文章目录
- [1. 登录实训云](#1. 登录实训云)
-
- [1.1 实训云网址](#1.1 实训云网址)
- [1.2 登录实训云](#1.2 登录实训云)
- [2. 创建网络](#2. 创建网络)
-
- [2.1 网络概述](#2.1 网络概述)
- [2.2 创建步骤](#2.2 创建步骤)
- [3. 创建路由器](#3. 创建路由器)
-
- [3.1 路由器名称](#3.1 路由器名称)
- [3.1 创建路由器](#3.1 创建路由器)
- [4. 连接子网](#4. 连接子网)
- [5. 创建虚拟网卡](#5. 创建虚拟网卡)
-
- [5.1 创建原因](#5.1 创建原因)
- [5.2 查看端口](#5.2 查看端口)
- [5.3 创建虚拟网卡](#5.3 创建虚拟网卡)
- [6. 管理安全组规则](#6. 管理安全组规则)
-
- [6.1 为什么要管理安全组规则](#6.1 为什么要管理安全组规则)
- [6.2 在默认安全组里创建规则](#6.2 在默认安全组里创建规则)
- [7. 创建云主机](#7. 创建云主机)
-
- [7.1 创建云主机bigdata1](#7.1 创建云主机bigdata1)
- [7.2 创建云主机bigdata2](#7.2 创建云主机bigdata2)
- [7.3 创建云主机bigdata3](#7.3 创建云主机bigdata3)
- [8. 绑定浮动IP地址](#8. 绑定浮动IP地址)
-
- [8.1 为何要绑定](#8.1 为何要绑定)
- [8.2 申请浮动IP地址](#8.2 申请浮动IP地址)
- [8.3 绑定浮动IP地址](#8.3 绑定浮动IP地址)
- [9. 远程连接云主机](#9. 远程连接云主机)
-
- [9.1 启动FinalShell](#9.1 启动FinalShell)
- [9.2 远程连接云主机bigdata1](#9.2 远程连接云主机bigdata1)
- [9.3 远程连接云主机bigdata2](#9.3 远程连接云主机bigdata2)
- [9.4 远程连接云主机bigdata3](#9.4 远程连接云主机bigdata3)
- [10. 修改本地的IP与主机名映射文件](#10. 修改本地的IP与主机名映射文件)
- [11. 本机Ping云主机](#11. 本机Ping云主机)
-
- [11.1 按IP地址来Ping](#11.1 按IP地址来Ping)
- [11.2 按主机名来Ping](#11.2 按主机名来Ping)
- [12. 修改配置文件](#12. 修改配置文件)
-
- [12.1 修改hdfs-site.xml文件](#12.1 修改hdfs-site.xml文件)
- [12.2 修改log4j.properties文件](#12.2 修改log4j.properties文件)
- [13. 启动大数据集群服务](#13. 启动大数据集群服务)
- [14. 完成词频统计任务](#14. 完成词频统计任务)
-
- [14.1 准备数据文件](#14.1 准备数据文件)
- [14.2 利用MR实现词频统计](#14.2 利用MR实现词频统计)
-
- [14.2.1 创建Maven项目](#14.2.1 创建Maven项目)
- [14.2.2 添加hadoop依赖](#14.2.2 添加hadoop依赖)
- [14.2.3 创建日志属性文件](#14.2.3 创建日志属性文件)
- [14.2.4 创建词频统计映射器类](#14.2.4 创建词频统计映射器类)
- [14.2.5 创建词频统计归并器类](#14.2.5 创建词频统计归并器类)
- [14.2.6 创建词频统计驱动器类](#14.2.6 创建词频统计驱动器类)
- [14.2.7 运行程序,查看结果](#14.2.7 运行程序,查看结果)
- [14.3 利用Hive实现词频统计](#14.3 利用Hive实现词频统计)
-
- [14.3.1 基于HDFS文件创建外部表](#14.3.1 基于HDFS文件创建外部表)
- [14.3.2 展开每行单词](#14.3.2 展开每行单词)
- [14.3.3 基于查询结果创建视图](#14.3.3 基于查询结果创建视图)
- [14.3.4 基于视图分组统计](#14.3.4 基于视图分组统计)
- [14.4 利用Spark实现词频统计](#14.4 利用Spark实现词频统计)
-
- [14.4.1 利用Spark RDD实现词频统计](#14.4.1 利用Spark RDD实现词频统计)
- [14.4.2 利用Spark SQL实现词频统计](#14.4.2 利用Spark SQL实现词频统计)
- [15. 关闭大数据集群服务](#15. 关闭大数据集群服务)
- [16. 实战小结](#16. 实战小结)
1. 登录实训云
1.1 实训云网址
- 网址:
http://192.168.192.40
1.2 登录实训云
-
输入用户名和密码
-
登录成功后显示首页
2. 创建网络
2.1 网络概述
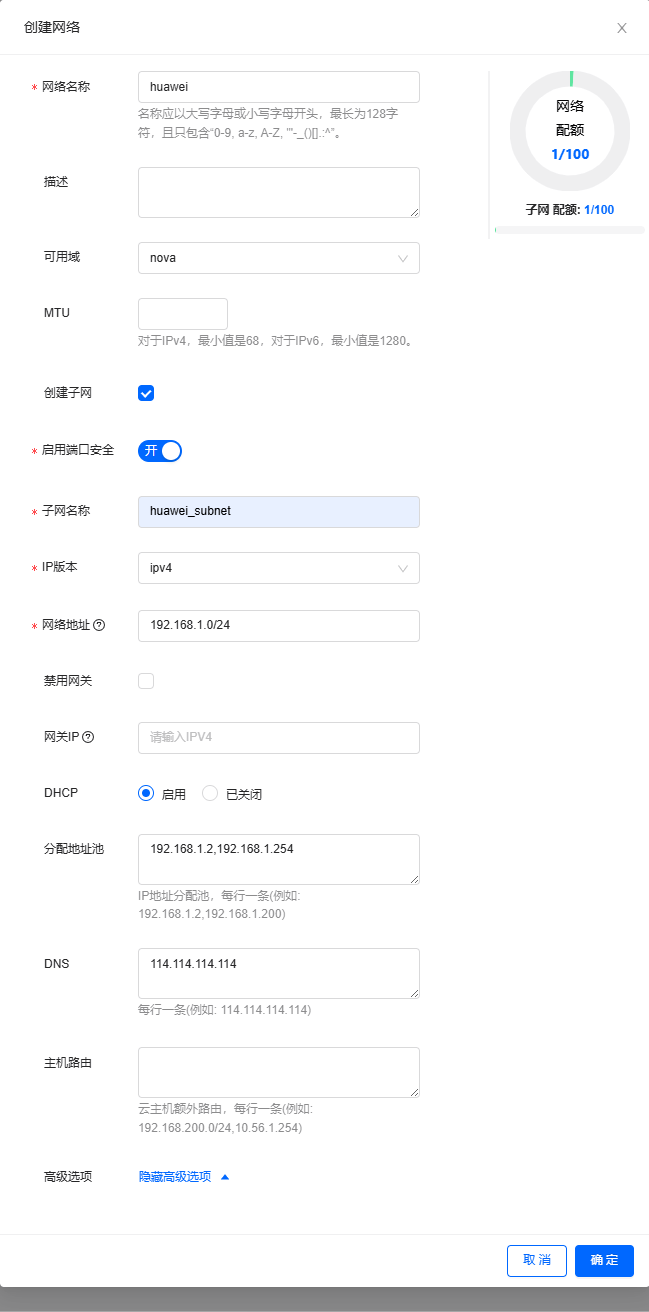
- 网络名为
huawei,子网为huawei_subnet,网络地址为192.168.1.0/24,分配地址池192.168.1.2,192.168.1.254,DNS设置为114.114.114.114。此网络结构清晰,地址配置明确,具备基础的网络配置要素,可满足一般网络应用场景下的设备接入与通信需求。
2.2 创建步骤
-
显示【网络】页面

-
单击【创建网络】按钮,在弹出的对话框里设置网络基本信息
-
单击【确定】按钮,成功创建网络
huawei
3. 创建路由器
3.1 路由器名称
- 路由器名称:
huawei_router
3.1 创建路由器
-
显示【路由器】页面
-
单击【创建路由器】按钮,在弹出的对话框里设置路由器基本信息

-
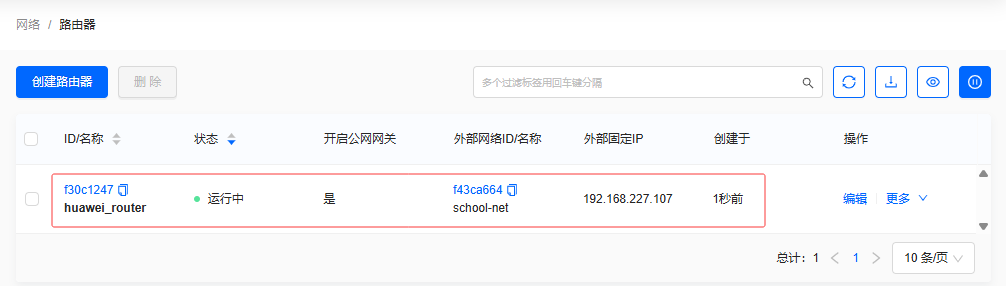
单击【确定】按钮,成功创建路由器
4. 连接子网
-
显示【路由器】页面
-
单击【更多】右边的箭头弹出下拉菜单
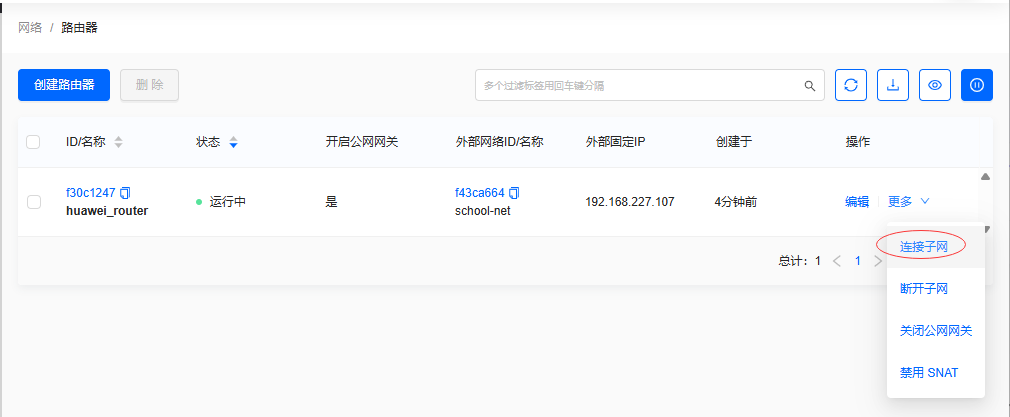
-
单击【连接子网】菜单选项,连接网络
huawei与子网huawei_subnet

-
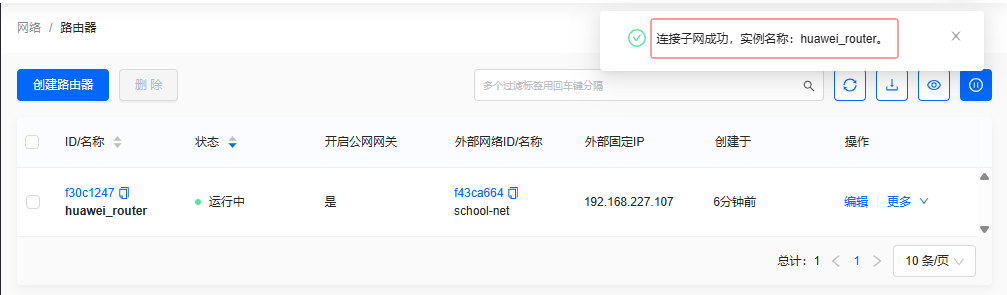
单击【确定】按钮,提示连接子网成功
5. 创建虚拟网卡
5.1 创建原因
- 创建虚拟网卡是为了给云主机分配固定IP地址。云主机在网络中运行,若需稳定的网络标识和连接,固定IP不可或缺。虚拟网卡充当云主机与网络间的桥梁,通过创建它并绑定固定IP,可确保云主机在网络中的唯一性和稳定性,便于管理与访问。
5.2 查看端口
- 显示【端口】页面
5.3 创建虚拟网卡
-
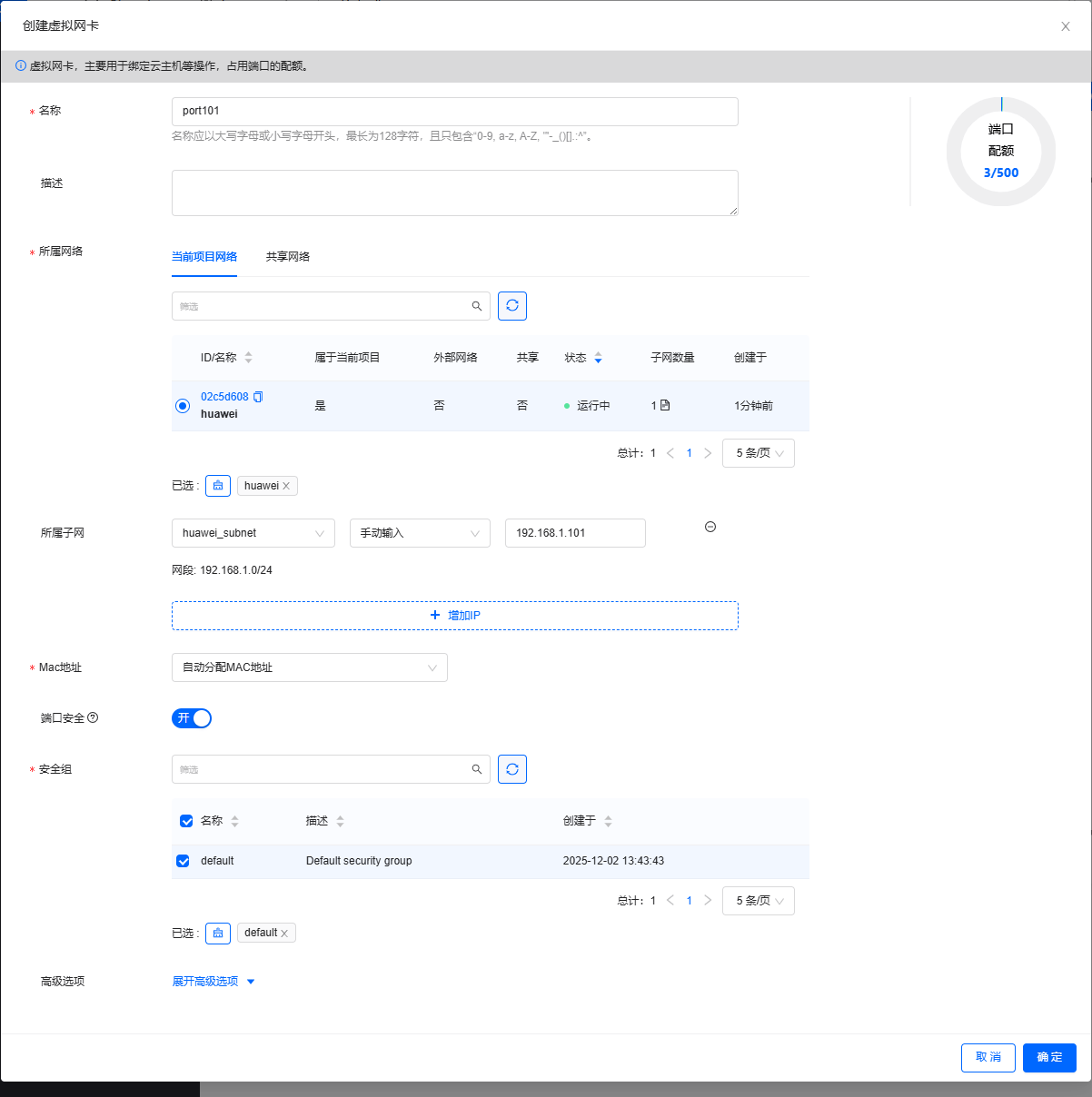
单击【创建虚拟网卡】按钮,弹出对话框设置虚拟网卡基本信息
-
单击【确定】按钮,成功创建虚拟网卡
port101
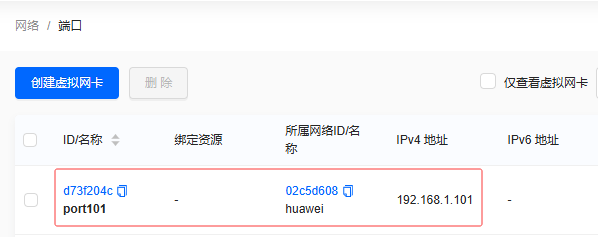
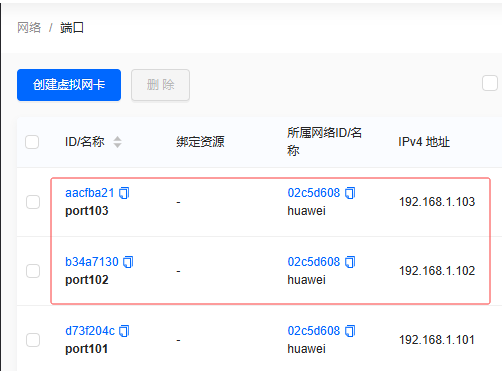
-
同理创建虚拟网卡
port102和port103
6. 管理安全组规则
6.1 为什么要管理安全组规则
- 管理安全组规则至关重要,因为后续使用FinalShell工具软件通过SSH连接云主机时,需设置规则放开ICMP协议和TCP协议入口的全部端口。这样能确保连接的顺利进行,同时保障网络安全,在满足连接需求的前提下,有效控制网络访问权限,防止潜在的安全威胁。
6.2 在默认安全组里创建规则
-
显示【安全组】页面
-
单击【创建规则】按钮,弹出对话框

-
设置
所有TCP协议
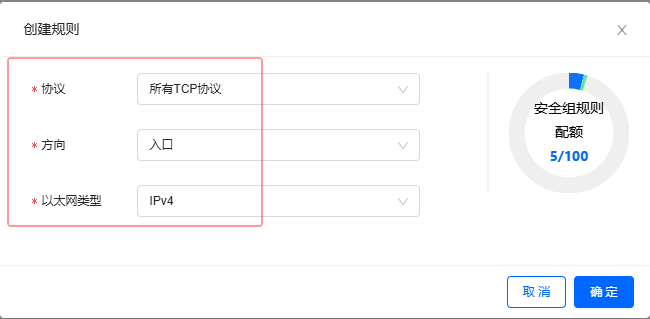
-
单击【确定】按钮,提示"创建规则成功"
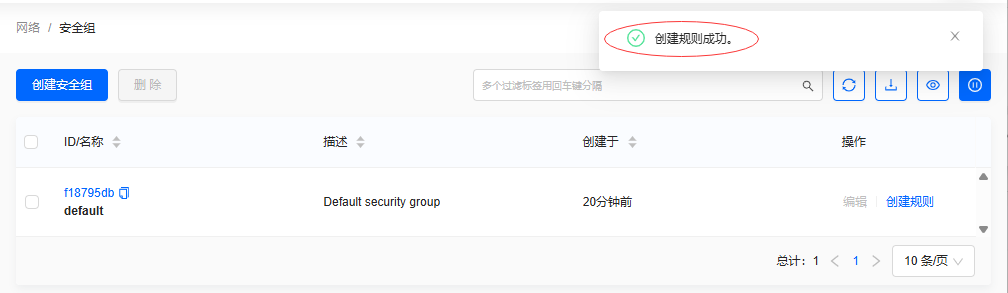
-
单击【创建规则】按钮,弹出对话框,设置
所有ICMP协议
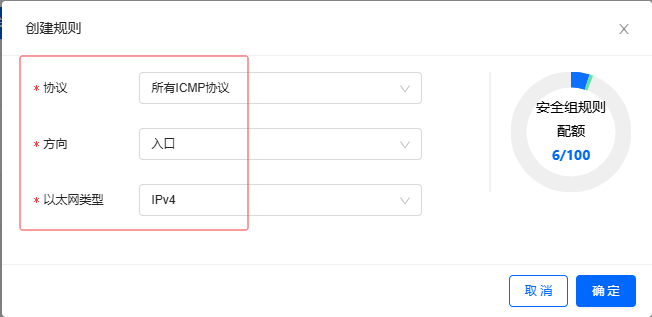
-
单击【确定】按钮,提示"创建规则成功"

7. 创建云主机
7.1 创建云主机bigdata1
-
显示【云主机】页面
-
单击【创建云主机】按钮,在弹出的对话框里设置云主机基本信息
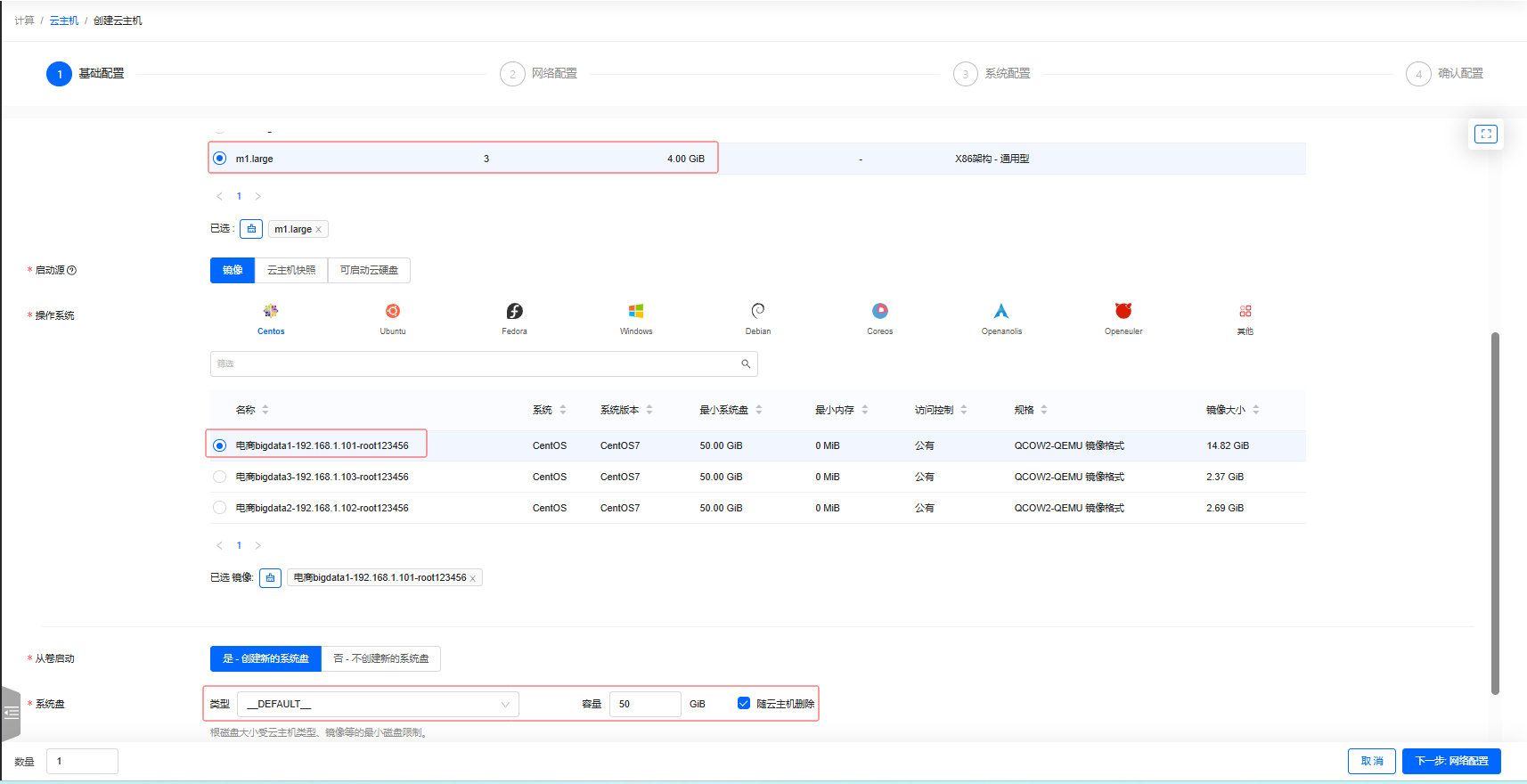
-
单击【下一步:网络配置】按钮,在弹出的对话框里选择
port101端口,勾选default安全组

-
单击【下一步:系统配置】按钮,在弹出的对话框里设置名称与登录密码

-
单击【下一步:确认配置】按钮
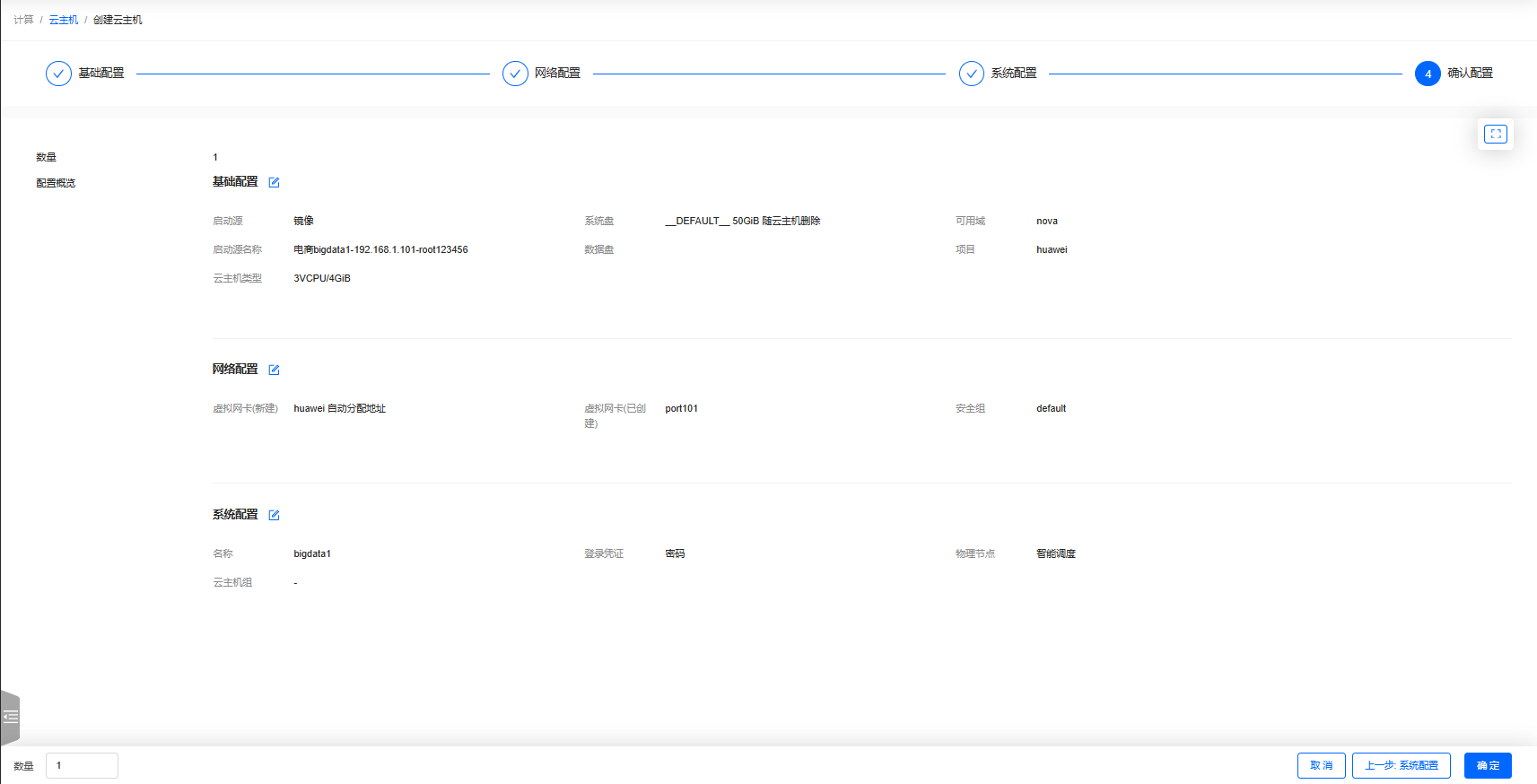
-
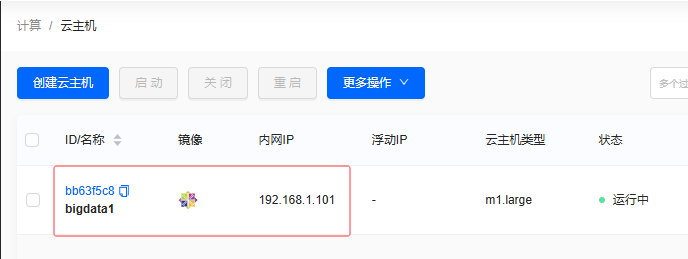
单击【确定】按钮,成功创建云主机
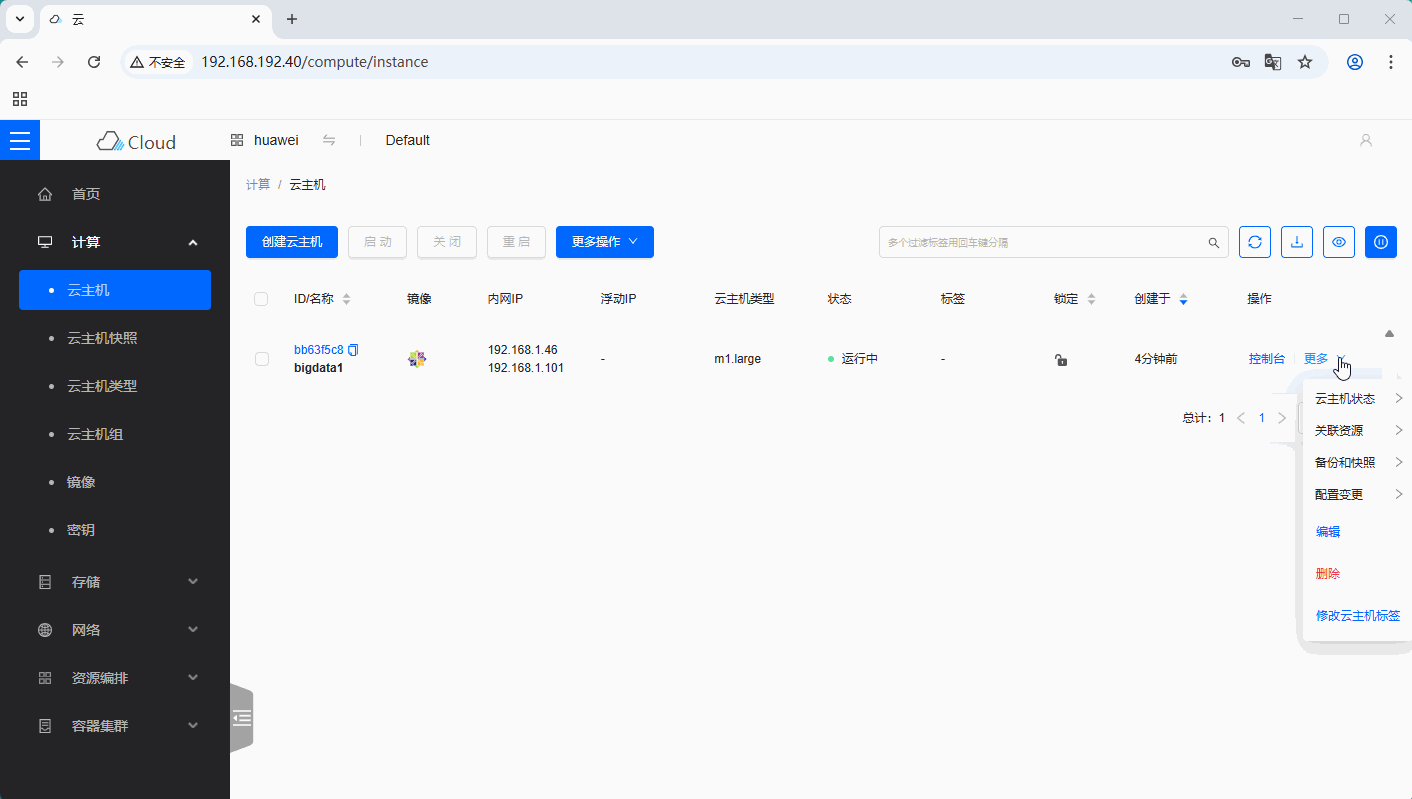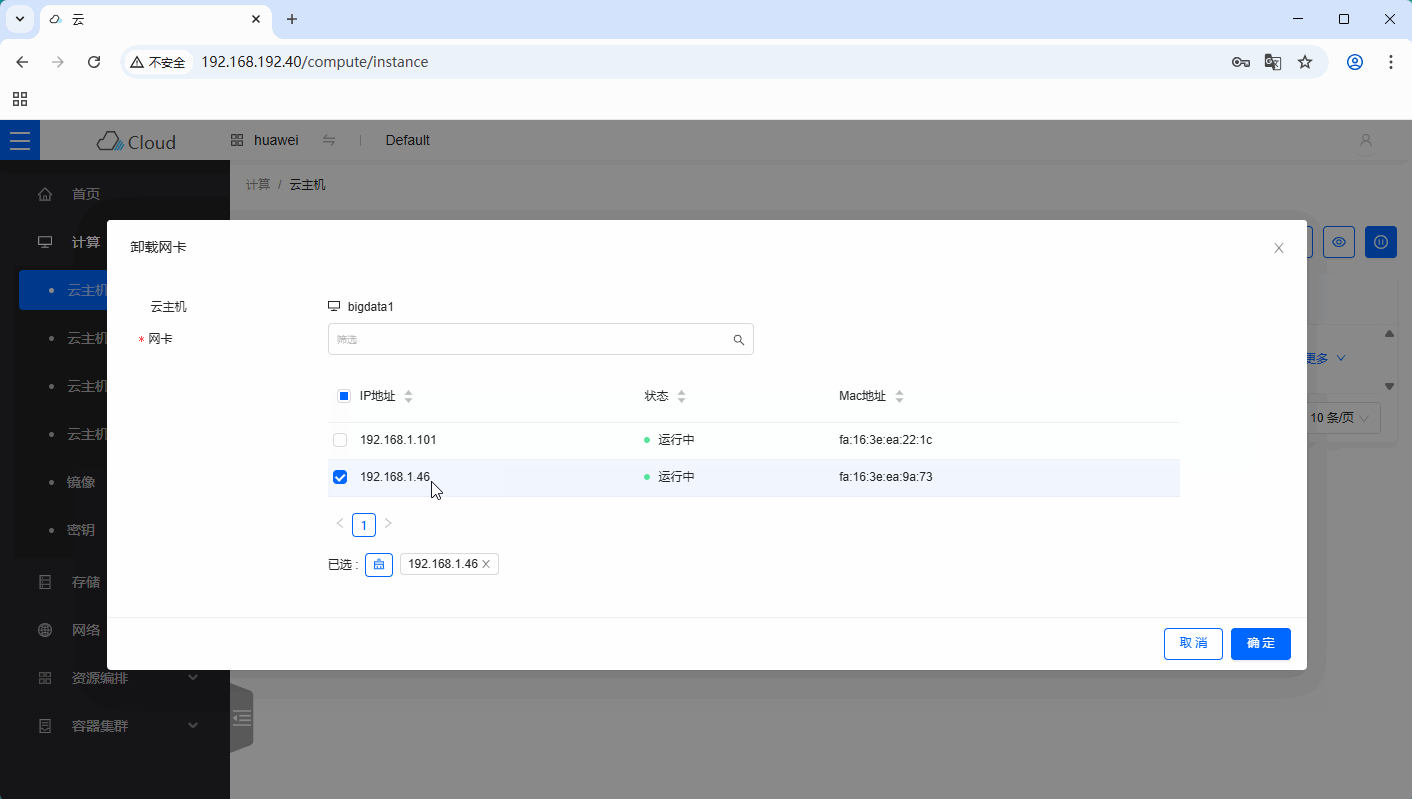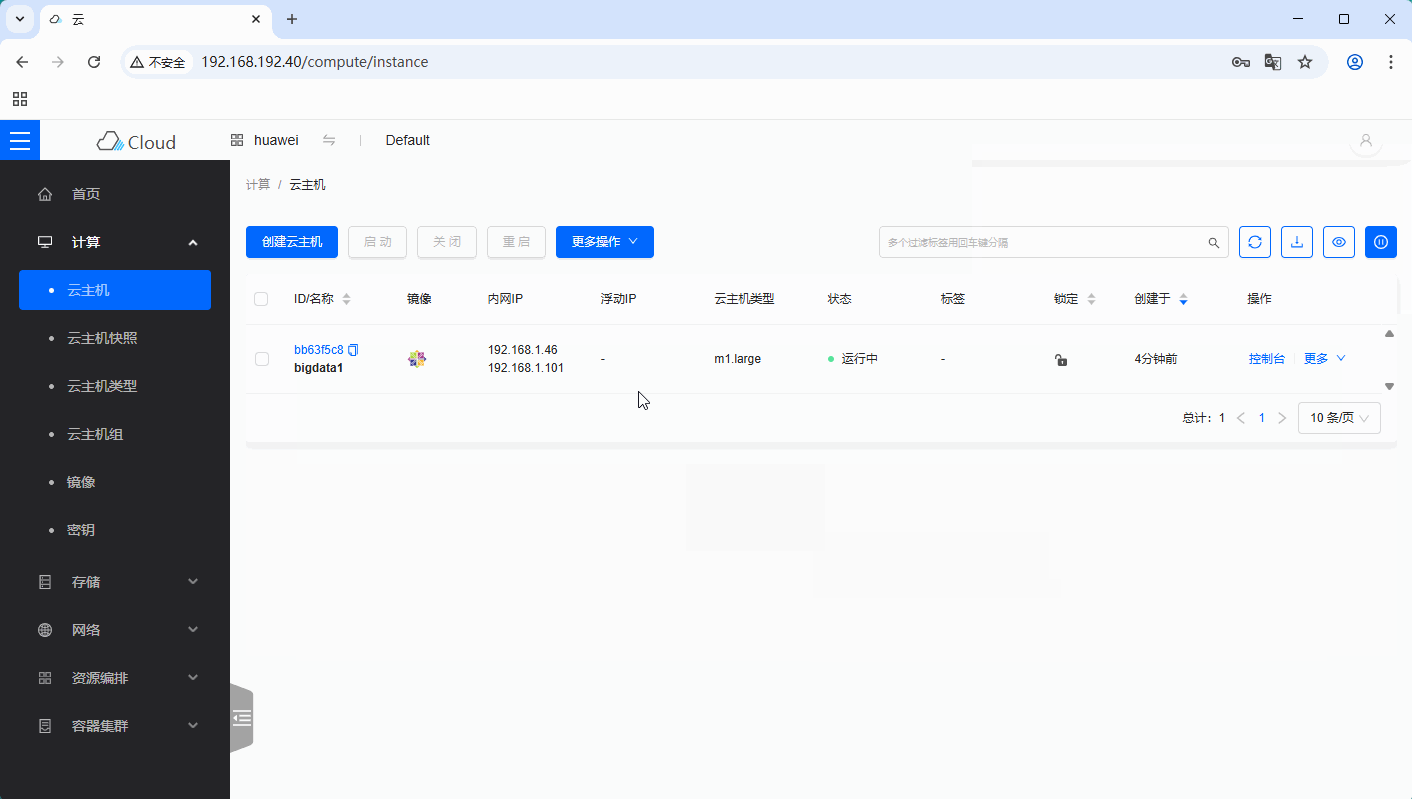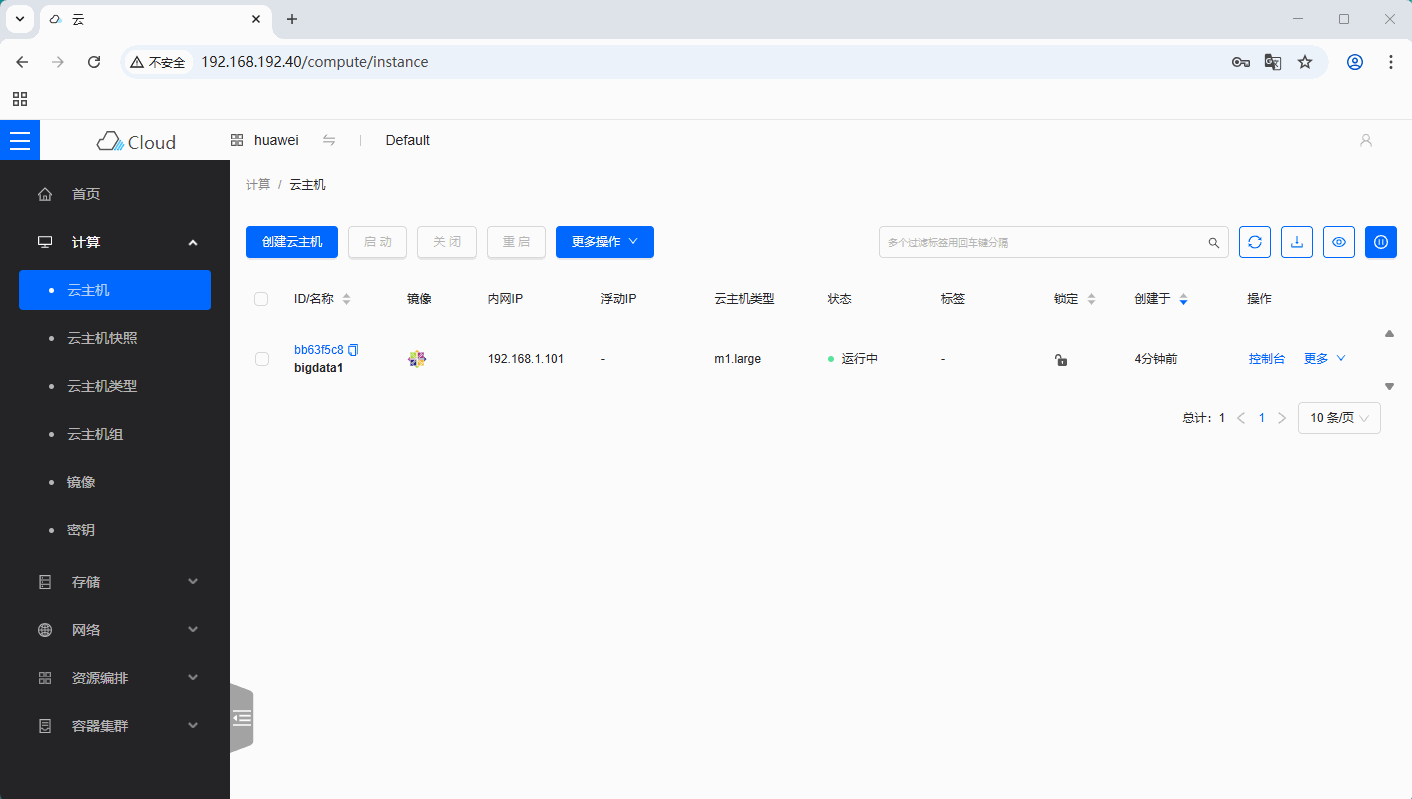
bigdata1,有固定IP地址192.168.1.101
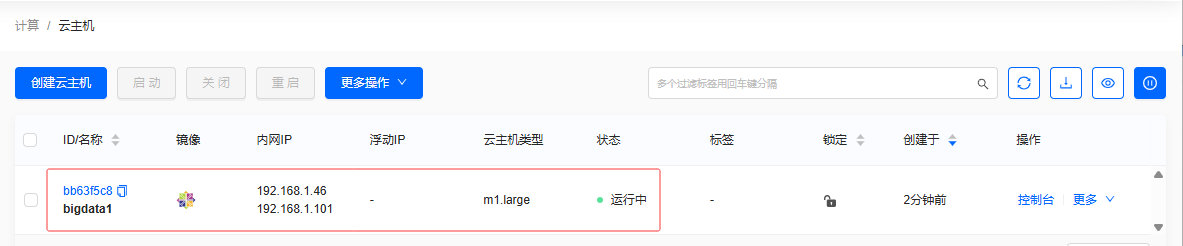
-
内网IP有两个,我们要解绑
192.168.1.46
-
云主机
bigdata1内网IP:192.168.1.101
7.2 创建云主机bigdata2
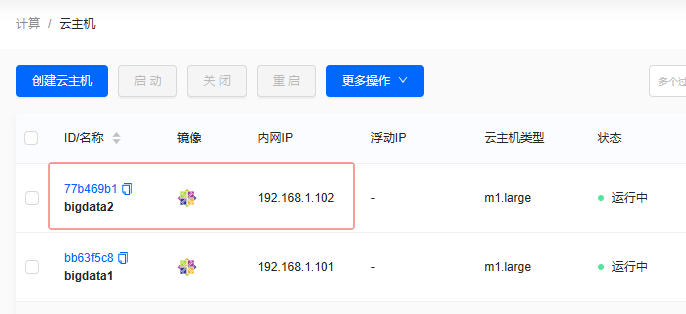
- 同理创建云主机
bigdata2,有固定IP地址192.168.1.102
7.3 创建云主机bigdata3
- 同理创建云主机
bigdata3,有固定IP地址192.168.1.103

8. 绑定浮动IP地址
8.1 为何要绑定
- 绑定浮动IP地址是实现FinalShell远程连接云主机的关键步骤。浮动IP地址具有灵活性,可与云主机动态绑定,即便云主机发生故障迁移等情况,IP地址仍可保持不变,从而确保FinalShell能够稳定地远程连接到云主机,保障远程操作的连续性和可靠性。
8.2 申请浮动IP地址
-
显示【浮动IP】页面

-
单击【申请IP】按钮,在弹出的对话框里设置网络信息与批量申请数量
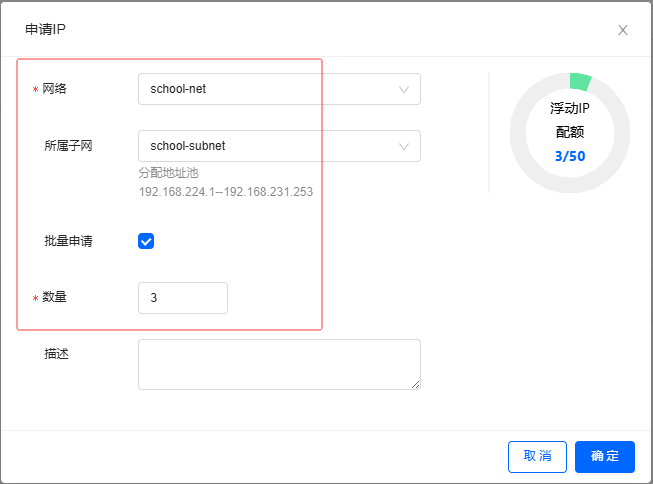
-
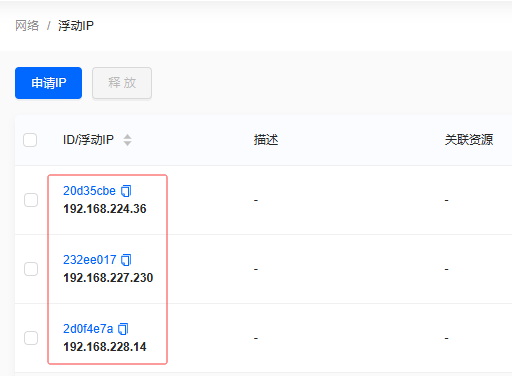
单击【确定】按钮,成功申请了三个浮动IP地址
8.3 绑定浮动IP地址
-
显示【云主机】页面
-
给云主机
bigdata1绑定浮动IP地址,【更多】下拉菜单的子菜单【关联资源】,【关联资源】的子菜单【绑定浮动IP】
-
单击【绑定浮动IP】菜单项,将云主机IP与浮动IP地址进行绑定

-
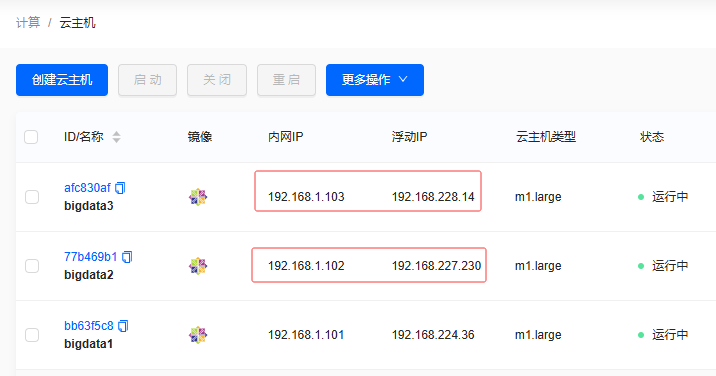
单击【确定】按钮,成功给云主机
bigdata1绑定浮动IP地址

-
同理,给云主机
bigdata2和bigdata3绑定相应的浮动IP地址
9. 远程连接云主机
9.1 启动FinalShell
- 启动FinalShell,目前尚未创建任何远程连接
9.2 远程连接云主机bigdata1
-
弹出【连接管理器】
-
新建
SSH连接

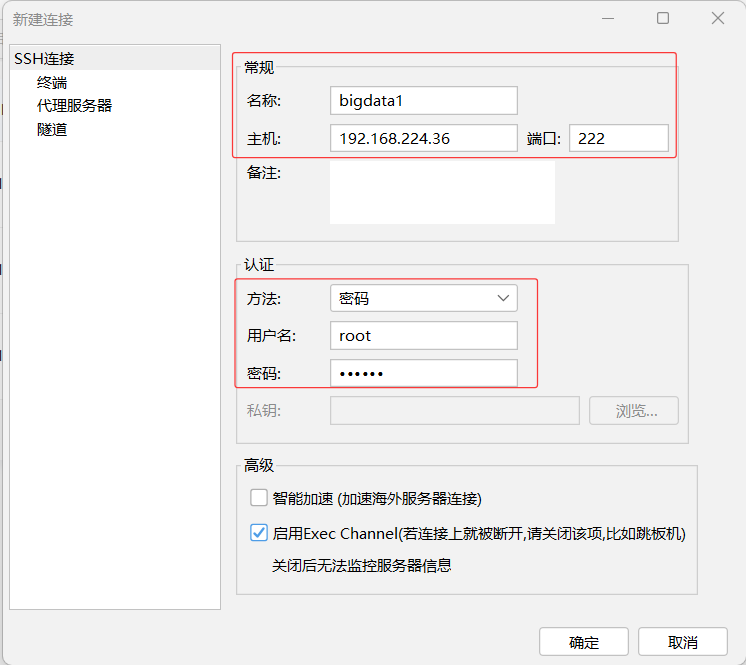
-
单击【SSH连接(Linux)】,在弹出的对话框里设置常规和认证信息,注意密码是
123456
-
单击【确定】按钮,成功创建连接
bigdata1
-
单击
bigdata1连接,弹出【安全警告】对话框

-
单击【接受并保存】按钮
9.3 远程连接云主机bigdata2
- 同理,远程连接云主机
bigdata2
9.4 远程连接云主机bigdata3
- 同理,远程连接云主机
bigdata3
10. 修改本地的IP与主机名映射文件
-
在文件
C:\Windows\System32\drivers\etc\hosts里添加三条映射
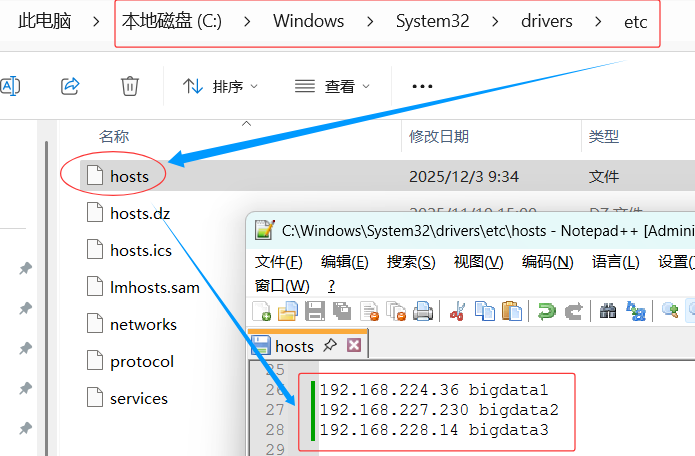 java
java192.168.224.36 bigdata1 192.168.227.230 bigdata2 192.168.228.14 bigdata3
11. 本机Ping云主机
11.1 按IP地址来Ping
- 执行命令:
ping 192.168.224.36

11.2 按主机名来Ping
- 执行命令:
ping bigdata1

12. 修改配置文件
12.1 修改hdfs-site.xml文件
- 执行命令:
cd $HADOOP_HOME/etc/hadoop

- 执行命令:
vim hdfs-site.xml,添加红框内属性,禁用所有权限检查
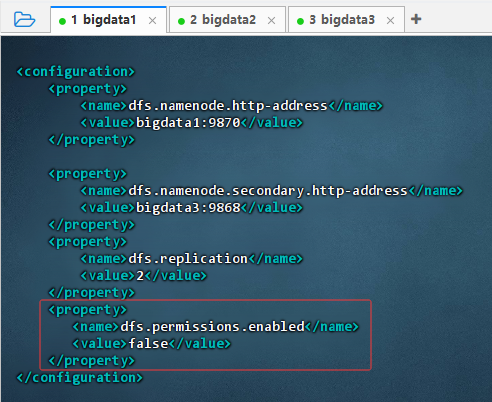
- 执行命令:
scp hdfs-site.xml root@bigdata2:$HADOOP_HOME/etc/hadoop

- 执行命令:
scp hdfs-site.xml root@bigdata3:$HADOOP_HOME/etc/hadoop

12.2 修改log4j.properties文件
- 执行命令:
vim log4j.properties,添加一句:log4j.logger.org.apache.hadoop=ERROR
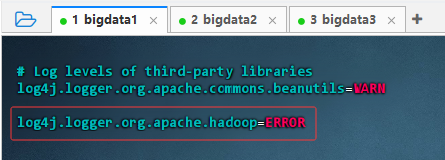
- 执行命令:
scp log4j.properties root@bigdata2:$HADOOP_HOME/etc/hadoop

- 执行命令:
scp log4j.properties root@bigdata3:$HADOOP_HOME/etc/hadoop

13. 启动大数据集群服务
-
在云主机
bigdata1上,执行命令:allstart.sh
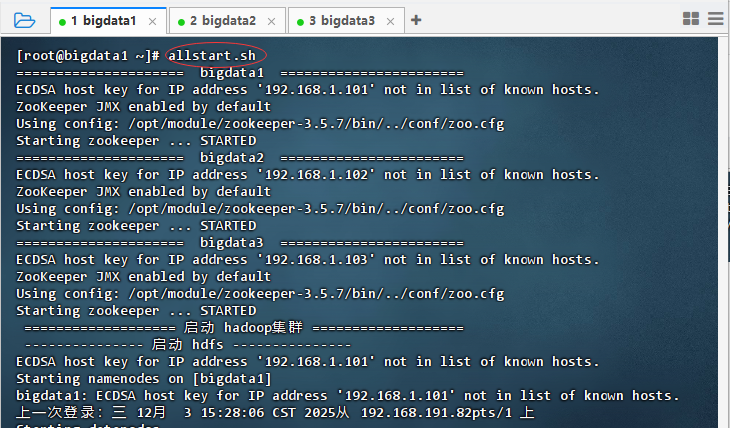
-
执行命令:
jps
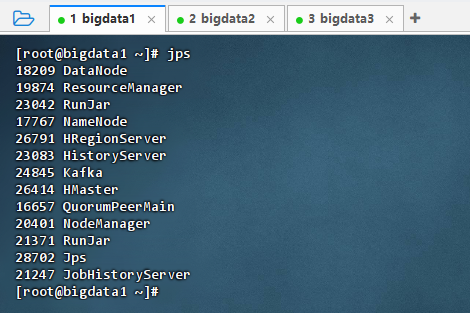
-
查看Hadoop的Web UI页面 -
http://bigdata1:9870
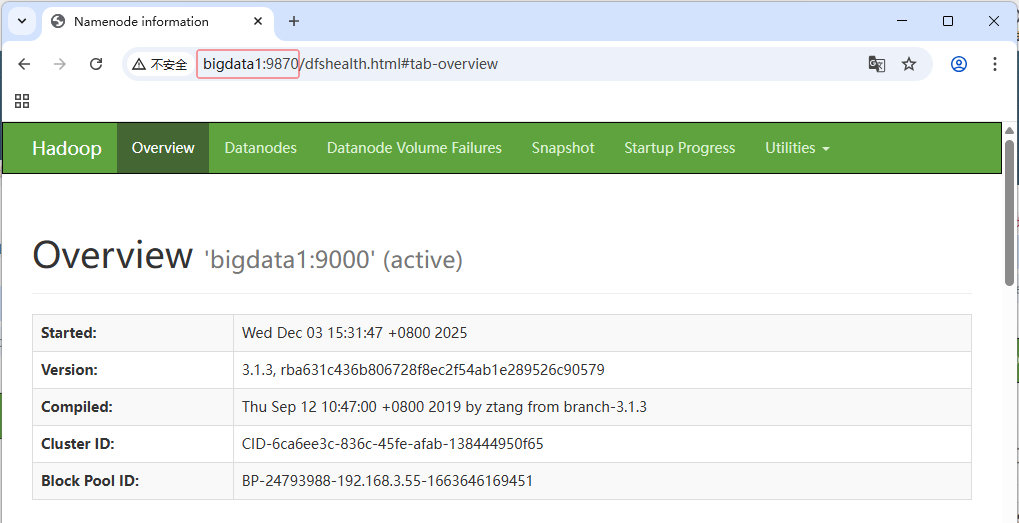
-
查看HDFS文件系统

14. 完成词频统计任务
14.1 准备数据文件
-
执行命令:
vim words.txt
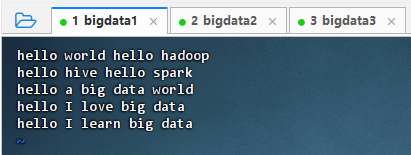 shell
shellhello world hello hadoop hello hive hello spark hello a big data world hello I love big data hello I learn big data -
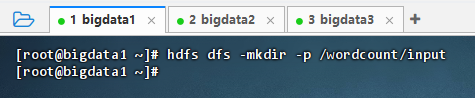
执行命令:
hdfs dfs -mkdir -p /wordcount/input
-
执行命令:
hdfs dfs -put words.txt /wordcount/input

14.2 利用MR实现词频统计
14.2.1 创建Maven项目
- 设置项目基本信息
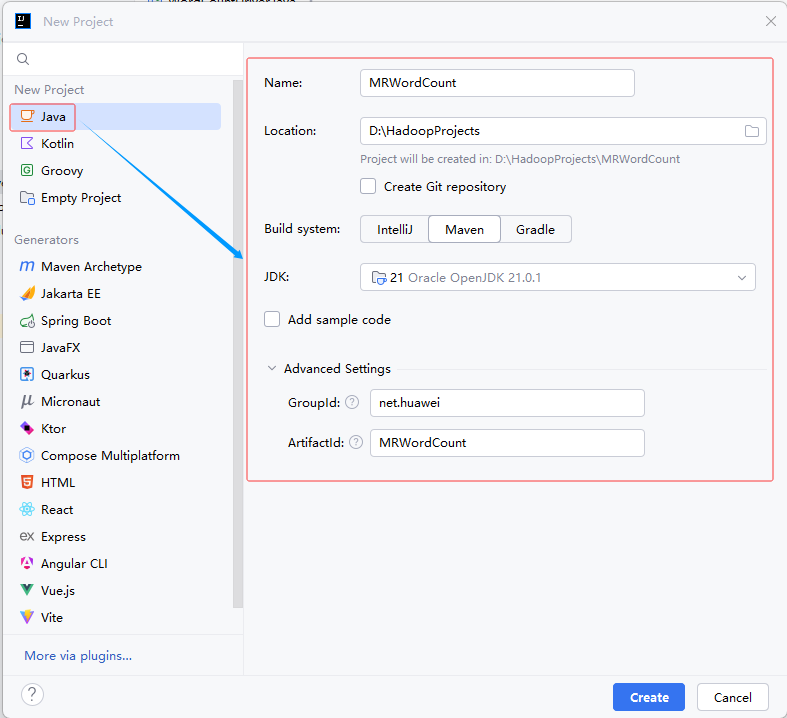
- 单击【Create】按钮,生成项目基本骨架
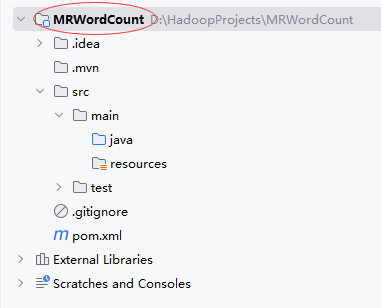
14.2.2 添加hadoop依赖
- 在
pom.xml里添加hadoop和junit依赖
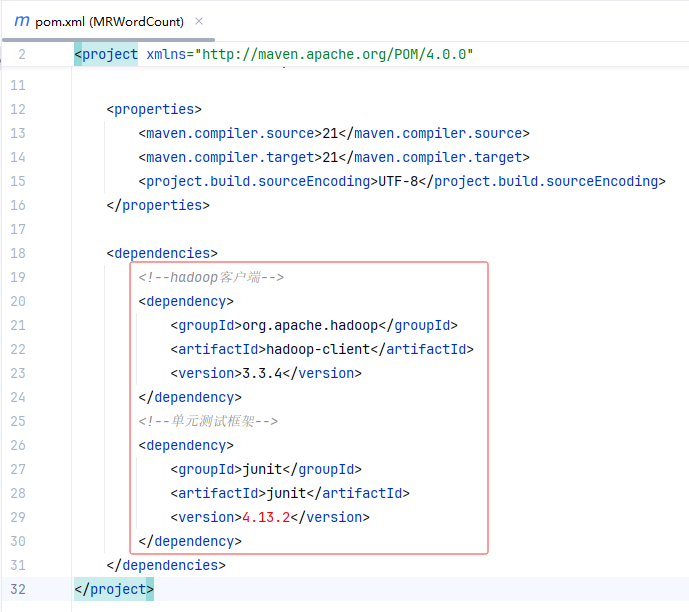
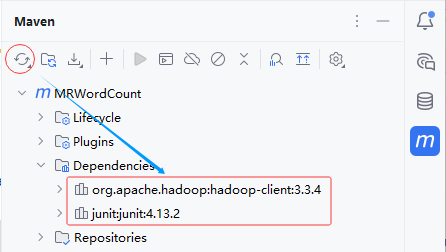
- 刷新项目依赖
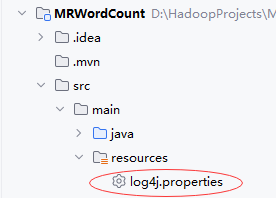
14.2.3 创建日志属性文件
-
在
resources里创建log4j.properties文件
 shell
shelllog4j.rootLogger=ERROR, stdout, logfile log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/wordcount.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
14.2.4 创建词频统计映射器类
-
创建
net.huawei.mr包
-
在
net.huawei.mr包里创建WordCountMapper类
 java
javapackage net.huawei.mr; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 功能:词频统计映射器 * 作者:华卫 * 日期:2025年12月03日 */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取行文本 String line = value.toString(); // 按空格拆分成单词数组 String[] words = line.split(" "); // 遍历单词数组,生成输出键值对 for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } } -
代码说明 :该代码定义了一个 Hadoop MapReduce 的 Mapper 类,用于词频统计。它将输入的每行文本按空格拆分为单词,对每个单词输出键值对(单词, 1),供后续 Reduce 阶段累加计数。继承自
Mapper<LongWritable, Text, Text, IntWritable>,符合 WordCount 任务规范。
14.2.5 创建词频统计归并器类
-
在
net.huawei.mr包里创建WordCountReducer类
 java
javapackage net.huawei.mr; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 功能:词频统计归并器类 * 作者:华卫 * 日期:2025年12月03日 */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, NullWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 定义键(单词)出现次数 int count = 0; // 遍历值迭代器,累加次数 for (IntWritable value : values) { count = count + value.get(); } // 生成新的输出键 String newKey = "(" + key.toString() + "," + count + ")"; // 输出新的键值对(newKey, null) context.write(new Text(newKey), NullWritable.get()); } } -
代码说明:该代码实现 Hadoop MapReduce 的 Reducer 类,用于词频统计。它接收相同单词的所有计数(值为1的 IntWritable),累加得到总频次,并将结果格式化为 "(单词,次数)" 字符串作为新键输出,值设为 NullWritable,适用于仅需输出统计结果的场景。
14.2.6 创建词频统计驱动器类
-
在
net.huawei.mr包里创建WordCountDriver类
 java
javapackage net.huawei.mr; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.net.URI; /** * 功能:词频统计驱动器 * 作者:华卫 * 日期:2025年12月03日 */ public class WordCountDriver { public static void main(String[] args) throws Exception { // 创建配置对象 Configuration conf = new Configuration(); // 设置客户端使用数据节点主机名属性 conf.set("dfs.client.use.datanode.hostname", "true"); // 获取工作实例 Job job = Job.getInstance(conf); // 设置作业启动类 job.setJarByClass(WordCountDriver.class); // 设置Mapper类 job.setMapperClass(WordCountMapper.class); // 设置map任务输出键类型 job.setMapOutputKeyClass(Text.class); // 设置map任务输出值类型 job.setMapOutputValueClass(IntWritable.class); // 设置Reducer类 job.setReducerClass(WordCountReducer.class); // 设置reduce任务输出键类型 job.setOutputKeyClass(Text.class); // 设置reduce任务输出值类型 job.setOutputValueClass(NullWritable.class); // 定义uri字符串(分布式文件系统前缀) String uri = "hdfs://bigdata1:9000"; // 创建输入路径(可以指向目录,也可以指向文件) Path inputPath = new Path(uri + "/wordcount/input"); // 创建输出路径 Path outputPath = new Path(uri + "/wordcount/output"); // 获取文件系统 FileSystem fs = FileSystem.get(new URI(uri), conf); // 删除输出路径(第2个参数设置是否递归删除) fs.delete(outputPath, true); // 给作业添加输入路径(允许多个) FileInputFormat.addInputPath(job, inputPath); // 给作业设置输出路径(只能一个) FileOutputFormat.setOutputPath(job, outputPath); // 等待作业完成 job.waitForCompletion(true); // 输出统计结果 System.out.println("======统计结果======"); // 获取输出路径的文件状态数组 FileStatus[] fileStatuses = fs.listStatus(outputPath); // 遍历文件状态数组 for (int i = 1; i < fileStatuses.length; i++) { // 输出结果文件路径 System.out.println(fileStatuses[i].getPath()); // 获取文件系统字节输入流 FSDataInputStream in = fs.open(fileStatuses[i].getPath()); // 将结果文件显示在控制台 IOUtils.copyBytes(in, System.out, 4096, false); } } } -
代码说明:该驱动类配置并提交 Hadoop 词频统计作业:设置 Mapper 和 Reducer 类及其输入输出类型,指定 HDFS 输入/输出路径,自动删除已有输出目录,作业完成后读取并打印结果文件内容到控制台。
14.2.7 运行程序,查看结果
- 运行词频统计驱动器类

14.3 利用Hive实现词频统计
- 执行命令:
hive,进入Hive客户端
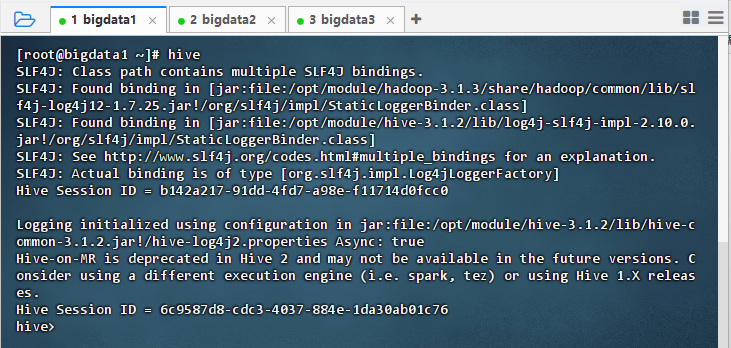
14.3.1 基于HDFS文件创建外部表
- 执行语句:
create external table t_word(line string) location '/wordcount/input';
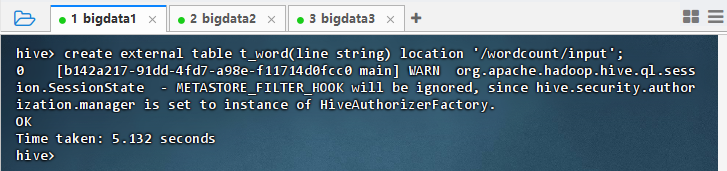
14.3.2 展开每行单词
- 执行语句:
select explode(split(line, ' ')) as word from t_word;
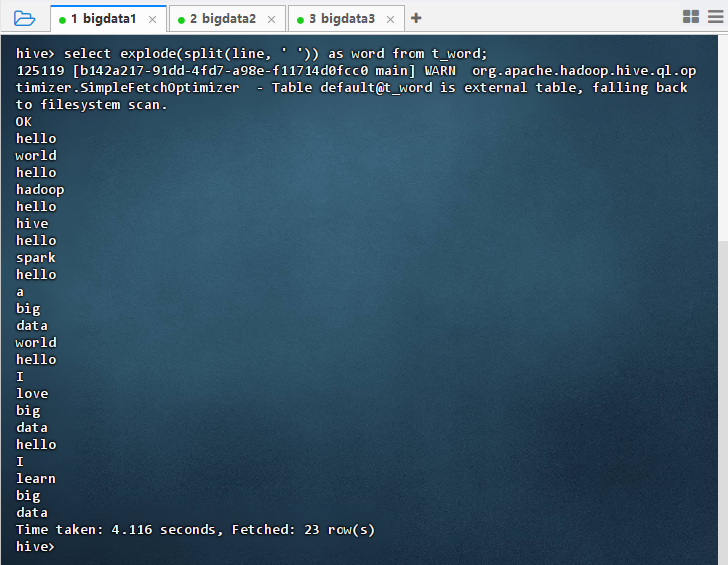
14.3.3 基于查询结果创建视图
- 执行语句:
create view v_word as select explode(split(line, ' ')) as word from t_word;
14.3.4 基于视图分组统计
- 不排序统计,执行语句:
select word, count(*) from v_word group by word;
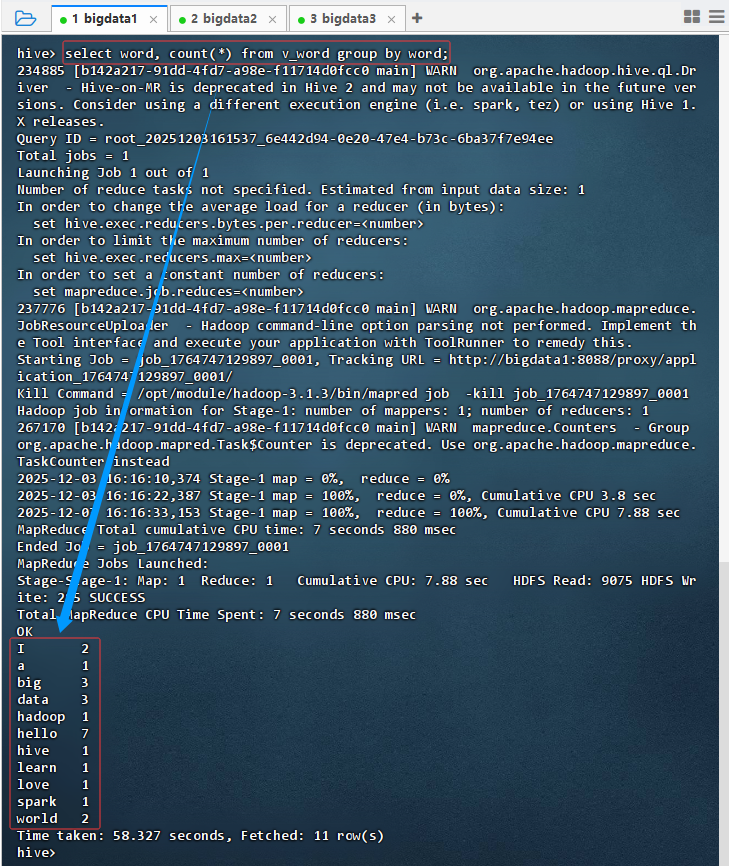
- 按词频排序统计,执行语句:
select word, count(*) as count from v_word group by word order by count desc;
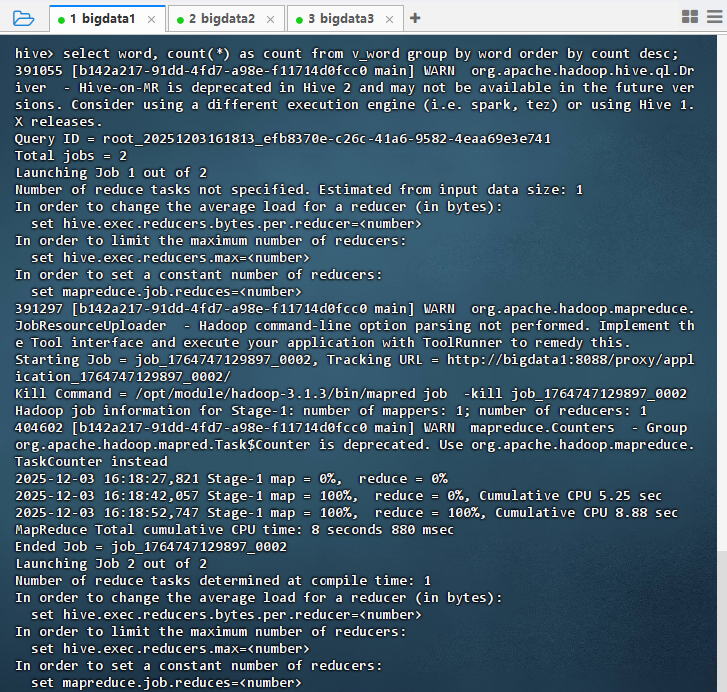
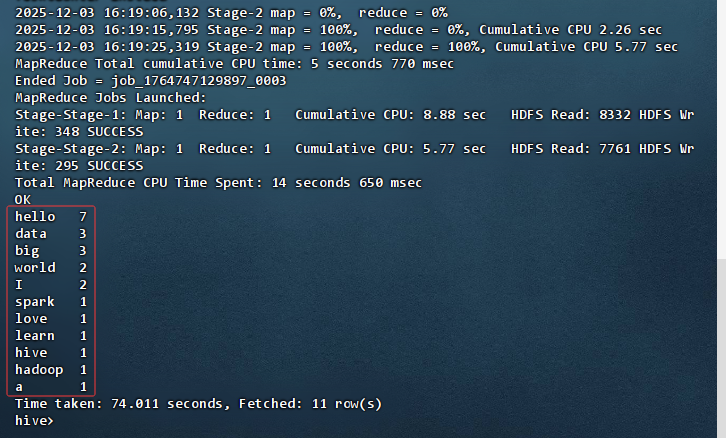
14.4 利用Spark实现词频统计
- 执行命令:
spark-shell
14.4.1 利用Spark RDD实现词频统计
-
执行代码
javasc.textFile("hdfs://bigdata1:9000/wordcount/input/words.txt") .flatMap(_.split(" ")) .map((_, 1)) .reduceByKey(_ + _) .sortBy(_._2, false) .collect() .foreach(println)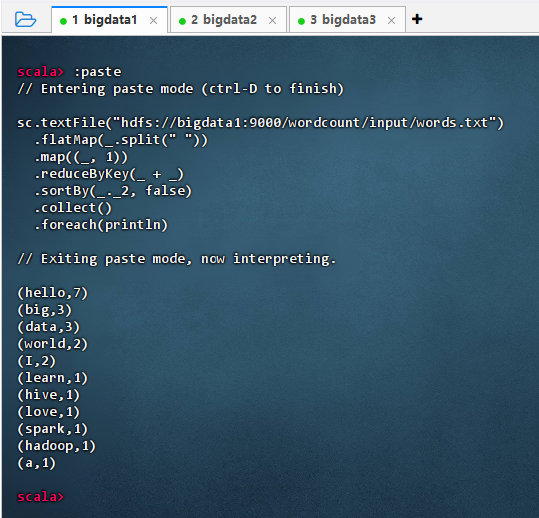
14.4.2 利用Spark SQL实现词频统计
-
读取文本文件生成数据帧
-
执行命令:
val df = spark.read.text("hdfs://bigdata1:9000/wordcount/input/words.txt")

-
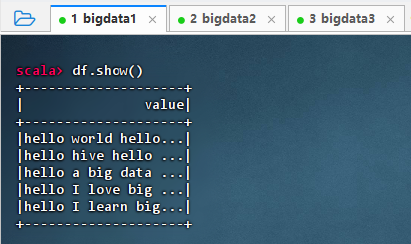
执行命令:
df.show()
-
-
基于数据帧生成临时视图
- 执行命令:
df.createOrReplaceTempView("t_value")
- 执行命令:
-
对临时视图进行词频统计
-
执行代码
scalaval wc = spark.sql(""" select word, count(*) as count from (select explode(split(value, " ")) as word from t_value) group by word order by count desc """)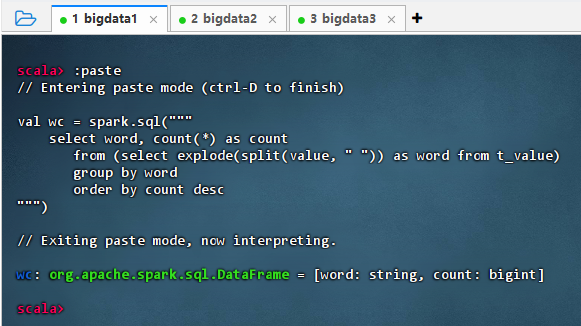
-
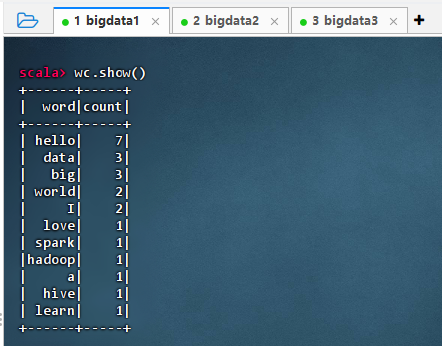
执行命令:
wc.show()
-
15. 关闭大数据集群服务
- 在云主机
bigdata1上,执行命令:allstop.sh

16. 实战小结
- 通过本次实战,我们完整地搭建并运行了一个基于Hadoop、Hive和Spark的大数据集群环境。从网络和云主机的创建、配置,到集群服务的启动与管理,再到利用MapReduce、Hive和Spark实现词频统计任务,全面掌握了大数据平台的搭建与应用开发流程。在实战中,我们成功实现了数据的分布式存储与处理,验证了不同技术框架在数据处理中的优势和适用场景。通过FinalShell远程连接和配置文件修改,进一步增强了对集群管理的理解。整个过程不仅提升了技术操作能力,还加深了对大数据生态系统各组件协同工作的认识,为后续更复杂的大数据项目积累了宝贵经验。