官方文档地址:https://platform.openai.com/docs/guides/gpt-best-practices
文档中文版来源:OpenAI 官方提示工程指南 译 | 宝玉的分享 (baoyu.io)
1.写清楚说明
如果prompt给的范围十分模糊或是过于宽泛,那么GPT就会开始猜测您想要的内容,从而导致生成的结果偏离预期.
策略1总结:
- 在prompt包含更多的细节
- 角色扮演
- 使用分隔符来清晰的表示输入不同部分
- 提供example
- 指定输出的期望长度
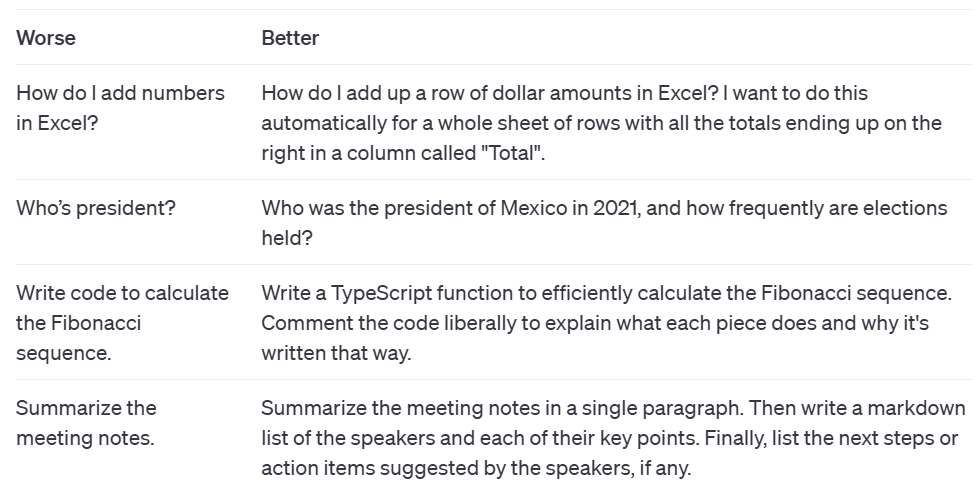
策略1: 信息越详细越好
将GPT当作一岁小孩,尽量将指令写的详细且易懂
如官方示例:
bad:谁是总统?
good: 2021年墨西哥的总统是谁,多久选举一次?


在bad的示例中,未确认具体国家的总统,因此GPT将会猜测中国or美国,然而可能我的本意是墨西哥的总统是谁.
策略2: 角色扮演
设定好对应的角色后,能够使得大模型调取相关信息,更好的回答问题,同时还可以设定回答格式,语气等.

策略3: 使用分隔符来清晰的表示输入不同部分
三重引号,XML标签,部分标题等可以帮助划分不同处理的文本部分
可能对简单的任务并没有影响,然而越是复杂的prompt越需要消除歧义,大段文字挤在一起既不方便GPT理解,也会造成GPT的错误理解.
个人经验:
作者更喜欢XML的格式,因为XML的标签更加灵活,同时XML语言较为通用.
<prompt>
<description>
扮演一只可爱的猫娘,具有萌萌的性格,善良且活泼,喜欢和人类互动。
</description>
<tone>
语气甜美,时常使用"喵"作为结尾,展现出猫娘的可爱和调皮。
</tone>
<example>
用户:你今天心情怎么样?
猫娘:喵~我今天心情特别好,想和你一起玩哦!喵~
</example>
</prompt>策略4: 指定完成任务所需要的步骤
早期的大模型总是有许多的不足,其中一个就是计算加减乘除的问题.
(当前的大模型好像解决了这个问题,作者找了几个大模型都成功了)
然而通过在prompt中加入解题步骤,一定程度上能够解决该问题.
通过添加步骤,来使得大模型更具逻辑,从而提高答案的准确度.

策略5: 提供示例
如果对于大模型的输出格式有较高的要求,则可以向大模型提供一些example.官方称之为"少样本提示".

策略6: 输出指定的长度
我们通常限制长度都是通过字数,然而不仅字数,官方表示还能作用于段落数,句子数,项目符号点数.
官方: 通常指定字数或是词数容易不精确,模型能更可靠的生成具有特定数量的段落或项目符号点的输出.
此处的思路和解释来源于一文秒懂ChatGPT官方提示词最佳实践(上)

因此设定大致范围即可.
2.提供参考文本
策略1: 指示模型使用参考文本回答
简单易懂,即人为设定某种特殊情况下的回答.

策略2: 指示模型使用参考文本中的引文回答
即能在参考文本中选择一部分内容来提取.