全文链接:https://tecdat.cn/?p=38115
分析师:Yang Yang,Kechen Zhao
在当今科技日新月异的时代,数据的有效利用成为各领域突破发展的关键。于医疗领域,乳腺癌的高发性与严重性不容忽视,优化抗乳腺癌候选药物的筛选与特性预测迫在眉睫,雌激素受体 α 亚型相关研究为此提供了重要方向**(** 点击文末"阅读原文"获取完整代码数据******** )。
金融领域同样挑战重重,信贷风控中精准预测违约支付及把握相关因素变化规律,以及比特币价格走势的准确预判,都对决策制定至关重要。再者,企业经营中处理严重不平衡的破产数据以评估风险,也是一大难点。
在此背景下,XGBoost、Adaboost、CatBoost 等梯度提升算法展现出强大的预测能力。
XGBoost、CatBoost、LightGBM抗乳腺癌候选药物的优化建模|附数据代码
本文围绕抗乳腺癌候选药物的优化建模展开研究。通过对相关数据的处理、变量筛选、不同预测模型的构建以及变量优化等工作,旨在为同时优化雌激素受体 α 亚型(ERα)拮抗剂的生物活性和吸收、分布、代谢、排泄和毒性(ADMET)性质提供有效的预测服务,以助力抗乳腺癌候选药物的筛选与优化。
引言
乳腺癌是全球常见且致死率较高的癌症之一,雌激素受体 α 亚型(ERα)在乳腺肿瘤形成过程中起促进作用,能拮抗 ERα 活性的化合物有望成为治疗乳腺癌的候选药物。为此,需构建化合物生物活性的定量预测模型和 ADMET 性质的分类预测模型进行相关优化预测。
问题提出与假设
(一)提出问题
-
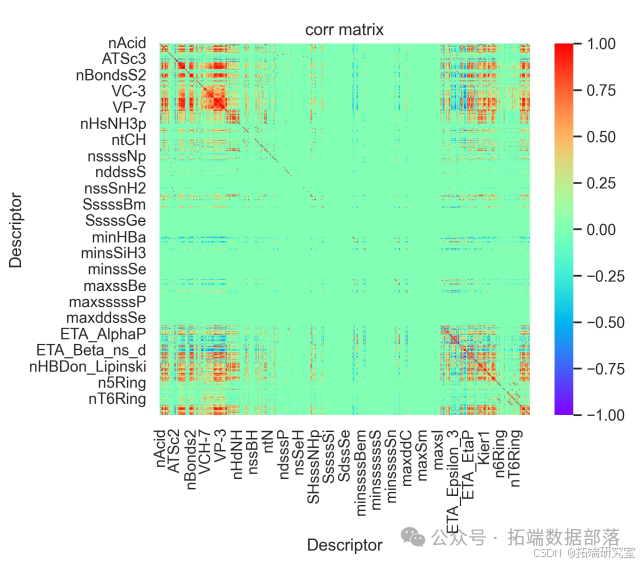
数据处理及变量筛选:对 1974 个化合物的 729 个分子描述符进行变量选择,依重要性排序并给出前 20 个对生物活性影响显著的分子描述符,说明筛选过程合理性。
-
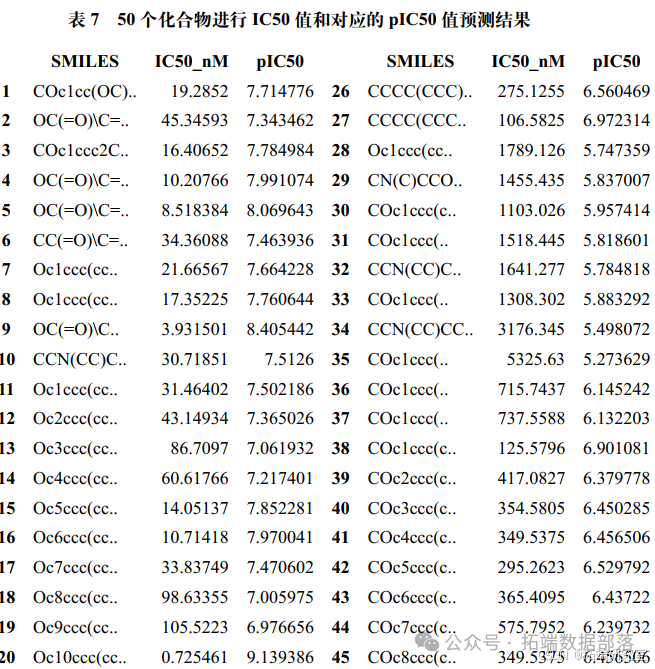
构建化合物对 ERα 生物活性的定量预测模型:选不超 20 个分子描述符变量构建模型,用其对 50 个化合物预测 IC50 值和 pIC50 值。
-
构建 ADMET 性质的分类预测模型:利用 729 个分子描述符,针对 1974 个化合物的 ADMET 数据构建 Caco - 2、CYP3A4、hERG、HOB、MN 的分类预测模型,并对 50 个化合物进行相应预测。
-
变量优化:寻找使化合物抑制 ERα 生物活性更好且 ADMET 性质(至少三个较好)更佳的分子描述符及其取值或取值范围。
(二)问题假设
go
假设涉及化合物数据测量正确、分子结构描述符间相互影响、数据丢失判定、取值范围界定、预测模型结果准确性以及模型连续性等方面,为后续研究提供前提条件。问题分析与解决
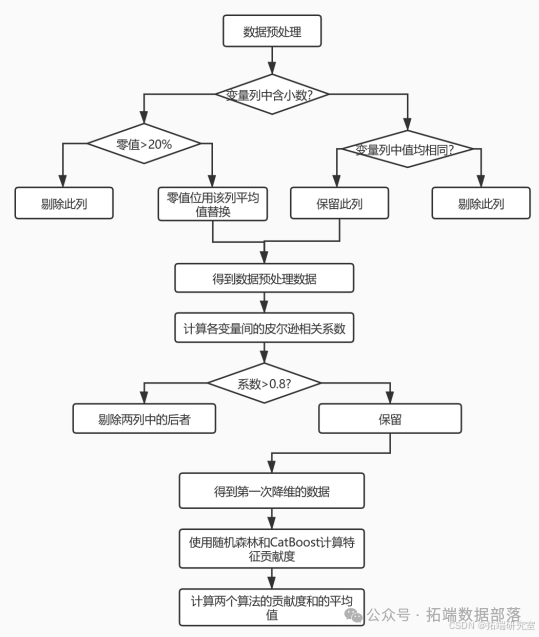
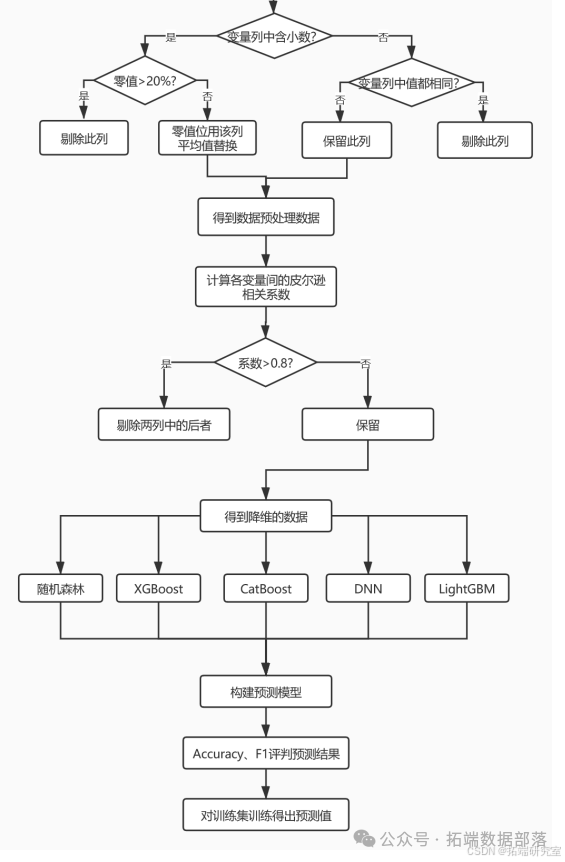
(一)问题一:数据处理及变量筛选
-
数据预处理:对 729 个分子描述符(特征变量)进行数据预处理,设定阈值剔除超阈值及仅有一种取值的分子描述符,对未超阈值的缺失处用未缺失值算术平均数补全。
-
筛选 20 个主要分子描述符:
-
首先用皮尔逊相关系数分析各分子描述符相关性,对相关性高的两个分子描述符仅保留一个,实现第一次降维。
-
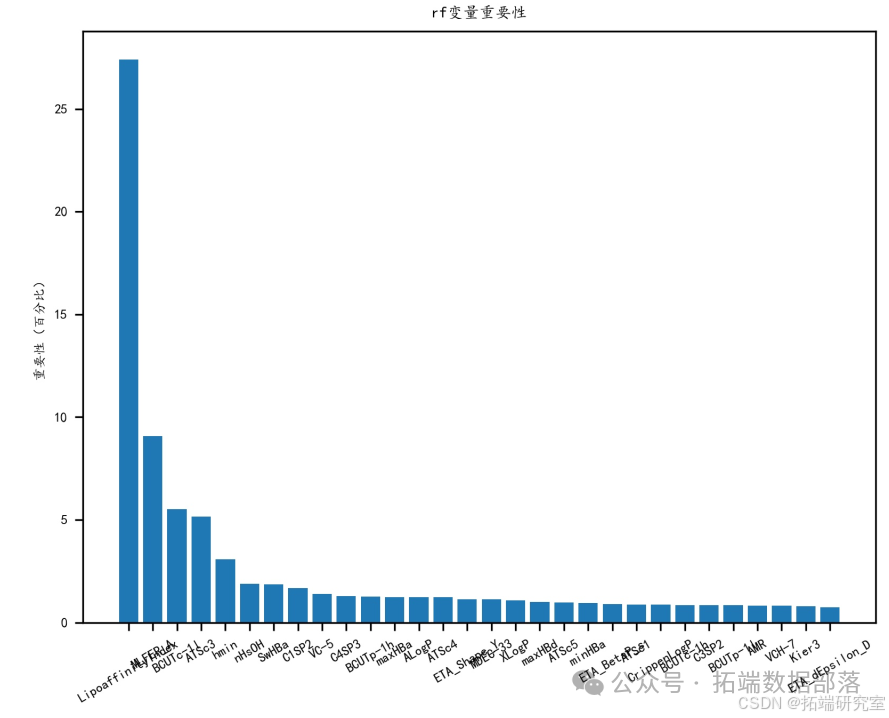
再用随机森林和 CatBoost 筛选剩下的分子描述符,实现第二次降维,并依特征重要性排序选出前 20 个对生物活性贡献度最高的变量。
(二)问题二:构建化合物对 ERα 生物活性的定量预测模型
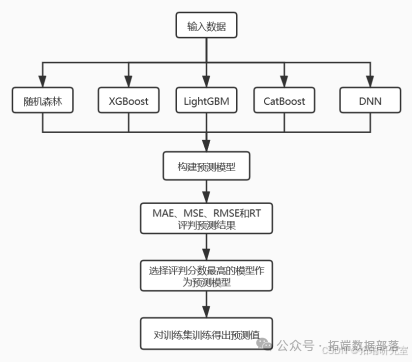
-
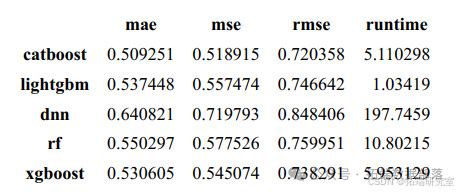
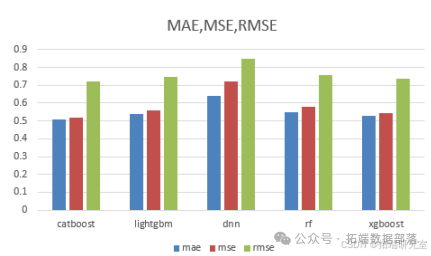
数据划分与模型选择:用随机森林、XGBoost、CatBoost、LightGBM 四种机器学习算法和 DNN 深度神经网络,将 1974 组数据按 8:2 比例分为训练集和测试集,以测试集预测结果为模型评判依据,评判标准为 MAE(平均绝对误差)、MSE(均方误差)、RMSE(均方根误差)和 RT(运行时间)。
-
确定最终模型及预测:取评判最优结果的模型作为最终构建的预测模型,将其预测结果值填入 "ERα - activity.xlsx" 的 test 表中的 IC50 - nM 列及对应的 pIC50 列中。
(三)问题三:构建 ADMET 性质的分类预测模型
-
数据处理:与问题一数据处理方法类似,剔除不利的分子描述符,补全缺失值并更新列,再用皮尔逊系数剔除相关性高的两个分子描述符的后者。
-
模型构建与预测:同样用上述四种机器学习算法和 DNN 深度神经网络,按 8:2 分训练集和测试集,以 Accuracy(准确率)和 F1(综合评价指标)为评判标准取最优结果模型,将预测值填入相应位置。
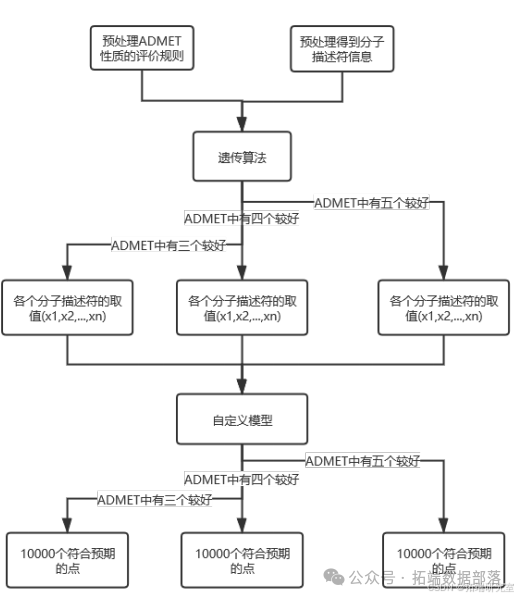
(四)问题四:变量优化
-
统一评价规则:将 ADMET 性质统一评价规则,如 Caco - 2、CYP3A4、HOB 取值为 1 表示 "好",hERG、MN 取值为 0 表示 "好",定义 ADMET 分数指标。
-
模型构建与计算:选取问题一预处理后剩余的 130 个分子描述符,用遗传算法结合问题二、三生成的模型预测 pIC50 和 ADMET 性质取值,通过评价函数得出评价值以产生和选择下一代种群。
变量筛选
点击标题查阅往期内容

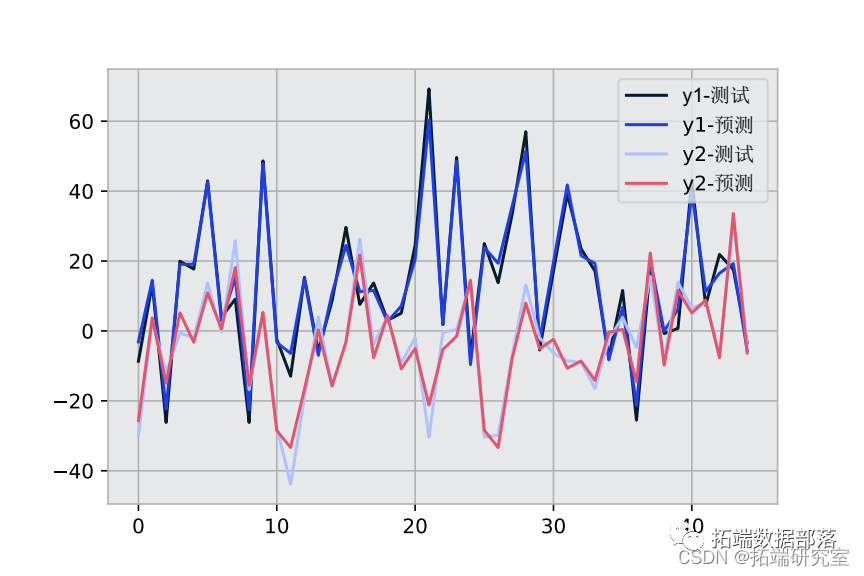
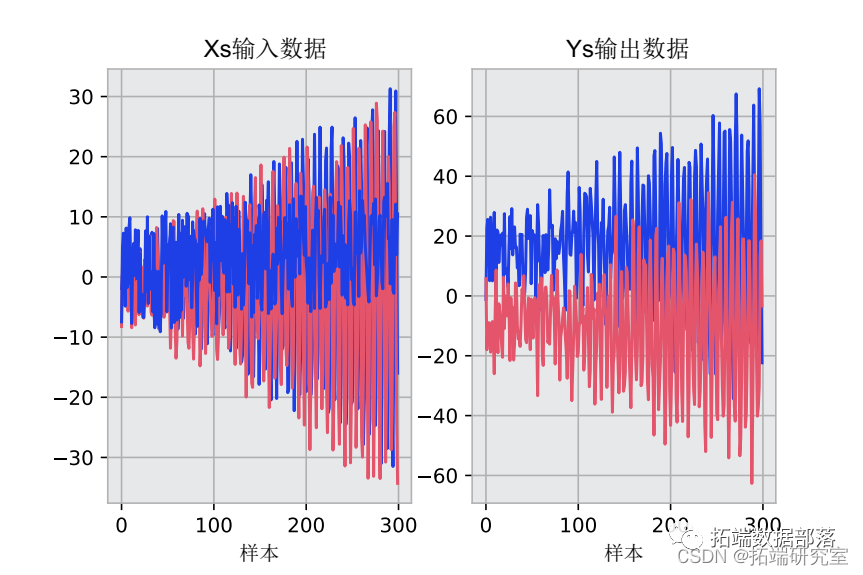
Python进行多输出(多因变量)回归:集成学习梯度提升决策树GRADIENT BOOSTING,GBR回归训练和预测可视化

左右滑动查看更多
01
02
03
04

相关算法介绍
(一)随机森林
随机森林是新兴的、高度灵活的机器学习算法,应用广泛,在分类和回归问题中有高准确率,且自带特征筛选机制,能评估各特征重要性。
(二)CatBoost
CatBoost 是基于对称决策树为基学习器的 GBDT 框架,参数少、支持类别型变量且准确性高,主要解决高效合理处理类别型特征的问题。
go
# # # 训练模型 # # #
other_params = {
'iterations': 3000, # 最大树数
'learning_rate': 0.028, # 学习率
'l2_leaf_reg': 3, # l2正则参数
39'bagging_temperature': 1, # 贝叶斯套袋控制强度
'random_strength': 1, # 分数标准差乘数
'depth': 6, # 树深
'rsm': 1, # 随机子空间(Random subspace method)
'one_hot_max_size': 50, #
如果feature包含的不同值的数目超过了指定值, 将feature转化为float。
'leaf_estimation_method': 'Gradient', #
计算叶子值的方法, Newton/ Gradient。
'fold_len_multiplier': 2, #
folds长度系数。设置大于1的参数, 在参数较小时获得最佳结果。
'border_count': 128,
'allow_writing_files': False # 不允许生成日志文件
}
model = CatBoostRegressor(**other_params)
model.fit(X_train, y_train)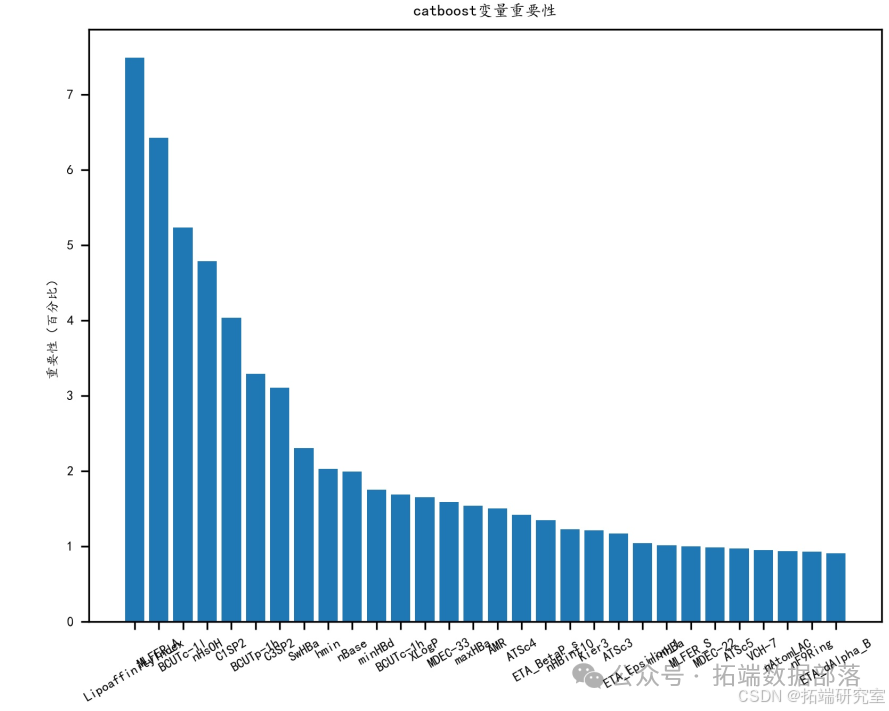
评判标准
(一)平均绝对误差(MAE)
MAE 表示预测值和观测值之间绝对误差的平均值,能准确反映实际预测误差大小,计算公式为:
go
# m表示样本数,yi表示i样本对应的真实的pIC50值,yˆi表示i样本对应的预测pIC50值
MAE = (1 / m) * sum(abs(yi - yˆi))(二)均方误差(MSE)
MSE 是参数估计值与参数真值之差平方的期望值,可评价数据变化程度,值越小说明预测模型精确度越高,计算公式为:
go
# m表示样本数,yi表示i样本对应的真实的pIC50值,yˆi表示i样本对应的预测pIC50值
MSE = (1 / m) * sum((yi - yˆi) ** 2)(三)均方根误差(RMSE)
RMSE 是衡量平均误差的较方便方法,对测量中的特大或特效误差敏感,能反映测量精密度。
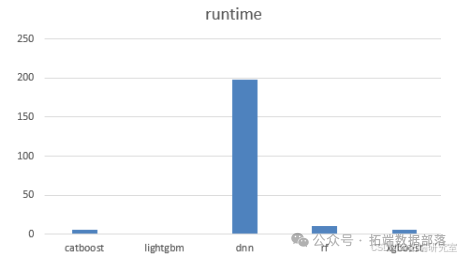
实验结果展示及分析
(一)构建化合物对 ERα 生物活性的定量预测模型
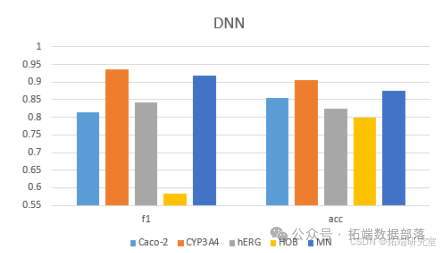
DNN 深度神经网络的 MAE、MSE、RMSE、RT 四个指标普遍高于其他普通机器学习模型,尤其是运行时间远高于其他模型,表明深度学习预测模型不适合本题应用场景。综合比较 MAE、MSE、RMSE 三个指标,CatBoost 模型表现相对较好,故选用 CatBoost 作为预测模型。
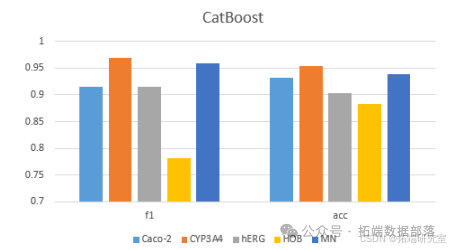
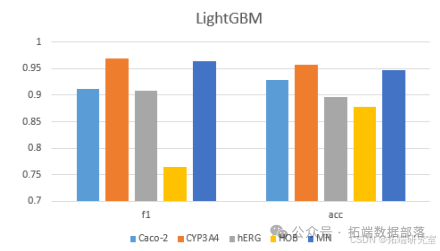
(二)构建 ADMET 性质的分类预测模型
不同模型对化合物的 ADMET 数据预测结果不同,如 CatBoost 对 hERG、HOB 的 F1 分数和 Accuracy 分数比其余四个模型都要高,LightGBM 对 MN 的 F1 分数和 Accuracy 分数比部分模型要高,XGBoost 对 Caco - 2、CYP3A4 的 F1 分数和 Accuracy 分数比其余四个模型都要高。


(三)变量优化
通过对原始数据分析,可观察出在 ADMET 性质取得最好和 pIC50 值最大之间存在负相关联系,且根据不同 ADMET 分数对应的 pIC50 取值范围假设,为进一步研究提供参考。
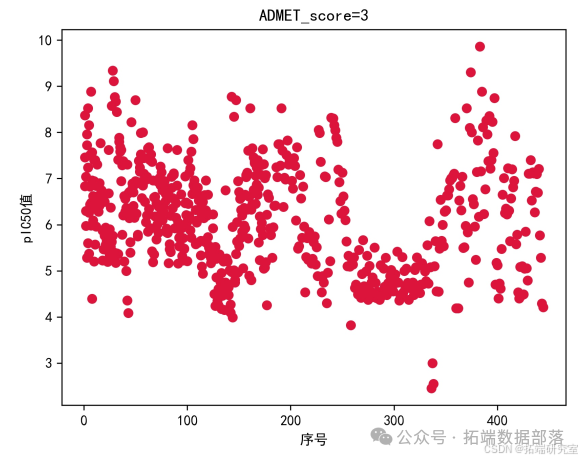
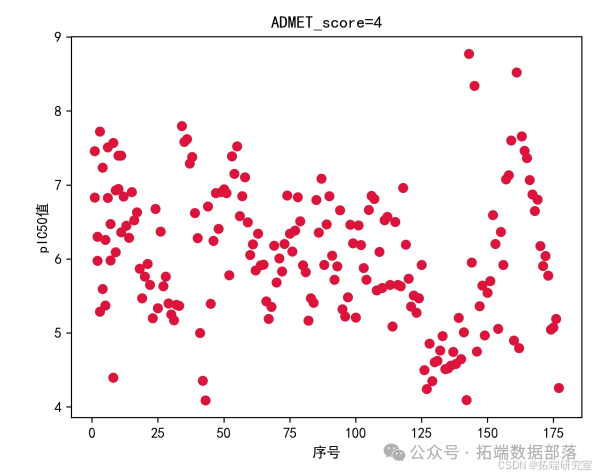
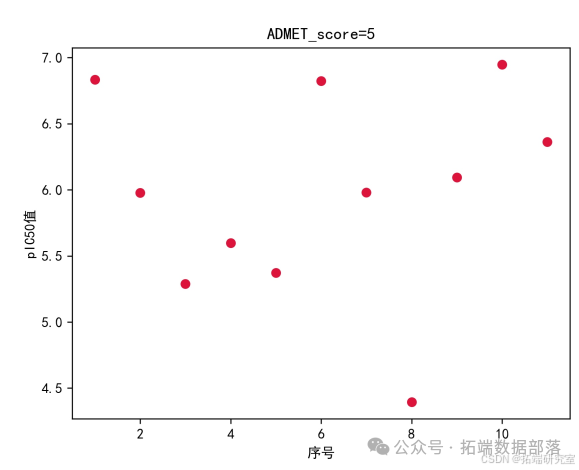
根据这个评价值进行下一代种群的产生和选择。具体过程如下图所示。
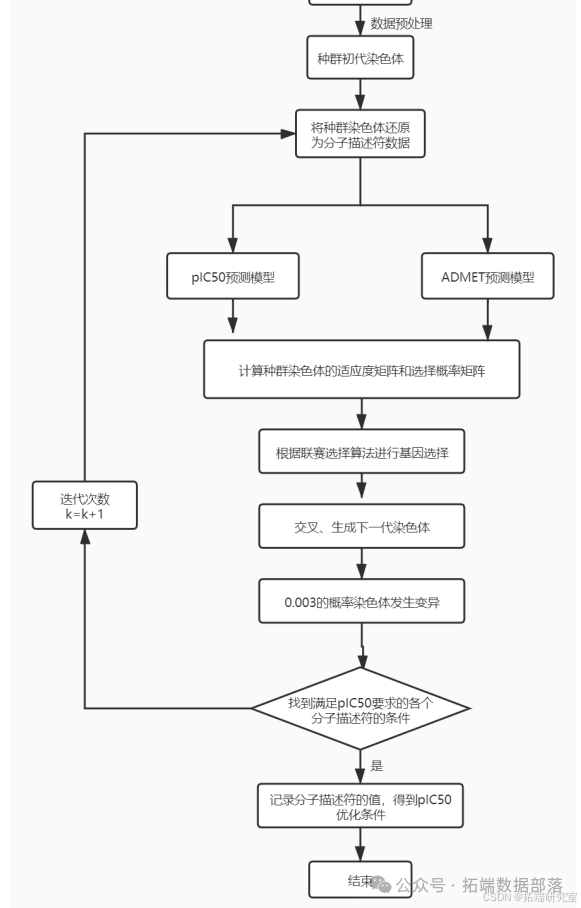
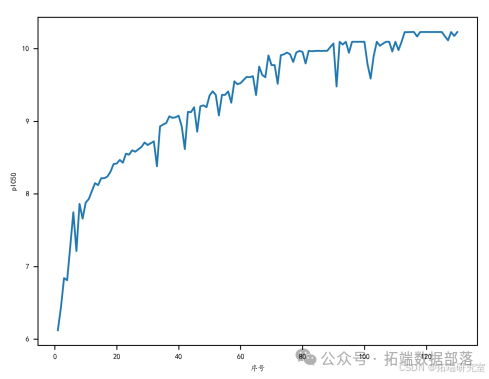
上文中的遗传算法中,我们已经得到了 pIC50 取值最大时的各个分子描述符的取值 X0 = (x1, x2..., xn)(xi 表示第 i 的分子描述符)。遗传算法运行过程中pIC50 变化如下图所示:
Python信贷风控模型:梯度提升Adaboost,XGBoost,SGD, GBOOST, SVC,随机森林, KNN预测金融信贷违约支付和模型优化|附数据代码
在此数据集中,我们必须预测信贷的违约支付,并找出哪些变量是违约支付的最强预测因子?以及不同人口统计学变量的类别,拖欠还款的概率如何变化?
有25个变量:
-
ID: 每个客户的ID
-
LIMIT_BAL: 金额
-
SEX: 性别(1 =男,2 =女)
4.教育程度:(1 =研究生,2 =本科,3 =高中,4 =其他,5 =未知)
5.婚姻: 婚姻状况(1 =已婚,2 =单身,3 =其他)
6.年龄:
-
PAY_0: 2005年9月的还款状态(-1 =正常付款,1 =延迟一个月的付款,2 =延迟两个月的付款,8 =延迟八个月的付款,9 =延迟9个月以上的付款)
-
PAY_2: 2005年8月的还款状态(与上述相同)
-
PAY_3: 2005年7月的还款状态(与上述相同)
-
PAY_4: 2005年6月的还款状态(与上述相同)
-
PAY_5: 2005年5月的还款状态(与上述相同)
-
PAY_6: 还款状态2005年4月 的账单(与上述相同)
-
BILL_AMT1: 2005年9月的账单金额
-
BILL_AMT2: 2005年8月的账单金额
-
BILL_AMT3: 账单金额2005年7月 的账单金额
-
BILL_AMT4: 2005年6月的账单金额
-
BILL_AMT5: 2005年5月的账单金额
-
BILL_AMT6: 2005年4月
-
PAY_AMT1 2005年9月,先前支付金额
-
PAY_AMT2 2005年8月,以前支付的金额
-
PAY_AMT3: 2005年7月的先前付款
-
PAY_AMT4: 2005年6月的先前付款
-
PAY_AMT5: 2005年5月的先前付款
-
PAY_AMT6: 先前的付款额在2005年4月
-
default.payment.next.month: 默认付款(1 =是,0 =否)
现在,我们知道了数据集的整体结构。因此,让我们应用在应用机器学习模型时通常应该执行的一些步骤。
第1步:导入
go
import numpy as np
import matplotlib.pyplot as plt所有写入当前目录的结果都保存为输出。
go
dataset = pd.read_csv('Card.csv')现在让我们看看数据是什么样的
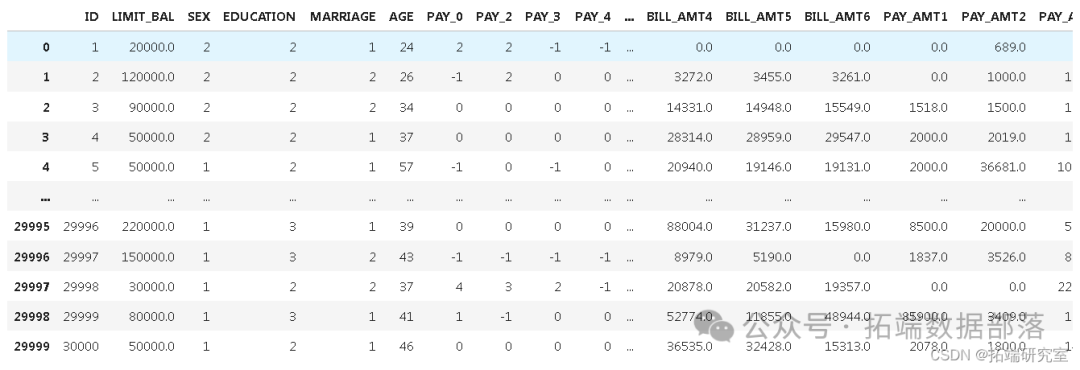
第2步:数据预处理和清理
go
dataset.shape
go
(30000, 25)意味着有30,000条目包含25列
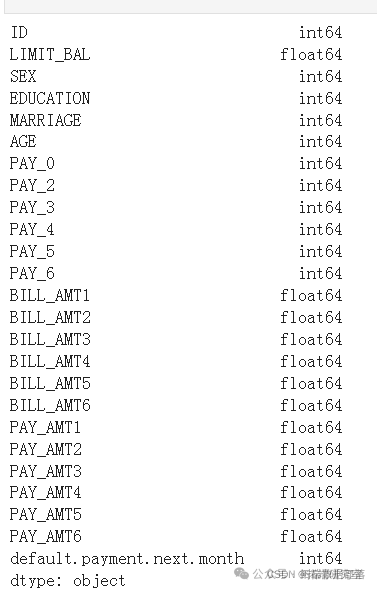
从上面的输出中可以明显看出,任何列中都没有对象类型不匹配。
go
#检查数据中Null项的数量,按列计算。
dataset.isnull().sum()
步骤3.数据可视化和探索性数据分析
go
# 按性别检查违约者和非违约者的计数数量
sns.countplot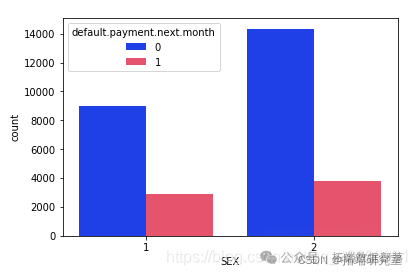
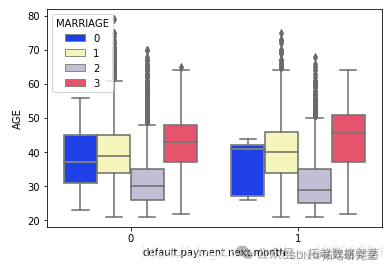
从上面的输出中可以明显看出,与男性相比,女性的整体拖欠付款更少
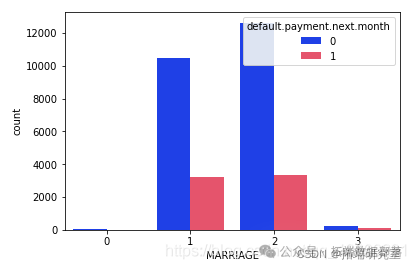
可以明显看出,那些拥有婚姻状况的人的已婚状态人的默认拖欠付款较少。
go
sns.pairplot
go
sns.jointplot
男女按年龄分布
go
g.map(plt.hist,'AGE')
go
dataset\['LIMIT_BAL'\].plot.density
步骤4.找到相关性
go
X.corrwith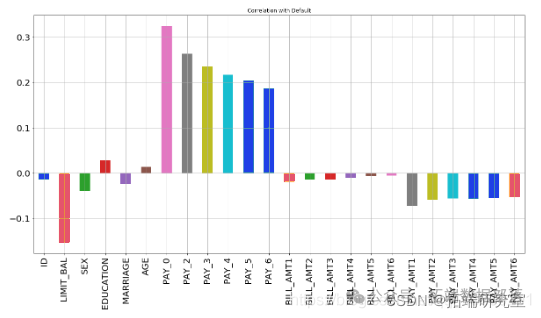
从上图可以看出,最负相关的特征是LIMIT_BAL,但我们不能盲目地删除此特征,因为根据我的看法,这对预测非常重要。ID无关紧要,并且在预测中没有任何作用,因此我们稍后将其删除。
go
# 绘制热图
sns.heatmap(corr)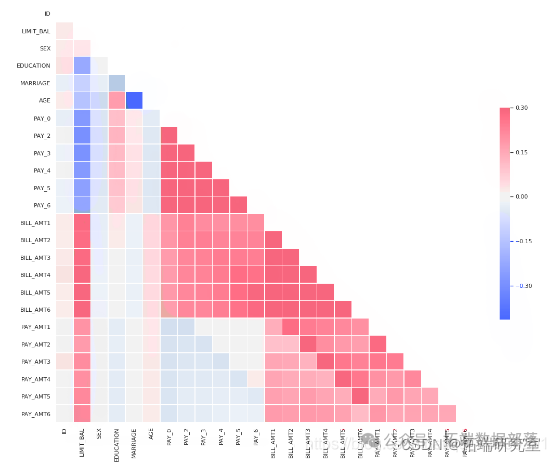
步骤5:将数据分割为训练和测试集
训练数据集和测试数据集必须相似,通常具有相同的预测变量或变量。它们在变量的观察值和特定值上有所不同。如果将模型拟合到训练数据集上,则将隐式地最小化误差。拟合模型为训练数据集提供了良好的预测。然后,您可以在测试数据集上测试模型。如果模型在测试数据集上也预测良好,则您将更有信心。因为测试数据集与训练数据集相似,但模型既不相同也不相同。这意味着该模型在真实意义上转移了预测或学习。
因此,通过将数据集划分为训练和测试子集,我们可以有效地测量训练后的模型,因为它以前从未看到过测试数据,因此可以防止过度拟合。
我只是将数据集拆分为20%的测试数据,其余80%将用于训练模型。
go
train\_test\_split(X, y, test\_size = 0.2, random\_state = 0)步骤6:规范化数据:特征标准化
对于许多机器学习算法而言,通过标准化(或Z分数标准化)进行特征标准化可能是重要的预处理步骤。
许多算法(例如SVM,K近邻算法和逻辑回归)都需要对特征进行规范化,
go
min\_test = X\_test.min()
range\_test = (X\_test - min_test).max()
X\_test\_scaled = (X\_test - min\_test)/range_test步骤7:应用机器学习模型
go
from sklearn.ensemble import AdaBoostClassifier
adaboost =AdaBoostClassifier()
go
xgb\_classifier.fit(X\_train\_scaled, y\_train,verbose=True)
end=time()
train\_time\_xgb=end-start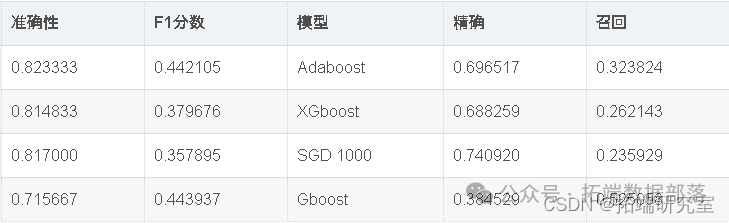
应用具有100棵树和标准熵的随机森林
go
classifier = RandomForestClassifier(random_state = 47,
criterion = 'entropy',n_estimators=100)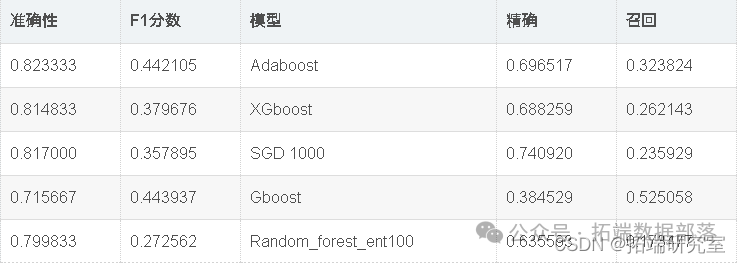
go
svc_model = SVC(kernel='rbf', gamma=0.1,C=100)
go
knn = KNeighborsClassifier(n_neighbors = 7)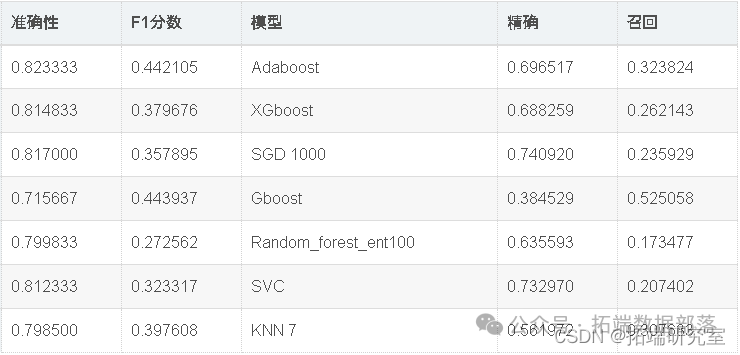
步骤8:分析和比较机器学习模型的训练时间
go
Train_Time = \[
train\_time\_ada,
train\_time\_xgb,
train\_time\_sgd,
train\_time\_svc,
train\_time\_g,
train\_time\_r100,
train\_time\_knn
\]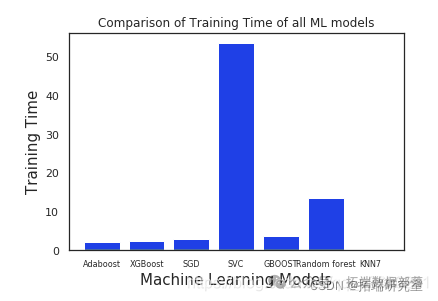
从上图可以明显看出,与其他模型相比,Adaboost和XGboost花费的时间少得多,而其他模型由于SVC花费了最多的时间,原因可能是我们已经将一些关键参数传递给了SVC。
步骤9.模型优化
在每个迭代次数上,随机搜索的性能均优于网格搜索。同样,随机搜索似乎比网格搜索更快地收敛到最佳状态,这意味着迭代次数更少的随机搜索与迭代次数更多的网格搜索相当。
在高维参数空间中,由于点变得更稀疏,因此在相同的迭代中,网格搜索的性能会下降。同样常见的是,超参数之一对于找到最佳超参数并不重要,在这种情况下,网格搜索浪费了很多迭代,而随机搜索却没有浪费任何迭代。
现在,我们将使用Randomsearch cv优化模型准确性。如上表所示,Adaboost在该数据集中表现最佳。因此,我们将尝试通过微调adaboost和SVC的超参数来进一步优化它们。
参数调整
现在,让我们看看adaboost的最佳参数是什么
go
random\_search.best\_params_
go
{'random\_state': 47, 'n\_estimators': 50, 'learning_rate': 0.01}
go
random\_search.best\_params_
go
{'n\_estimators': 50, 'min\_child\_weight': 4, 'max\_depth': 3}
go
random\_search.best\_params_
go
{'penalty': 'l2', 'n\_jobs': -1, 'n\_iter': 1000, 'loss': 'log', 'alpha': 0.0001}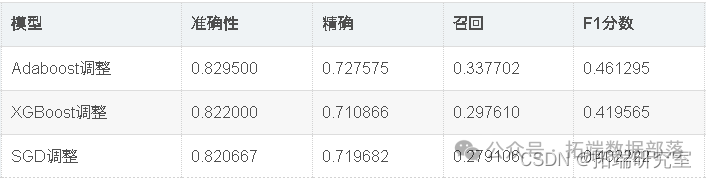
出色的所有指标参数准确性,F1分数精度,ROC,三个模型adaboost,XGBoost和SGD的召回率现已优化。此外,我们还可以尝试使用其他参数组合来查看是否会有进一步的改进。
ROC曲线图
go
auc = metrics.roc\_auc\_score(y\_test,model.predict(X\_test_scaled))
plt.plot(\[0, 1\], \[0, 1\],'r--')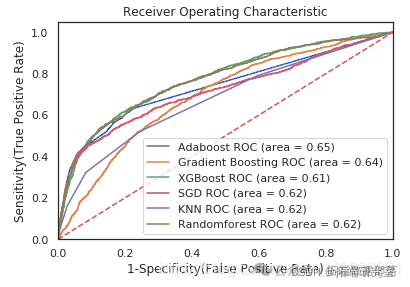
go
# 计算测试集分数的平均值和标准差
test_mean = np.mean
# 绘制训练集和测试集的平均准确度得分
plt.plot
# 绘制训练集和测试集的准确度。
plt.fill_between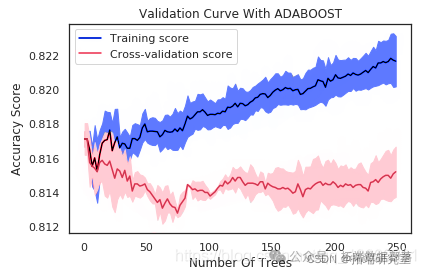
验证曲线的解释
如果树的数量在10左右,则该模型存在高偏差。两个分数非常接近,但是两个分数都离可接受的水平太远,因此我认为这是一个高度偏见的问题。换句话说,该模型不适合。
在最大树数为250的情况下,由于训练得分为0.82但验证得分约为0.81,因此模型存在高方差。换句话说,模型过度拟合。同样,数据点显示出一种优美的曲线。但是,我们的模型使用非常复杂的曲线来尽可能接近每个数据点。因此,具有高方差的模型具有非常低的偏差,因为它几乎没有假设数据。实际上,它对数据的适应性太大。
从曲线中可以看出,大约30到40的最大树可以最好地概括看不见的数据。随着最大树的增加,偏差变小,方差变大。我们应该保持两者之间的平衡。在30到40棵树的数量之后,训练得分就开始上升,而验证得分开始下降,因此我开始遭受过度拟合的困扰。因此,这是为什么30至40之间的任何数量的树都是一个不错的选择的原因。
结论
因此,我们已经看到,调整后的Adaboost的准确性约为82.95%,并且在所有其他性能指标(例如F1分数,Precision,ROC和Recall)中也取得了不错的成绩。
此外,我们还可以通过使用Randomsearch或Gridsearch进行模型优化,以找到合适的参数以提高模型的准确性。
我认为,如果对这三个模型进行了适当的调整,它们的性能都会更好。
通过ARIMA、XGBOOST、PROPHET和LSTM预测比特币价格|附数据代码
比特币作为一种持续占据世界头条并日益流行的加密货币,随着越来越多的人和组织开始采用它。在本文中,我将测试4种不同的Python机器学习模型对比特币预测能力:ARIMA、Prophet、XGBoost和LSTM。通过将数据划分为测试集和训练集,我将比较每个模型的性能,并得出哪个模型表现最佳。
测试模型的标准程序
每个模型将在数据的前70%上进行训练,并在最后30%上进行测试。比特币数据将被重新采样为天,并仅限于过去4年的数据(从2021年3月31日起)。
每个模型的均方根误差(RMSE)将决定哪个模型最佳。RMSE是残差的标差------或者更简单地说,是残差分布的分散程度。
1. 探索性数据分析(EDA)
导入库:
go
python# 导入所需的库
import numpy as np
import pandas as pd
import datetime as dt
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import mean\_squared\_error
from math import sqrt
from pandas.plotting import autocorrelation_plot读取数据集到数据框:
go
python# 将数据集读取到数据框中
df.head()
绘制比特币价格随时间变化的图表:
go
python复制# 绘制比特币价格随时间变化的图表
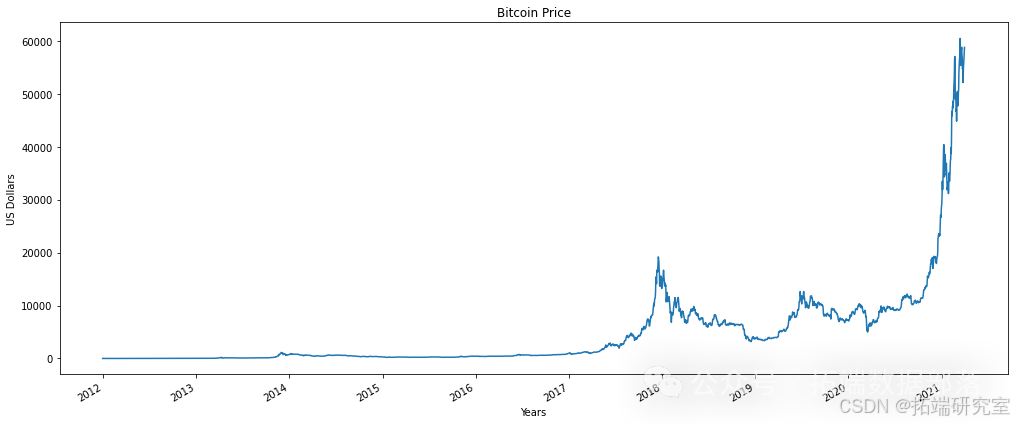
plt.tight_layout()正如图表所示,2017-2021年的价格行为与2012-2017年有显著不同
绘制自相关图,查看时间序列中是否存在大量的滞后:
go
python复制# 绘制自相关图,查看时间序列中是否存在大量的滞后
autocorrelation_plot(df)
plt.show()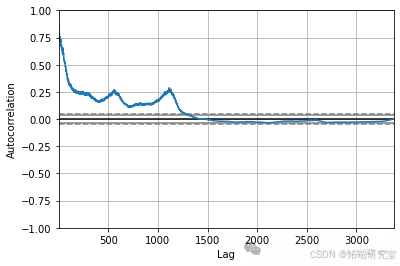
查看过去200天的数据,可能需要调整数据以适应这个时间段:
go
python复制# 查看过去200天的数据,可能需要调整数据以适应这个时间段
df.Weighted_Price.iloc\[-200:\].
figsize=(14,6))
plt.tight_layout()
plt.show()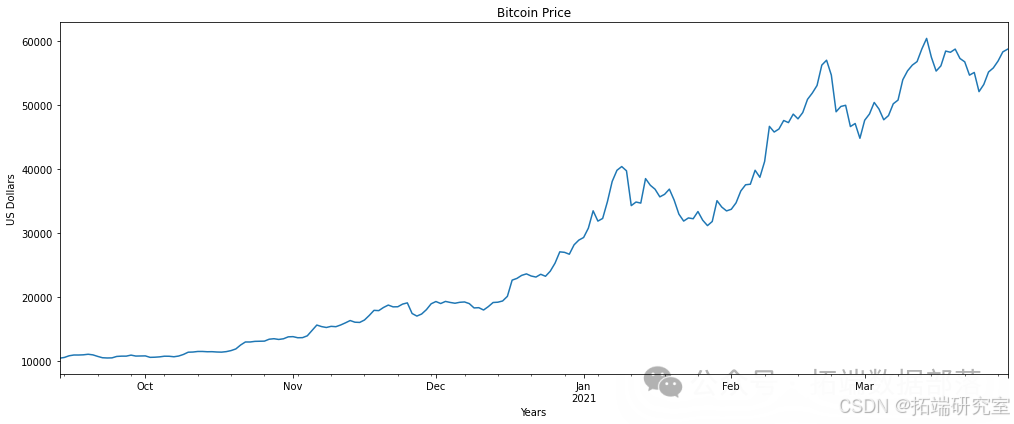
go
df2.Weighted_Price.plot(title = "Bitcoin Price", figsize=(14,6))
plt.tight_layout()
plt.xlabel('Dates')
plt.ylabel('$ Price')
plt.show()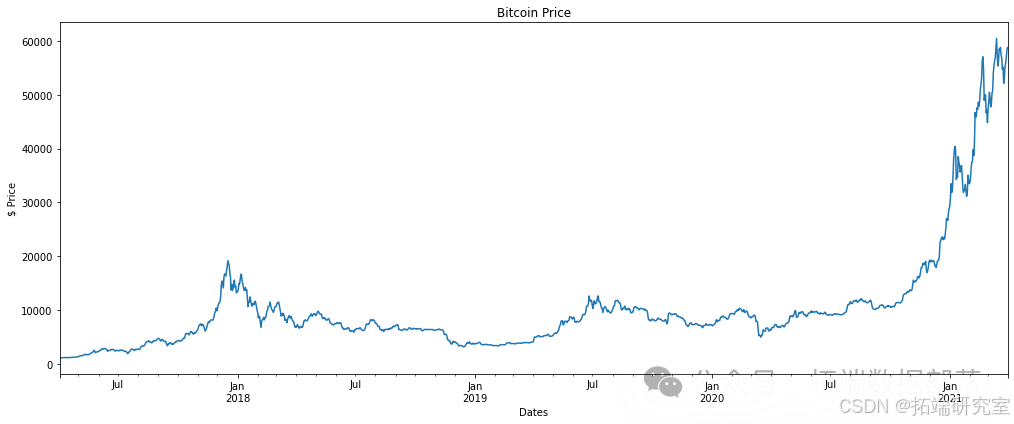
数据看起来对于训练模型更为相关。然而,最近的峰值将涉及测试数据分割 - 这是一个艰难的预测。
1. ARIMA滚动预测
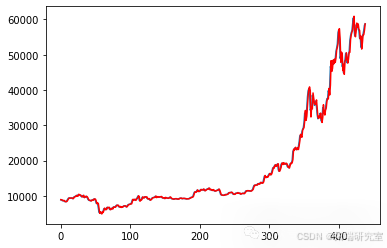
首先,我创建了一个ARIMA滚动预测模型,以获得一个优秀的RMSE基线。然而,由于这个模型是按滚动的日增量进行预测的,与其他模型进行比较并不公平。如图所示,预测值以红色显示,实际价格以蓝色显示。然而,我们必须放大更多才能区分两者。
评估预测:
go
# 评估预测 rmse = sqrt(mean\_squared\_error(test, predictions)) print(
# 绘制预测与实际结果的对比图 plt.plot(test) plt.plot(predictions, color='red') plt.show()
go
plt.plot(predictions, color='red')
plt.xlabel('Days')
plt.ylabel('$ Price')
plt.title('Predicted vs. Actual BTC Price')
plt.show()
go
Test RMSE: 914.737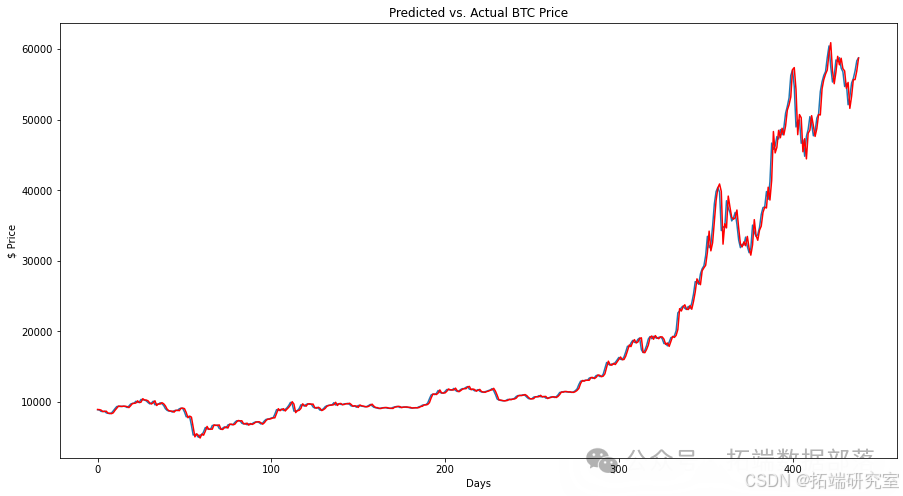
go
plt.plot(predictions\[-50:\], color='red')
plt.xlabel('Days')
plt.ylabel('$ Price')
plt.title('Predicted vs. Expected BTC Price Forecast')
plt.show()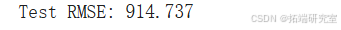
2. PROPHET模型
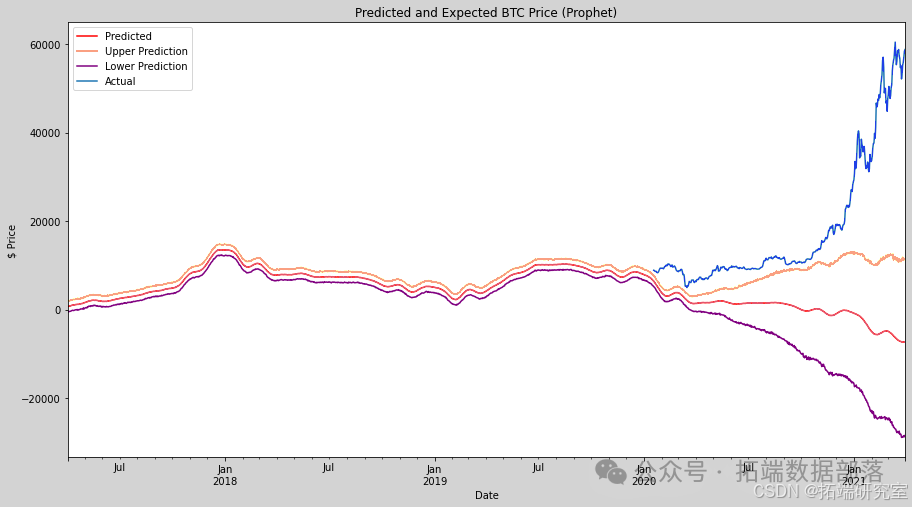
Prophet库是由Facebook开发的开源库,专为时间序列数据的自动预测而设计。该模型主要关注趋势和季节性的预测。但由于其易用性,我决定首先使用默认设置来实现这个模型。如图所示,先知模型预测比特币价格将会下跌。此外,该模型还提供了上限和下限的估计值(阴影区域的边缘)。虽然上限估计的斜率方向准确,但与测试数据相比,这个模型表现不佳。
频率为天,周期为测试数据的长度:
go
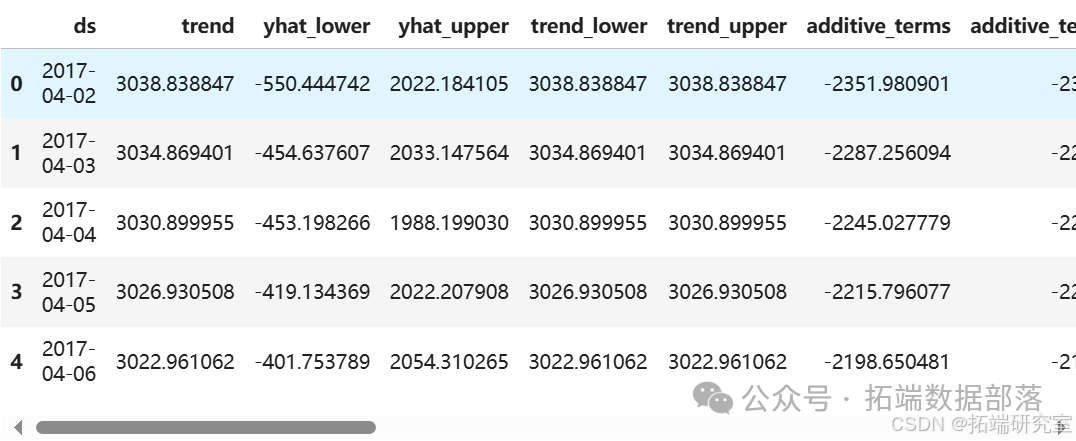
# 频率为天,周期为测试数据的长度 future = model.make\_future\_dataframe(periods=len(test), freq='D') forecasting = model.predict(future) # 存储预测结果并返回RMSE y\_true = test\['y'\].values y\_pred = forecasting.yhat.values\[-len(test):\]
go
# 绘制预测图 model.plot(forecasting)
plt.ylabel('$ Price')
plt.xlabel('Date')
plt.show()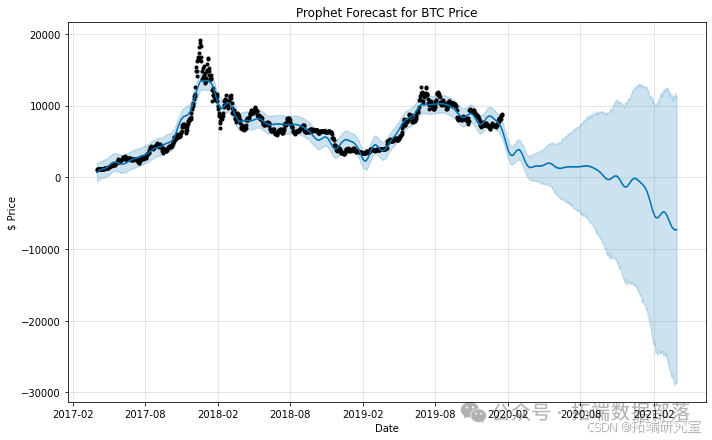
3. ARIMA模型
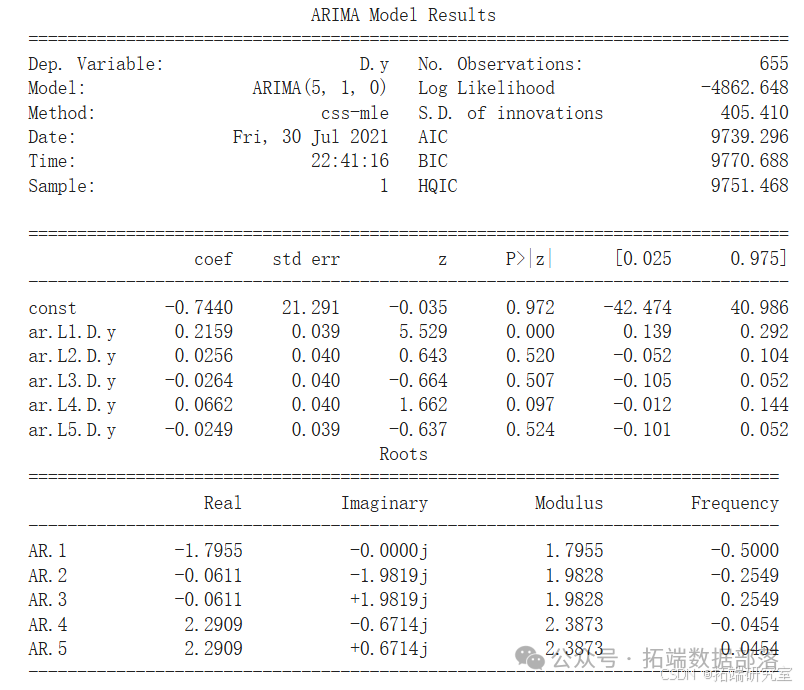
接下来是ARIMA模型,它是自回归积分滑动平均(AutoRegressive Integrated Moving Average)的缩写。ARIMA是一种广泛使用的统计方法,用于分析和预测时间序列数据。它由一组时间序列数据的标准结构组成,并提供了一种简单而强大的方法来进行熟练的时间序列预测。ARIMA模型有3个参数(p, d, q),这些参数指示正在使用的特定ARIMA模型。我只是应用了我以前在不同的时间序列数据上使用过的参数,这可能导致模型不利。
go
# 按照常规方法将数据分为70%的训练集和30%的测试集
price = df2.Weighted_Price # 获取比特币加权价格数据
X = price.values # 将价格数据转换为数值数组
datesX = price.index # 获取价格数据的索引(日期)
size = int(len(X) * 0.70) # 计算训练集的大小
train, test = X\[0:size\], X\[size:len(X)\] # 分割数据为训练集和测试集
days\_in\_year = 365 # 定义一年中的天数
plotDates = datesX\[size:len(X)\] # 获取测试集的日期索引,用于后续绘图
# 使用ARIMA模型进行预测,参数设置为(5,1,0)
differenced = difference(train, days\_in\_year) # 对训练数据进行差分处理,以满足ARIMA模型的平稳性要求
model = ARIMA(differenced, order=(5, 1, 0)) # 初始化ARIMA模型,参数p=5, d=1, q=0
model_fit = model.fit() # 拟合模型
start_index = len(differenced) # 预测的起始索引
end\_index = start\_index + 438 # 预测的结束索引,这里选择了438步进行预测
forecast = model\_fit.predict(start=start\_index, end=end_index) # 进行预测
history = \[x for x in train\] # 初始化历史数据列表,用于存储训练数据
day = 1 # 初始化天数计数器
predicted_results = list() # 初始化预测结果列表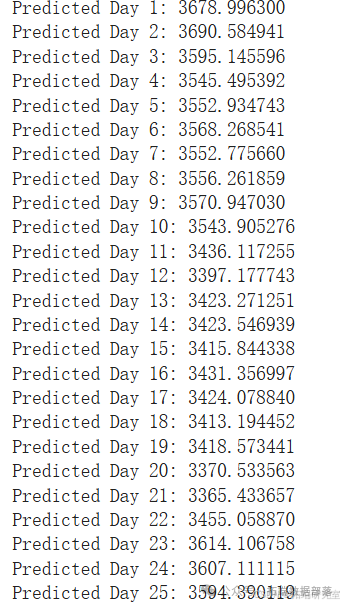

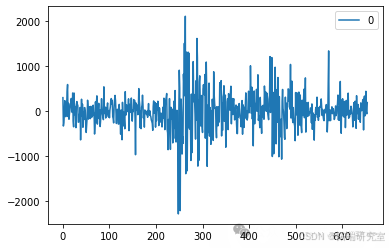
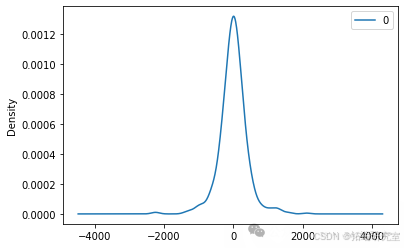

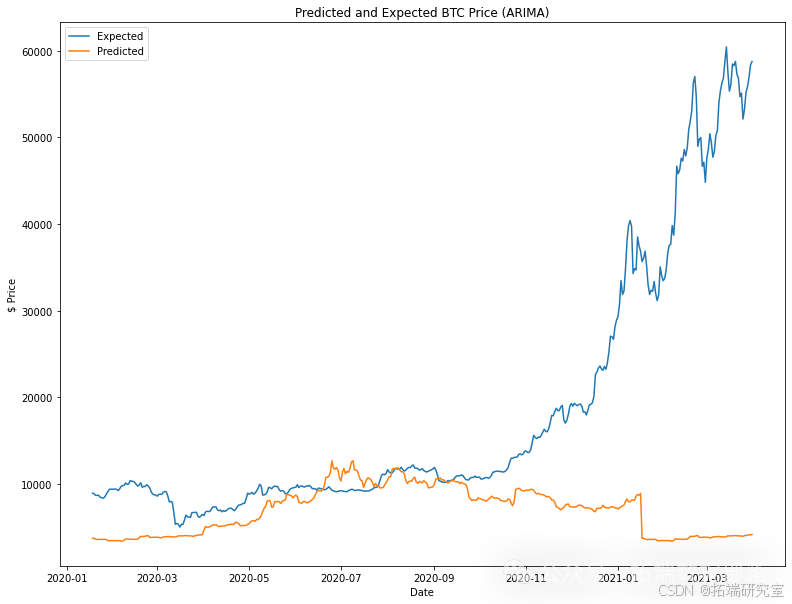
4. LSTM模型
长短期记忆(LSTM)模型是一种能够学习观察序列的循环神经网络。这使它们成为适合时间序列预测的深度学习网络。然而,通常LSTM在处理像比特币这样波动大且难以预测的时间序列数据集时会遇到困难。经过艰苦的过程尝试应用我的数据后,我终于训练了模型。在最后的拟合中,我使用了50个周期和"adam"优化器。
go
model.compile(loss="mean\_squared\_error",optimizer="adam")
go
# fit the model to the training data
model.fit(x\_train,y\_train,epochs=50,batch_size=32)
go
plt.xticks(x, labels, rotation = 'vertical')
plt.xlabel('Time')
plt.ylabel('$ Price')
plt.legend(loc=4, prop={'size': 14})
plt.show()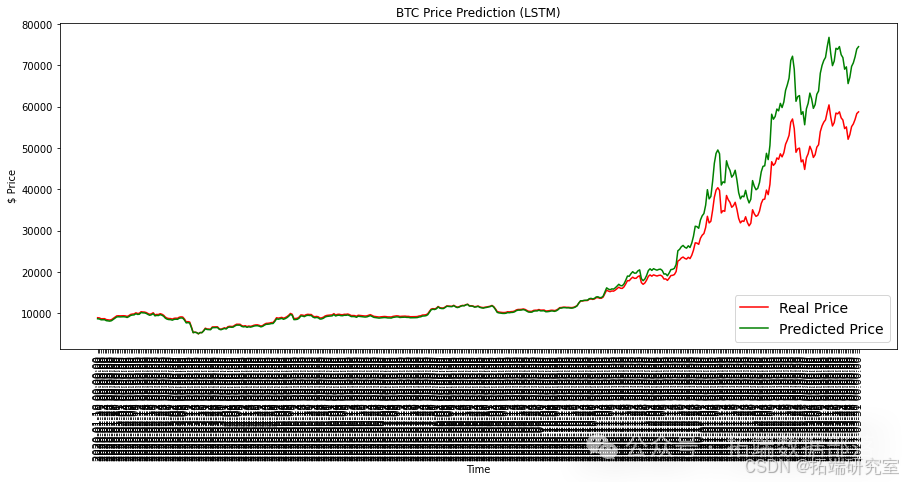

5. XGBOOST模型
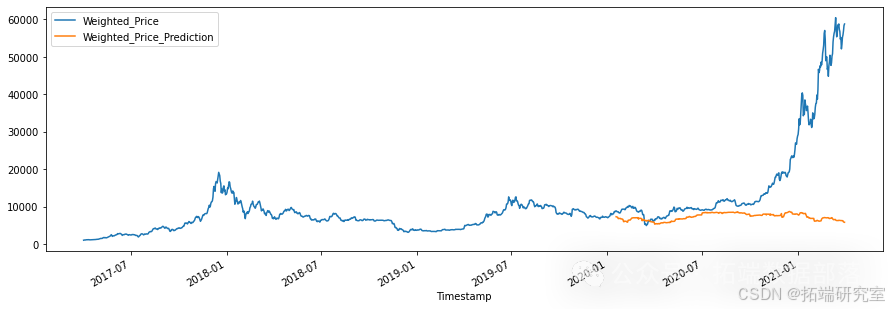
XGBoost是目前最流行的机器学习算法之一。无论手头的预测任务是回归还是分类。XGBoost以其比其他机器学习算法提供更好的解决方案而闻名。事实上,自从它诞生以来,它已经成为处理结构化数据的"最新技术"机器学习算法。然而,在这种情况下,我们将在时间序列数据上使用它。因此,模型需要从日期时间索引创建时间序列特征 - 用于在预测时与其目标价格标签一起使用。不幸的是,最终模型表现不佳。

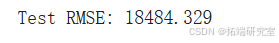
6. 结论
最终结果如下所示。长短期记忆模型在处理像比特币价格这样波动大且难以预测的数据时,被证明是最有效的。这个比特币数据集包含了极其波动和异常的时间序列数据。因此,我发现模型在预测最近439天的价格时遇到了困难,我并不感到惊讶。此外,我承认我本可以选择更好、更明智的参数,以便让这些模型和库的结果更公平。然而,我认为LSTM模型的低RMSE证明了神经网络在机器学习中的强大能力。我期待在未来更深入地探索RNN在金融时间序列数据中的应用!
go
ax.bar(modelz,nums)
plt.xlabel('Models')
plt.ylabel('RMSE')
plt.title('RMSE of the Models')
plt.show()
plt.show()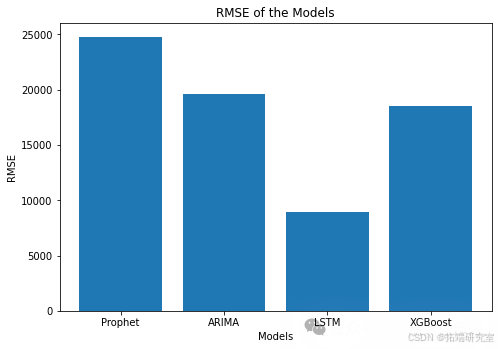
SMOTE逻辑回归、SVM、随机森林、AdaBoost和XGBoost分析严重不平衡的破产数据|附数据代码
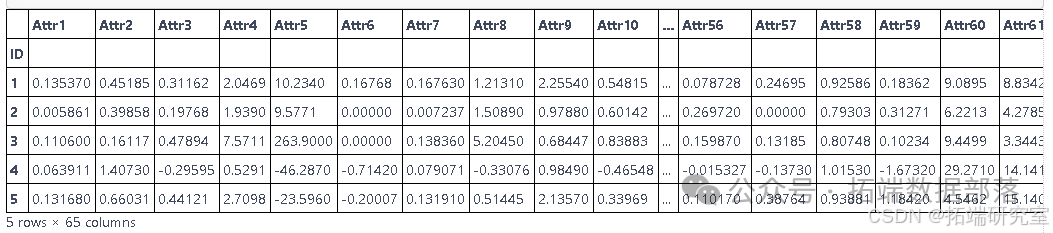
本文旨在探讨如何有效处理并分析严重不平衡的破产数据,采用XGBoost模型作为主要分析工具。数据集包含实体的多种特征和财务比率,目标变量为公司未来几年是否破产(1表示破产,0表示未破产)。通过一系列预处理步骤,包括缺失值处理、多重共线性检查、异常值分析以及通过K-means聚类探索数据分布,本文最终实现了对不平衡数据的有效重采样,并评估了多种机器学习模型在破产预测任务上的性能。
数据预处理
数据导入与探索
首先,使用pandas库导入数据集,并设置实体ID为索引:
go
df = pd.read_csv('train.csv')
df.set_index('ID', inplace = True)
df.head()数据不平衡性
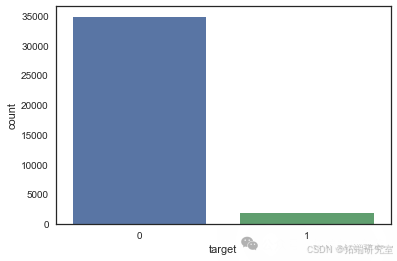
初步分析表明数据存在严重的不平衡性,这是破产预测任务中常见的挑战。不平衡性可能源于罕见但影响重大的事件发生。
缺失值处理
对于数据中的缺失值,采用适当的插补策略以确保数据完整性。通过可视化缺失值矩阵,可以直观地了解缺失值的分布情况。
go
plt.figure(figsize=(16,6))
msno.matrix(X_df,labels = True, color=(0.20,0.15,0.45))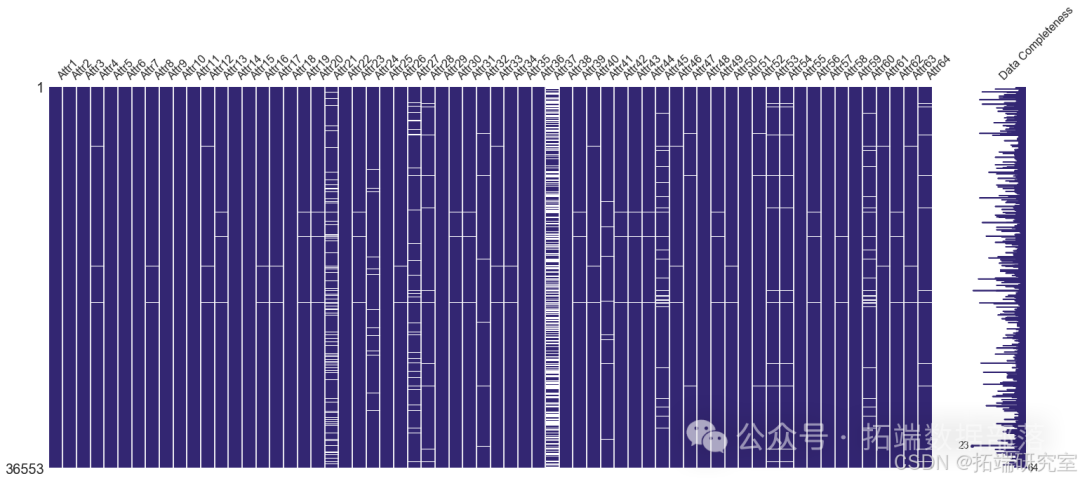
多重共线性检查
通过绘制热图检查特征之间的多重共线性问题,以避免模型训练过程中的信息冗余和过拟合风险。
go
fig, ax = plt.subplots(figsize=(16,12))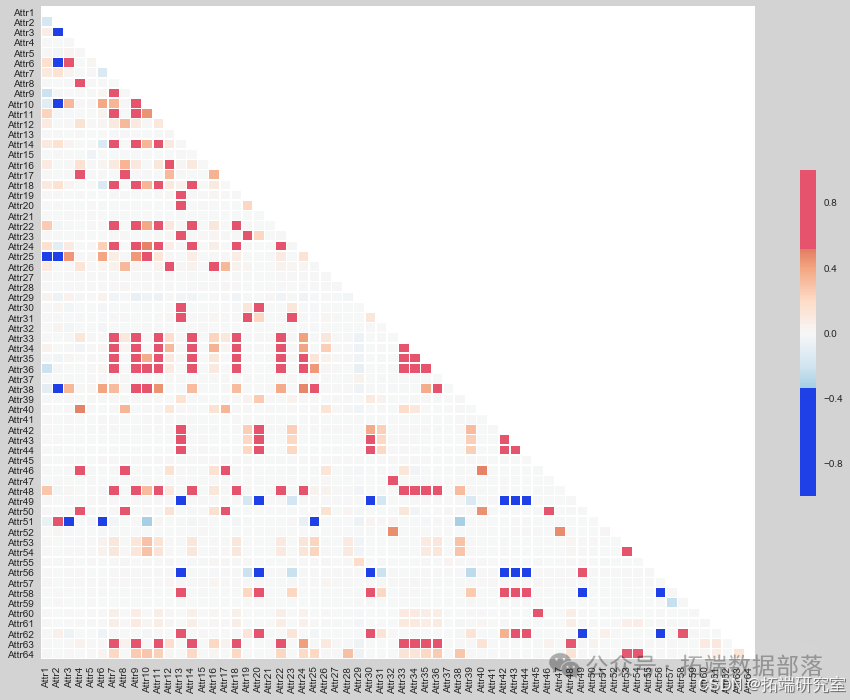
go
plt.xticks(rotation=90)
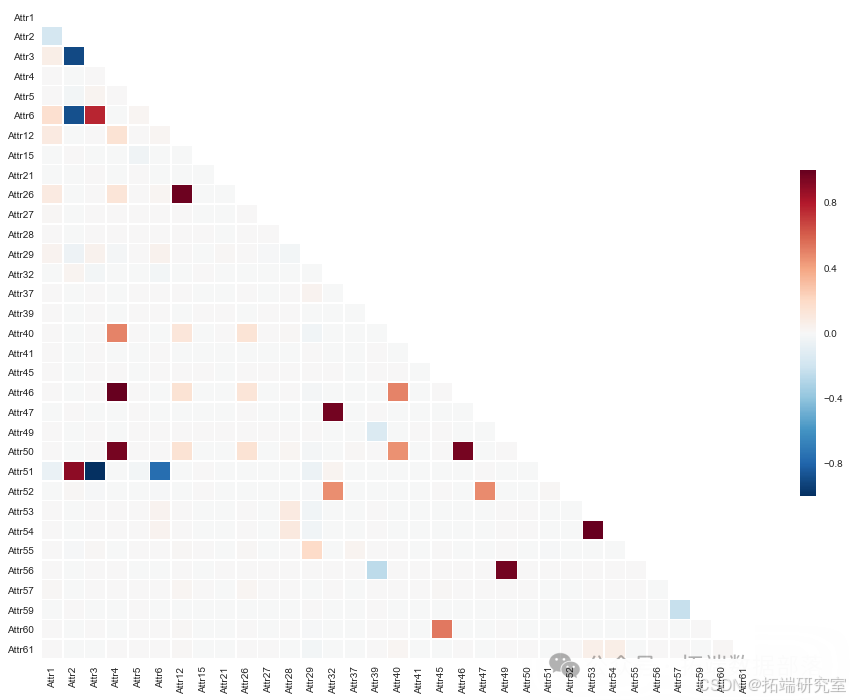
异常值处理
虽然识别出存在跨越多个标准差的异常值,但鉴于缺乏领域专业知识,未直接删除这些异常值,以避免可能的信息损失。
数据探索与聚类分析
K-means聚类
采用K-means聚类算法探索数据在特征空间中的分布特性,通过肘部法则确定最佳聚类数。结果显示数据多样性较高,可能包含多个潜在的子群体。
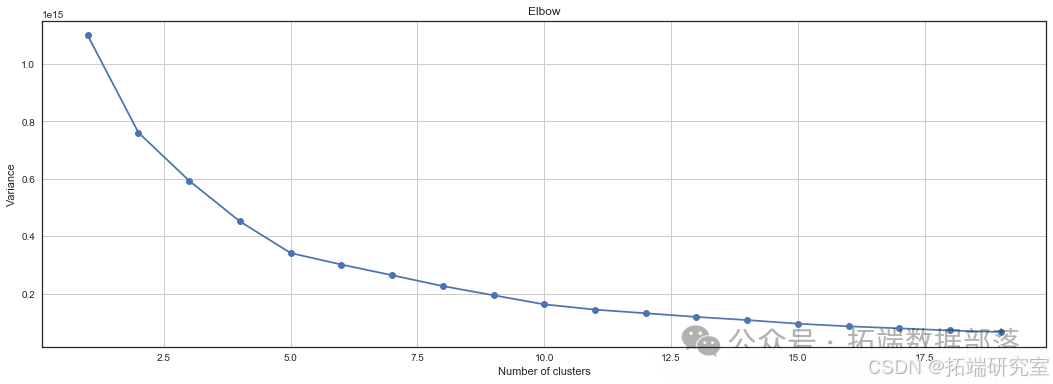
数据是多种多样的,许多实体分布在特征空间中。
因此,我们的数据可能属于 2 个以上的类,因为在聚类 = 2 时,方差似乎有点偏离。
数据重采样
SMOTE技术
针对数据的高度不平衡性,应用SMOTE(Synthetic Minority Over-sampling Technique)技术进行过采样。通过生成少数类(破产)的合成样本,平衡数据集,从而提高模型对少数类的识别能力。
go
X\_res, Y\_res = sm.fit\_sample(X\_train, Y_train)模型评估与选择
模型应用
将逻辑回归、SVM、随机森林、AdaBoost和XGBoost等模型应用于处理后的数据集,评估它们在破产预测任务上的性能。
go
pd.DataFrame(predictors).T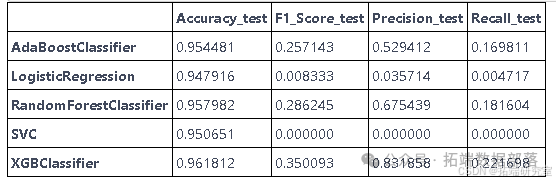
性能比较
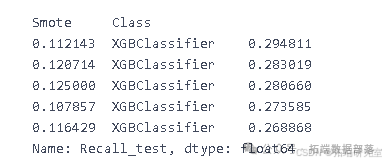
通过多次实验调整SMOTE中的过采样比率,并对比不同模型在召回率上的表现。结果显示,XGBoost模型在0.11214的打击率下取得了最高的召回率,表明其在处理不平衡数据方面的优势。
go
smote_values = np.linspace(0.065, 0.125, num= 15)
smote_values
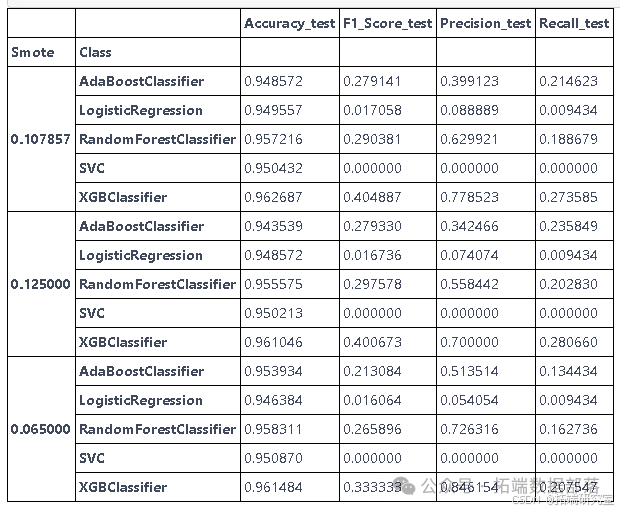
召回分数是我们感兴趣的。召回率显示了我们的模型将正值预测为正值的能力。由于我们的数据高度不平衡,因此任何模型都很难获得更好的召回率。有时模型忽略了少数群体。
结论
综上所述,XGBoost模型在破产预测任务中表现优异,特别是在处理严重不平衡的数据集时,其高召回率证明了其在识别少数类(破产公司)方面的有效性。通过合理的数据预处理、重采样策略以及模型选择,本文为类似的不平衡分类问题提供了一种有效的解决方案。未来的研究可以进一步探索更多先进的重采样技术和模型优化策略,以提升模型的整体性能。
关于分析师
在此对Yang Yang对本文所作的贡献表示诚挚感谢,他完成了电子信息(计算机技术)专业的硕士学位,专注于深度学习、机器学习等领域。擅长 R 语言、Python、mysql、tableau、Java 等技术。

在此对Kechen Zhao对本文所作的贡献表示诚挚感谢。她在墨尔本大学完成了学业,获得应用数学与统计本科学位,并进一步深造获得数据科学研究生学历。Kechen Zhao在软件方面有着深厚的技能,特别擅长使用R 语言、Python和Java。在专业领域,他尤其擅长机器学习、数据采集、分析和处理以及数学建模和预测。

Yimeng Li是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在南京大学完成了数学系统计学专业的学位,专注数理统计、机器学习领域。擅长R语言、Python、Tableau。

本文中分析的数据、代码**** 分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取全文完整代码数据资料。
本文选自《【梯度提升专题】XGBoost、Adaboost、CatBoost预测合集:抗乳腺癌药物优化、信贷风控、比特币应用》。
点击标题查阅往期内容
样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
PYTHON集成学习:自己编写构建ADABOOST分类模型可视化决策边界及SKLEARN包调用比较
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测




