本节内容,是stable diffusion的文生图详细讲解课程,我们将学习在stable diffusion中,如何书写优秀的提示语句以及提示词的设计有哪些可以借鉴的规范和技巧。
然后我们会详细讲解文生图中的一些常用参数,学习完本节课程,相信大家便能快速书写出合适的提示语句,并通过调整参数更好地使用stable diffusion webui绘制理想的图片。
stable diffusion和midjourney等AI绘图应用一样,需要提供提示词或提示语句,来引导AI生成图片。我们在之前的课程已经提到,stable diffusion webui,提供了正向提示词和反向提示词输入区域,用来分别书写希望出现在画面中的要素,和不希望出现的要素。提示词的编写是图片绘制的关键,图片生成质量很大程度上取决于提示词设计是否合理。
目前, stable diffusion对中文提示词支持还不是很好,在stable diffusion中最好使用英文来构建提示词,和midjourney一样,我们可以使用翻译软件将我们的中文提示词翻译成英文。
一:提示词书写参考框架
此外,早期的模型,stable diffusion对自然语言的处理能力有限,所以和midjourney类似,我们需要将图像构思尽量以逗号分隔的简短词或句来描述,这样stable diffusion能更好地理解我们的需求。
当然,stable diffsion近期推出的SDXL模型以及sd3模型已经有了很大的进步,这两个模型能更好地处理自然语言,所以在SDXL和sd 3模型下,可以使用更加自然的提示语句来生成图像。
但目前为止,仍然还有很多优秀的大模型是基于早期模型构建,所以我们还是应该掌握如何通过简短词句来构造提示语句。在stable diffusion中,通过简短词句构造提示语句可以遵循一定的方法和规范,为此,我们也总结了一个适应性较高的stable diffusion正向提示词编写框架用于协助大家快速编写提示语句。

我们的正向提示词框架主要分为4个部分
第一部分:画质、视角和风格
我们在提示语句的开头可以先描述图片的画质特征以及视角。
画质描述:如杰出作品,高分辨率,原始照片,逼真图片,这些提示词基本上是固定的,我们可以直接参考一些常用的写法
视角:如front view正面视角,side view侧面视角,from above俯视视角,from below仰视视角,close up特写镜头等等,有的时候我们也可以尝试增加一些艺术家名字、艺术风格的描述
第二部分:画面主体
这一部分,可以针对画面构思主体进行描述,比如人物以及人物特征
第三部分:环境和背景
在画面主体描述后,我们可以再增加对画面环境、背景、光线的详细描述
第四部分:特殊关键字
如果使用LoRA,LyCoris,embedding时,我们可以根据文档中的说明,添加与之相关的一些特殊关键字。我们会在后续LoRA,LyCoris,embedding课程中详细讲解这些知识
比如我们这里构思了一幅图像,图像的大致内容是一名在海边的女孩。
我们可以根据上述框架设计正向提示词
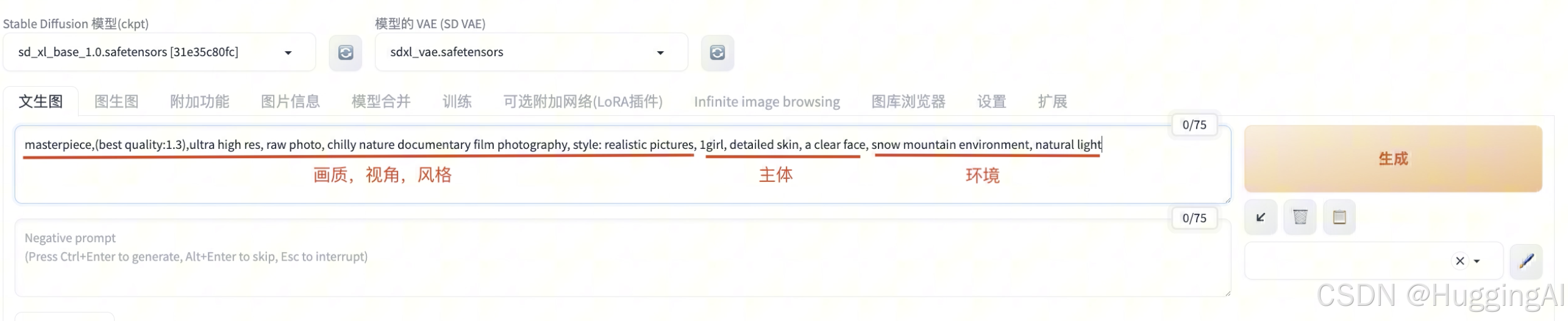
高品质,精细的细节,高分辨率,8K壁纸,中国女孩,黑色长发,白色裙子,正脸,高鼻梁,大眼睛,细长的眉毛,海边,海滩,蔚蓝的大海,明亮的光线,使用翻译软件翻译成英文
masterpiece,(best quality:1.3),ultra high res, raw photo, chilly nature documentary film photography, style: realistic pictures, 1girl, detailed skin, a clear face, snow mountain environment, natural light
这里的正向提示语句,开头对画质进行了描述,然后对画面主体元素进行了描述,再加上环境光线等描述词,便组成了完整的正向提示语句。
而对于反向提示词,在stable diffusion中我们通常可以使用固定的反向提示语句,比如
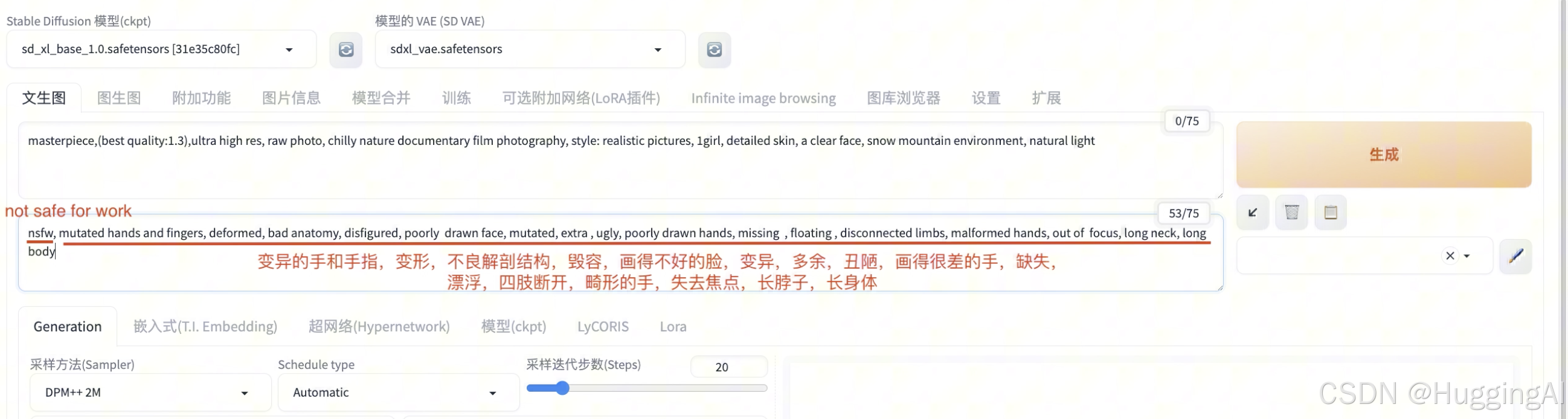
nsfw, mutated hands and fingers, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra , ugly, poorly drawn hands, missing , floating , disconnected limbs, malformed hands, out of focus, long neck, long body
我们分析一下这里的提示词,nsfw会经常使用到,具体含义是 not safe for work,工作中不适合的图像,通常是指颜色,暴力,血腥图像
然后是一些其他的描述,比如变异的手和手指,变形,不良解剖结构,毁容,画得不好的脸,变异,多余,丑陋,画得很差的手,缺失,漂浮,四肢断开,畸形的手,失去焦点,长脖子,长身体等等。
我们一般无需记忆反向提示词,网上可以搜索到很多反向提示词模版,这些提示词模版可以在一定程度上避免AI绘图过程中出现一些异常的元素。反向提示词模版有很多,但大部分是类似的。实际使用中,根据场景选择其中的一个即可。
另外,对于某些模型和插件,也会需要增加一些固定的反向提示词关键词,我们在后续的课程中,遇到该类型的反向提示词,会特别说明。
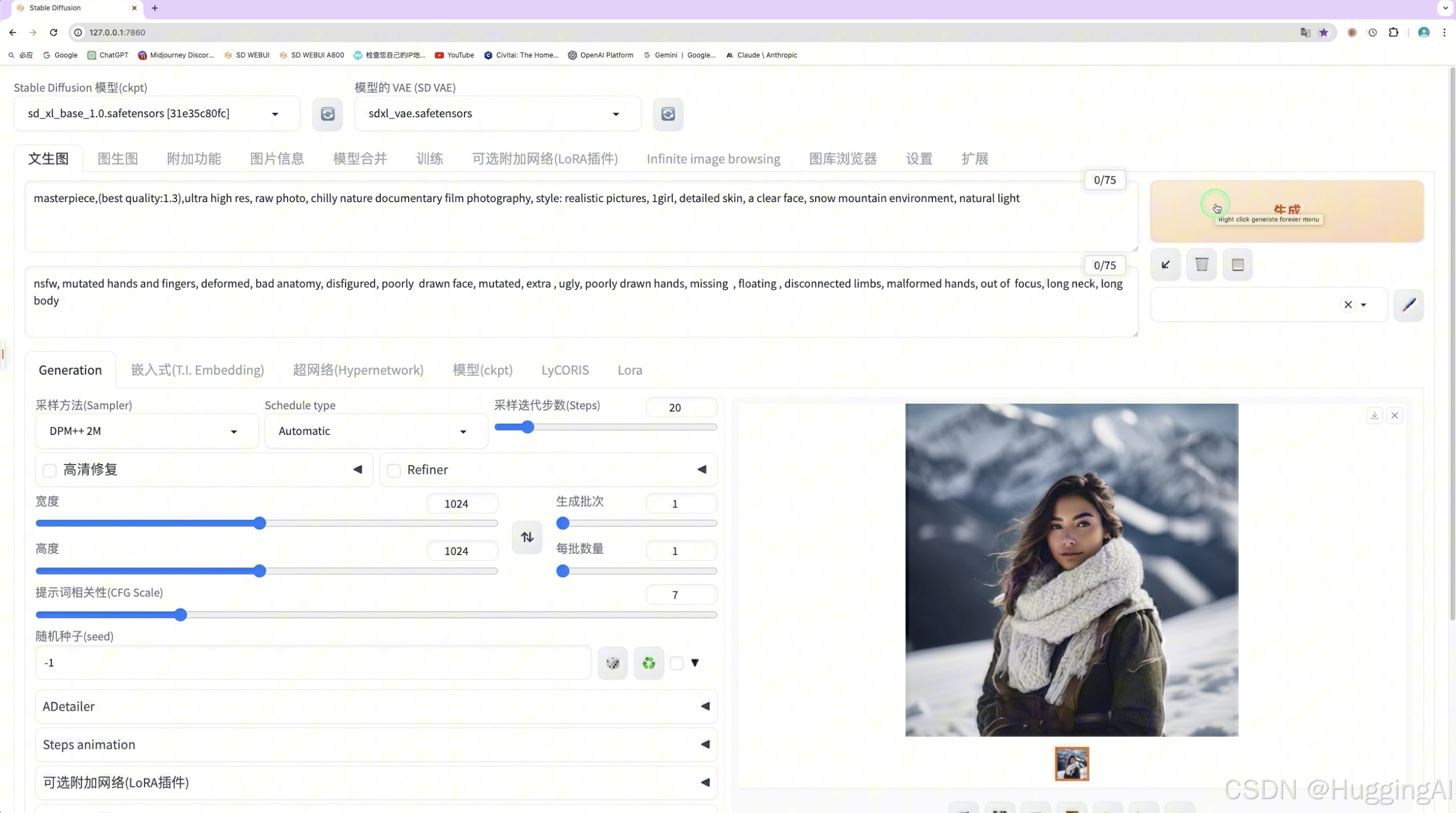
我们在这里使用SDXL版本的模型,输入上述正向和反向提示词,点击生成按钮,可以看到stable diffusion很快帮我们生成了相应的图片。
二:提示词权重
在midjourney的课程中,我们有学习到可以对提示词设置权重,来引导图像的生成。而在stable diffusion中,同样可以对提示词设置权重,从而在AI绘图过程增加或降低这些提示词元素对生成图像的影响程度。
stable diffusion中,默认权提示词重值为1.我们可以通过多种方式设置目标提示词的权重,

第一:小括号,将提示词放在小括号中代表权重为1.1 ,增加权重,如果两个小括号代表权重为1.1*1.1,三个则代表权重为1.1*1.1*1.1
第二:中括号,将提示词放在小括号中代表权重为0.9,减少权重
第三:大括号,将提示词放在小括号中代表权重为1.05,增加权重
大家在看到其他人写的提示词中含有小中大括号,需要理解其涵义
第四:小括号使用冒号+数值的方式则是赋值权重,权重由冒号后的数字来决定比如(tree:1.5)表示权重值为1.5(增加),(tree:0.7)表示权重值为0.7
我们这里还要特别提醒,中括号和大括号除了权重还有更多高级用法,比如步数设置,元素混合设置等等,我们简单说明一下,

比如flower:5 中括号中的flower后跟一个冒号然后接整数数字,代表从第5步开始画花这一元素
而flower:0.5,冒号后跟的是小数,则代表从采样总步数的50%开始画花这一元素。
flower::10 中括号中的flower后跟两个冒号然后接数字 代表从最开始画花这一元素,但是画到第10步就不再绘制花元素,
更复杂一点的用法是诸如\[flower::20:5] ,代表从第5步开始画,到20步结束,
我们稍后会讲解采样步数参数,需要了解步数参数的涵义才能理解上述用法的意义;
中括号还有融合元素的用法,
比如这里的提示语句,pink\|blondlong hair,beautiful girl, gothic dress, clear details, Gothic architecture interior
中括号中用竖线将粉色pink和金色blond分隔,渲染的时候,是一步粉红一步金色,最后绘制出来的是融合后的粉金色。

大括号也有一些特殊的用法,比如
{Crown|Corolla|Hairpin|Bowknot},long blond hair, beautiful girl, gothic dress, clear details
这里的大括号中用竖线分隔了皇冠,花冠,簪子,蝴蝶结这四个描述词,在绘制图像时,会随机选择其中的一个来出图。
所以我们用上述提示语句绘制图片时,女孩头部的装饰有可能是皇冠,花冠,簪子,蝴蝶结中的任意一个。

以上这些语法在实际绘画中可以起到精细调节的作用,但有些生涩难懂,我们不会经常用到,所以了解即可。
三:常用选项和参数
除了书写合适的提示词,参数的设置对图象的生成也会有非常大的影响。我们来看看stable diffusion webui有哪些常用的参数。
在讲解之前,需要提醒一下大家,不同的stable diffusion webui版本,界面上的内容尤其是参数选项区域会有一些细微的差别,我们这里讲解演示使用的是1.9.2版本的stable diffusion webui。
在提示词下方区域是参数设置区,
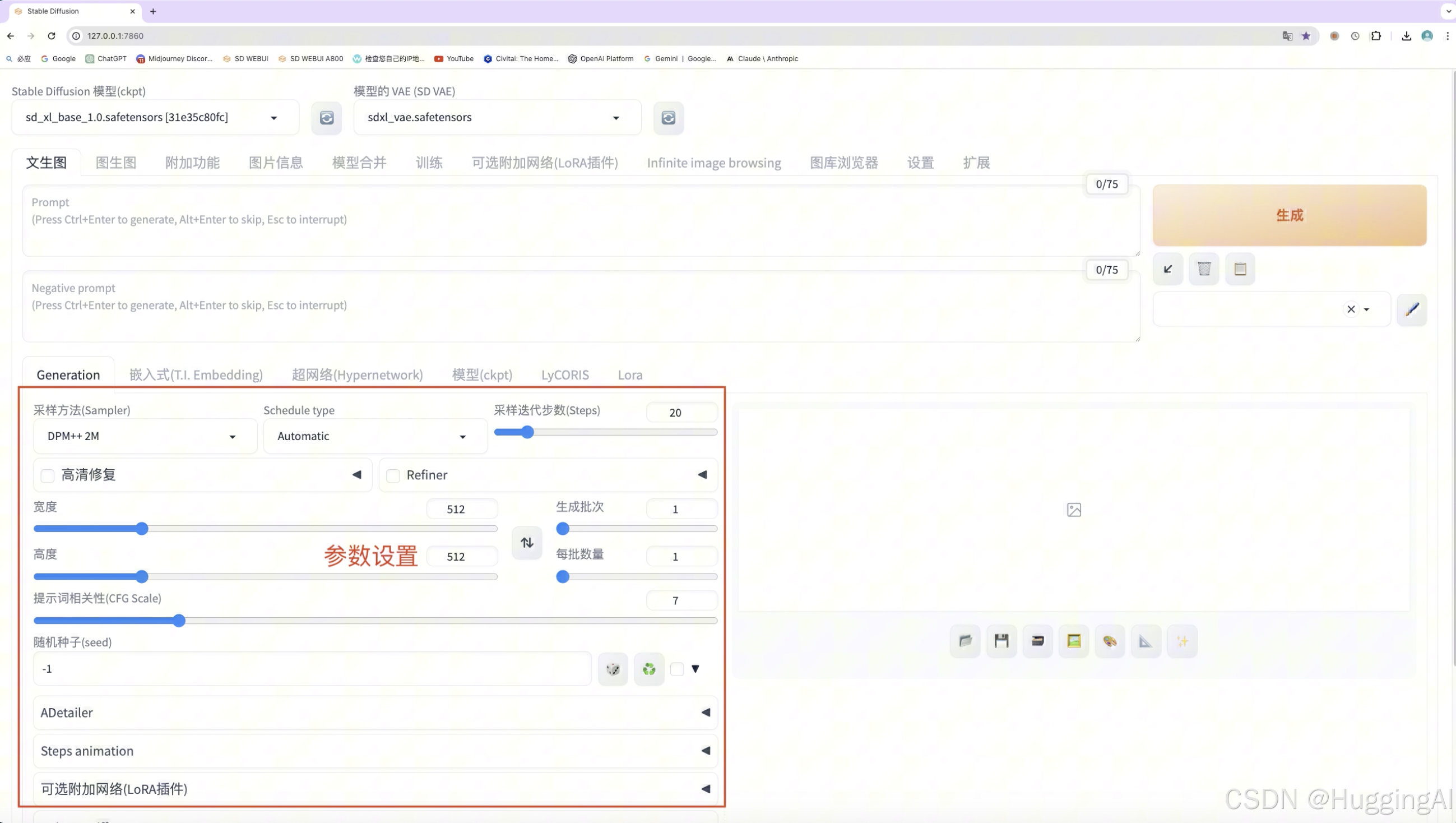
3.1 采样方法,计划类型和采样步数
首先是采样方法,计划类型schedule type和采样步数设置
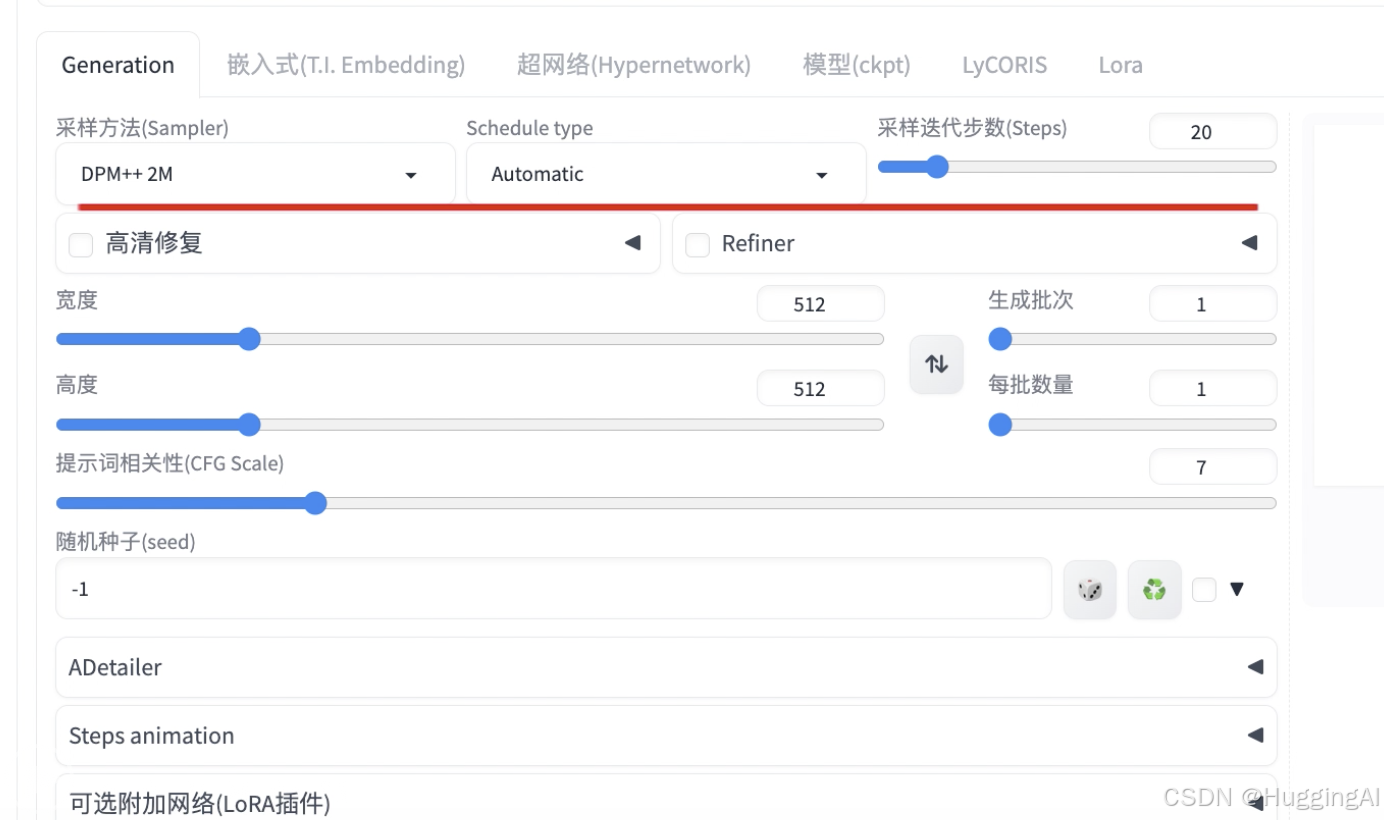
在讲解前,我们先了解一下stable diffusion模型的工作机制,stable diffusion和midjourney一样,是一种潜在扩散模型(latent diffusion model),一个标准的绘图过程分为两个步骤;前向扩散过程,和后向的去噪、复原以及生成目标的过程。前向过程不断向输入数据中添加噪声,而采样方法主要在后向过程中负责去噪的过程。
在图像生成前,模型会首先在潜在空间中生成一个完全随机的图像,然后噪声预测器会开始工作,从图像中减去预测的噪声。随着这个步骤的不断重复,最终我们得到了一个清晰的图像。Stable Diffusion在每个步骤中都会生成一张新的采样后的图像,整个去噪的过程,即为采样,而使用的采样手段,我们又称之为采样器或采样方法。
采样步数则用于设定噪音计划表,噪音计划表用于控制每个采样步骤的采样水平。增加采样步数,会缩小每一步的降噪幅度,有助于减少采样误差,但会增加计算时间。
Schedule type计划类型一般设置为automatic自动选择即可,当然,我们也可以自行指定使用的计划类型。
采样方法有很多,我们不在课程中详细展开,但会在另外的文章中总结各种采样方法的详细特征。
我们这里基于同一个模型,使用同样的提示词,设置相同的参数,然后使用不同的采样方法分别生成图片,我们简单看一下对比:

另外,关于采样方法我们也做了一些特征汇总:
比如:
名称中带有a标识的采样方法表示这一类是祖先采样器。这一类采样方法在每个采样步骤中都会向图像添加噪声,采样结果具有一定的随机性,如果期望得到稳定、可重现的图像,应该避免采用祖先采样器
这是什么意思呢?
我们简单演示一下方便大家理解,以eular为例,不带a时,使用固定的种子值,以下4张图片是设置不同的采样步数生成的图片(10,20,30,40),可以看到,这4张图片是比较稳定和接近的,
但是选择带a的eular的采样方法,固定的种子值,设置不同的采样步数生成的图片(10,20,30,40),绘制的四幅图片差异更大

带有Karras字样的采样方法,主要的表现在于噪点步长在接近尾声时会更小,这有助于图像的质量提升,所以带Karras的采样方法我们在实际中会使用得比较多
又比如DPM++是对DPM的改进,其结果更准确,但是相应的也会更慢一些。我们在实际中会更多地会使用DPM++
DDIM与PLMS这两种采样方法都已不再广泛使用

另外在后面的模型讲解课程中,我们会提到,某些模型提供的文档已经推荐了应该采用的采样方法,我们按照模型文档的说明选择合适的采样方法即可。
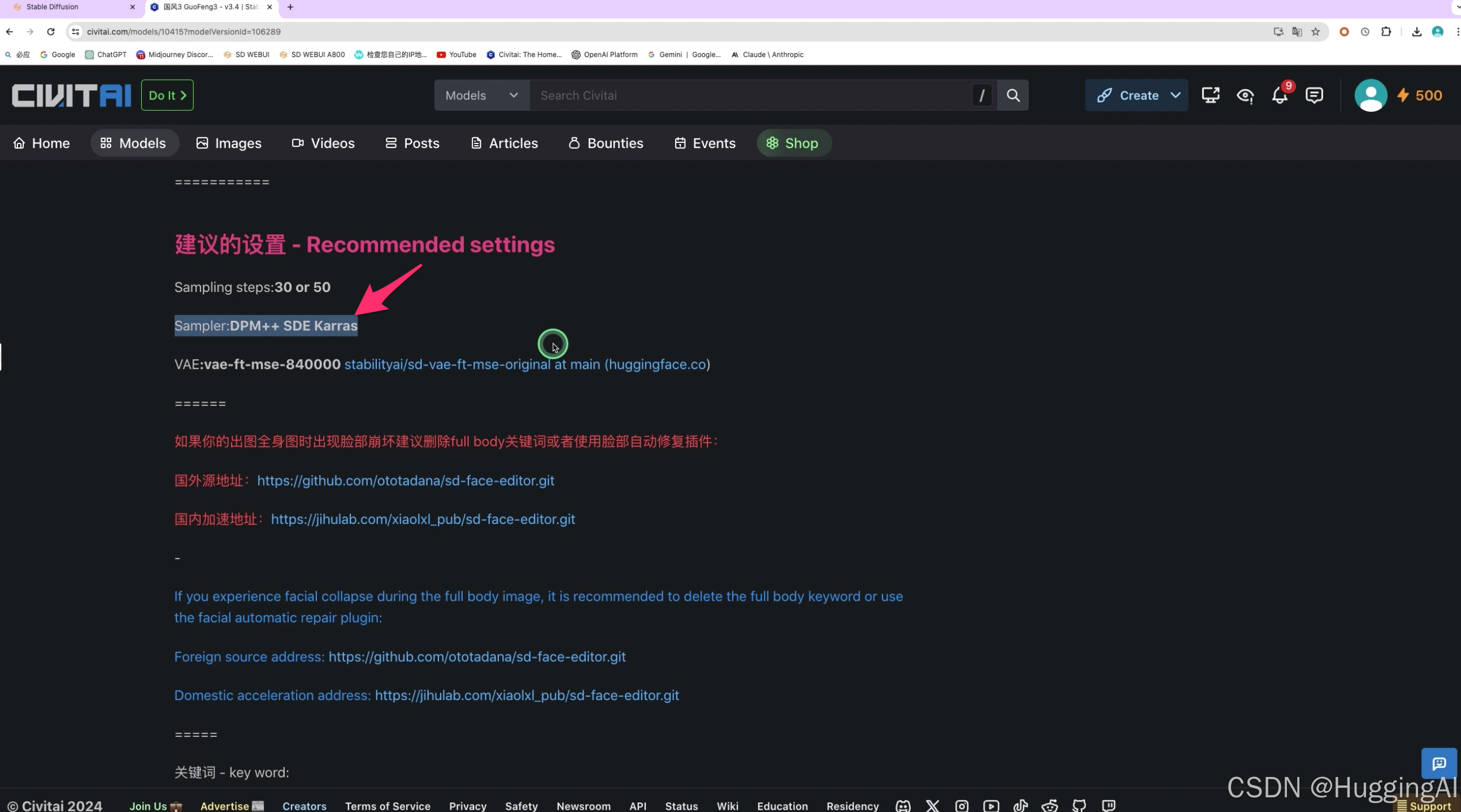
比如我们之前演示的guofeng3模型,选择V3.3,右侧点击show more查看详细说明,可以看到,说明中有特别提到推荐使用DPM++ SDE Karras采样方法。
3.2 高清修复
在采样方法下方是高清修复,这是一个非常重要的选项。
早期模型默认情况stable diffusion生成的是512x512分辨率的图像。这与早期模型stable diffusion训练时所使用的图像数据分辨率有关。这些早期模型,我们如果设置较大的分辨率比如1024*1024,则有可能会生成诡异的图像,

这是因为更大分辨率的图像,stable diffusion可能会用类似拼接的方式去绘制,这个时候就可能出现意向不到的情况。
而我们如果想得到更高分辨率的图像,应该如何做呢?我们可以使用高清修复选项,高清修复实际上是基于低分辨率图片,采用一定算法扩充图片的像素细节,从而生成更高分辨率的图片,
我们在使用时先点击高清修复前的复选框,并点击右边的下拉按钮,界面上会展开与高清修复相关的一些额外选项,
首先需要选择放大算法,放大算法也有很多,比如潜变量,R-ESRGAN,scuNET,这些算法更偏重于底层技术,我们不在这里详细讲解这些算法的细节,但会在另外的文章中详细介绍这些算法的特征。
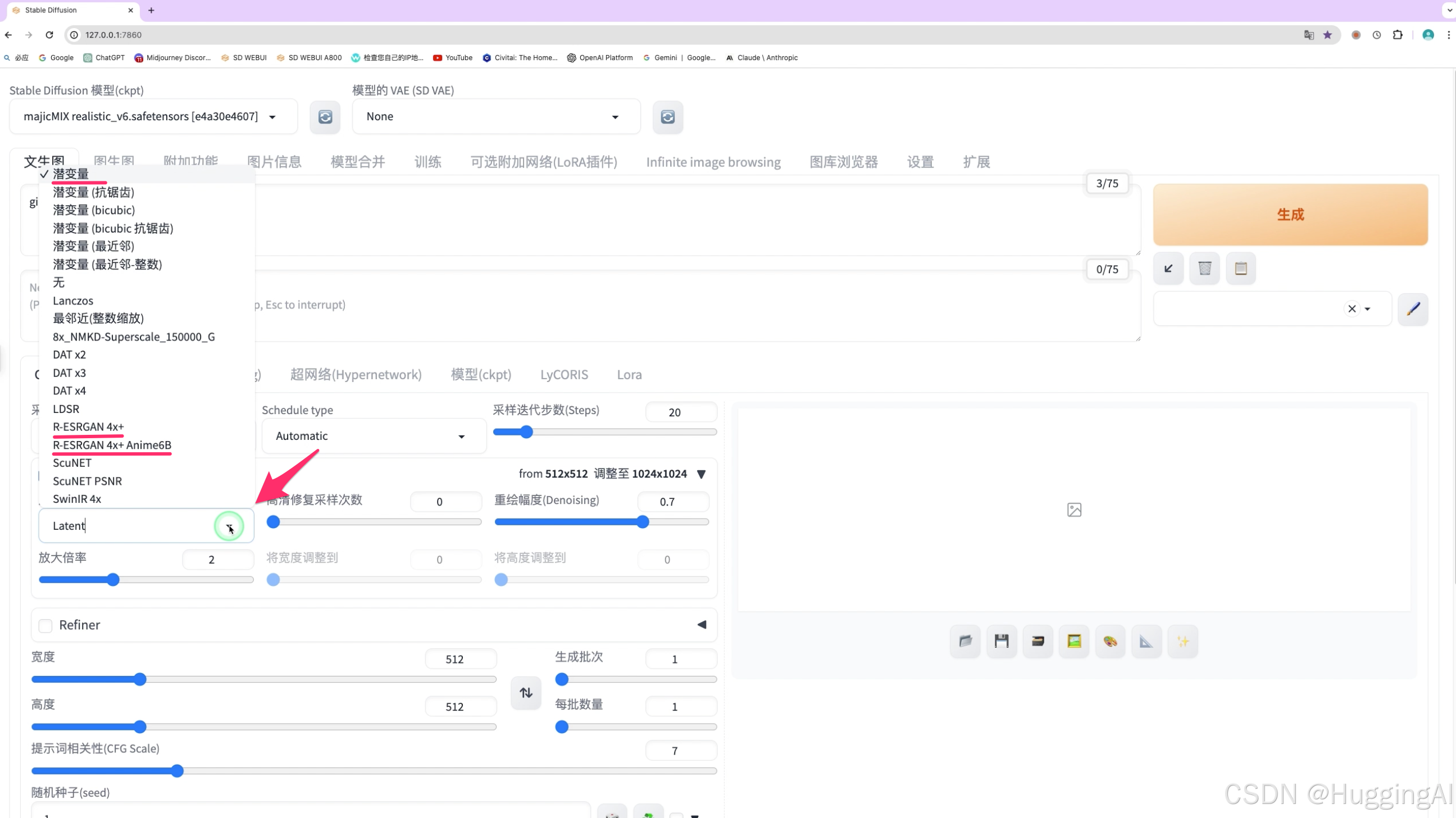
这里简单讲述一些常用的放大算法,
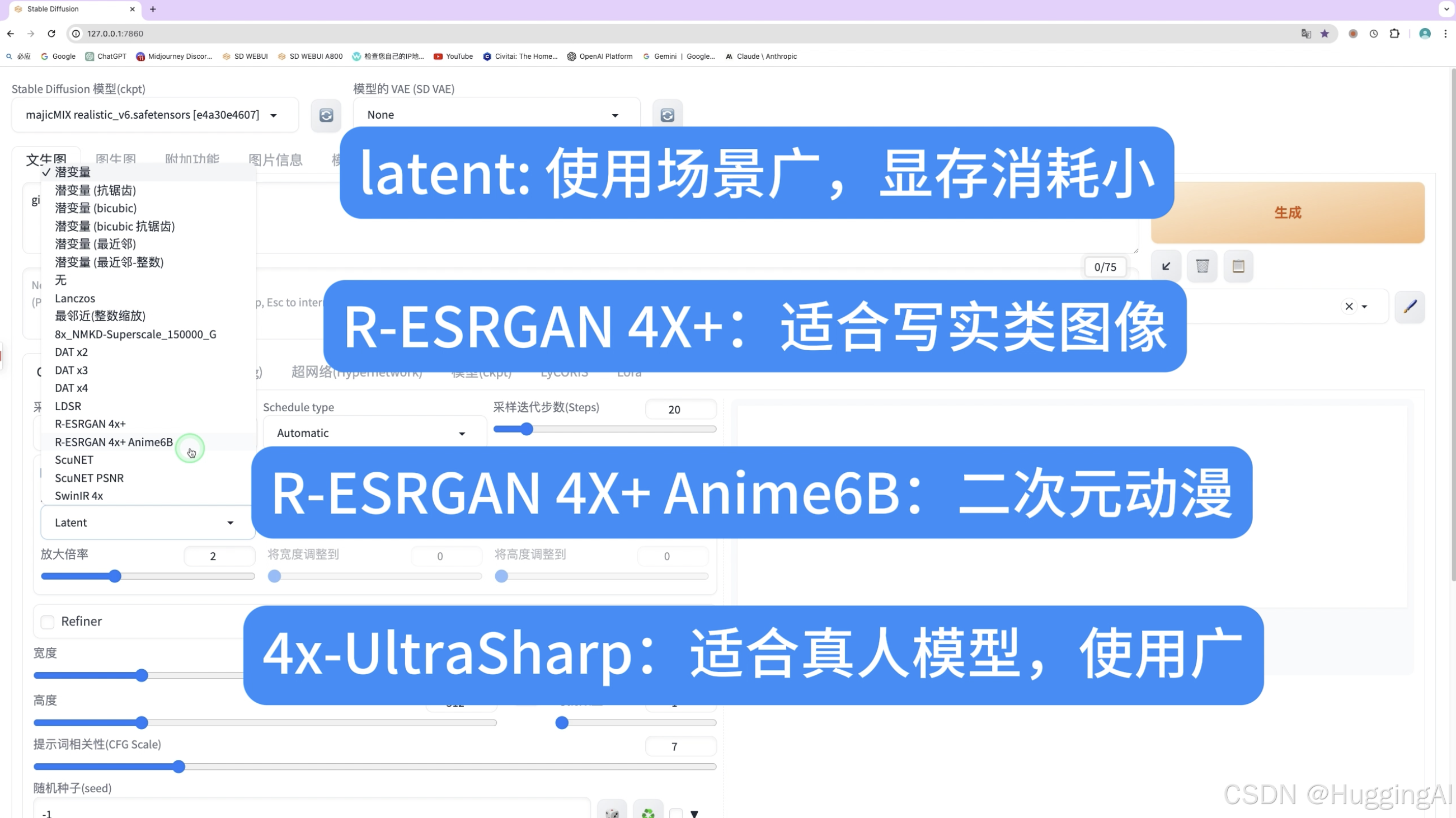
潜变量latent放大算法,该算法使用场景比较广,显存消耗较小,但效果不是最优,
R-ESRGAN有两个相关放大算法,照片等写实类图片我们推荐使用第一个,如果是二次元动漫图片则推荐带有anime关键字的算法(用R-ESRGAN 4x+ Anime6B)
另外还有一些放大算法默认是没有的,需要自行安装
比如4x-UltraSharp这个放大算法在stable diffusion中非常受欢迎,该算法基于ESRGAN做了优化,适合常见的图片格式,尤其对真人模型非常适合。
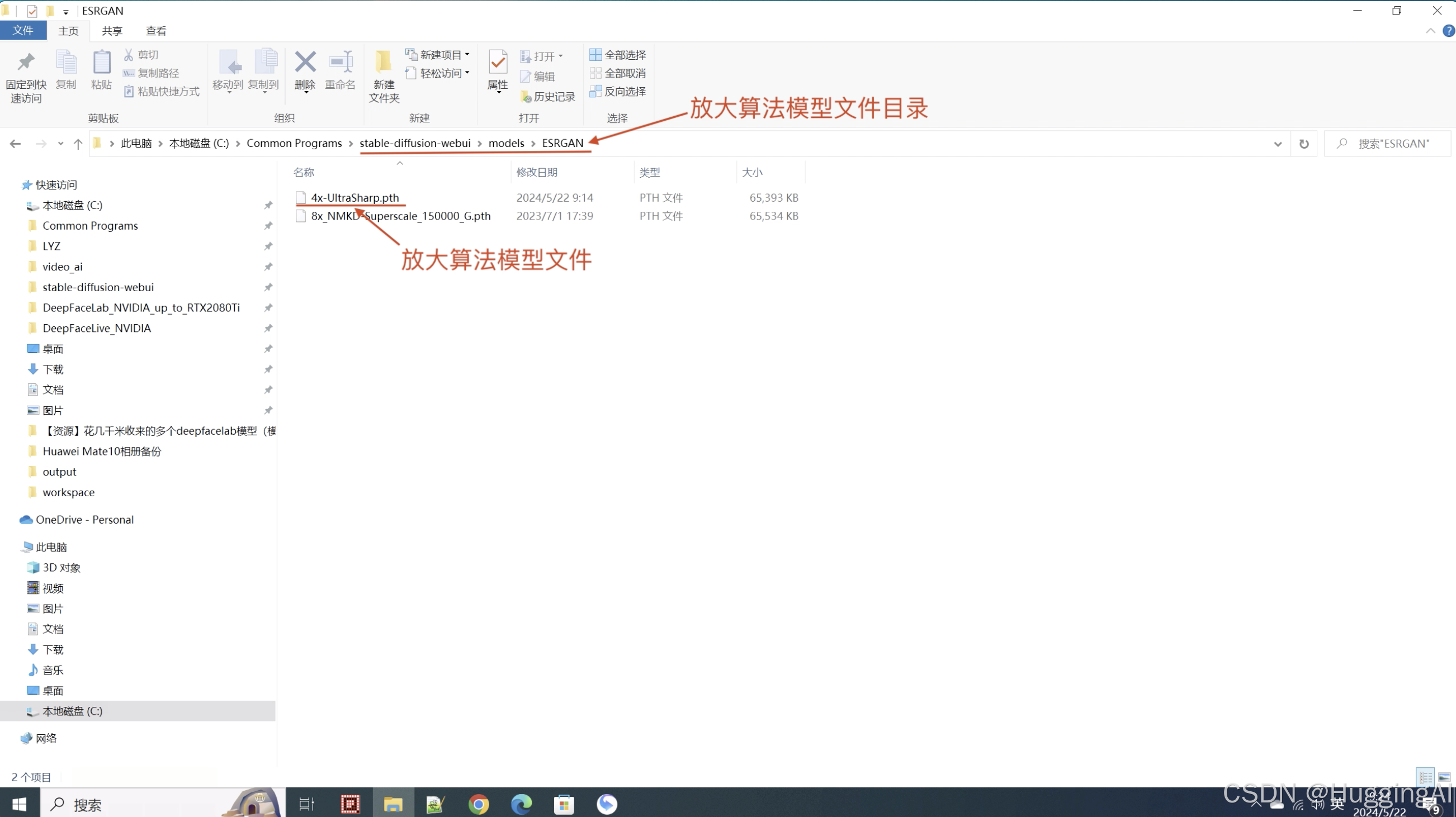
安装4x-UltraSharp放大算法很简单,这需要将算法模型文件放置到stable-diffusion-webui程序主目录中的models文件夹下的ESRGAN子文件夹即可,放置后注意需要重启webui。
高清修复采样次数,设置为0时,采用默认值,这个参数一般不用调整。
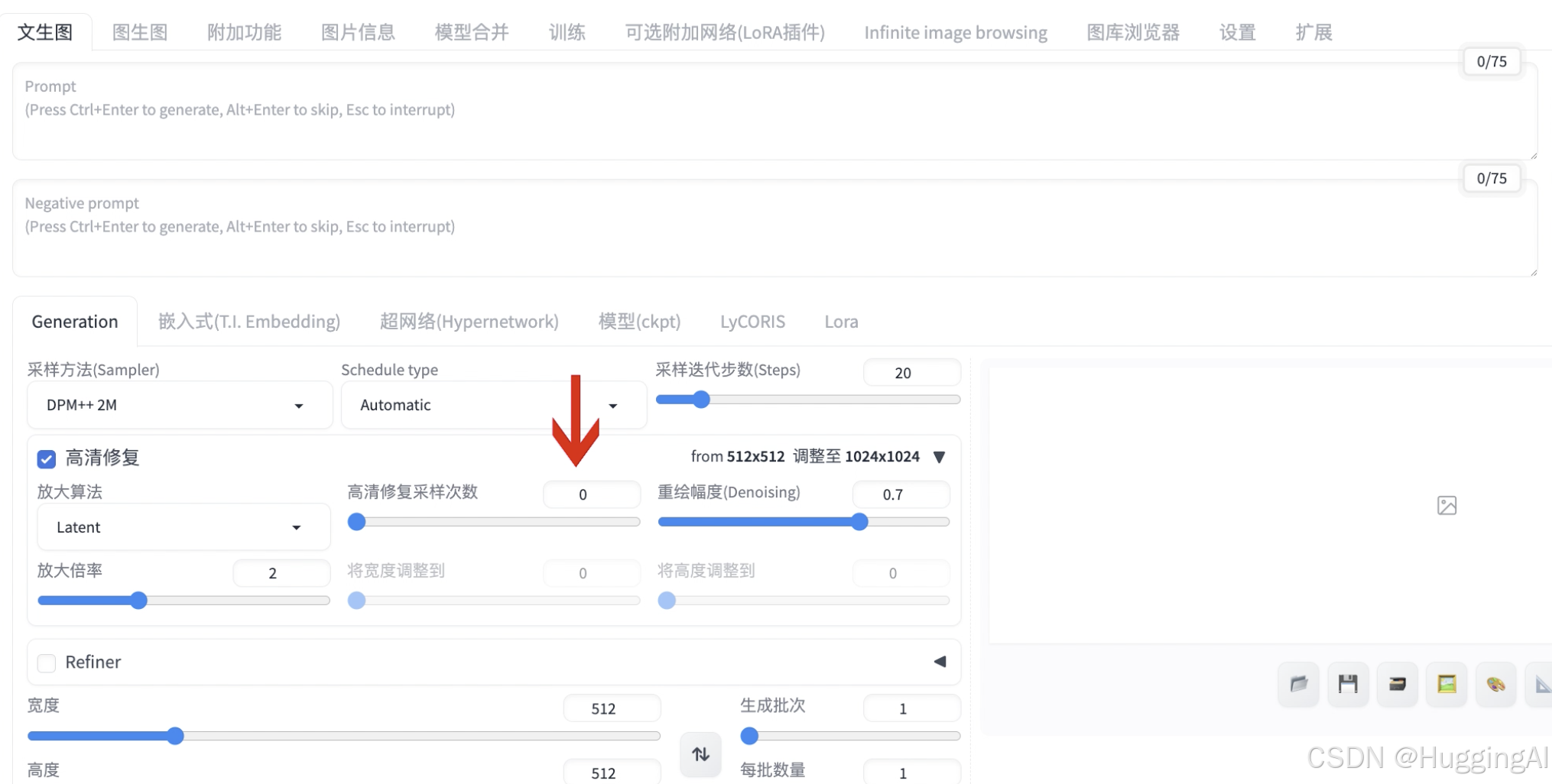
重绘幅度(Denoising):一般0.4~0.7比较好,可以自己尝试调整。重绘幅度越高,那么放大生成的图片就会与原图相差甚远。
重绘幅度如果设置为0,是否是不重绘了,答案是否定的。如果希望不重绘图片而增加分辨率可以使用附加功能中的图片放大功能,这个我们会在另外的课程中演示。
放大倍率,可以设置分辨率放大倍数,默认为2,需要注意的是,开启高清修复,生成的图片分辨率更高,绘制图片时的显存占用也会增加,对于低显存用户,即使开启了xformer,也可能在生成过程中因为爆显存失败,如果希望生成更高分辨率图片同时不明显增加显存占用,我们可以使用一些另外的扩展插件,比如ultimate sd scale, tile diffusion等等。
以下是使用了上述高清修复选项生成的1024X1024分辨率的图片,可以看到,这个时候,图片生成不会再出现异常的情况,同时图片分辨率也得到了提升。

高清修复能够帮助提高早期模型的图片分辨率,而对于SDXL模型和SD3模型,由于stable diffusion在训练时采用的图像数据分辨率更高。在使用更新的SDXL或SD3模型时,默认即可使用1024*1024分辨率,当然对于SDXL或SD3模型仍然可以使用高清修复进一步提升图片的分辨率。
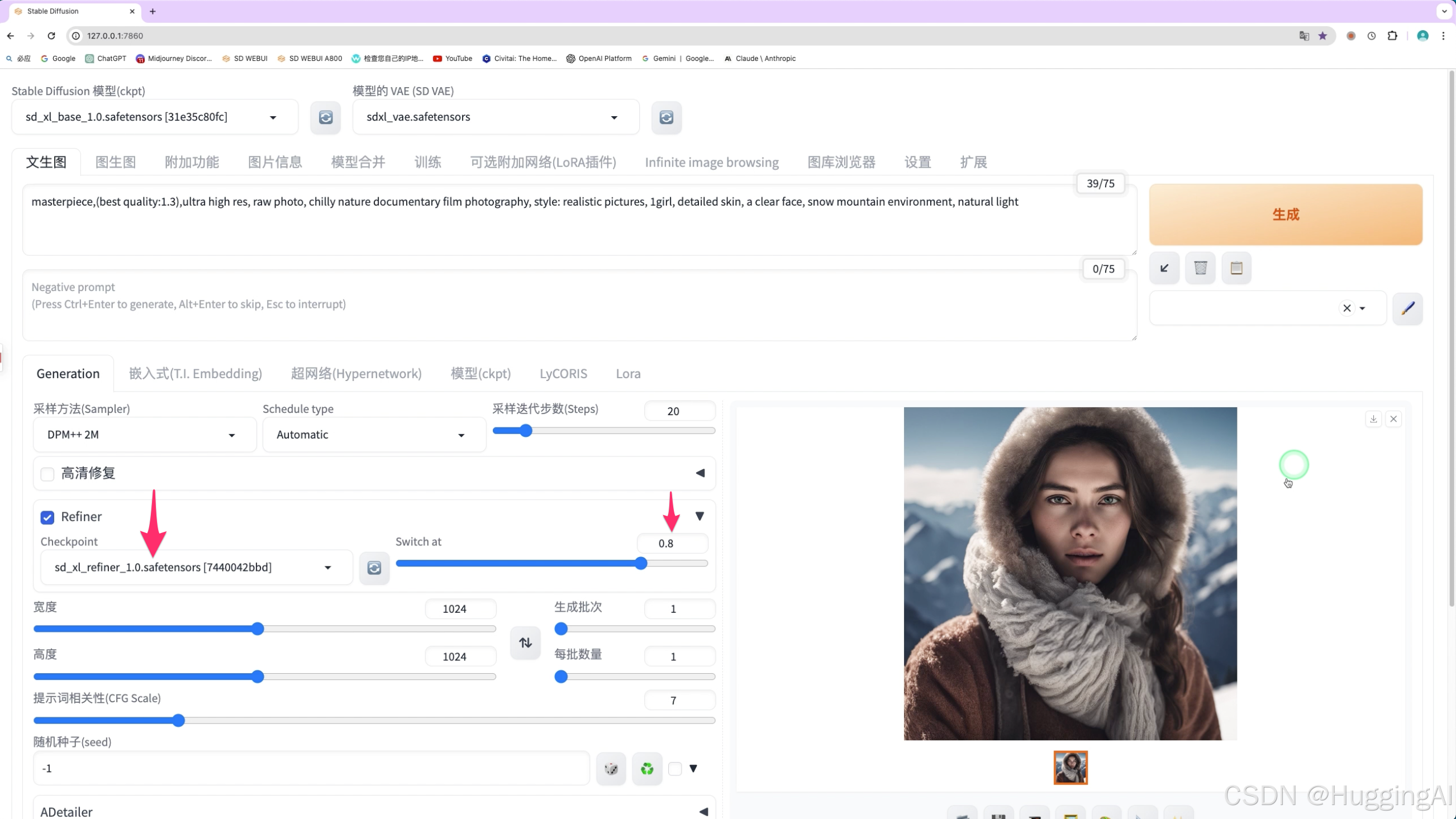
3.3 refiner
refiner, refiner是在1.6.0版本的stable diffusion webui增加的选项,
使用sdxl模型绘制图片时,实际上更推荐采用一种两步走的生图方式,先用1个基础模型生成一张看起来差不多的图片,然后再使用一个精修模型把它打磨的更漂亮,我们可以在页面左上角选择使用的基础模型,而借助refiner选项,定义使用的精修模型。比如刚刚使用的提示词,我们点击refiner前的复选框,并点击下拉图标展开refiner选项,refiner选项中我们选择使用的精修模型,这里选择sd_xl_refiner模型,然后switch at可以设置精修模型介入的时机,我们这里设置为0.8,代表在80%采样步数开始,使用选择错sd_xl_refiner模型,点击生成按钮,按上述方式生成的图片通常都会更加的精细。

3.4 图像宽度和高度
高清修复和refiner下方是图像宽度和高度选项,这两个选项用于设置原始图像的分辨率。
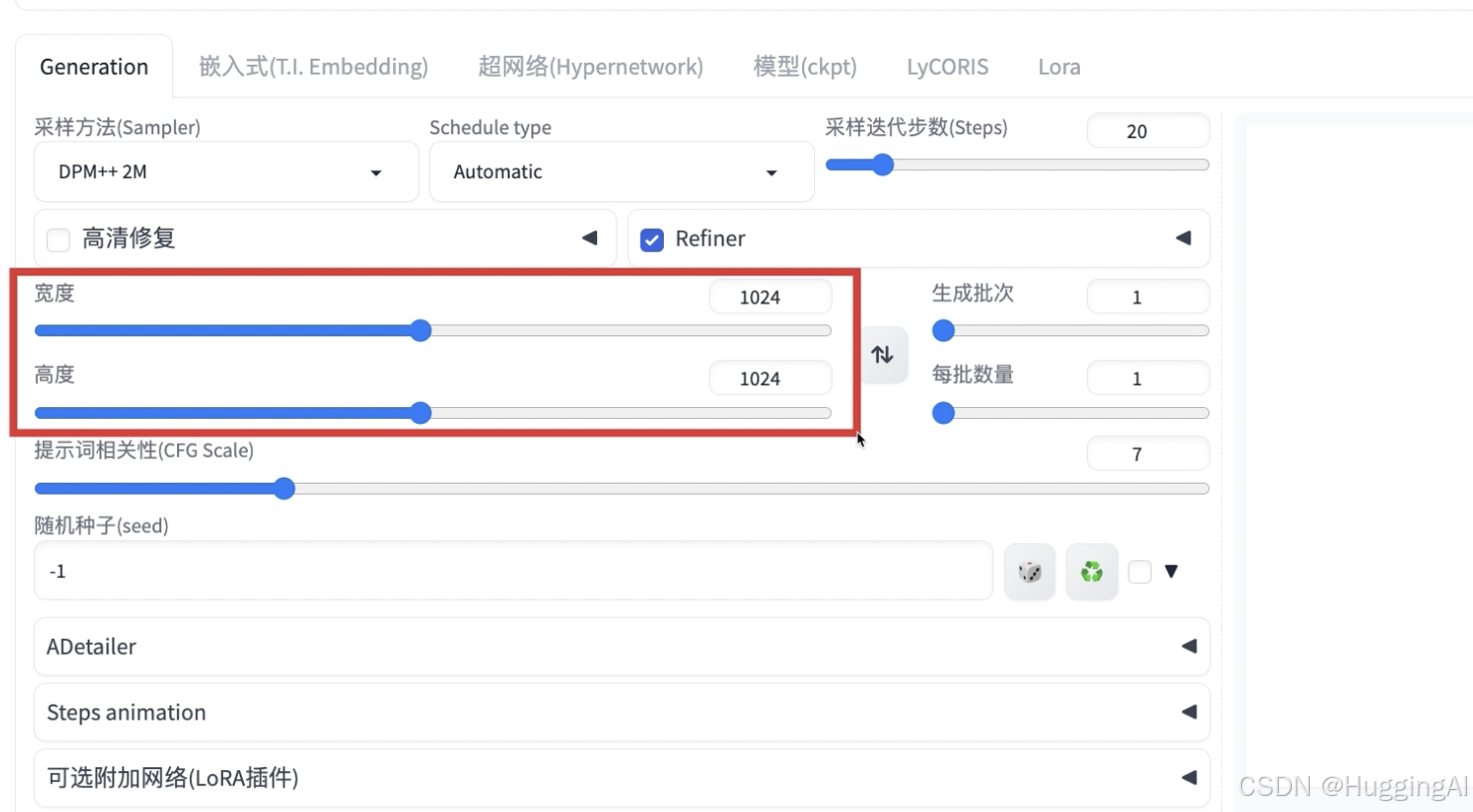
早期模型默认使用512x512,我们也可以使用其他比例,比如768*576(4:3比例),768*432(16:9比例),但是如之前所述,早期模型不宜设置过大的分辨率入1024*768(4:3比例),因为除了需要占用更多的显存,也可能导致奇异的图片输出。如果需要大分辨率图片,可以使用高清修复,或者后续课程中会讲到的附加功能中的放大算法。而对于sdxl模型和sd3模型,则可以设置1024*1024的分辨率,因为sdxl模型在训练时使用了较高分辨率的图片。
3.5 生成批次,每批数量
宽度与高度设置右边是生成批次与每批数量设置
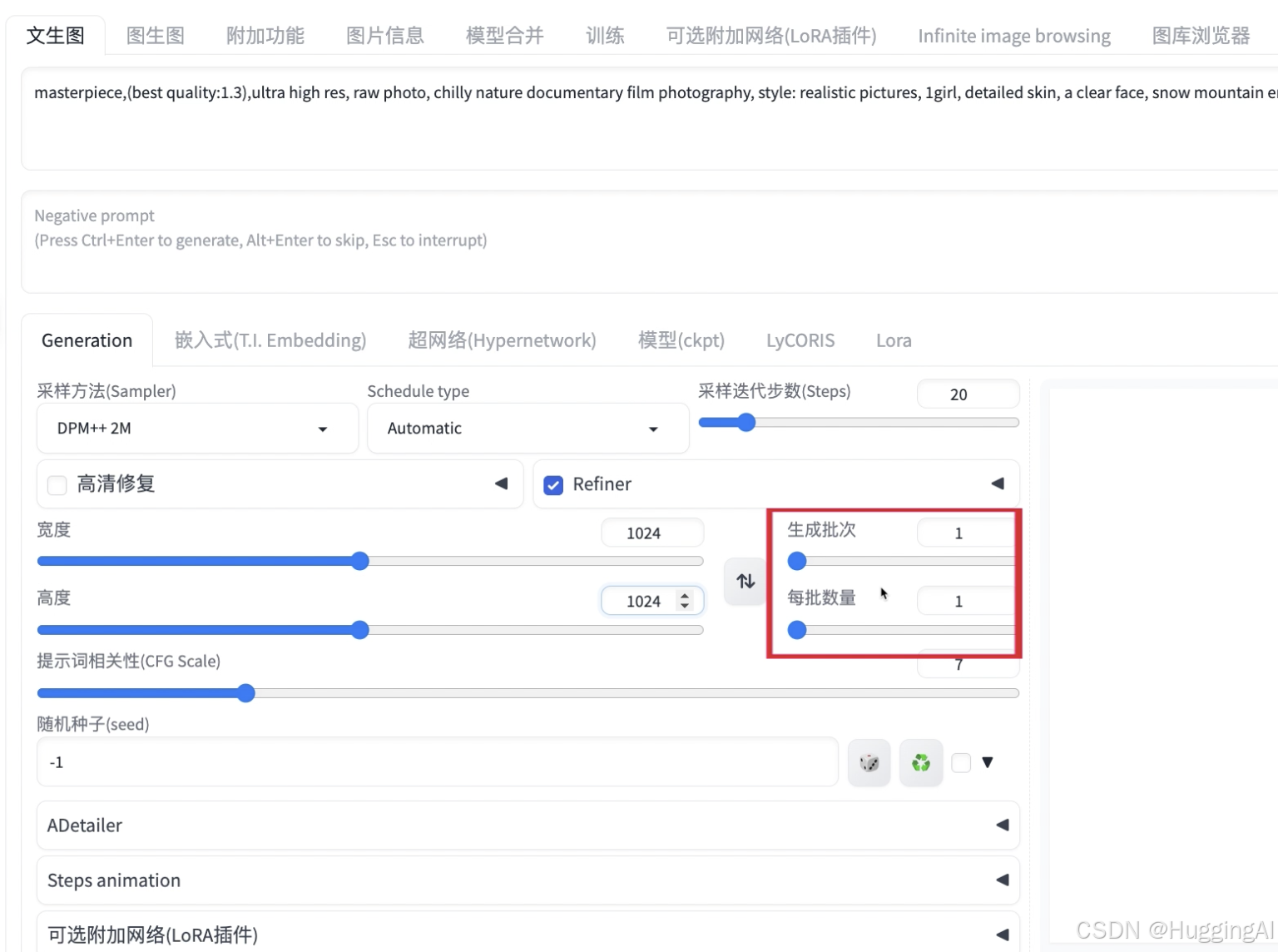
生成批次用于设置点击生成按钮显卡执行几次绘画操作
每批数量就是显卡每次同时绘制多少副画,该数值设置越高,对显存需求也会更高
增加批次和数量可以达到批量出图的效果,增加每批数量,会增加显存占用,如果GPU显存配置较高,可以通过提高该数值来提升出图效率
3.6 提示词相关性
宽度与高度下方是提示相关性(CFG Scale)选项,该选项用来调节提示文本对图片扩散过程的引导程度,提示相关性数值越高,提示词对绘制图片的影响越大。
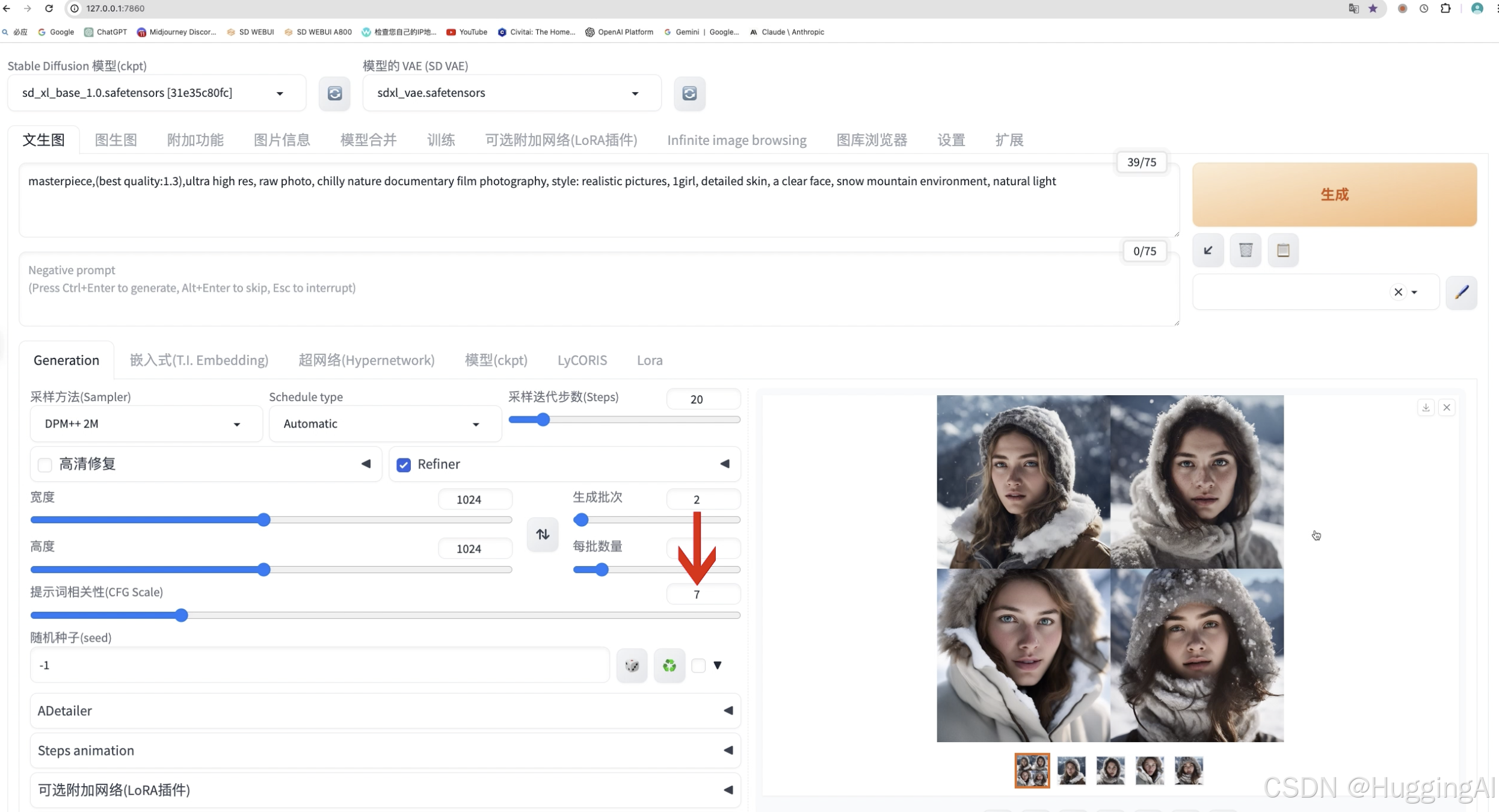
目前,提示相关性可以设置为1-30,这个数值并不是越高越好,尤其对于早期的sd1.5和sd2.1模型,如果设置过低或过高出图都会比较奇怪,比如我们这里使用了同样的提示词和随机种子值,我们设置为默认值7,可以看到,此时出图的效果还不错。
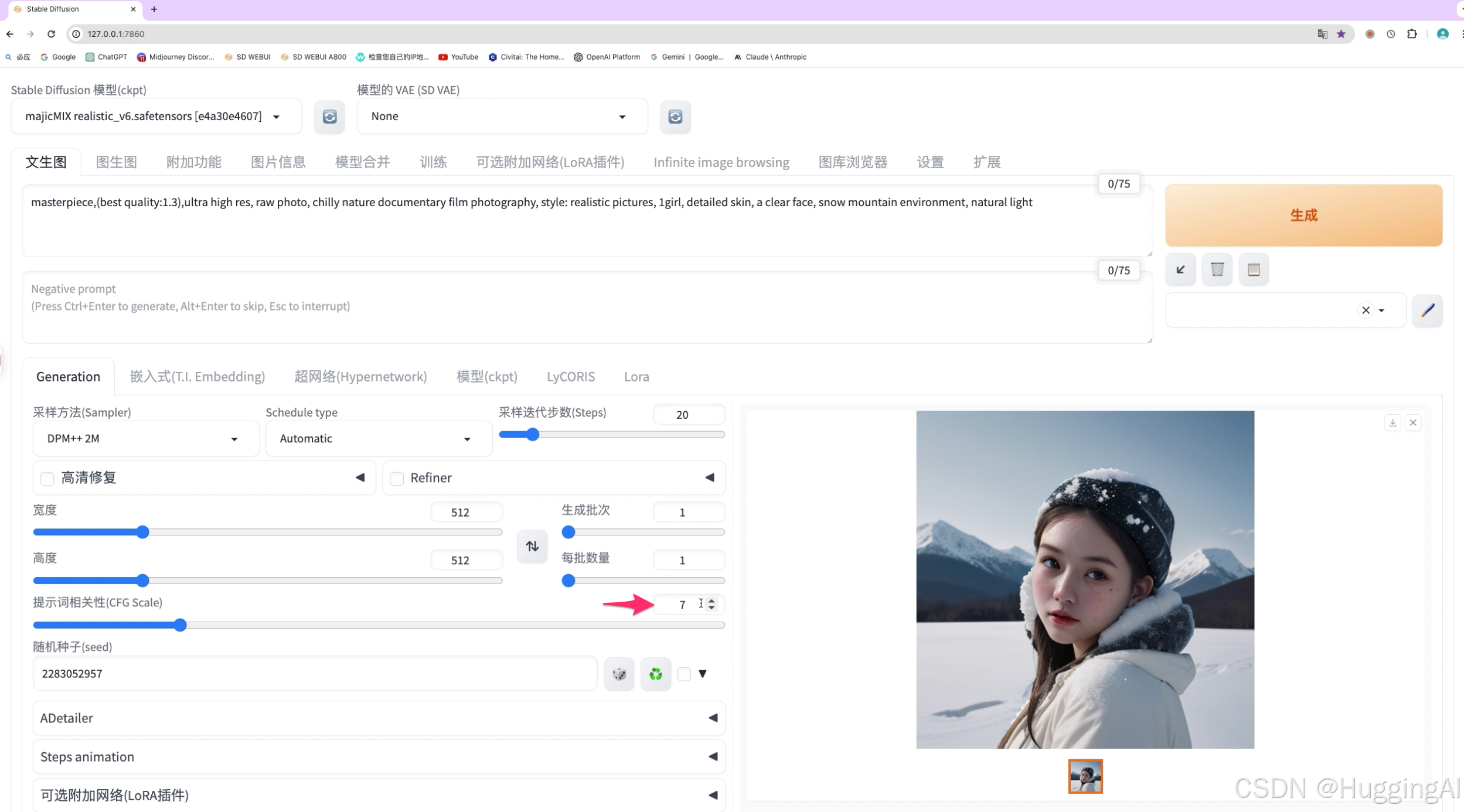
但我们设置较高的值,可以看到所绘制的图片色彩上就有一些不够自然了。
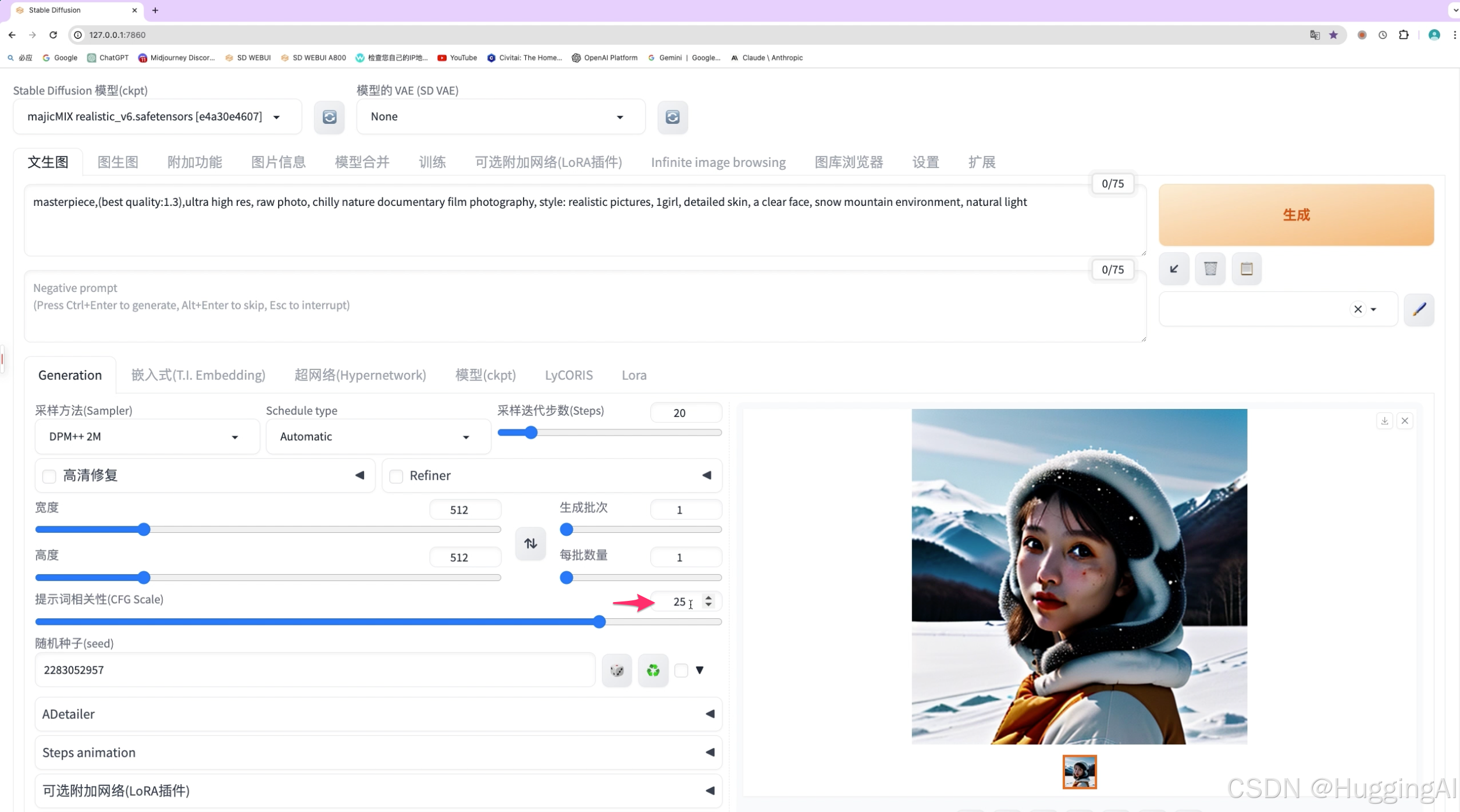
而设置为较小的值1时,绘制的图片也有些奇怪。
对于sd1.5和sd2.1模型,一般来说取7-12出图效果会比较好,应该避免使用过低或过高的提示词相关性值。
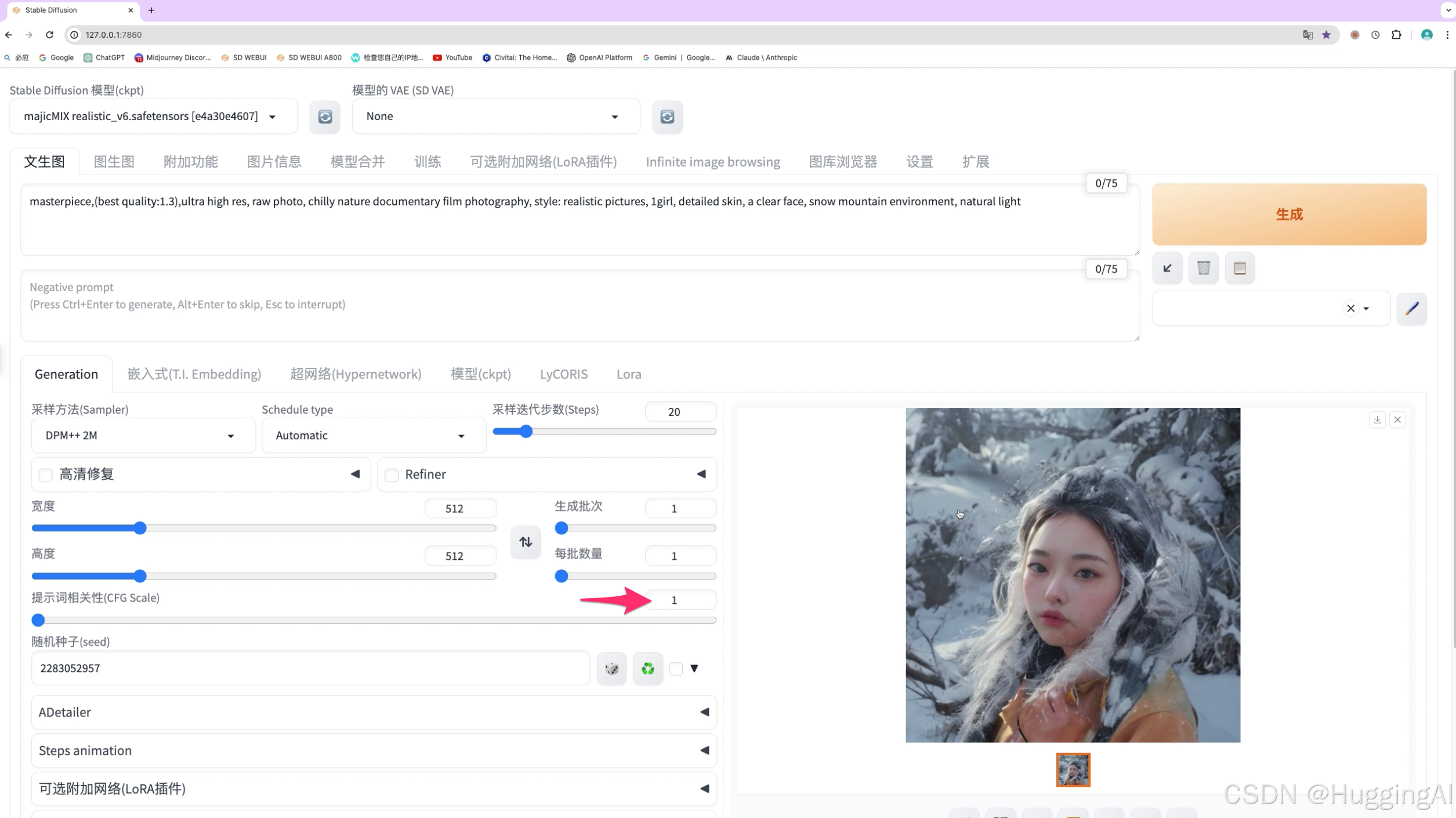
而对sdxl模型,该模型出图相对更加稳定,所以对提示相关性值的适应性更高。比如我们这里使用较高提示词相关性值25,也能获取较好质量的图片。
3.7 随机种子
提示词相关性下方是随机种子设置
我们之前在midjourney的课程中有讲述过种子值seed,与midjourney类似,stable diffusion在绘图时也会引入一个种子值,该种子值将影响扩散模型在后向去噪过程中如何去复原图像。
种子默认值是-1,这表示stable diffusion会随机选择种子值生成图片,我们如果使用-1,再次点击生成按钮时,会生成一幅完全不同的图像。
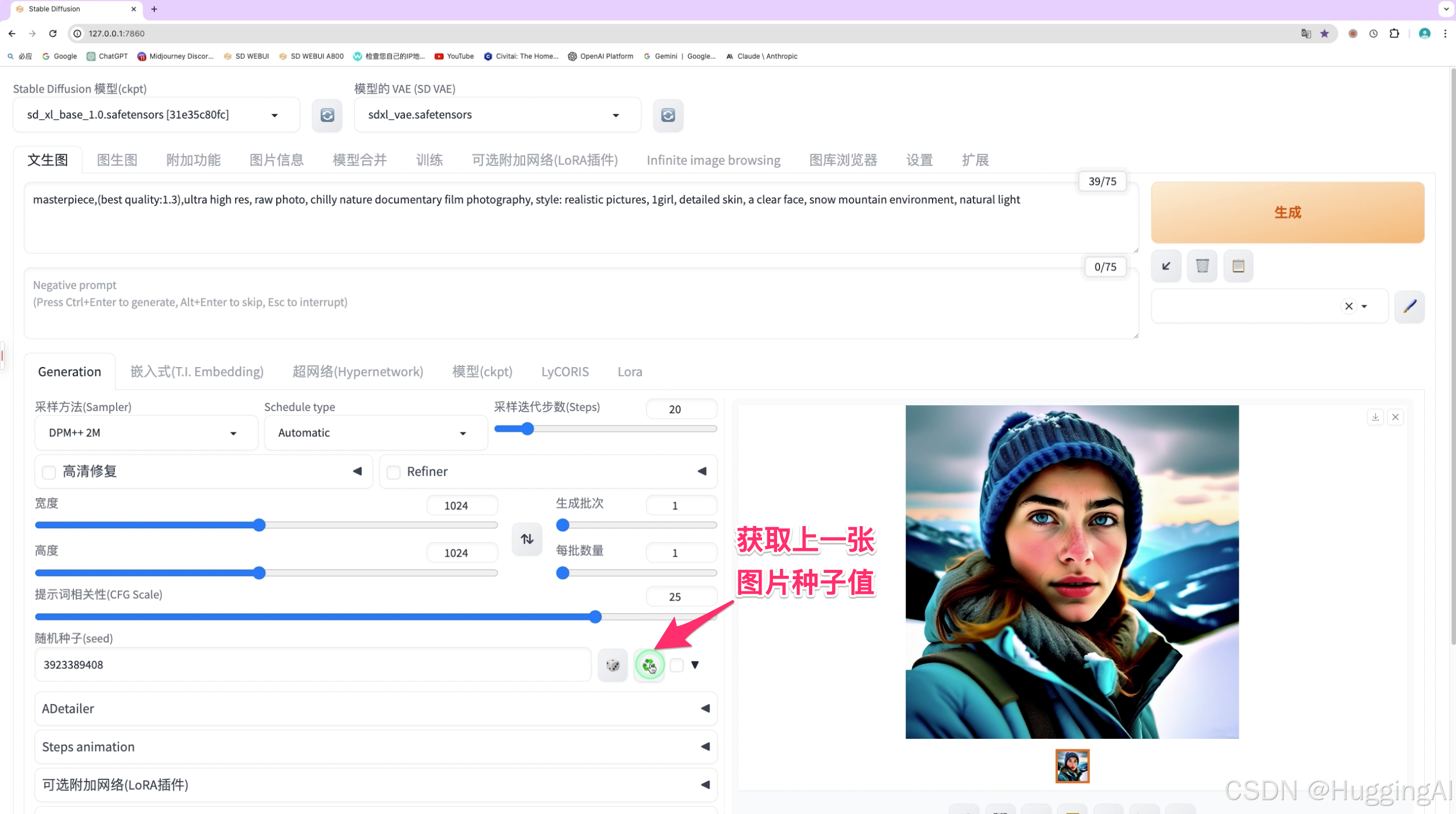
那么如何生成完全一样的图像呢,我们可以点击第二个绿色循环图标按钮,获取上一幅图像的随机种子值,然后点击生成,在提示词以及其他参数不变的情况下,使用相同的随机种子值,将生成相同的图像。
我们还可以通过生成图像中下方的图片信息获取种子值,下方文本中的seed后的数值即为生成图像时使用的种子值。
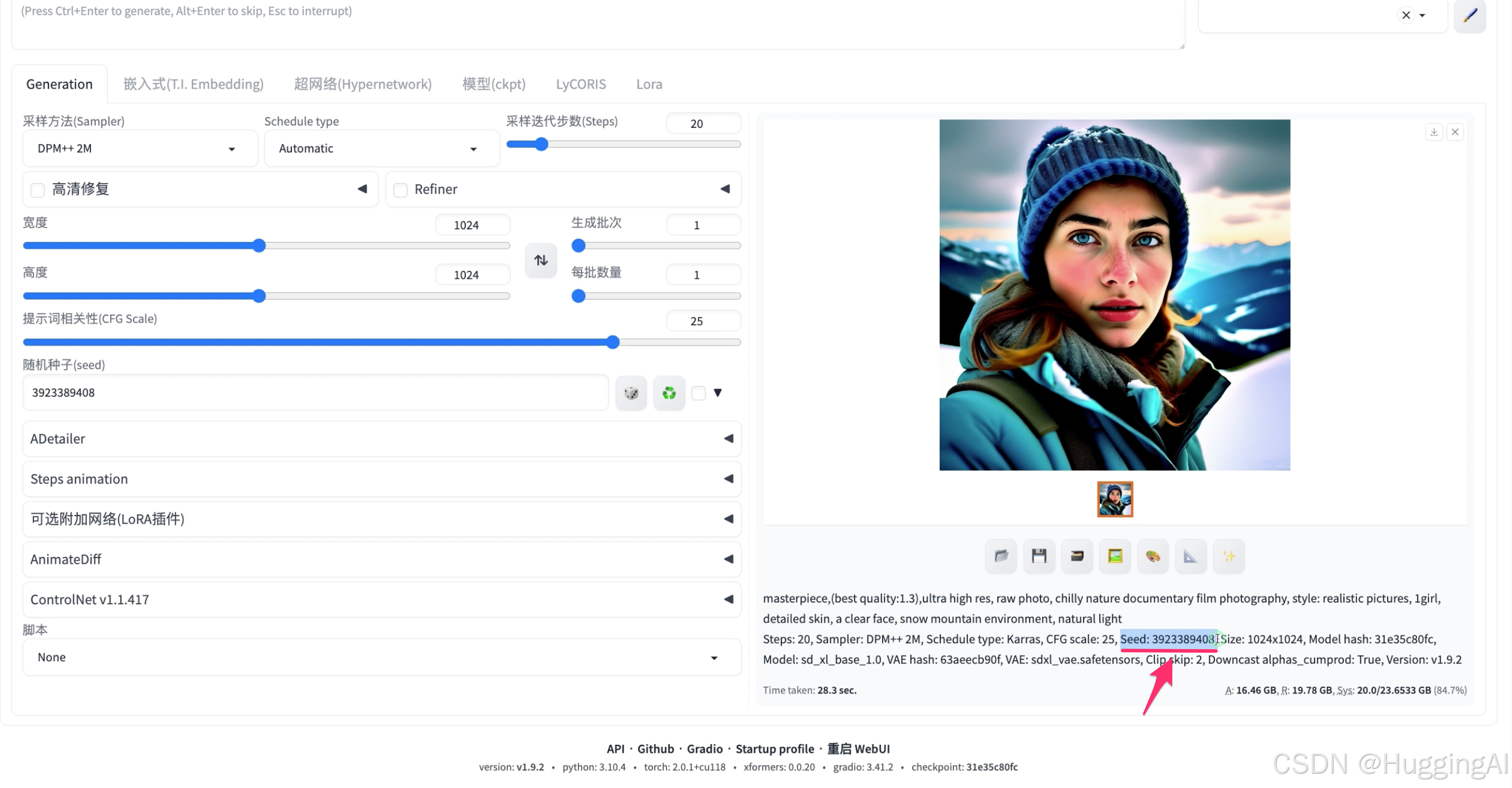
点击骰子图标,可以快速将随机种子值设置为默认值-1。

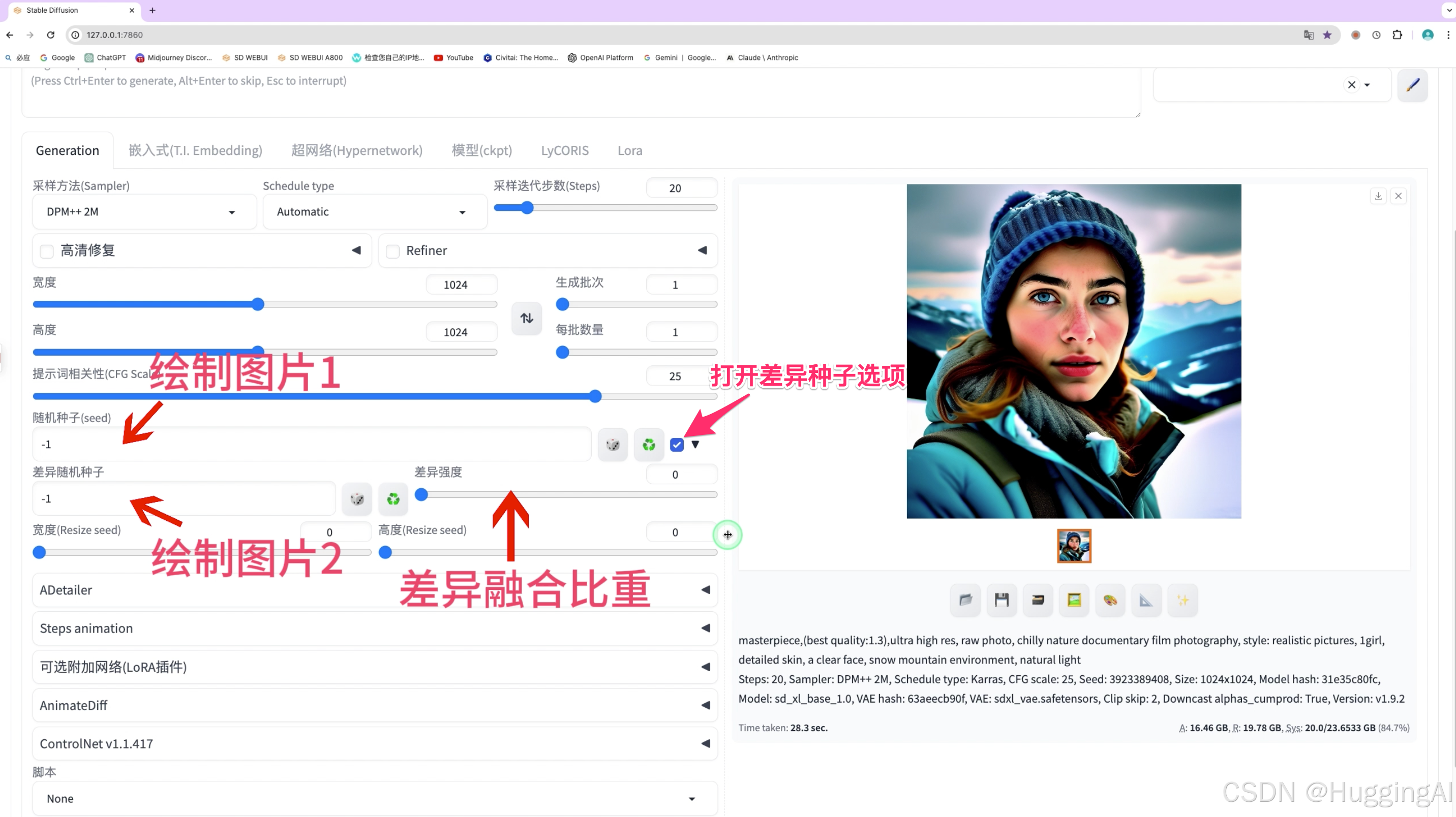
3.8 差异种子
在循环图标按钮后面的复选框可以打开差异种子设置选项
通过差异随机种子可以结合两张图片的特征来绘制图片,我们可以简单理解一下,通过随机种子生成的图片为图片1,通过差异随机种子生成的图片为图2,差异随机种子可以融合两张图的特征,差异强度越靠近左侧0生成的图片越像图1,差异强度调整到右侧1就越像图2;
差异随机种子和实际种子一样可以设置为-1,表示随机生成种子值,也可以设置为固定的值。
使用差异随机种子有什么应用场景呢?
基于差异随机种子的原理,一旦我们生成了一张或者两张较为满意的图片,我们可以使用差异选项去生成新的图片,新的图片会基于差异强度采纳原图特征。
我们演示一下,这里我们生成了一幅很喜欢的人物图片,
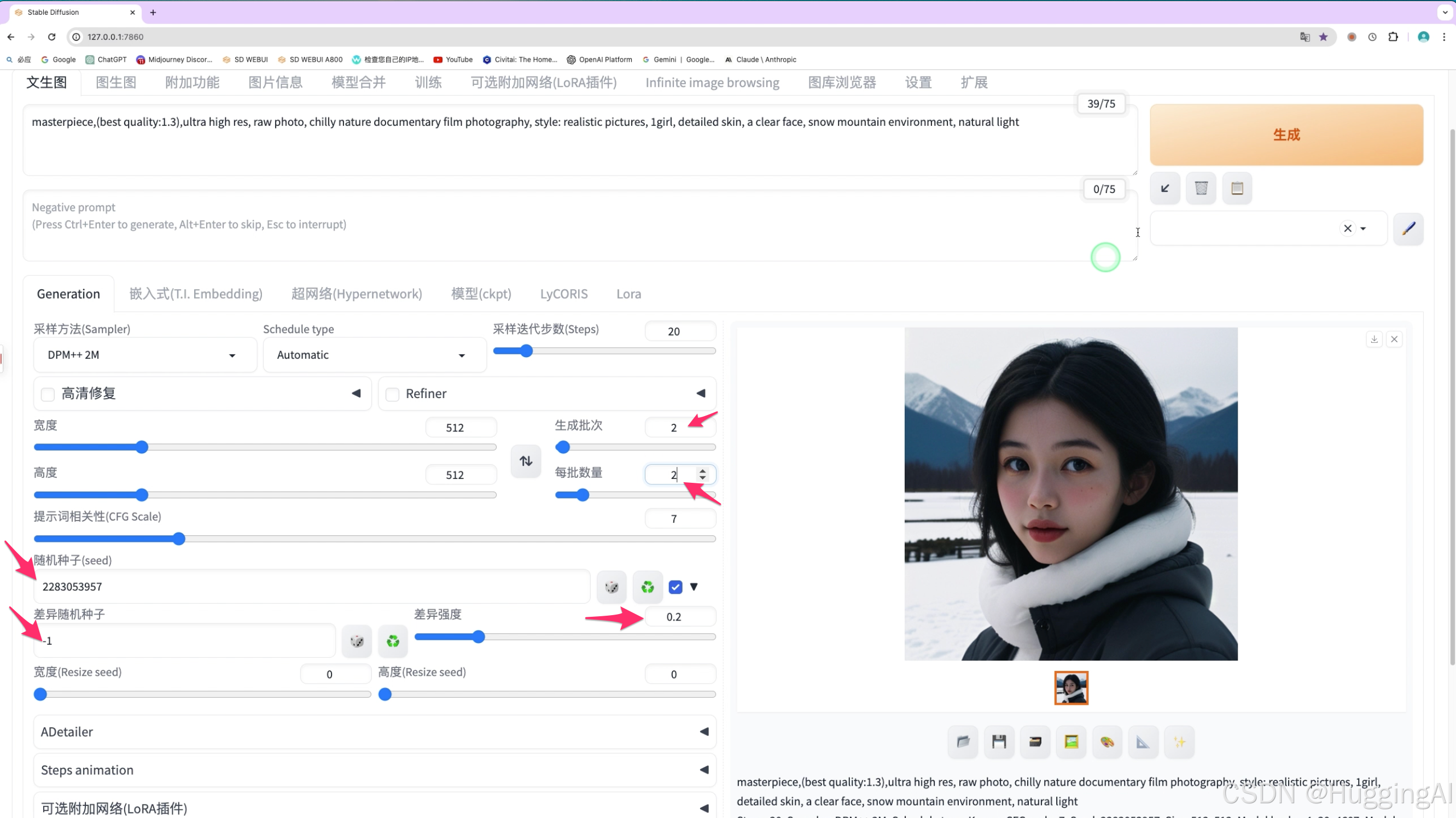
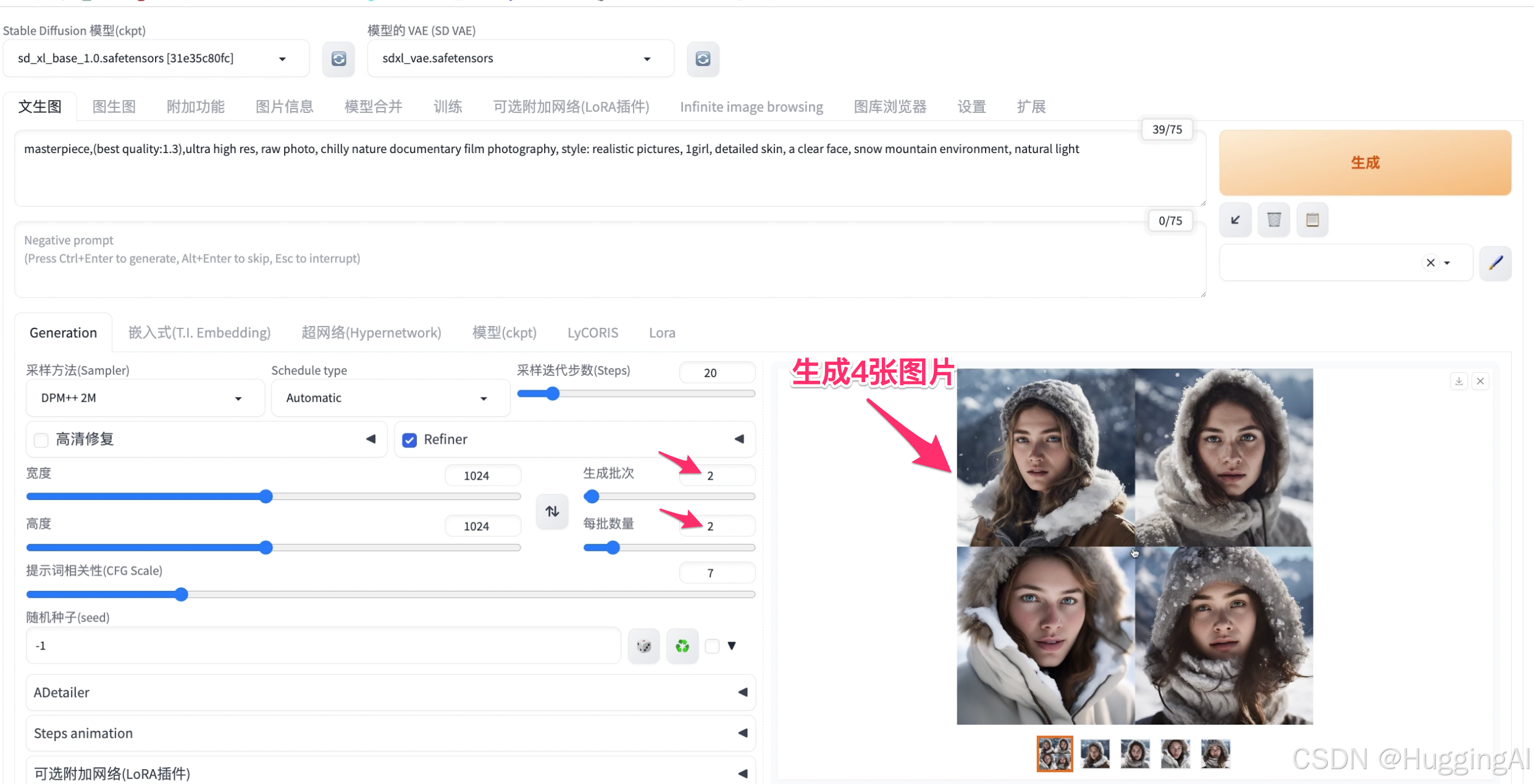
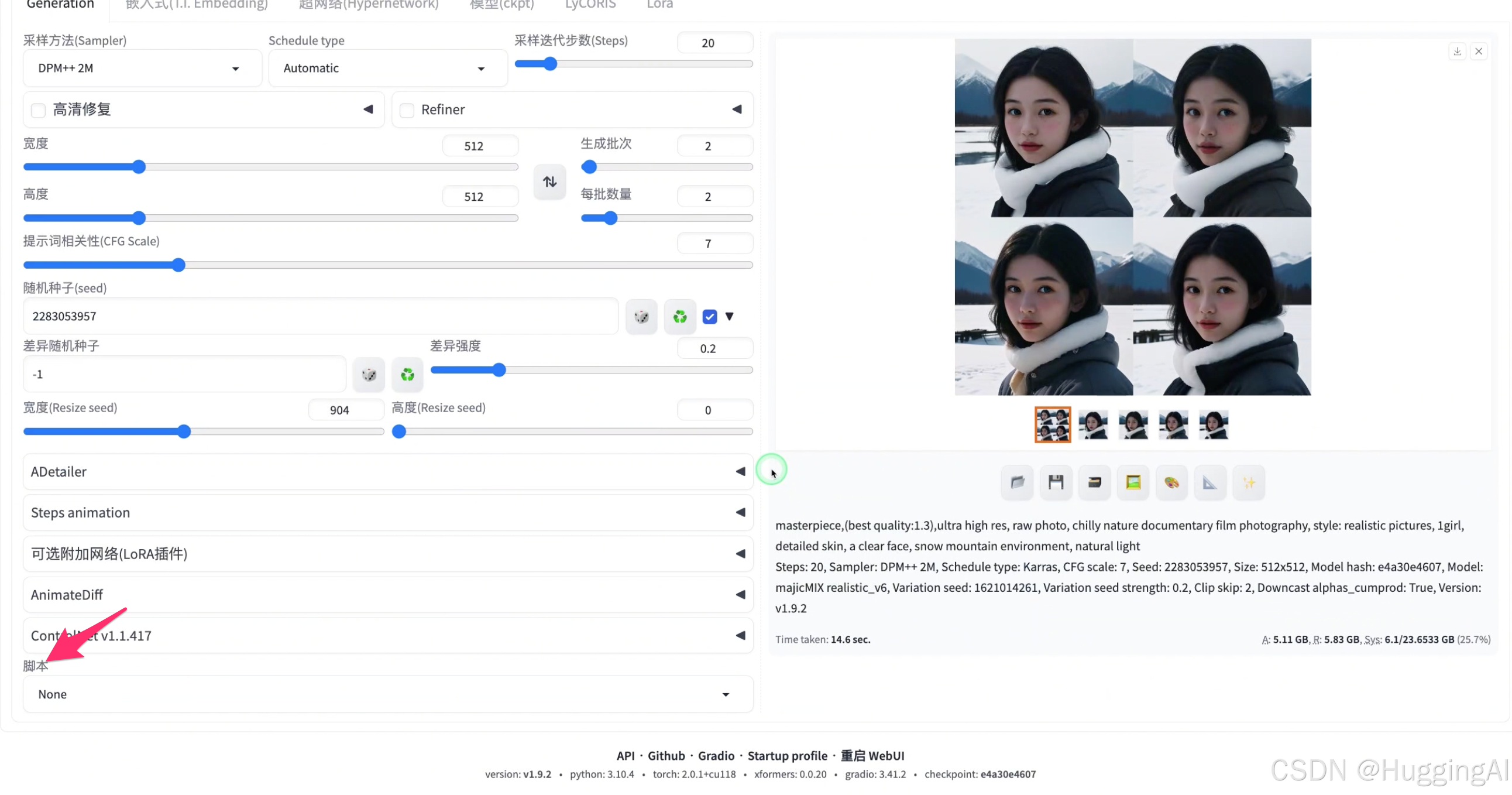
我们在随机种子这里固定其种子值,同时开始差异随机种子选项,差异随机种子使用-1,差异强度设置为0.2,然后设置生成批次为2,每批数量为2,让stable diffusion一次帮我们绘制4幅图片,点击生成:

可以看到,因为差异强度设置为0.2,所以新生成的四幅图片发生了变化但都与固定随机种子生成的图片相似,我们回想一下midjourney中的vary生成图片变体功能,
在stable diffusion里,可以借助差异随机种子实现类似的功能,且stable diffusion对生成变体图片具有更强的可控性。
差异随机种子下方的宽度和高度影响的是潜空间噪声画布的大小,通过调整宽度和高度值,可以影响最终图片的绘制,一般情况我们不用修改。
3.9 脚本选项
在选项栏的最下方,还有一个脚本选项,脚本工具可以帮助我们使用不同的提示词或选项批量绘制图片,是提高stable diffusion出图效率的重要手段
我们讲解一下stable diffusion最常使用的三个脚本工具: 提示词矩阵、批量提示词和X/Y/Z图表
3.9.1 提示词矩阵
一:我们先看一看提示词矩阵,该脚本工具可以用于评估提示词采用不同融合方式时如何影响出图效果
使用方法是用竖线分隔提示词可变部分
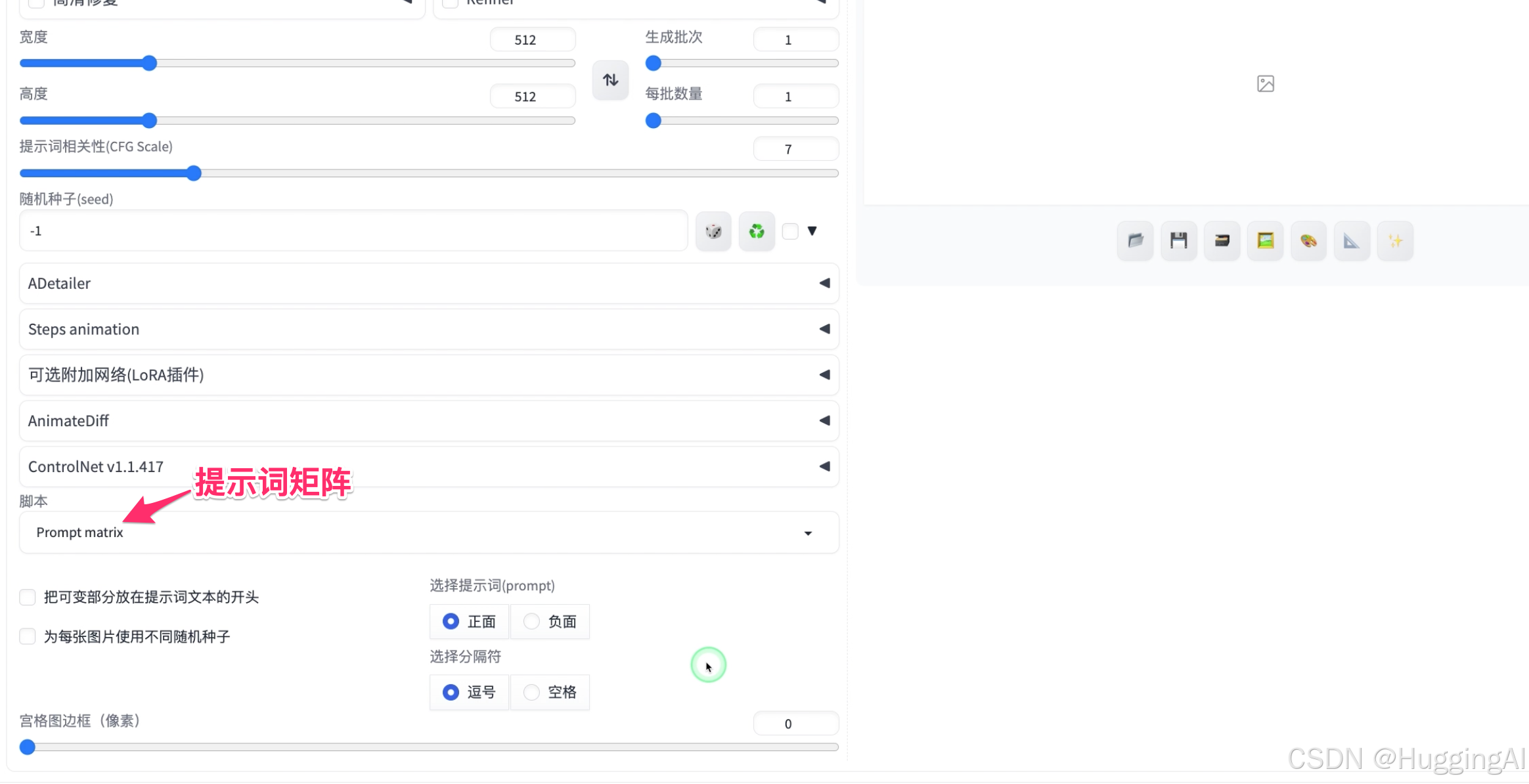
我们使用之前简单的提示词 1 girl,然后换行,输入
|photo|oil painting
这里给出了两个用竖线分隔的词|photo|oil painting,stable diffusion会以矩阵的形式将词添加到提示词中,然后依次生成图片,因为会多次生成图片,所以耗时会长一些。当然我们可以使用竖线分隔多个词,这样会构造更大的矩阵,生图时间也会更长。
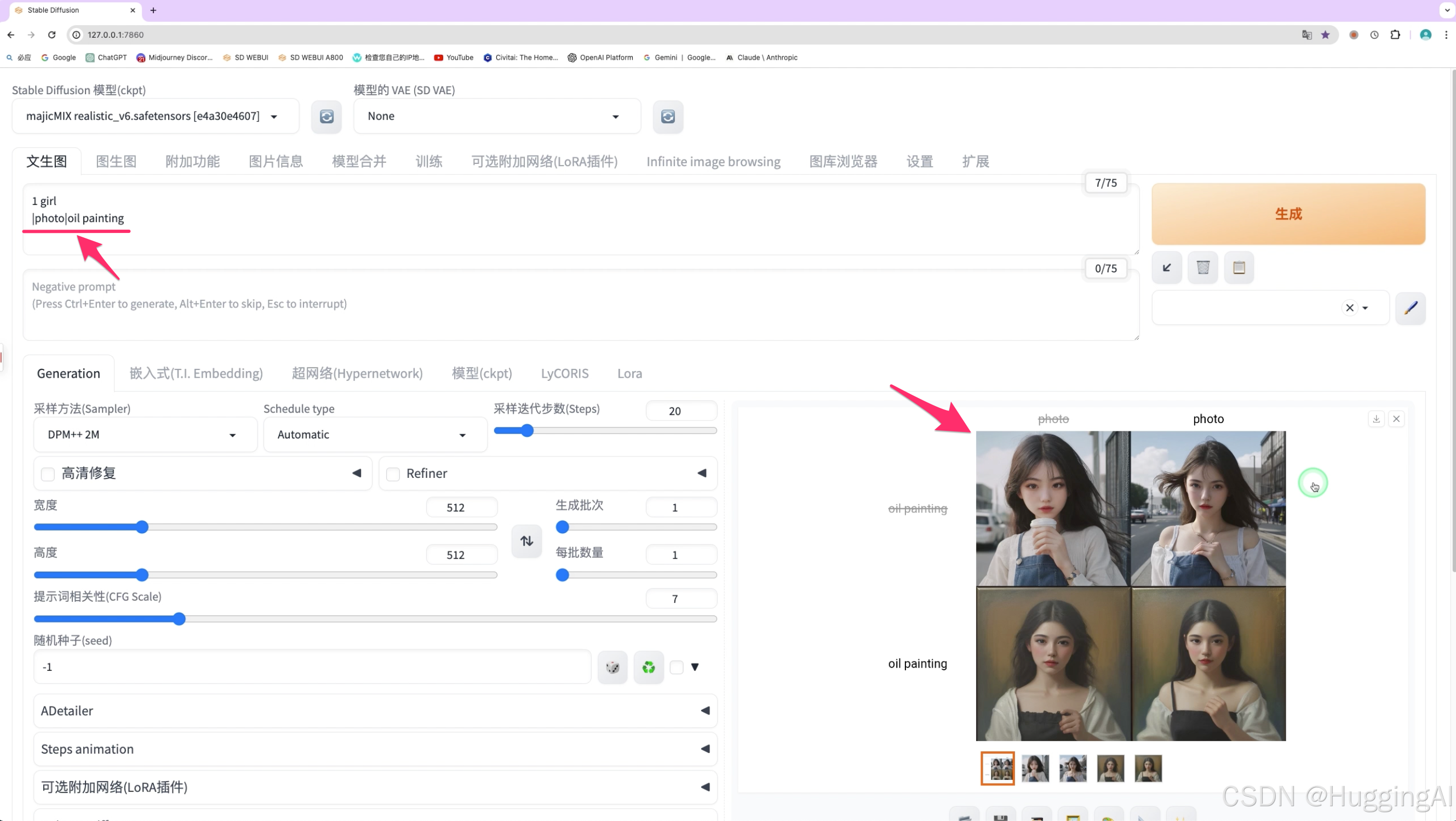
我们可以点击生成的四张图片,图片横轴和纵轴会列出实际出图时使用的提示词,

比如右上角的图片使用了photo,左下角的图片使用了oilpainting,右下角的图使用了photo和oilpainting,左上角的图photo和oilpainting都没有使用,这就是矩阵脚本的用法。
3.9.2:从文本框或文本载入提示词:
我们演示一下,正向提示词区域,我们删除画面主体部分,只保留开头的画质等描述,脚本选择从文本框或文本载入提示词,我们使用文本框输入不同的提示词元素,
insert prompts at the选择end表示将输入的提示词添加到提示语句末尾
提示词输入列表输入三行,分别为1dog,1cat,1child,
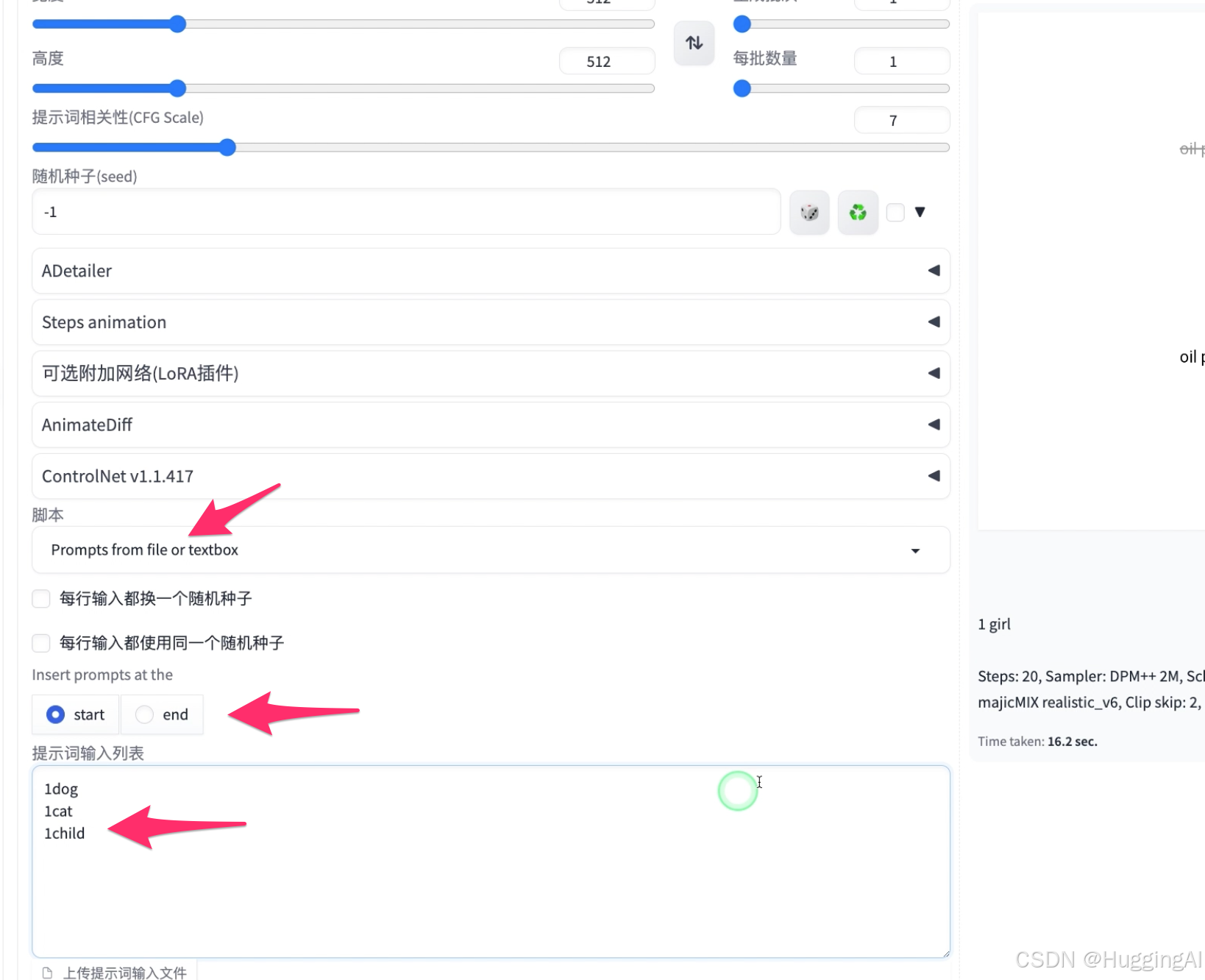
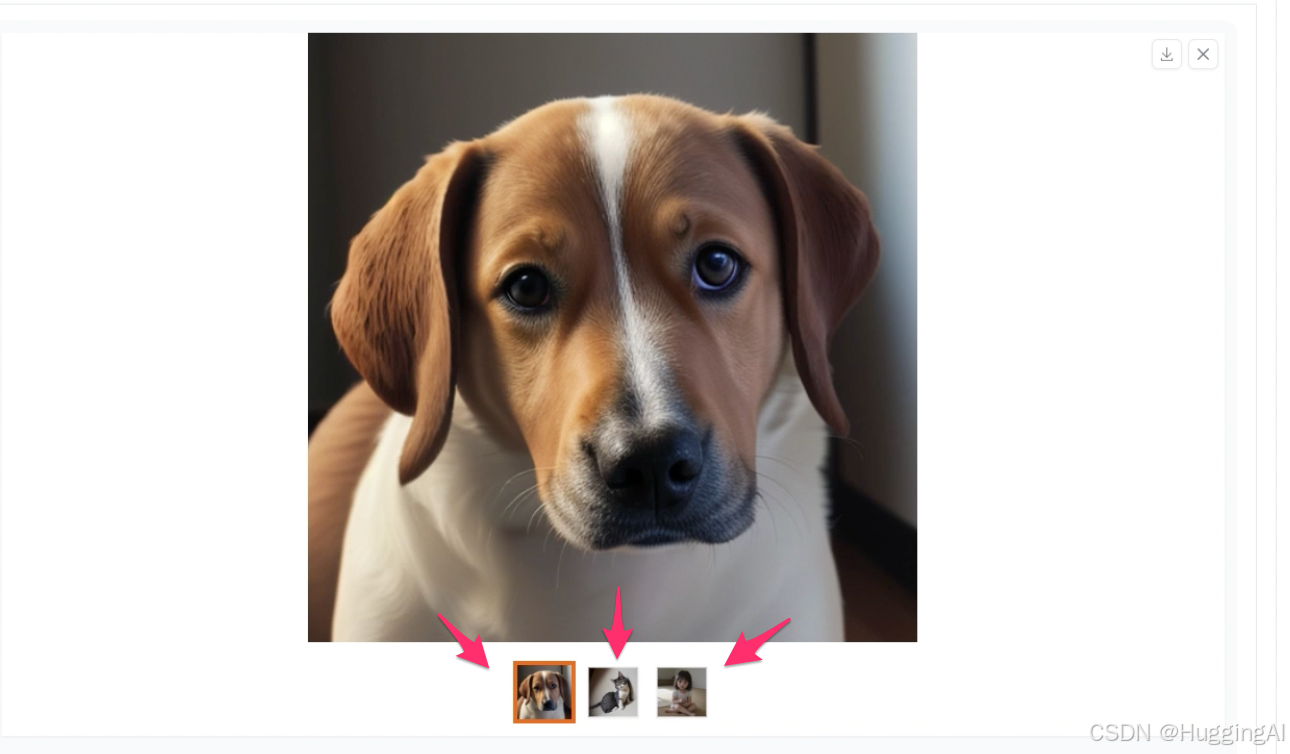
点击生成,可以看到,stable diffusion帮我们生成了关于狗,猫和小孩的三幅图片
3.9.3:X/Y/Z图表
如果我们希望对比不同的参数选项对绘制图片的影响,可以使用X/Y/Z图表
比如我们需要比较不同的采样方法,或者是prompt中的提示词绘制图片的影响,那么可以使用这个脚本工具快速完成绘制。
举个例子:
masterpiece,(best quality:1.3),ultra high res, raw photo, chilly nature documentary film photography, style: realistic pictures, 1girl, white clothes, detailed skin, a clear face, snow mountain environment, natural light
我们希望比较不同的采样方法(Euler a, DPM++ 2M)来渲染不同的颜色服装(white,black,red,yellow)
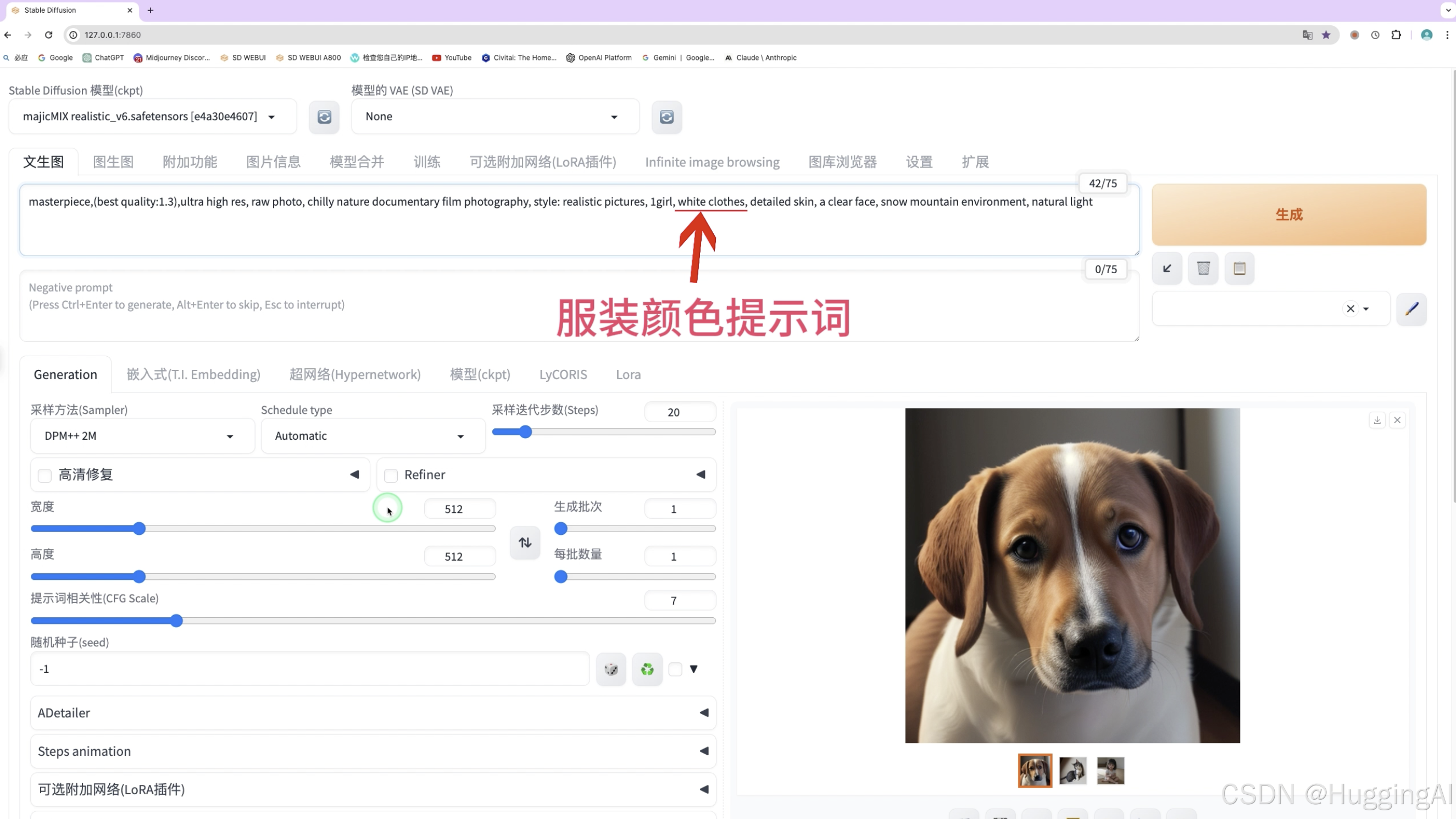
我们可以选择X/Y/Z图标脚本工具,下方会出现相关选项和输入项目
X轴我们选择采样方法,设置采样方法Euler,DPM++ 2M
Y轴选择提示词替换,输入white,black,red,yellow, 注意第一个词white是被替换的词,提示词中white clothes中的white会被依次替换。
Z轴可以选择nothing
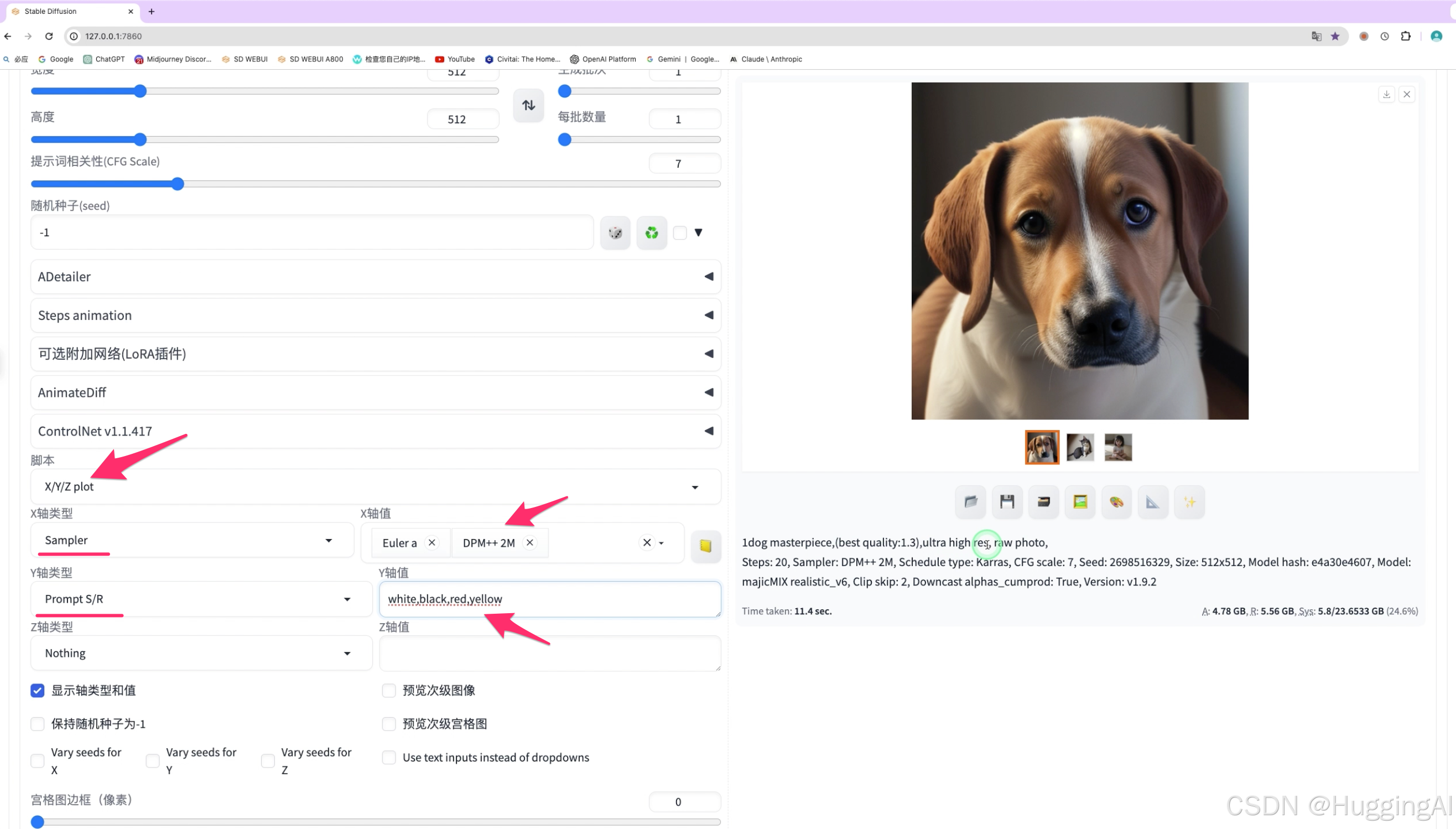
stable diffusion会根据不同采用方法和提示词批量绘制图片,因为需要绘制多张图片,所以执行时间会比较长,耐心等待即可。
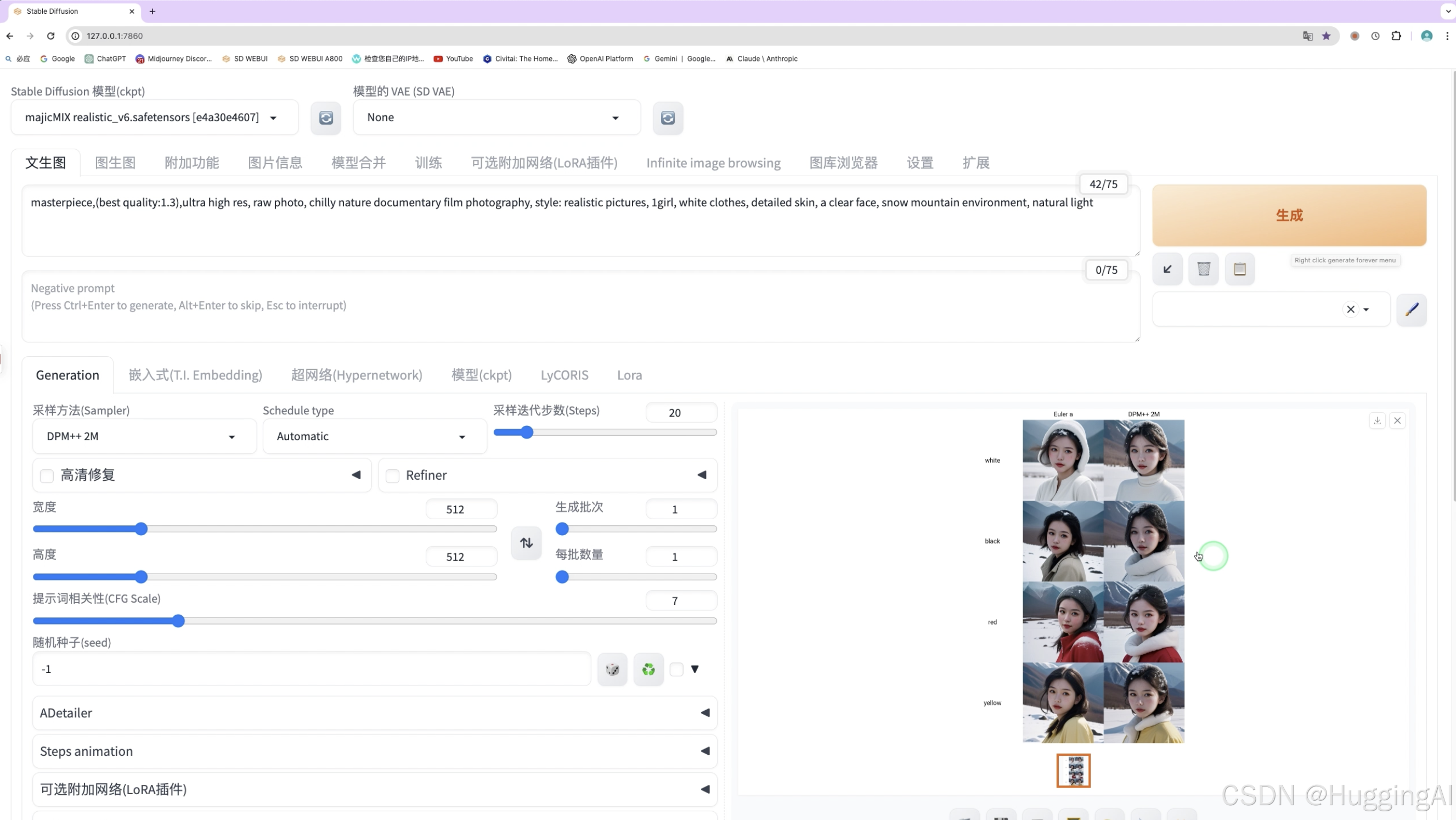

脚本工具在我们生成图片时能大大提高我们的效率,因为AI绘图随机性,我们可能要多次执行绘图操作,调整参数,才可能找到满意的图片,脚本工具可以将这些本来需要多次操作的步骤批量化执行,我们只需等待结果即可。
3.10 插件和扩展选项
除了这些常用的选项,某些插件和扩展在安装后也会提供参数和选项。
比如随机种子下方的Adetailer和ControlNet就是我们安装相关插件和扩展所提供的参数选项,这些参数和选项我们在后续课程使用插件和扩展的课程中会按需讲解。
好了,本节课的内容在这里就结束了,我们做一下总结,本节课程,我们讲述了如何设计优秀的提示语句来引导stable diffusion绘制图片,我们重点讲解了关于提示词权重的使用方法,也引申讲解了提示词中括号与大括号的一些扩展知识,另外我们设计了一套针对stable diffusion的提示词框架用于帮助大家快速书写提示语句。接着我们重点讲述与演示了stable diffusion webui绘制图片时常用的参数选项,包括采样方法,采样步数,高清修复,refiner,图片宽高,提示词相关性,随机种子,脚本工具等等,熟练掌握这些参数选项的功能,可以帮助我们更好地选择合适的方式绘制图片以及更好地控制图片的生成过程,同时也能提升我们使用stable diffusion webui绘制图片的效率。