本来这节内容是打算直接讲字节码指令的,但讲之前又必须得先讲指令集架构,而指令集架构又分为两种,一种是基于栈的,一种是基于寄存器的。
那不妨我们这节就单独来讲讲栈虚拟机和寄存器虚拟机,它们有什么不同,以及各自的优缺点。
栈和寄存器
关于栈这个数据结构,我们前面曾讲过,戳链接直达。
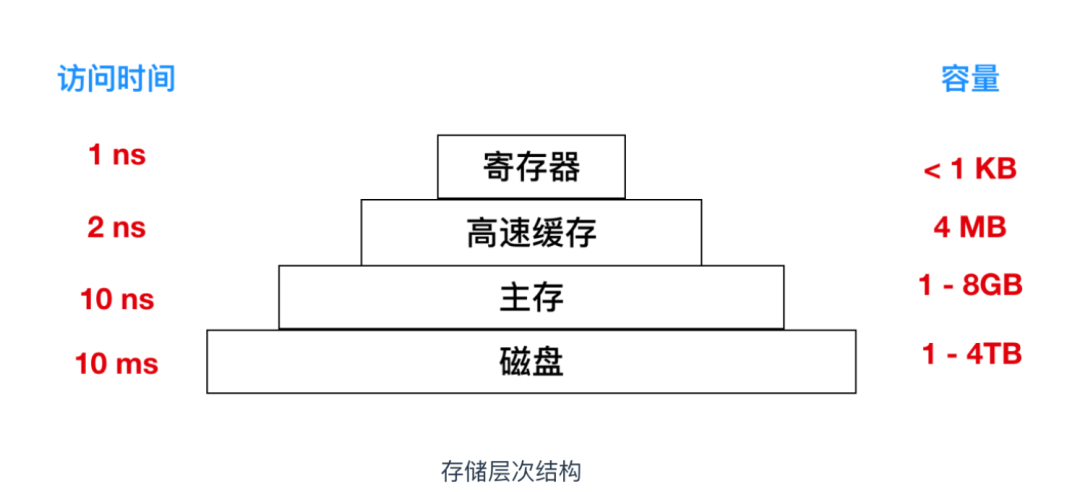
寄存器(Register)是中央处理器(CPU)内用来暂存指令、数据和地址的存储器,也是 CPU 中读写最快的存储器。
图片来源于cxuan
从硬件层面来说,栈位于内存当中,而寄存器位于 CPU 当中,这也是为什么,我们通常会说,基于寄存器架构的虚拟机会比基于栈的虚拟机快的原因。
基于栈的虚拟机
前面我们讲 JDK 的发展历程时,提到了 Hotspot VM,它是血缘最正统的 Java 虚拟机。
HotSpot VM 是基于栈的一种虚拟机,当 Java 程序运行时,HotSpot VM 加载编译后的字节码文件(也就是.class 文件),其解释器或JIT编译器会读取文件中的字节码指令,将它们解释(或编译)为机器码。
方法调用和执行过程中的数据(如局部变量和中间结果)会存储在栈(操作数栈,下面会讲)中,字节码指令操作这些数据,然后执行程序逻辑。
下面这幅图我们之前在讲JVM 是如何运行 Java 代码的时候讲过。
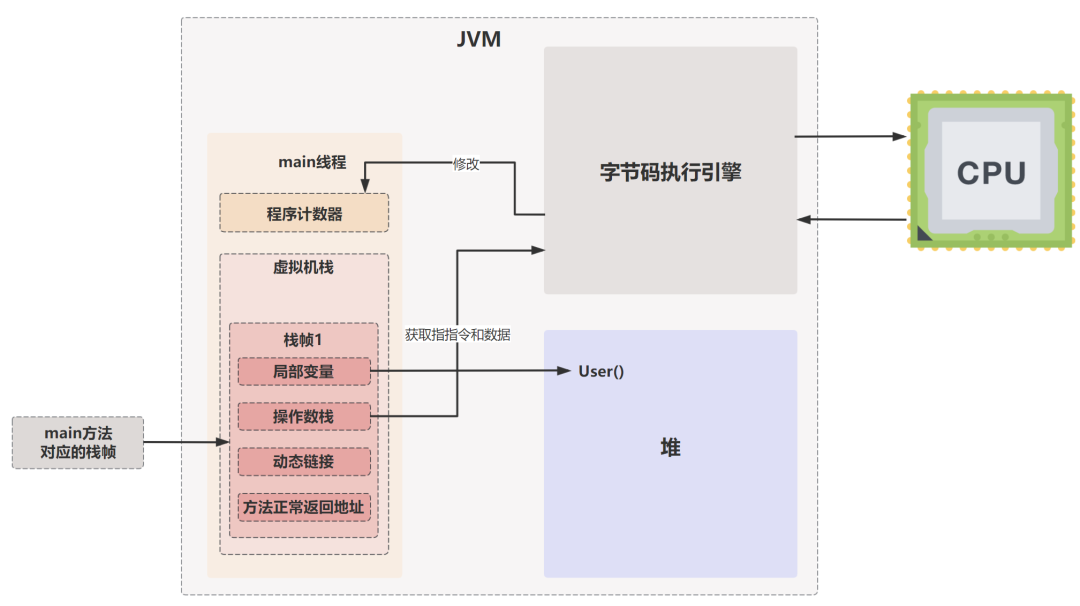
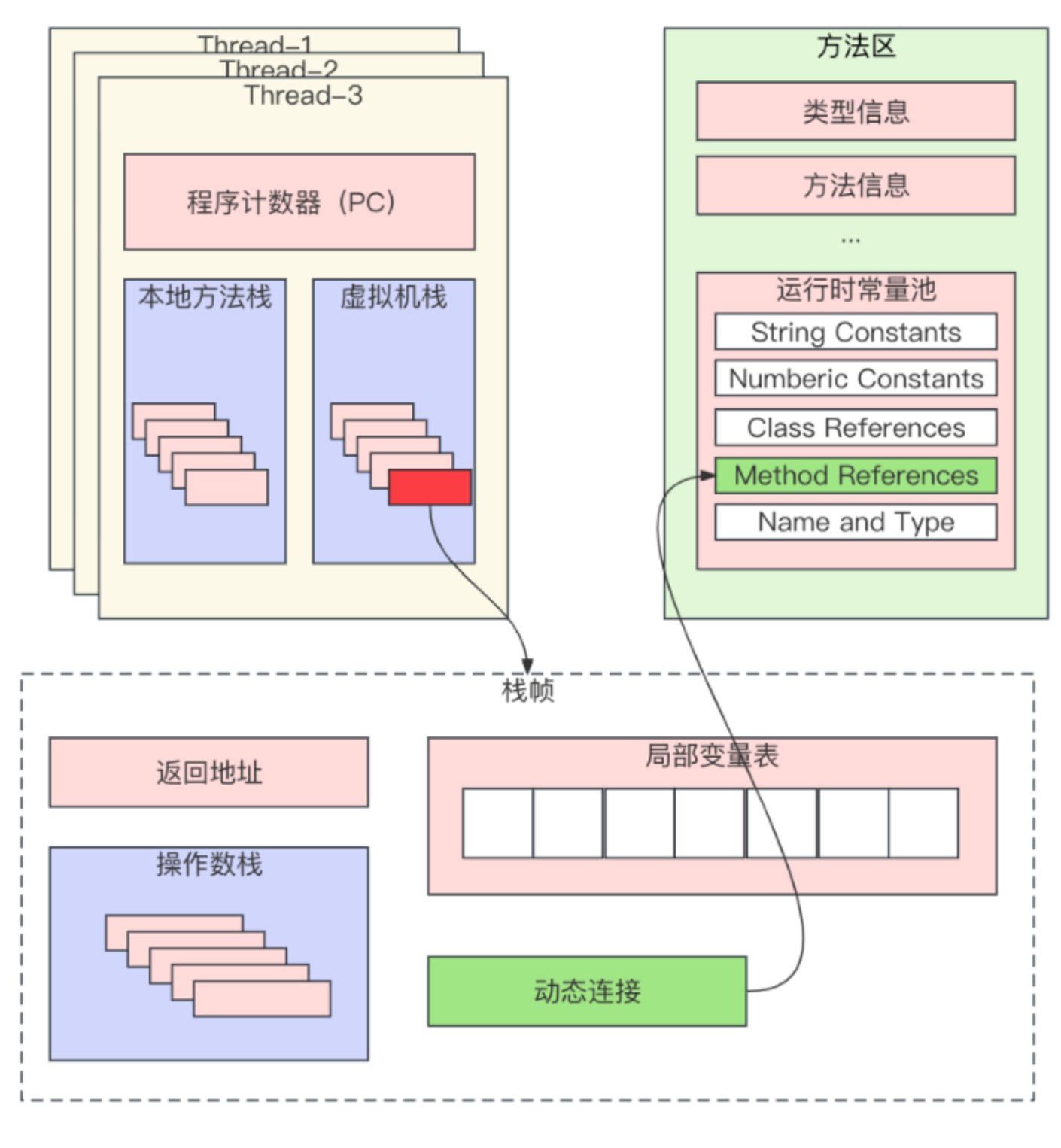
main 方法被执行的时候,JVM 会创建一个栈帧(Stack Frame),通过存储局部变量表、操作数栈、动态链接、方法出口等信息来支撑和完成方法的执行,栈帧就是虚拟机栈中的子单位。
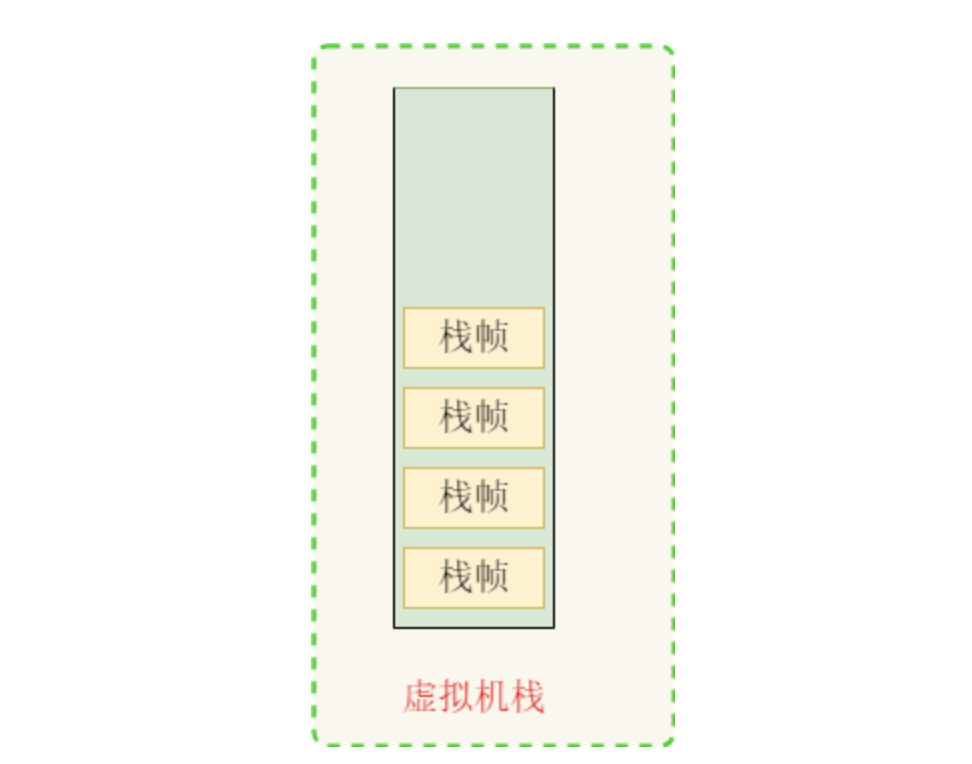
栈帧本身也是一种栈结构,用于支持虚拟机进行方法调用和方法执行,遵循 LIFO 的原则,每个栈帧都包含了一个方法的运行信息,每个方法从调用到执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈和出栈的过程。
图片来源于网络,作者浣熊say
虚拟机栈是线程私有的,每个线程都有自己的 Java 虚拟机栈。方法调用时都会创建一个新的栈帧,该栈帧被推入虚拟机栈,成为当前活动栈帧。
- 入栈:方法调用时,虚拟机栈会为这个方法分配一个栈帧,这个栈帧被压入虚拟机栈,成为当前的活动栈帧。PC 寄存器指向当前栈帧的指令,执行方法的指令序列从该地址开始。
- 出栈:方法执行完成后,对应的栈帧会被移除,控制权回到前一个栈帧,前一个栈帧中的返回值成为当前活动栈帧的一个操作数,继续执行。
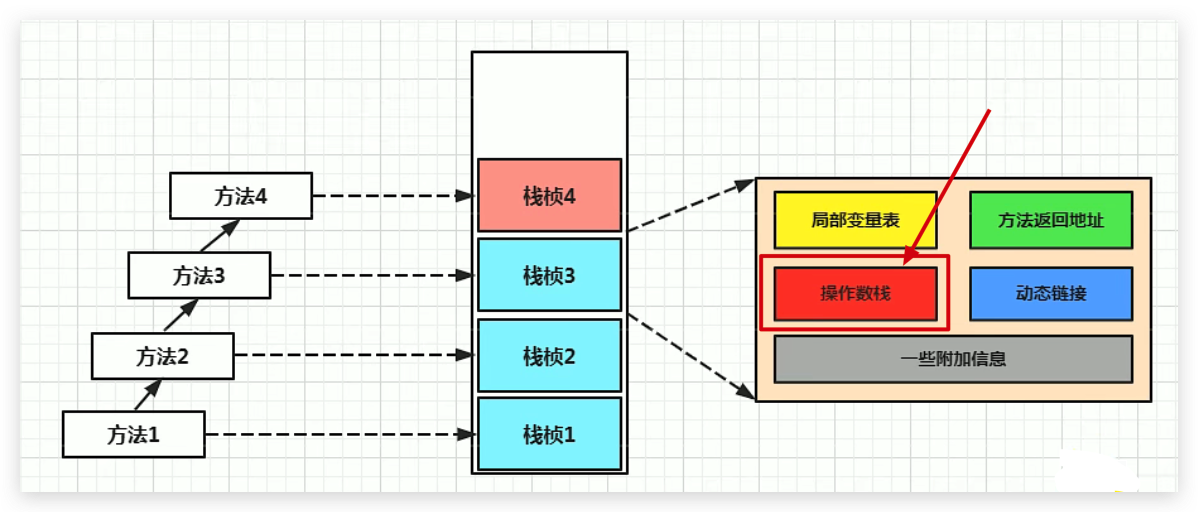
其中的操作数栈(Operand Stack)也是一种栈结构,用于保存方法执行时的中间结果、参数和返回值。当一个方法刚刚开始执行的时候,这个方法的操作数栈是空的。
在方法执行的过程中,操作数栈被用于执行各种字节码指令。例如,将两个数字相加的指令会从操作数栈中弹出两个数字,将它们相加,然后将结果压入操作数栈中。
另外,操作数栈的内容是临时的,它的生命周期和方法的生命周期是一样的,当方法执行结束后,操作数栈也会被销毁。
R 大曾在知乎的贴子里提到过:
VM 当初设计的时候非常重视代码传输和存储的开销,因为假定的应用场景是诸如手持设备、机顶盒之类的嵌入式应用,所以要代码尽量小;外加基于栈的实现更简单(无论是在源码编译器的一侧还是在虚拟机的一侧),而且主要设计者 James Gosling 的个人经验上也对这种做法非常熟悉(例如他之前实现过 PostScript 的虚拟机,也是基于栈的指令集),所以就选择了基于栈。
我们简单来看一下基于栈的虚拟机方法执行的过程,以下面的代码为例:
int a = 33;
int b = 44;
int c = a + b;通过 javap -c Main 命令可以查看对应的字节码,如下所示:
Compiled from "Main.java"
public class com.github.paicoding.forum.test.javabetter.jvm.Main {
public static void main(java.lang.String[]);
Code:
0: bipush 33
2: istore_1
3: bipush 44
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: return
}我们用图来说明指令执行的过程,大致如下。
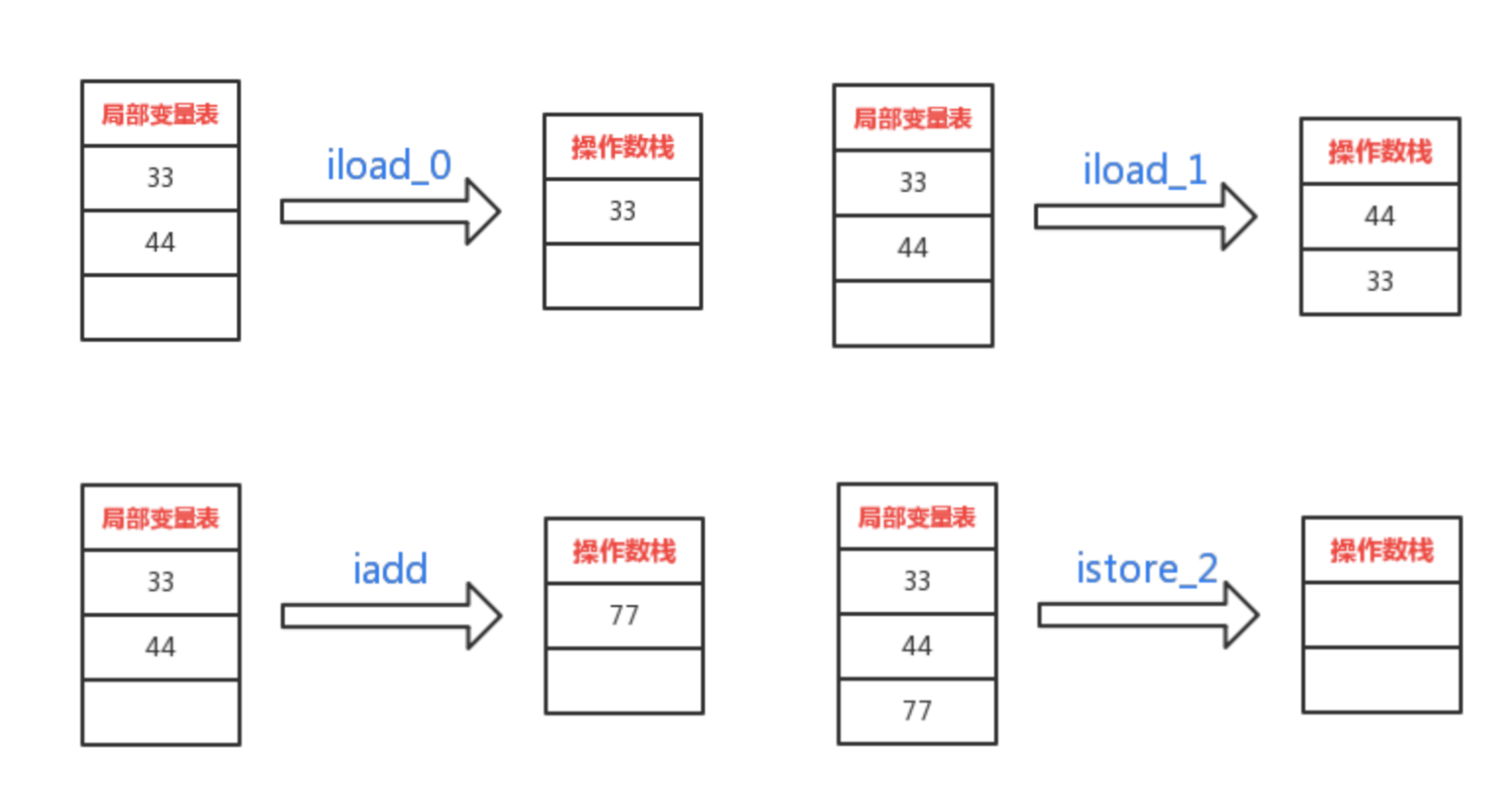
- iload_0 将 33 压入操作数栈中
- iload_1 将 44 压入操作数栈中
- iadd 将操作数栈中的 33 和 44 弹出,相加后将结果 77 压入操作数栈中
- istore_2 将栈顶的 77 弹出,存入局部变量表中下标为 2 的位置
关于字节码指令的具体释义,我们放到下一节去细讲,这里主要是带大家体会一下基于栈的虚拟机和基于寄存器的虚拟机之间的差别。
基于寄存器的虚拟机
那除了有基于栈的虚拟机实现,当然也有基于寄存器的虚拟机实现,比如 LuaVM,负责执行 Lua 语言,一门轻量级的脚本语言,可戳链接了解。
5.0 之前的 Lua 其实是用基于栈的指令集,到 5.0 才改为用基于寄存器的。出于两点考虑,一是减少数据移动次数,降低数据迁移带来的拷贝开销;二是减少虚拟指令条数,提高指令执行效率。

好,我们就基于 lua 来看一下基于寄存器的虚拟机方法执行的过程。
第一步,安装 lua,这里我用的是 macOS,直接用 brew 安装就好了。
brew install luaWindows 用户可以查看这个文档:lua-users wiki: Building Lua In Windows For Newbies
也可以通过 Lua for Windows 来完成安装:
我们来编写一段简单的 lua 代码,保存为 example.lua。
local a = 33
local b = 44
local c = a + b然后查看字节码指令。
luac -l example.lua结果如下:
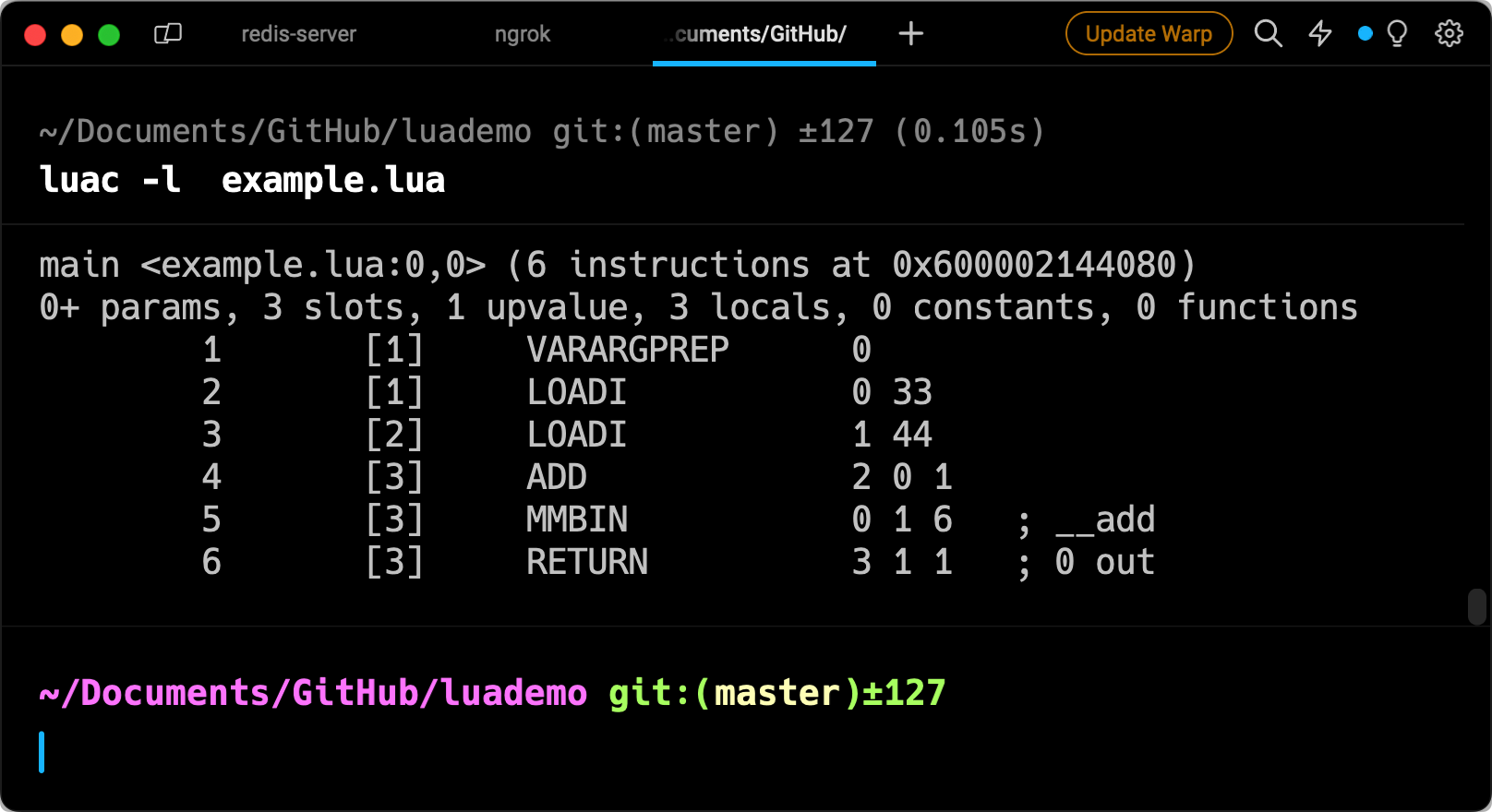
main <example.lua:0,0> (6 instructions at 0x600002144080)
0+ params, 3 slots, 1 upvalue, 3 locals, 0 constants, 0 functions这是函数的描述,表示这是 example.lua 文件中的主函数。它包含 6 条指令。函数不接受参数(0+ params),有 3 个本地变量槽位(3 slots),1 个闭包变量(1 upvalue),3 个本地变量(3 locals),没有常量(0 constants)和内部函数(0 functions)。
接下来是具体的指令:
- VARARGPREP 0:准备变长参数,用于处理传入的参数。
- LOADI 0 33:将整数 33 加载到寄存器 0。
- LOADI 1 44:将整数 44 加载到寄存器 1。
- ADD 2 0 1:将寄存器 0 和寄存器 1 中的值相加,并将结果存放在寄存器 2。对应于脚本中两个数值的加法操作。
- MMBIN 0 1 6; add:这是一个元方法(metamethod)调用,用于处理加法操作。这指示 Lua 虚拟机查找并执行
add元方法。元方法是 Lua 中用于重载标准操作符的特殊方法。 - RETURN 3 1 1; 0 out:返回操作,将寄存器 3 中的值作为返回值。
1 1表示从寄存器 3 返回一个值,0 out指没有额外的返回值。
小结
基于栈的优点是可移植性更好、指令更短、实现起来简单,但不能随机访问栈中的元素,完成相同功能所需要的指令数也比寄存器的要多,需要频繁的入栈和出栈。
基于寄存器的优点是速度快,有利于程序运行速度的优化,但操作数需要显式指定,指令也比较长。