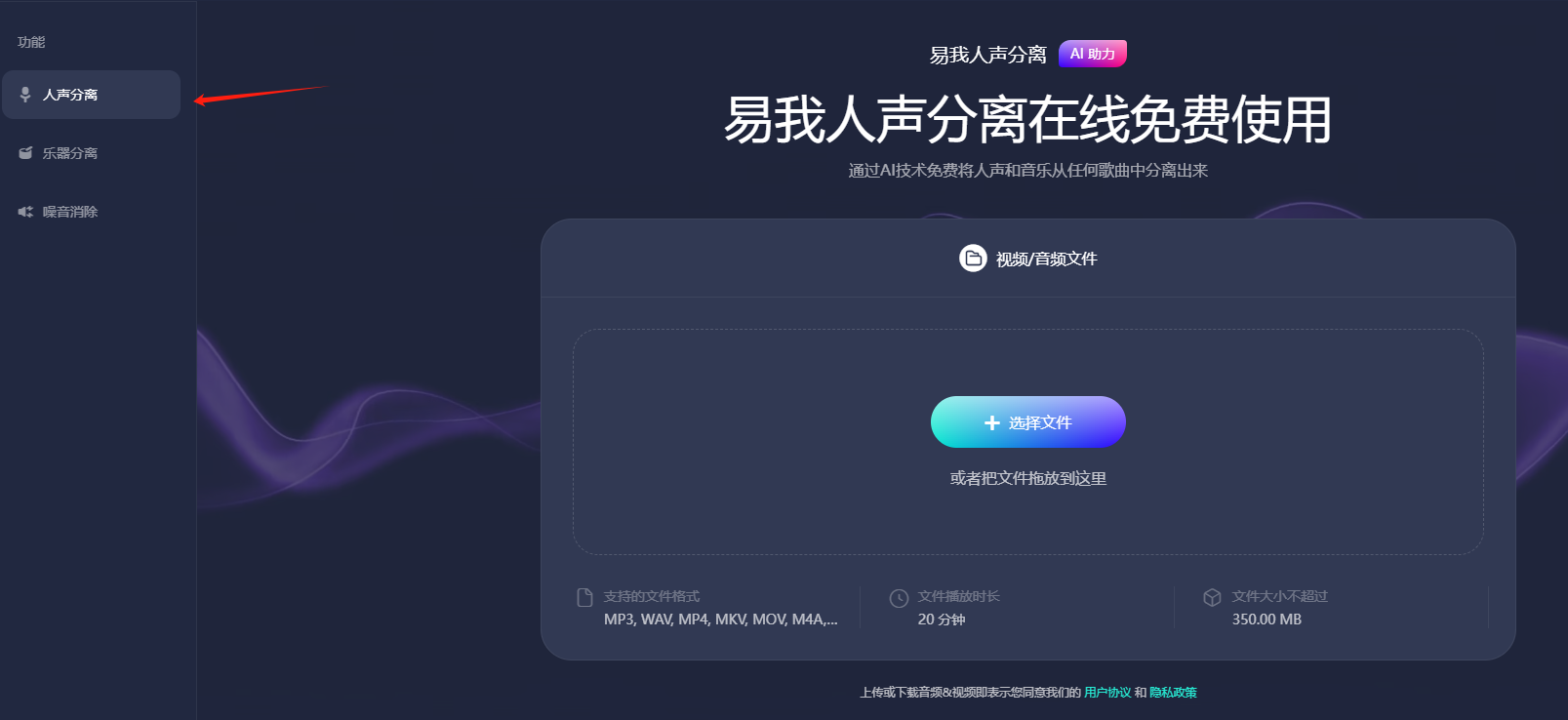
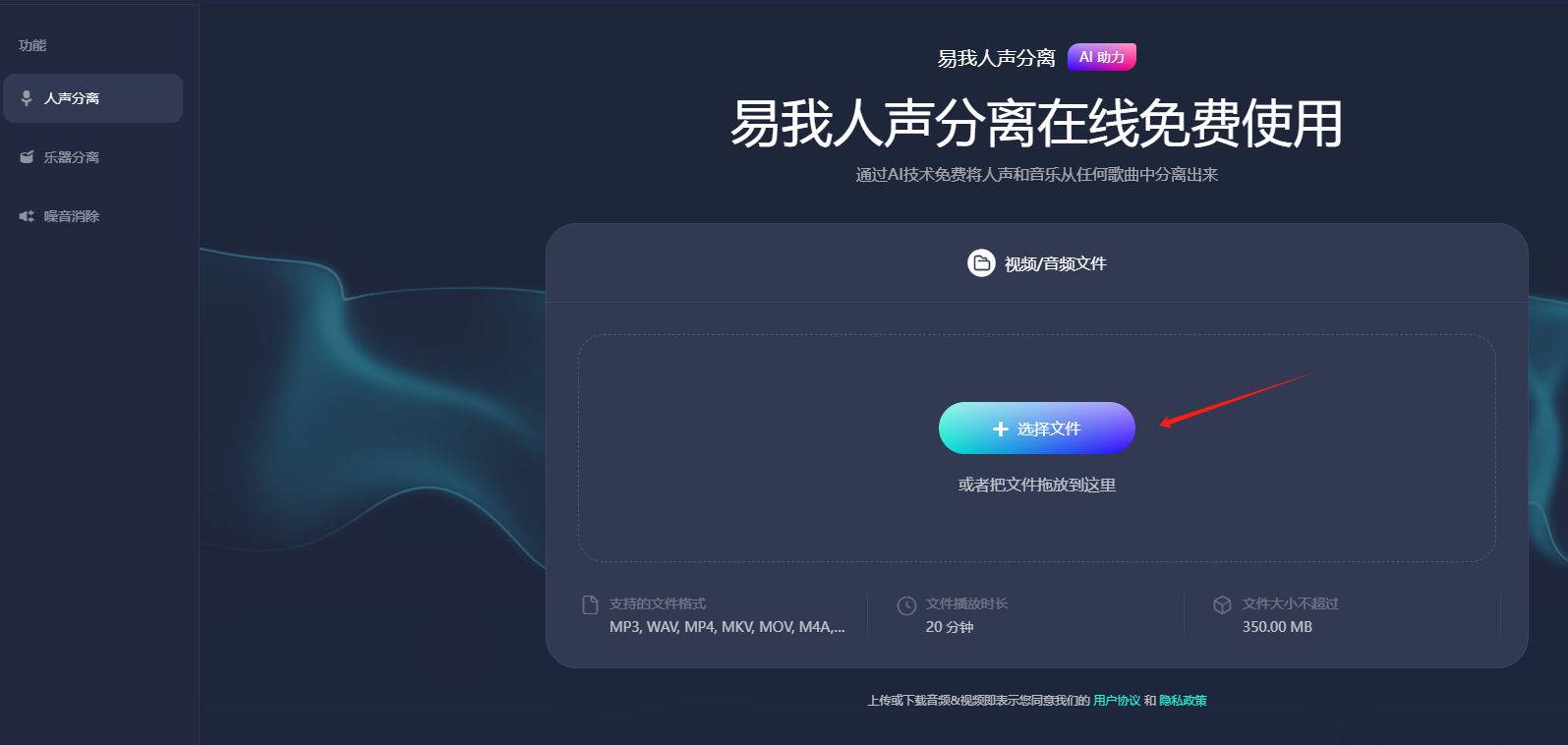
**步骤2.**点击"选择文件",把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。

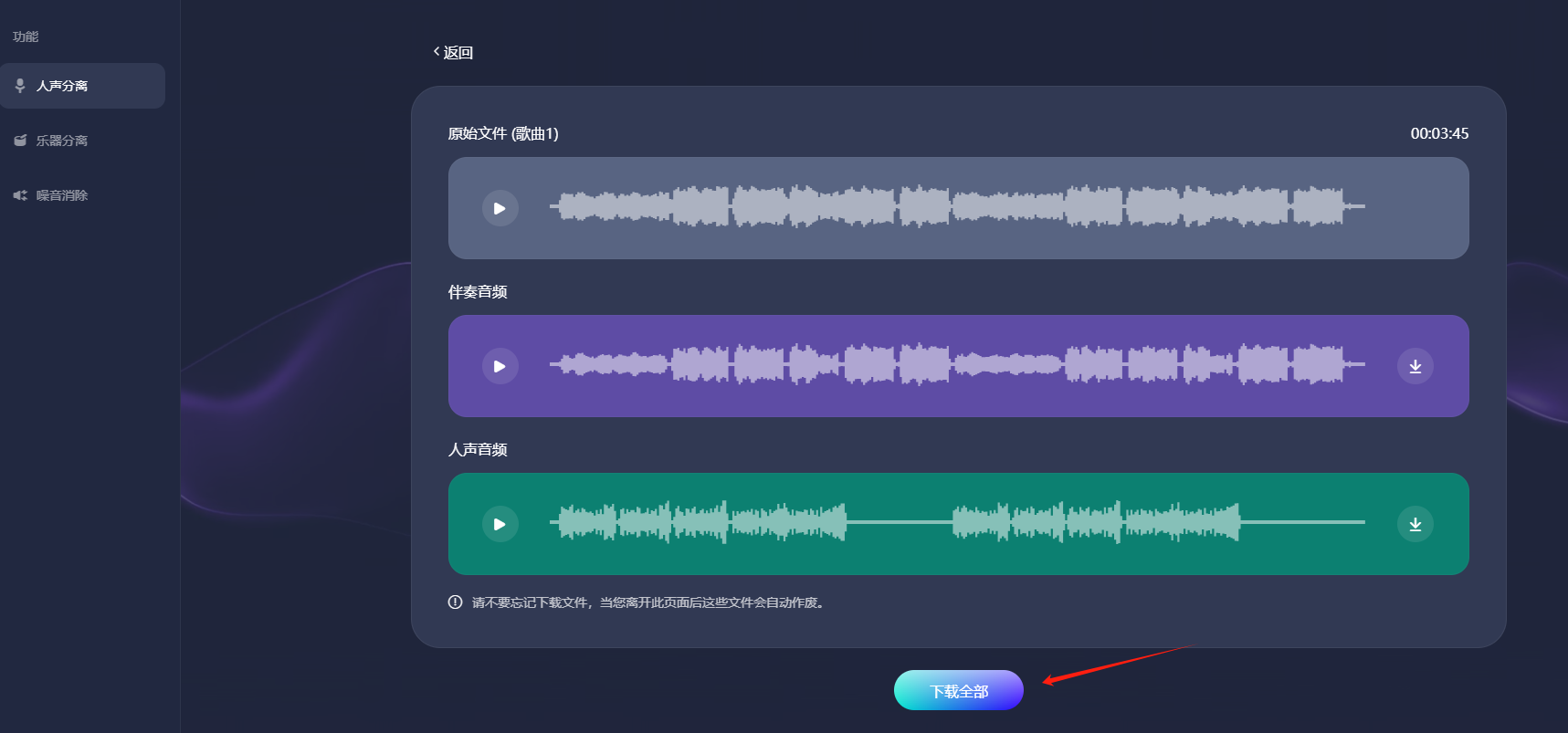
**步骤3.**AI处理完成后,会生成伴奏音频和人声音频,点击"下载全部"即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
五、视频人声分离技术的未来发展
随着人工智能技术的不断进步和音频信号处理领域的深入研究,视频人声分离技术有望在未来实现更高的分离精度和更广泛的应用场景拓展。
例如,在虚拟现实(VR)和增强现实(AR)领域,这项技术有望为用户提供更加沉浸式的音视频体验。同时,随着5G、6G等通信技术的普及,视频人声分离技术也将在云端处理、实时传输等方面展现出更大的潜力。

总之,视频人声分离技术以其独特的优势和广泛的应用前景,正逐渐改变着我们的数字媒体生活。未来,随着技术的不断进步和创新应用的涌现,我们有理由相信这项技术将在更多领域大放异彩。