前言
在【课程总结】day31:多模态大模型初步了解一文中,我们对多模态大模型的基本原理有了初步了解,本章内容将通过论文阅读理解,更进一步理解多模态大模型中所涉及的 Vit 架构、Transformer在视觉应用的理念以及 Clip图像与文本匹配的应用。
ViT 模型论文阅读理解
多模态大模型中所涉及的最为经典的模型就是 ViT,所以我们先了解该论文的核心要点。
论文标题:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文地址:https://arxiv.org/abs/2010.11929
ABSTRACT部分
论文原文
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place.
We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks . When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
论文翻译
尽管变换器架构已成为自然语言处理任务的标准,但其在计算机视觉中的应用仍然有限。在视觉领域,注意力的作用要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。
我们表明,这种对卷积神经网络的依赖并不是必需的,直接将纯变换器应用于图像块的序列可以在图像分类任务中表现得非常好 。当在大量数据上进行预训练并转移到多个中型或小型图像识别基准(如 ImageNet、CIFAR-100、VTAB 等)时,视觉变换器 (ViT) 的表现 与最先进的卷积网络相比,取得了优秀的结果 ,同时训练所需的计算资源显著减少。
论文理解
- 该论文提出了一个解决问题思想,使用
Transformer结构来处理图像。
INTRODUCTION部分
论文原文
Self-attention-based architectures, in particular Transformers (Vaswani et al., 2017), have become the model of choice in natural language processing (NLP). The dominant approach is to pre-train on a large text corpus and then fine-tune on a smaller task-specific dataset (Devlin et al., 2019). Thanks to Transformers' computational efficiency and scalability, it has become possible to train models of unprecedented size, with over 100B parameters (Brown et al., 2020; Lepikhin et al., 2020). With the models and datasets growing, there is still no sign of saturating performance.
In computer vision, however, convolutional architectures remain dominant (LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016). Inspired by NLP successes, multiple works try combining CNN-like architectures with self-attention (Wang et al., 2018; Carion et al., 2020), some replacing the convolutions entirely (Ramachandran et al., 2019; Wang et al., 2020a). The latter models, while theoretically efficient, have not yet been scaled effectively on modern hardware accelerators due to the use of specialized attention patterns. Therefore, in large-scale image recognition, classic ResNet-like architectures are still state of the art (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al., 2020).
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images , with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer . Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in a supervised fashion.
论文翻译
基于自注意力的架构,尤其是
Transformer(Vaswani 等,2017),已成为自然语言处理(NLP)中的首选模型。主流的方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调(Devlin 等,2019)。得益于Transformer的计算效率和可扩展性,训练超过 1000 亿参数的前所未有规模的模型成为可能(Brown 等,2020;Lepikhin 等,2020)。随着模型和数据集的增长,性能仍没有饱和的迹象。
然而,在计算机视觉中,卷积架构仍然占主导地位(LeCun 等,1989;Krizhevsky 等,2012;He 等,2016)。受到 NLP 成功的启发,多个研究尝试将类似 CNN 的架构与自注意力结合(Wang 等,2018;Carion 等,2020),其中一些完全替代卷积(Ramachandran 等,2019;Wang 等,2020a)。后者模型虽然在理论上高效,但由于使用了专门的注意力模式,尚未在现代硬件加速器上有效扩展。因此,在大规模图像识别中,经典的 ResNet 类架构仍然是最先进的(Mahajan 等,2018;Xie 等,2020;Kolesnikov 等,2020)。
受到 NLP 中变换器扩展成功的启发,我们尝试将标准Transformer直接应用于图像 ,尽可能少地进行修改。为此,我们将图像分割成小块,并将这些小块的线性嵌入序列作为输入提供给Transformer。图像小块的处理方式与 NLP 应用中的标记(单词)相同。我们在监督方式下对图像分类进行模型训练。
论文理解
Transformer是一个非常强大的模型,可以处理时序信息并且在NLP自然语言任务中表现优秀。- 计算机视觉方面目前仍然是 卷积网络 主导的,而 Transformer 有非常强大的并行计算性能。
- 如何使用Transformer 来替代卷积呢,论文中给出了一种思想:
- 将图像分割成小块,然后对每个小块进行
embedding,然后将这些embedding序列(图像变为了时序的序列)作为输入提供给Transformer,以此发挥 Transformer 的并行计算优势。
- 将图像分割成小块,然后对每个小块进行
模型结构
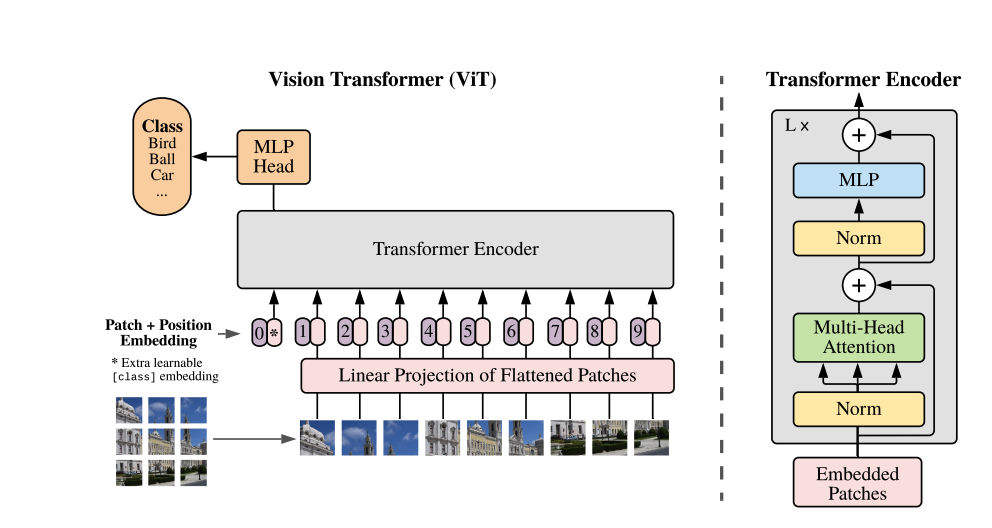
论文原文
An overview of the model is depicted in Figure 1. The standard Transformer receives as input a 1D sequence of token embeddings. To handle 2D images, we reshape the image
$$ x \in \mathbb{R}^{H \times W \times C} $$into a sequence of flattened 2D patches$$ x_p \in \mathbb{R}^{N \times (P^2 \cdot C)} $$, where$$(H, W)$$is the resolution of the original image ,$$C$$is the number of channels ,$$(P, P)$$is the resolution of each image patch , and$$N = \frac{HW}{P^2}$$is the resulting number of patches, which also serves as the effective input sequence length for the Transformer.
The Transformer uses a constant latent vector size$$D$$through all of its layers, so we flatten the patches and map to$$D$$dimensions with a trainable linear projection (Eq. 1). We refer to the output of this projection as the patch embeddings.
Similar to BERT's class token, we prepend a learnable embedding to the sequence of embedded patches$$(z_0^0 = x_{\text{class}})$$, whose state at the output of the Transformer encoder$$(z_L^0)$$serves as the image representation$$y$$(Eq. 4). Both during pre-training and fine-tuning, a classification head is attached to$$z_L^0$$. The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time.
Position embeddings are added to the patch embeddings to retain positional information. We use standard learnable 1D position embeddings, since we have not observed significant performance gains from using more advanced 2D-aware position embeddings (Appendix D.4). The resulting sequence of embedding vectors serves as input to the encoder.
The Transformer encoder (Vaswani et al., 2017) consists of alternating layers of multiheaded self-attention (MSA, see Appendix A) and MLP blocks (Eq. 2, 3). Layer normalization (LN) is applied before every block, and residual connections after every block (Wang et al., 2019; Baevski & Auli, 2019). The MLP contains two layers with a GELU non-linearity.
论文翻译
模型的概述如图 1 所示。标准
Transformer接收1D的标记嵌入序列作为输入。为了处理2D图像,我们将图像$$x \in \mathbb{R}^{H \times W \times C}$$重塑为一系列展平的2D小块$$x_p \in \mathbb{R}^{N \times (P^2 \cdot C)}$$,其中$$(H, W)$$是原始图像的分辨率 ,$$C$$是通道数 ,$$(P, P)$$是每个图像小块的分辨率 ,$$N = \frac{HW}{P^2}$$是得到的小块数量 ,这也作为Transformer的有效输入序列长度。
Transformer在其所有层中使用恒定的潜在向量大小$$D$$,因此我们将小块展平并通过可训练的线性投影映射到$$D$$维(公式 1)。我们将此投影的输出称为小块嵌入。
类似于BERT的 class 标记,我们在嵌入小块的序列前添加一个可学习的嵌入$$(z_0^0 = x_{\text{class}})$$,其在Transformer的编码器输出时的状态$$(z_L^0)$$作为图像表示$$y$$(公式 4)。在预训练和微调过程中,分类头都附加在$$z_L^0$$上。分类头在预训练时通过一个隐藏层的MLP实现,在微调时通过一个线性层实现。
位置嵌入被添加到小块嵌入中以保留位置信息。我们使用标准的可学习1D位置嵌入,因为我们没有观察到使用更先进的2D位置嵌入会显著提升性能(附录 D.4)。生成的嵌入向量序列作为编码器的输入。
Transformer编码器(Vaswani 等,2017)由多头自注意力 (MSA,见附录 A)和 MLP 块(公式 2、3)交替层 组成。在每个块之前应用层归一化 (LN),在每个块之后应用残差连接(Wang 等,2019;Baevski & Auli,2019)。MLP 包含两个层,并使用 GELU 非线性激活函数。
论文理解
- 为了让Transformer 能够处理图像,我们将图像分割成小块,其中H,W 为图像的分辨率,C 为通道数,P 为小块的分辨率。
- 为了满足图片后续的分类能力,采用了 BERT 的 CLS 标记,在Embedding层的第一个位置添加了一个 CLS 标记。
- 为了保留图片的时序信息,采用了可学习的 1D position embedding,最后将生成的嵌入序列作为编码器的输入。
- Transformer 只使用了encoder部分,相比原始的 Transformer,将Layer Normalization 和 Residual Connection 添加到了encoder部分。
回顾 BERT
由于 Vit 架构中提到了图像分类采用了 Bert 模型,所以我们回顾与此相关的部分。
论文地址:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
模型结构
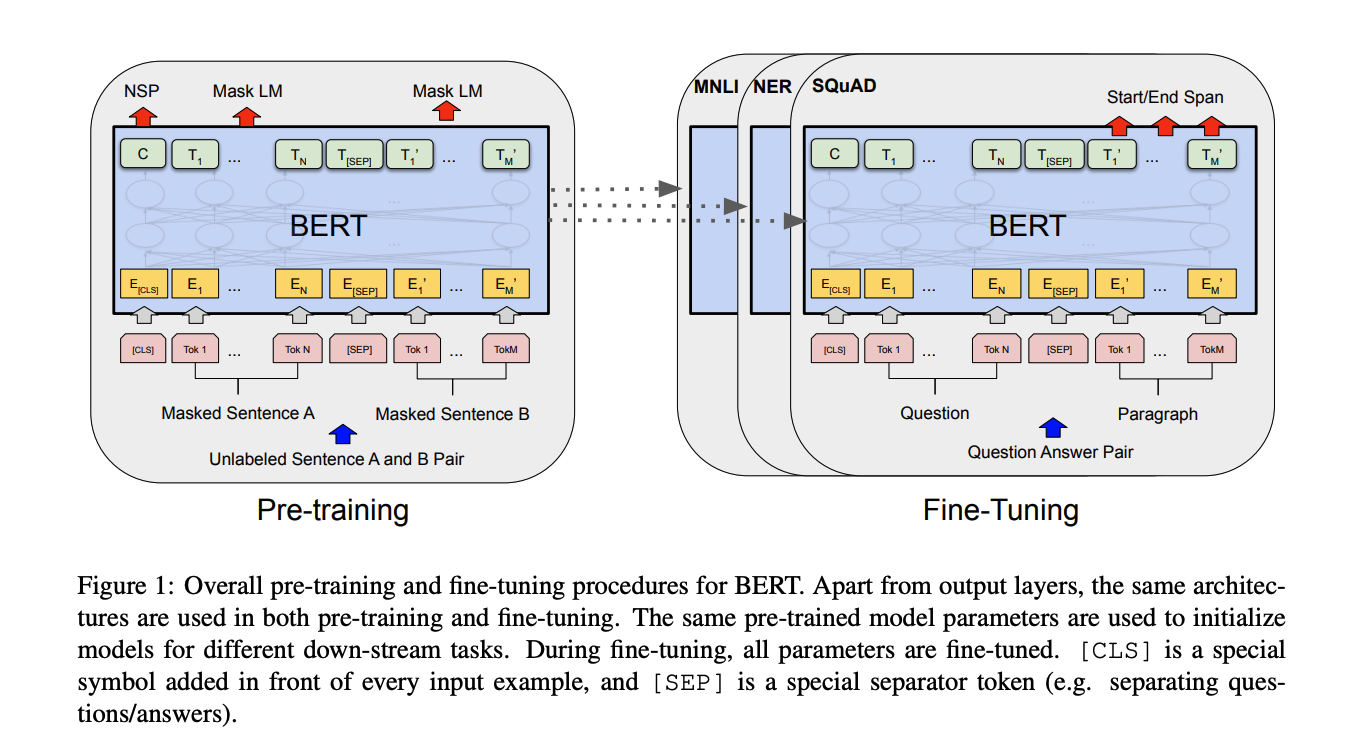
论文原文
Figure 1: Overall pre-training and fine-tuning procedures for BERT. Apart from output layers, the same architectures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initialize models for different down-stream tasks. During fine-tuning, all parameters are fine-tuned. CLS is a special symbol added in front of every input example, and SEP is a special separator token (e.g. separating questions/answers).
论文翻译
图1:BERT的整体预训练和微调过程。除了输出层外,预训练和微调中使用相同的架构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调过程中,所有参数都进行微调。CLS 是在每个输入示例前添加的特殊符号,SEP 是一个特殊的分隔符标记(例如,用于分隔问题/答案)。
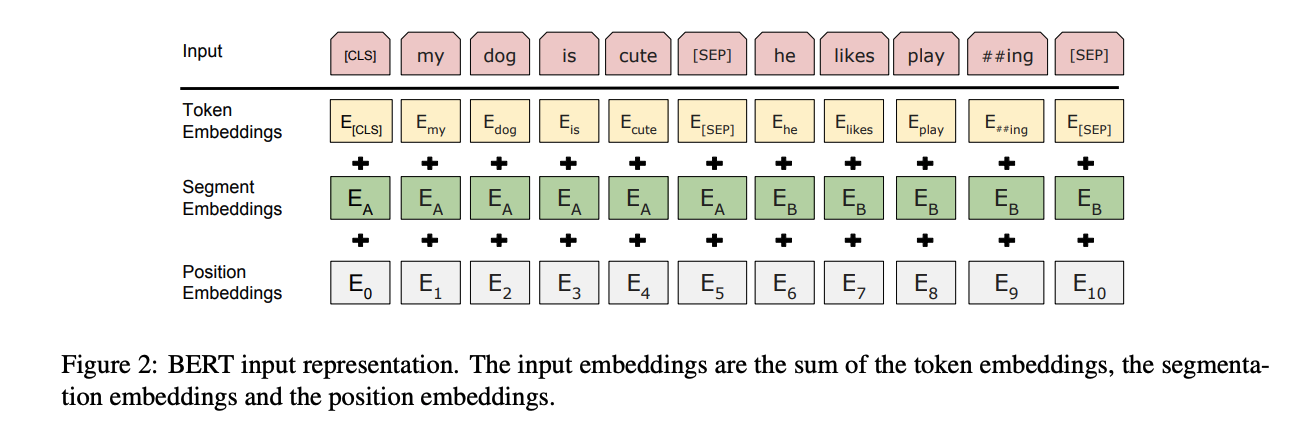
论文原文
To make BERT handle a variety of down-stream tasks, our input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., h Question, Answeri) in one token sequence. Throughout this work, a "sentence" can be an arbitrary span of contiguous text, rather than an actual linguistic sentence. A "sequence" refers to the input token sequence to BERT, which may be a single sentence or two sentences packed together. We use WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary. The first
token of every sequence is always a special classification token (CLS). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token (SEP). Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
论文翻译
为了使BERT能够处理各种下游任务,我们的输入表征能够明确地表示单个句子 和一对句子 (例如,<问题, 答案>)在一个
token序列中。在我们的通篇文章中,一个"sentence(句子)"可以是任意连续的文本,而不必是实际的语言句子 。"sequence(序列)"指的是输入到BERT的token序列,这可以是一个单独的句子或两个句子组合在一起。
我们使用WordPiece嵌入(Wu等,2016),词汇量为30,000个标记。每个序列的第一个token始终是一个特殊的分类标记(CLS)。与该token对应的最终隐藏状态用于分类任务的聚合序列表示。如果是句子对,则被打包成一个单一序列。我们通过两种方式来区分句子。首先,我们用一个特殊token(SEP)将它们分开 。其次,我们为每个token添加一个已经学过的embedding词向量,指示它属于句子A还是句子B。
论文理解
通过对论文的回顾,我们可以发现,Vit 架构中采用了与 BERT 相似的架构,并且也使用了 BERT 的 CLS 标记。
CLIP 模型论文阅读理解
多模态大模型的训练过程中,需要将文本和图像进行匹配,所以 CLIP 即承担此项任务。
论文标题:CLIP: Learning Transferable Visual Models From Natural Language Supervision
论文地址:https://arxiv.org/abs/2103.00020
论文原文
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision.
We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enablingzero-shottransfer of the model to downstream tasks.
We study the performance of this approach by benchmarking on over30different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training.
论文翻译
最先进的计算机视觉系统被训练以预测一组固定的预定对象类别。这种限制性的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据 来指定任何其他视觉概念。直接从关于图像的原始文本学习是一种有前景的替代方案,它利用了更广泛的监督来源。
我们展示了简单的预训练任务,即预测哪个标题与哪个图像相匹配,是一种高效且可扩展的方法,可以在从互联网上收集的 4 亿对(图像,文本)数据集上从零开始学习最先进的图像表示。在预训练之后,自然语言被用来引用学习到的视觉概念(或描述新的概念),从而使模型能够zero-shot转移到下游任务。
我们通过在超过30个不同的现有计算机视觉数据集上进行基准测试来研究这种方法的性能,涵盖 OCR、视频中的动作识别、地理定位以及多种类型的细粒度对象分类等任务。该模型在大多数任务中非平凡地转移,并且通常与完全监督的基线竞争,而无需任何特定于数据集的训练。
模型结构
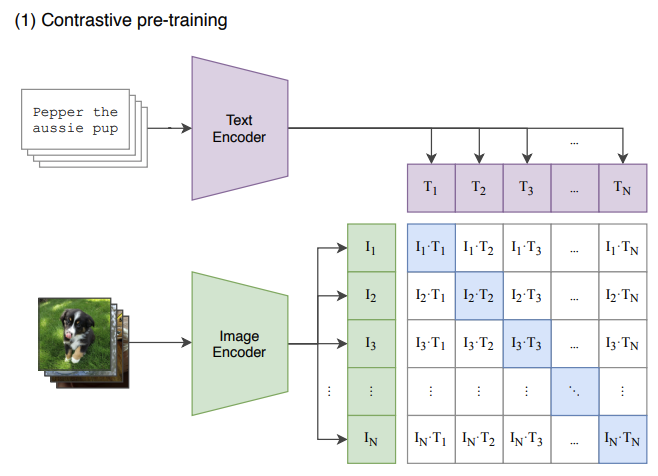
论文原文
Figure 1. Summary of Our Approach While standard image models jointly train an image feature extractor** and a linear classifier to predict some label, CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples. At test time, the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset's classes.
论文翻译
图 1. 我们方法的总结 标准的图像模型共同训练图像特征提取器和线性分类器以预测某个标签,而
CLIP共同训练 图像编码器 和 文本编码器 以**预测一批(图像,文本)**训练示例的正确配对。在测试时,学习到的文本编码器通过嵌入目标数据集类别的名称或描述来合成一个 zero-shot 线性分类器。
论文理解
- CLIP的模型包括两个部分,即文本编码器 (Text Encoder)和图像编码器 (Image Encoder)。Text Encoder选择的是
Text Transformer模型;Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT。 - CLIP将图片-文本pair对进行对比学习输入到同一个神经网络,将它们映射到同一个嵌入空间,从而实现了图像和文本跨模态的语义对齐。
- 用图片预测对应的文本,结果会非常多样,训练起来会非常慢。而使用对比学习,判断图片文本是否是一对,就简化了任务。
对比学习
python
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2CLIP 在文本-图像对数据集上的对比学习训练过程如下:
- 对于一个包含 N 个 <文本-图像> 对的训练
batch,使用Text Encoder和Image Encoder提取N个文本特征和N个图像特征。
这里共有
N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的 (N^2 - N) 个文本-图像对为负样本。
- 将
N个文本特征和N个图像特征两两组合,CLIP模型会预测出 (N^2) 个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。 - 那么
CLIP的训练目标就是最大化N个正样本的相似度,同时最小化 (N^2 - N) 个负样本的相似度,即最大化对角线中蓝色的数值,最小化其它非对角线的数值:
katex
\text{min}\left(\sum_{i=1}^{N}\sum_{j=1}^{N}(I_i \cdot T_j)_{i \neq j} - \sum_{i=1}^{N}(I_i \cdot T_j)\right)迁移预训练模型实现zero-shot
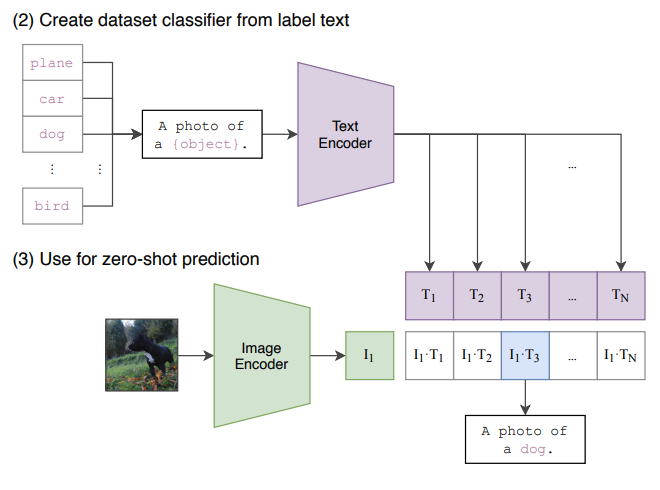
论文原文
CLIP is pre-trained to predict if an image and a text snippet are paired together in its dataset. To perform
zero-shotclassification, we reuse this capability. For each dataset, we use the names of all the classes in the dataset as the set of potential text pairings and predict the most probable (image, text) pair according to CLIP.
In a bit more detail, we first compute the feature embedding of the image and the feature embedding of the set of possible texts by their respective encoders. The cosine similarity of these embeddings is then calculated , scaled by a temperature parameter τ, and normalized into a probability distribution via a softmax. Note that this prediction layer is a multinomial logistic regression classifier with L2-normalized inputs, L2-normalized weights, no bias, and temperature scaling.
When interpreted this way, the image encoder is the computer vision backbone which computes a feature representation for the image and the text encoder is a hypernetwork (Ha et al., 2016) which generates the weights of a linear classifier based on the text specifying the visual concepts that the classes represent. Lei Ba et al. (2015) first introduced a zero-shot image classifier of this form while the idea of generating a classifier from natural language dates back to at least Elhoseiny et al. (2013).
论文翻译
CLIP 被预训练以预测图像和文本片段是否在其数据集中配对。为了执行
zero-shot分类,我们重用这一能力。对于每个数据集,我们使用数据集中所有类别的名称作为潜在文本配对的集合,并根据 CLIP 预测最可能的(图像,文本)对。
更详细地说,我们首先计算图像的特征嵌入 和可能文本集合的特征嵌入 。然后计算这些嵌入的余弦相似度 ,通过温度参数 τ 进行缩放,并通过softmax正规化为概率分布。请注意,这个预测层是一个多项式逻辑回归分类器,具有 L2 规范化的输入、L2 规范化的权重、没有偏置和温度缩放。
从这个角度解释时,图像编码器是计算机视觉的骨干,计算图像的特征表示,而文本编码器是一个超网络(Ha 等,2016),根据指定类别所代表的视觉概念生成线性分类器的权重。Lei Ba 等(2015)首次引入了这种形式的zero-shot图像分类器,而从自然语言生成分类器的想法至少可以追溯到 Elhoseiny 等(2013)。
论文理解
- 训练后的CLIP其实是两个模型:视觉模型+文本模型,与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。
- 经过在文本-图像对数据上训练的模型,CLIP有能力判断给定的文本和图像是否匹配,即可以直接做图像分类。
- CLIP的zero-shot分类过程如下:
- 根据任务的分类标签构建每个类别的描述文本(以Imagenet有N=1000类为例):A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;
- 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
内容小结
关于 Vit 模型
- 多模态大模型中所涉及的
ViT架构,提出了一个使用Transformer结构来处理图像的思想。 - Vit架构的处理过程:将图像分割成小块,然后对每个小块进行
embedding并作为输入提供给Transformer,以此发挥 Transformer 的并行计算优势。 - 为了满足图片后续的分类能力,采用了 BERT 的 CLS 标记,在Embedding层的第一个位置添加了一个 CLS 标记。
关于 CLIP 模型
- CLIP的模型包括两个部分,即文本编码器 (Text Encoder)和图像编码器(Image Encoder)。
- CLIP模型通过
图片-文本pair对进行对比学习,将它们映射到同一个嵌入空间,从而实现了图像和文本跨模态的语义对齐。 - CLIP模型的最大亮点是:不需要任何训练数据 ,直接在图像和文本的pair对上进行训练 ,从而实现了
zero-shot的图像分类。