pandas的分类类型数据(Categorical Data)
这次学习使用Categorical Data,在某些 pandas 操作中使用分类类型能实现更好的性能和减少内存使用。另外还学习一些工具,这些工具有助于在统计和机器学习应用程序中使用分类数据。
一.背景
通常,表中的列会包含一组具有非重复值的同类型实例,之前学习的 unique 和 value_counts 函数,它们使我们能够从数组中提取不同的值并分别计算它们的频率。
python
import numpy as np
import pandas as pd
np.random.seed(12345)
# []*2 表示重复两次
values = pd.Series(['apple', 'orange', 'apple', 'apple'] * 2)
print(values)
# 使用unique()对values去重,输出一个列表
print(pd.unique(values))
# 使用value_counts()对values中出现的不同值计算出现的频次(计数),输出一个Series
print(values.value_counts())输出结果:
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
dtype: object
'apple' 'orange'
apple 6
orange 2
Name: count, dtype: int64
许多数据系统(用于数据仓库、统计计算或其他用途)已经开发了专门的方法来表示具有重复值的数据,以实现更高效的存储和计算。在数据仓库中,最佳实践是使用包含不同值的所谓维度表,并将主要观测值存储为引用维度表的整数键:
python
import numpy as np
import pandas as pd
# []*2 表示重复两次
values = pd.Series([0, 1, 0, 0] * 2)
dim = pd.Series(['apple', 'orange'])
# 可以使用 take() 方法恢复原来的 Series 字符串。
# 原来的Series字符串:pd.Series(['apple', 'orange', 'apple', 'apple'] * 2)
val_str = dim.take(values)
print(values)
print(dim)
print(val_str)输出结果:
0 0
1 1
2 0
3 0
4 0
5 1
6 0
7 0
dtype: int64
0 apple
1 orange
dtype: object
0 apple
1 orange
0 apple
0 apple
0 apple
1 orange
0 apple
0 apple
dtype: object
这种整数表示形式称为 categorical 或 dictionary-encoded 表示形式 (例如:上面的apple用0表示,orange用1表示 )。不同值的数组可以称为数据的类别、字典或级别。这里,我们将使用分类和类别(categorical 和 categories) 这两个术语。引用类别的整数值称为类别代码或简称代码。
在执行分析时,分类表示可以显著提高性能(简单理解:就是用整数值代替原值分析,类似于上面的示例用0代表apple,1代表orange)。另外还可以对类别执行转换,同时保持代码不变。
可以以相对较低的成本进行的一些示例转换包括:重命名类别;添加新类别而不更改现有类别的顺序或位置。
二.pandas 中的分类扩展类型
pandas 具有特殊的 Categorical 扩展类型,用于保存使用基于整数的 categorical 表示或编码的数据。这是一种流行的数据压缩技术,适用于多次出现相似值的数据,并且可以以较低的内存使用量提供明显更快的性能,尤其是对于字符串数据。看下面的代码示例:
python
import numpy as np
import pandas as pd
# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
df = pd.DataFrame({'fruit': fruits,
'basket_id': np.arange(N),
'count': rng.integers(3, 15, size=N),
'weight': rng.uniform(0, 4, size=N)},
columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)
# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)df输出:
| | basket_id | fruit | count | weight |
| 0 | 0 | apple | 11 | 1.564438 |
| 1 | 1 | orange | 5 | 1.331256 |
| 2 | 2 | apple | 12 | 2.393235 |
| 3 | 3 | apple | 6 | 0.746937 |
| 4 | 4 | apple | 5 | 2.691024 |
| 5 | 5 | orange | 12 | 3.767211 |
| 6 | 6 | apple | 10 | 0.992983 |
| 7 | 7 | apple | 11 | 3.795525 |
|---|
fruit_cat输出:
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category Categories (2, object): 'apple', 'orange'
fruit_cat 的值 现在是 pandas.Categorical 的实例,可以通过 .array属性访问:
python
import numpy as np
import pandas as pd
# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
df = pd.DataFrame({'fruit': fruits,
'basket_id': np.arange(N),
'count': rng.integers(3, 15, size=N),
'weight': rng.uniform(0, 4, size=N)},
columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)
# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)
c = fruit_cat.array
print(type(c))type(c)输出:
pandas.core.arrays.categorical.Categorical
Categorical 对象具有 categories 和 codes 属性:
python
import numpy as np
import pandas as pd
# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
df = pd.DataFrame({'fruit': fruits,
'basket_id': np.arange(N),
'count': rng.integers(3, 15, size=N),
'weight': rng.uniform(0, 4, size=N)},
columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)
# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)
c = fruit_cat.array
print(type(c))
# Categorical 对象的 categories 和 codes 属性
print(c.categories)
print(c.codes)c.categories 输出:
Index('apple', 'orange', dtype='object')
c.codes 输出:
array(0, 1, 0, 0, 0, 1, 0, 0, dtype=int8)
使用 categories 访问器会更方便,稍后在 "分类方法" 中学习使用。
在代码和类别之间进行映射的一个非常使用技巧是使用dict和enumerate,例如:
dict(enumerate(c.categories))
输出:{0: 'apple', 1: 'orange'}
可以将转换后的结果列赋值给DataFrame的相应列,使其转换为分类列;还可以用其他的Python序列类型直接创建 pandass.Categorical列。例如下面代码中的后5行:
python
import numpy as np
import pandas as pd
# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
df = pd.DataFrame({'fruit': fruits,
'basket_id': np.arange(N),
'count': rng.integers(3, 15, size=N),
'weight': rng.uniform(0, 4, size=N)},
columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)
# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)
c = fruit_cat.array
print(type(c))
# Categorical 对象的 categories 和 codes 属性
print(c.categories)
print(c.codes)
dict(enumerate(c.categories))
df['fruit'] = df['fruit'].astype('category')
print(df['fruit'])
my_categories = pd.Categorical(['foo', 'bar', 'baz', 'foo', 'bar'])
print(my_categories)print(df'fruit') 输出:
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category
Categories (2, object): 'apple', 'orange'
print(my_categories) 输出:
'foo', 'bar', 'baz', 'foo', 'bar'
Categories (3, object): 'bar', 'baz', 'foo'
如果从其他来源获取了分类编码数据,则可以使用替代 from_codes 构造函数,例如:
python
import numpy as np
import pandas as pd
categories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
my_cats_2 = pd.Categorical.from_codes(codes, categories)
print(my_cats_2)输出:
'foo', 'bar', 'baz', 'foo', 'foo', 'bar'
Categories (3, object): 'foo', 'bar', 'baz'
除非明确指定,否则分类转换不假定类别的特定排序。因此,categories 数组的顺序可能会有所不同,具体取决于输入数据的顺序。但使用 from_codes 或任何其他构造函数时,可以指示类别有意义的排序:
python
import numpy as np
import pandas as pd
categories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
ordered_cat = pd.Categorical.from_codes(codes, categories, ordered=True)
print(ordered_cat)输出:
'foo', 'bar', 'baz', 'foo', 'foo', 'bar'
Categories (3, object): 'foo' \< 'bar' \< 'baz'
输出 foo \< bar \< baz 表示在排序中 'foo' 在 'bar' 之前,依此类推。另外,可以使用 as_ordered 对无序分类实例进行排序:
python
import numpy as np
import pandas as pd
categories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
my_cats_2 = pd.Categorical.from_codes(codes, categories)
print(my_cats_2.as_ordered())用as_ordered() 输出:
'foo', 'bar', 'baz', 'foo', 'foo', 'bar'
Categories (3, object): 'foo' \< 'bar' \< 'baz'
最后要注意的是,分类数据不必是字符串,虽然上面我只学习展示了字符串示例。分类数组可以包含任何不可变的值类型。
三.使用 Categoricals 进行计算
与 unencoded 版本(如字符串数组)相比,在 pandas 中使用 Categorical 的行为方式通常相同。pandas 的某些功能(如 groupby 函数)在处理分类时性能更好,还有一些函数可以使用 ordered 标志。
下面学习一个示例,对一些随机数值数据使用 pandas.qcut 分箱函数,返回 pandas.Categorical:
python
import numpy as np
import pandas as pd
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
# 正态分布数据
draws = rng.standard_normal(1000)
# 计算此数据draws的四分位数分箱并提取一些统计数据
bins = pd.qcut(draws, 4)
print(bins)print(bins)输出:
(-3.121, -0.675\], (0.687, 3.211\], (-3.121, -0.675\], (-0.675, 0.0134\], (-0.675, 0.0134\], ..., (0.0134, 0.687\], (0.0134, 0.687\], (-0.675, 0.0134\], (0.0134, 0.687\], (-0.675, 0.0134\]
Length: 1000
Categories (4, intervalfloat64, right): (-3.121, -0.675 < (-0.675, 0.0134] < (0.0134, 0.687] <
(0.687, 3.211]]
下面我们给四分位数用labels参数指定名称,可能在数据分析或生成报表时更有用:
python
import numpy as np
import pandas as pd
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
# 正态分布数据
draws = rng.standard_normal(1000)
# 计算此数据draws的四分位数分箱并提取一些统计数据,用labels指定四分位数名称
bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
print(bins)输出:
'Q1', 'Q4', 'Q1', 'Q2', 'Q2', ..., 'Q3', 'Q3', 'Q2', 'Q3', 'Q2'
Length: 1000
Categories (4, object): 'Q1' \< 'Q2' \< 'Q3' \< 'Q4'
在用print(bins.codes:10) 输出看看:0 3 0 1 1 0 0 2 2 0
设置了labels的 bins 分类不包含边缘数据的信息,因此我们可以使用 groupby 来提取一些汇总统计信息:
python
import numpy as np
import pandas as pd
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
# 正态分布数据
draws = rng.standard_normal(1000)
# 计算此数据draws的四分位数分箱并提取一些统计数据,用labels指定四分位数名称
bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
bins = pd.Series(bins, name='quartile')
results = (pd.Series(draws).groupby(bins).agg(['count', 'min', 'max']).reset_index())
print(results)
print(results['quartile'])results输出:
quartile count min max
0 Q1 250 -3.119609 -0.678494
1 Q2 250 -0.673305 0.008009
2 Q3 250 0.018753 0.686183
3 Q4 250 0.688282 3.211418
results'quartile' 输出:
0 Q1
1 Q2
2 Q3
3 Q4
Name: quartile, dtype: category
Categories (4, object): 'Q1' \< 'Q2' \< 'Q3' \< 'Q4'
results中的 'quartile' 列保留 bin 中的原始分类信息,包括排序。
四.使用分类(categoricals)提高性能
在前面,我说过分类类型可以提高性能和内存使用,我们看一些例子,考虑一些具有 1000 万个元素和少量不同类别的 Series:
python
import numpy as np
import pandas as pd
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
N = 10_000_000
labels = pd.Series(['foo', 'bar', 'baz', 'qux'] * (N // 4))
# 将标签转换为分类标签:
categories = labels.astype('category')
# 用以下代码来比较labels和categories的内存使用情况
lab_mem = labels.memory_usage(deep=True)
cat_men = categories.memory_usage(deep=True)
print(lab_mem, '\t', cat_men)内存对比输出:600000132 10000544 ,从输出可以看出categories对内存的使用明显要小。当然,转换为类别(categories)不是免费的,但是只需要一次性消耗。使用 categoricals 时,GroupBy 操作可以明显加快速度,因为基础算法使用基于整数的 codes 数组,而不是字符串数组。大家可以用labels.value_counts()和categories.value_counts()消耗的时间做个对比,会发现categories.value_counts()耗时比labels.value_counts()少指数级甚至少的更多。
五.分类的方法
包含分类数据的序列 具有几个类似于 Series.str 专用字符串方法的特殊方法。特殊访问器属性 cat 提供对 categorical 方法的访问。
python
import numpy as np
import pandas as pd
# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
s = pd.Series(['a', 'b', 'c', 'd'] * 2)
cat_s = s.astype('category')
print(cat_s)
print(cat_s.cat.codes)
print(cat_s.cat.categories)
# 假设我们知道此数据的实际类别集超出了数据中观察到的四个值,可以使用 set_categories 方法来更改它们
actual_categories = ['a', 'b', 'c', 'd', 'e']
cat_s2 = cat_s.cat.set_categories(actual_categories)
print(cat_s2)
print(cat_s.value_counts())
print(cat_s2.value_counts())以上代码输出:
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (4, object): 'a', 'b', 'c', 'd'
0 0
1 1
2 2
3 3
4 0
5 1
6 2
7 3
dtype: int8
Index('a', 'b', 'c', 'd', dtype='object')
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (5, object): 'a', 'b', 'c', 'd', 'e'
a 2
b 2
c 2
d 2
Name: count, dtype: int64
a 2
b 2
c 2
d 2
e 0
Name: count, dtype: int64
在大型数据集中,分类通常用作节省内存和提高性能的便捷工具。筛选大型 DataFrame 或 Series 后,许多类别可能不会显示在数据中。为了帮助解决这个问题,我们可以使用 remove_unused_categories 方法来修剪未观察到的类别:
python
import numpy as np
import pandas as pd
s = pd.Series(['a', 'b', 'c', 'd'] * 2)
cat_s = s.astype('category')
cat_s3 = cat_s[cat_s.isin(['a', 'b'])]
print(cat_s3)
print(cat_s3.cat.remove_unused_categories())cat_s3输出:
0 a
1 b
4 a
5 b
dtype: category
Categories (4, object): 'a', 'b', 'c', 'd'
cat_s3.cat.remove_unused_categories() 输出:
0 a
1 b
4 a
5 b
dtype: category
Categories (2, object): 'a', 'b'
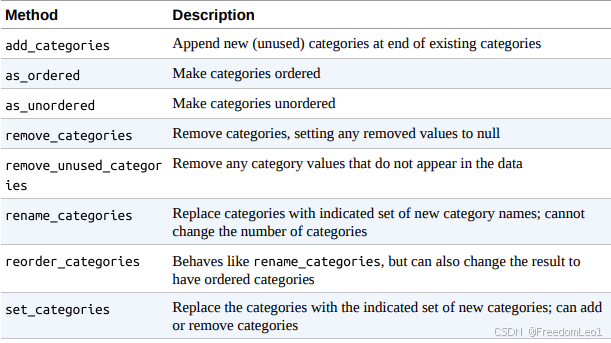
下图是可用分类方法的列表:
六.创建用于建模的虚拟变量
当您使用统计或机器学习工具时,通常会将分类数据转换为虚拟变量,也称为独热编码。这涉及创建一个 DataFrame,其中包含每个不同类别的列;这些列包含给定类别的出现次数,出现一次为 1,否则为 0。使用pandas.get_dummies 函数将此一维分类数据转换为包含虚拟变量的 DataFrame:
python
import numpy as np
import pandas as pd
cat_s = pd.Series(['a', 'b', 'c', 'd'] * 2, dtype='category')
# 这里要指定dtype类型,否则会返回布尔型,这是因为新版pandas的原因
pd.get_dummies(cat_s, dtype=float)
print(a)输出结果:
| | a | b | c | d |
| 0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 1.0 | 0.0 | 0.0 | 0.0 |
| 5 | 0.0 | 1.0 | 0.0 | 0.0 |
| 6 | 0.0 | 0.0 | 1.0 | 0.0 |
| 7 | 0.0 | 0.0 | 0.0 | 1.0 |
|---|
**总结:**有效的数据准备可以让我们花更多时间分析数据,减少准备分析的时间,从而显著提高工作效率。数据清洗与预处理的学习先到这,学的内容要不断的实操练习才会熟练。后面我将继续学习数据整理:连接、合并和重塑等。