MapReduce 的 Shuffle 过程指的是 MapTask 的后半程,以及ReduceTask的前半程,共同组成的。
从 MapTask 中的 map 方法结束,到 ReduceTask 中的 reduce 方法开始,这个中间的部分就是Shuffle。是MapReduce的核心,心脏。

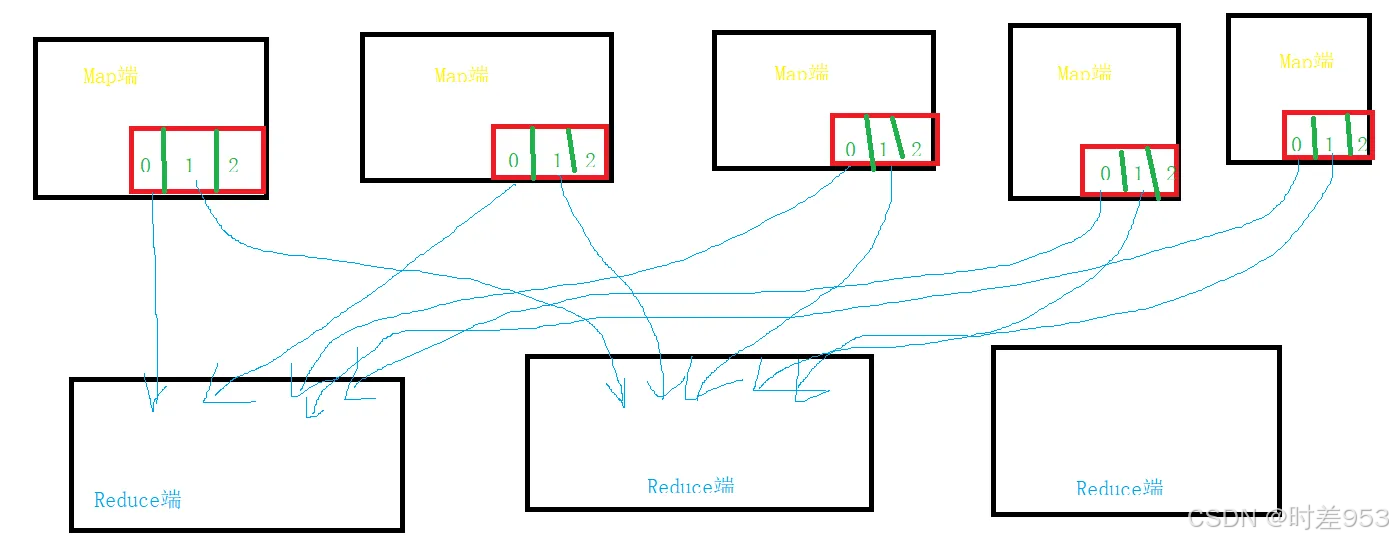
map端:
**1、**map中的context.write方法,对外写出的时候,其实是写入到了一个环形缓冲区内(内存形式的),这个环形缓冲区大小是100M,可以通过参数设置。如果里面的数据大于80M,就开始溢写(从内存中将数据写入到磁盘上)。溢写的文件存放地址可以设置。
2、 在溢写过程中,环形缓冲区不会停止工作,是会利用剩余的20%继续存入环形缓冲区的。除非是环形缓冲区的内存满了,map任务就被阻塞了。
在溢写出来的文件中,是排过序的,排序规则:快速排序算法。在排序之前,会根据分区的算法,对数据进行分区。在内存中,先分区,在每一个分区中再排序,接着溢写到磁盘上的。
3、 溢写出来的小文件需要合并为一个大文件,因为每一个MapTask只能有一份数据。就将相同的分区文件合并,并且排序(此处是归并排序)。每次合并的时候是10个小文件合并为一个大文件,进行多次合并,最终每一个分区的文件只能有一份。
假如100个小文件,需要合并几次呢?
100 每10分合并一次,第一轮:100个文件合并为了10个文件,这10个文件又合并为一个大文件,总共合并了11次。
**4、**将内存中的数据,溢写到磁盘上,还可以指定是否需要压缩,以及压缩的算法是什么。
reduce端:
1、 reduce端根据不同的分区,拉取每个服务器上的相同的分区的数据。
reduce任务有少量复制线程,因此能够并行取得map输出。默认值是5个线程,但这个默认值可以修改,设置mapreduce.reduce.shuffle. parallelcopies 属性即可。
**2、**如果map上的数据非常的小,该数据会拉取到reduce端的内存中,如果数据量比较大,直接拉取到reduce端的硬盘上。